







Qwen2.5 VL 论文解读
- 论文: https://arxiv.org/abs/2502.13923 (CVPR 2025.1.19)
- 代码: https://github.com/QwenLM/Qwen2.5-VL
- 模型:
- https://huggingface.co/Qwen
- https://modelscope.cn/organization/qwen
- web: https://chat.qwenlm.ai (Qwen官方客户端,目前支持: Qwen2.5-Max、Qwen2.5-Plus、Qwen2.5-Turbo,还未支持 Qwen2.5 VL)
回顾一下 Qwen VL 和 Qwen2 VL
Qwen VL
- 论文: https://arxiv.org/abs/2308.12966 (2023.10.3)
- 代码: https://github.com/QwenLM/Qwen-VL
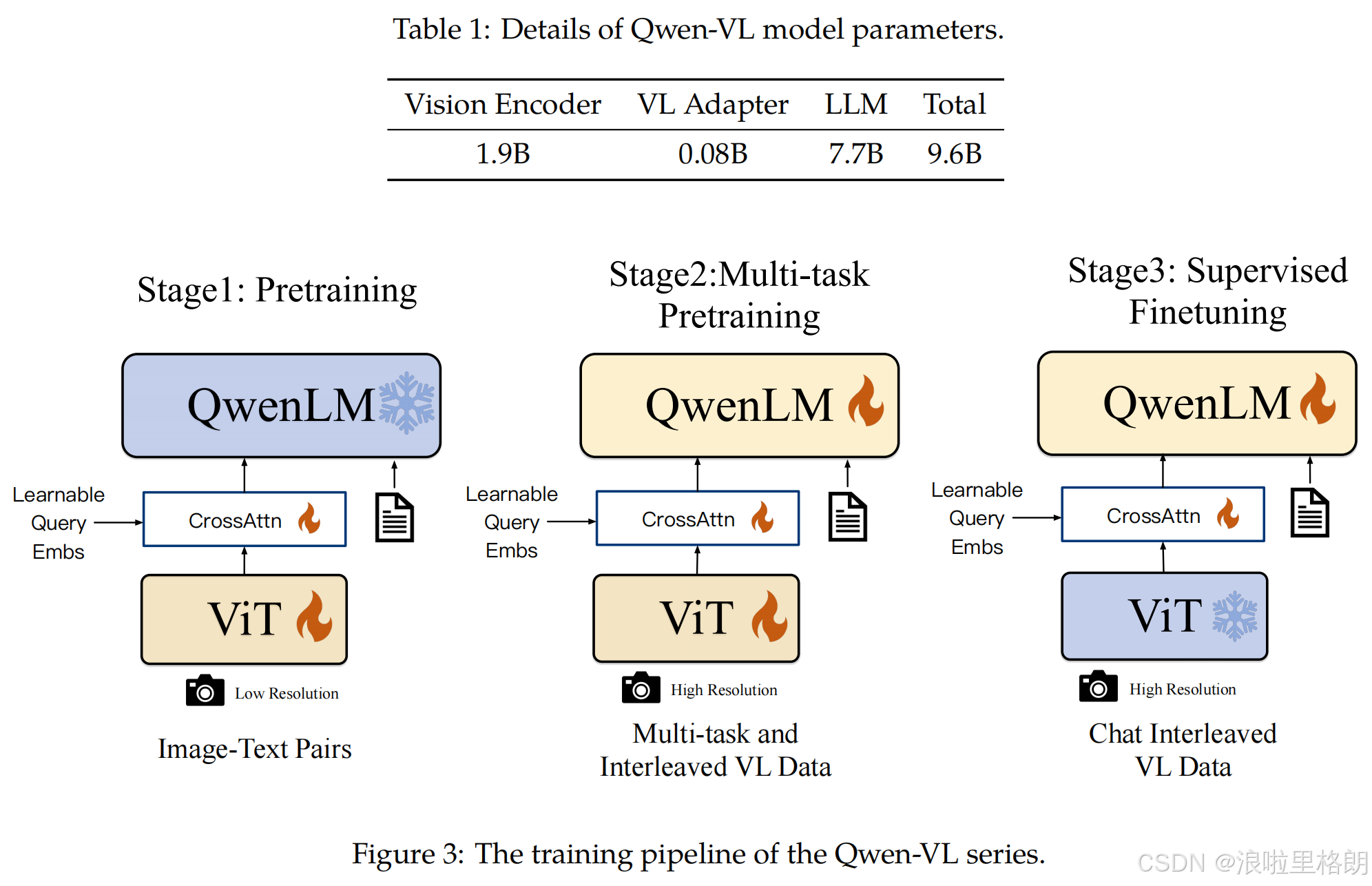
- 模块化架构
由 语言模型(Qwen-7B)、视觉编码器(ViT-bigG初始化)、位置感知适配器 三部分组成。视觉编码器处理图像生成特征序列,适配器通过交叉注意力将特征压缩为固定长度(256 tokens),并引入二维绝对位置编码保留空间信息。 - 输入接口设计
支持多图像交错输入,通过<|vision_start|>和<|vision_end|>标记区分图文模态,为多图像对比分析奠定基础。 - 训练策略
三阶段训练:ViT预训练→全模型联合训练→指令微调(Qwen-VL-Chat),通过图像-标题-框元组对齐实现定位能力。
Qwen2 VL
- 论文: https://arxiv.org/abs/2409.12191
- 代码: https://github.com/QwenLM/Qwen2.5-VL (和Qwen2.5 VL 同一个git)
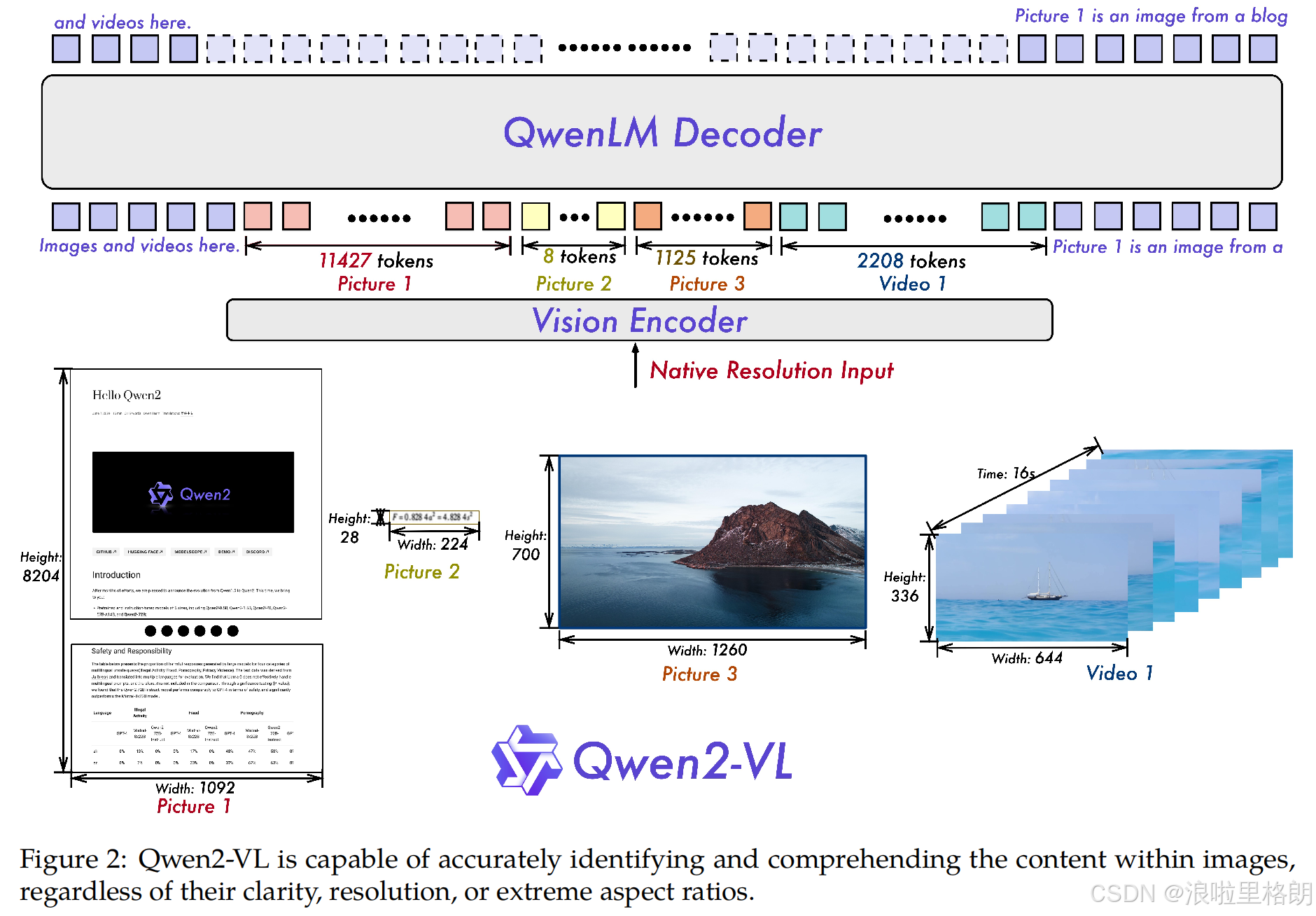
- 动态分辨率支持
引入 Naive Dynamic Resolution 机制,ViT去除固定位置编码,采用2D-RoPE动态处理任意分辨率图像,生成可变长度视觉tokens。推理时通过MLP压缩相邻2×2 tokens,减少计算负载。 - 多模态位置编码(M-RoPE)
将旋转位置编码分解为时间、高度、宽度三个维度,支持文本、图像、视频的时空信息融合。文本使用1D-RoPE,图像按空间位置编码,视频增加时间维度递增ID。 - 统一视频处理
视频以2帧/秒采样,通过3D卷积处理,每帧视为图像并动态调整分辨率,总tokens限制为16384以平衡长视频处理效率。 - 模型扩展
推出2B/8B/72B参数版本,视觉编码器固定为675M参数,与LLM规模解耦,支持端侧到云端部署。
论文总结
回到文章“Qwen2.5-VL Technical Report”,文章介绍了Qwen2.5-VL视觉语言模型,通过优化架构、改进训练方法和扩充数据,提升多模态理解与交互能力,在多任务中表现出色。下面是论文的思维导图:
网络结构
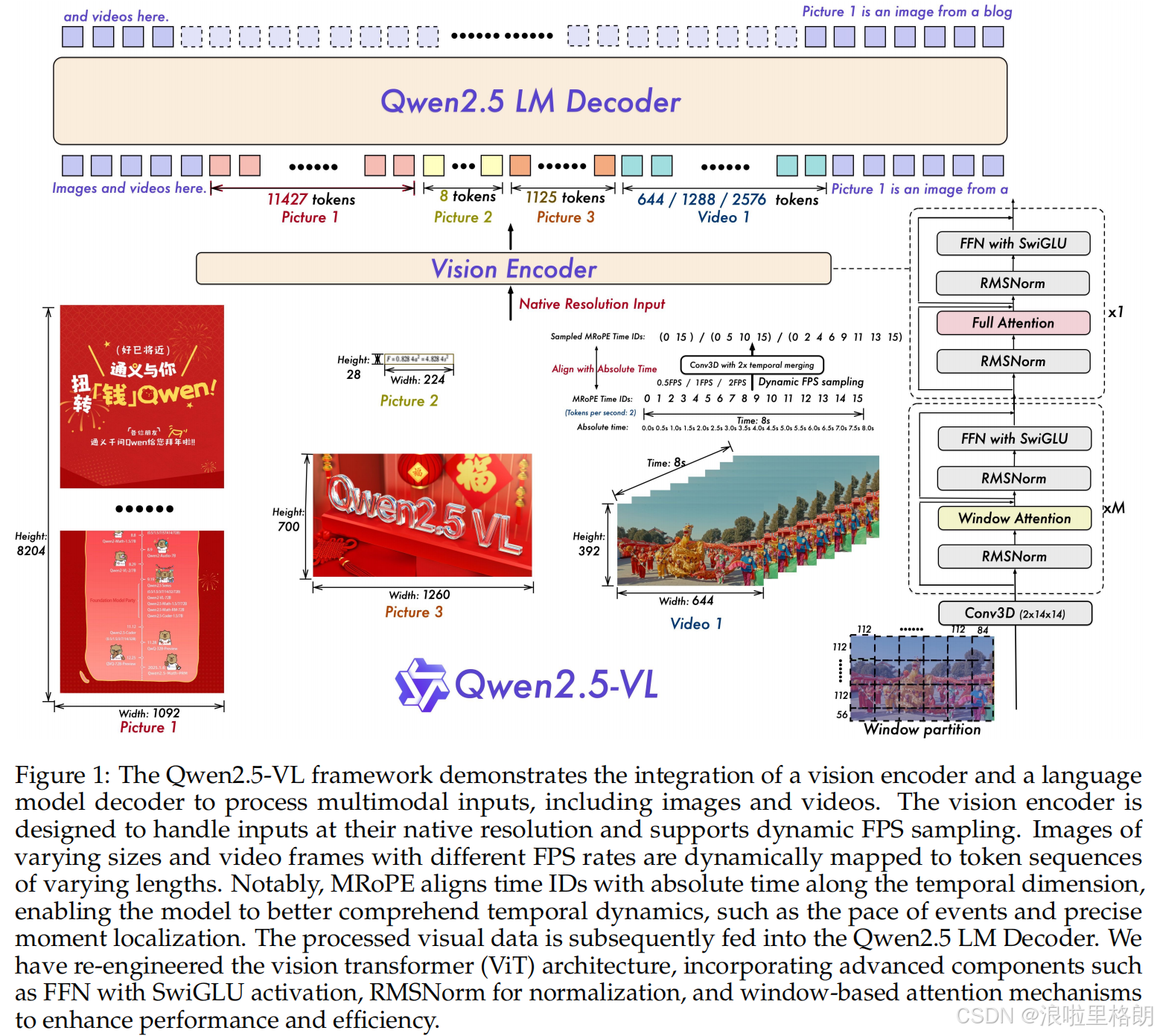
Qwen2.5-VL的整体框架
Figure 1展示了Qwen2.5-VL的整体框架,核心在于体现视觉编码器与语言模型解码器如何协同处理多模态输入。
- 视觉编码器:负责处理图像和视频等视觉输入。它支持以原生分辨率接收输入,并通过动态FPS采样技术,能将不同大小的图像和不同帧率的视频帧动态映射为不同长度的token序列。同时采用了如2D - RoPE(2D Rotary Position Embedding)等技术来编码空间信息,帮助模型更好地理解图像中的空间关系。在处理视频时,还通过将MRoPE(Multimodal Rotary Position Embedding)的时间ID与绝对时间对齐,使得模型能够理解视频中的时间动态,例如事件的节奏和精确时刻定位。处理后的视觉数据会被输入到Qwen2.5语言模型解码器中。
- Qwen2.5语言模型解码器:接收视觉编码器处理后的信息,与文本信息融合,进而生成相应的输出,实现多模态的交互和理解。
Qwen2.5-VL 不同规模模型的架构配置信息
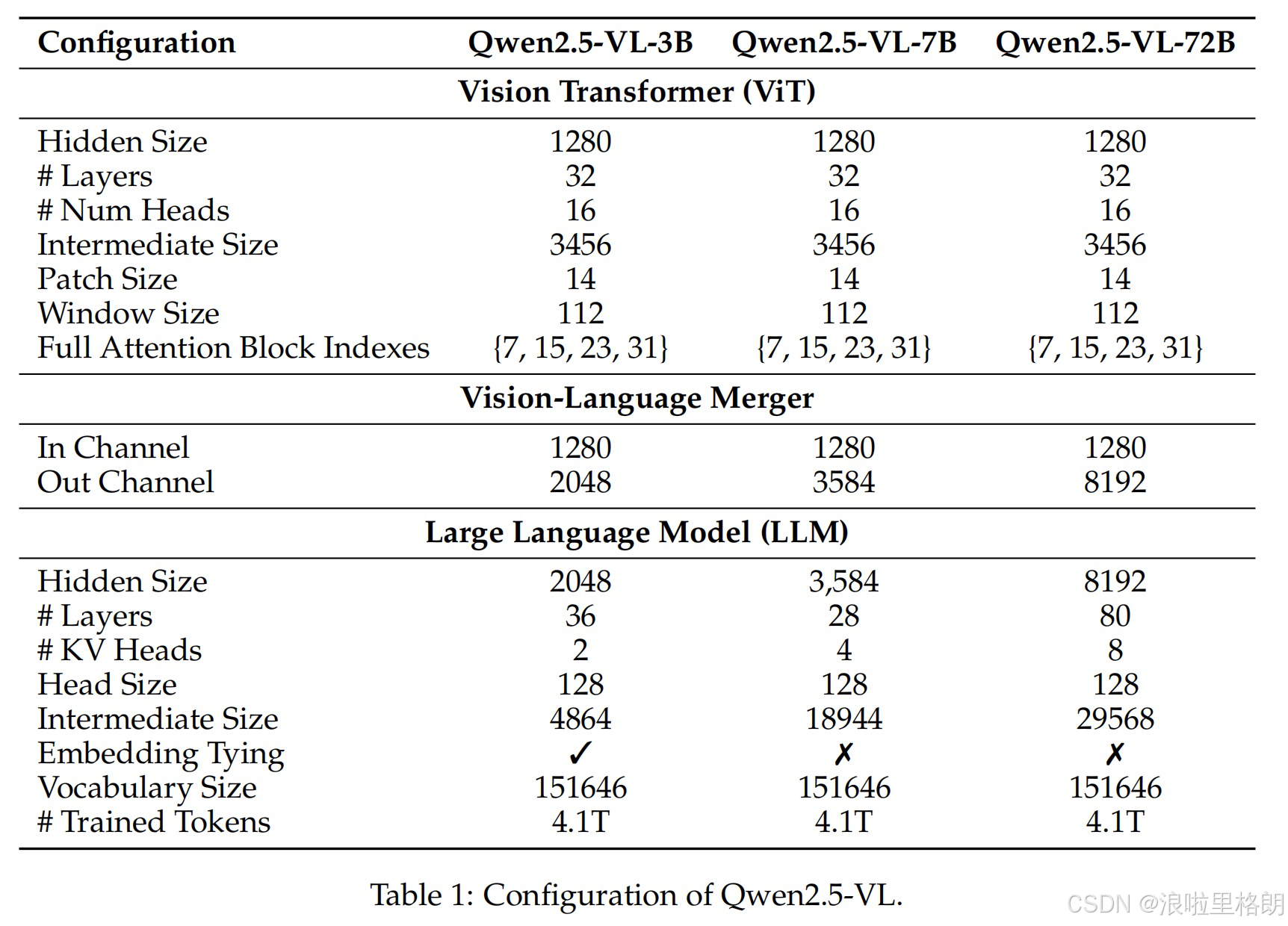
Table 1详细列出了Qwen2.5-VL不同规模模型(Qwen2.5-VL-3B、Qwen2.5-VL-7B、Qwen2.5-VL-72B)的架构配置信息。
- Vision Transformer (ViT)部分
- Hidden Size:三个模型均为1280,代表隐藏层的维度大小,它影响模型的表示能力和计算复杂度。
- # Layers:都为32层,层数决定了模型对视觉数据特征提取的深度和复杂度。
- # Num Heads:均是16头,多头注意力机制能让模型从不同角度捕捉特征信息,提升对复杂数据的理解能力。
- Intermediate Size:均为3456,是多层感知机(MLP)中间层的维度,影响模型的非线性变换能力。
- Patch Size:统一为14,即图像被划分成14×14的小块作为基本处理单元。
- Window Size:都是112,窗口注意力机制中的窗口大小,在提升计算效率的同时,限制了注意力计算的范围。
- Full Attention Block Indexes:三个模型都为{7, 15, 23, 31},表示仅在这四层使用全自注意力机制,其余层使用窗口注意力机制。
- Vision-Language Merger部分
- In Channel:分别为1280、1280、1280,是输入通道数,与ViT输出的特征维度相关。
- Out Channel:分别为2048、3584、8192,是输出通道数,决定了融合后特征的维度,不同规模模型有所差异,以适配不同的语言模型输入要求。
- Large Language Model (LLM)部分
- Hidden Size:不同模型分别为2048、3584、8192,代表语言模型隐藏层的维度,影响语言理解和生成能力。
- # Layers:分别是36、28、80层,层数差异体现了不同模型在语言处理能力和复杂度上的不同。
- # KV Heads:分别为2、4、8,影响注意力机制中关键值的处理,与模型对信息的捕捉和利用能力相关。
- Head Size:均为128,是注意力头的大小,影响每个头对信息的处理精度。
- Intermediate Size:不同模型分别为4864、18944、29568,是语言模型MLP中间层的维度,影响语言模型的表达能力。
- Embedding Tying:Qwen2.5-VL-3B为✓,表示嵌入层共享权重,而Qwen2.5-VL-7B和Qwen2.5-VL-72B为✗,不共享嵌入层权重。
- Vocabulary Size:均为151646,表明三个模型使用相同大小的词汇表。
- # Trained Tokens:均为4.1T,意味着三个模型在训练过程中使用了相同规模的语料。
Qwen2.5-VL的模型结构
Qwen2.5-VL的模型结构主要由三部分组成:
- Large Language Model:以Qwen2.5语言模型为基础,进行了一定的修改,将1D RoPE修改为Multimodal Rotary Position Embedding Aligned to Absolute Time,以更好地适应多模态理解任务,在融合视觉信息和文本信息时发挥关键作用。
- Vision Encoder:采用重新设计的ViT架构,通过融入2D-RoPE和窗口注意力机制,支持原生分辨率输入,在提升计算效率的同时保持对图像细节的捕捉能力。采用RMSNorm进行归一化和SwiGLU作为激活函数,增强计算效率和与语言模型组件的兼容性。在处理视频时,通过独特的3D补丁分区策略和绝对时间编码,有效处理视频数据。
- MLP-based Vision-Language Merger:为解决长序列图像特征带来的效率挑战,该模块将空间上相邻的四个补丁特征分组,然后拼接并通过两层MLP投影到与语言模型文本嵌入对齐的维度,实现视觉特征与语言模型的有效融合,减少计算成本的同时,为语言模型提供合适的视觉信息表示。
数据格式

QwenVL HTML是Qwen2.5-VL用于统一表示文档信息的格式,这种格式确保所有文档元素都能以结构化、易访问的方式呈现,方便模型进行高效处理和理解。具体格式如下:
<html>
<body>
<!-- 段落 -->
<p data-bbox="x1 y1 x2 y2"> content </p>
<!-- 表格 -->
<style>table{id} style</style>
<table data-bbox="x1 y1 x2 y2" class="table{id}"> table content </table>
<!-- 图表 -->
<div class="chart" data-bbox="x1 y1 x2 y2">
<img data-bbox="x1 y1 x2 y2" />
<table> chart content </table>
</div>
<!-- 公式 -->
<div class="formula" data-bbox="x1 y1 x2 y2">
<img data-bbox="x1 y1 x2 y2" />
<div> formula content </div>
</div>
<!-- 图像说明 -->
<div class="image caption" data-bbox="x1 y1 x2 y2">
<img data-bbox="x1 y1 x2 y2" />
<p> image caption </p>
</div>
<!-- 图像OCR -->
<div class="image ocr" data-bbox="x1 y1 x2 y2">
<img data-bbox="x1 y1 x2 y2" />
<p> image ocr </p>
</div>
<!-- 乐谱 -->
<div class="music sheet" format="abc notation" data-bbox="x1 y1 x2 y2">
<img data-bbox="x1 y1 x2 y2" />
<div> music sheet content </div>
</div>
<!-- 化学公式内容 -->
<div class="chemical formula" format="smile" data-bbox="x1 y1 x2 y2">
<img data-bbox="x1 y1 x2 y2" />
<div> chemical formula content </div>
</div>
</body>
</html>
在这个格式中:
- 每个元素都有一个
data-bbox属性:用于记录该元素在文档中的位置坐标(x1, y1, x2, y2),x1、y1 是元素左上角的坐标,x2、y2 是元素右下角的坐标,这有助于模型理解元素的空间位置信息,对文档布局分析和对象定位至关重要。例如,<p data-bbox="x1 y1 x2 y2"> content </p>表示一个段落,data-bbox记录了该段落的位置,使模型能感知其在文档中的具体位置。 - 不同类型的文档元素有各自的标签:如
<p>标签用于段落,<table>标签用于表格,<div class="chart">用于图表等。这种明确的标签体系有助于模型识别和区分不同类型的内容。 - 表格样式和属性:
<style>table{id} style</style>用于定义表格的样式,<table data-bbox="x1 y1 x2 y2" class="table{id}"> table content </table>中的class属性用于指定表格的类别,data-bbox同样记录了表格的位置,table content是表格中的具体内容。 - 复合元素的嵌套结构:对于图表(
<div class="chart">)、公式(<div class="formula">)等复合元素,采用了嵌套结构。例如图表,包含一个图像(<img>)和一个表格(<table>),这种结构可以完整地表示复杂元素的组成部分,方便模型理解其结构和内容。 - 特定格式属性:像乐谱(
<div class="music sheet" format="abc notation" data-bbox="x1 y1 x2 y2">)和化学公式(<div class="chemical formula" format="smile" data-bbox="x1 y1 x2 y2">)的format属性,用于指定其特定的格式,帮助模型更好地处理和解析这些特殊内容。
训练方式
预训练(Pre-training) (对应论文 2.2小节)
- 数据准备
- 数据扩展与来源:预训练数据量从1.2万亿token大幅扩展到约4万亿token,通过清洗原始网络数据、合成数据等方式构建。数据涵盖多种多模态类型,如图像字幕、交错图像文本数据、OCR数据、视觉知识、多模态学术问题、定位数据、文档解析数据、视频描述、视频定位和基于代理的交互数据等。
- 数据处理与筛选:针对交错图像文本数据,因其存在文本 - 图像关联不紧密、噪声多等问题,开发了评分和清洗管道。先进行标准数据清洗,再通过内部评估模型的四阶段评分系统筛选,评分标准包括文本质量、图像 - 文本相关性、信息互补性和信息密度平衡,以确保使用高质量数据。在处理定位数据时,采用基于输入图像实际尺寸的坐标值表示边界框和点,增强模型对物体真实世界尺度和空间关系的捕捉能力,并通过合成多种格式数据、扩充对象类别等方式提升模型在定位任务上的性能。
- 各类数据处理细节:为提升OCR性能,收集合成数据、开源数据和内部采集数据,合成大量图表数据并处理tabular数据;对于视频数据,动态采样FPS,为长视频构建多帧字幕,制定多种时间戳格式;在代理数据方面,收集多平台截图,生成截图字幕和UI元素定位注释,统一操作格式并生成推理过程,提升模型感知和决策能力。
- 训练流程
- 初始化与阶段划分:使用DataComp和内部数据集对视觉编码器(ViT)进行从头训练,以预训练的Qwen2.5语言模型初始化LLM组件。预训练分为三个阶段,每个阶段使用不同数据配置和训练策略。
- 各阶段训练重点:
- 第一阶段,仅训练ViT,利用图像字幕、视觉知识和OCR数据,使其更好地与语言模型对齐;
- 第二阶段,解冻所有模型参数,使用包括交错数据、视觉问答等更复杂的数据集,增强模型处理复杂视觉信息的能力;
- 第三阶段,纳入视频和代理数据,增加序列长度,提升模型对长序列的推理能力。
- 训练效率优化:为应对训练时图像大小和文本长度差异导致的计算负载不平衡问题,根据输入序列长度动态打包数据样本到LLM,第一、二阶段序列长度统一为8192,第三阶段增加到32768,以平衡计算负载并适应模型处理长序列能力的提升。
后训练(Post-training) (对应论文 2.3小节)
- 监督微调(Supervised Fine-Tuning,SFT)
- 数据构建:构建约200万条数据的数据集,纯文本数据和多模态数据各占50%,包括图像 - 文本、视频 - 文本组合。数据主要为中文和英文,含少量多语言内容,涵盖多种对话复杂度和场景,来源包括开源库、购买数据集和在线查询数据。还包含针对不同应用场景的专门子集,如通用视觉问答、图像字幕、数学问题解决等。
- 格式转换与优势:采用ChatML格式组织指令跟随数据,与预训练数据模式不同但保持架构一致性。这种格式可实现多模态对话角色标记、结构化注入视觉嵌入和保留跨模态位置关系,促进知识转移并保持预训练特征的完整性。
- 数据筛选与过滤:实施两阶段数据过滤管道。第一阶段用Qwen2-VL-Instag模型对问答对进行层次分类,分为8个主要领域和30个细粒度子类别;第二阶段采用规则和模型驱动的过滤方法,规则过滤去除重复、不完整或格式错误的条目,模型过滤从多个维度评估问答对,确保高质量数据进入SFT阶段。
- 训练实施:在SFT阶段,模型在多样化的多模态数据上进行微调,包括图像 - 文本对、视频和纯文本,数据来自通用VQA、拒绝采样和专门数据集。
- 直接偏好优化(Direct Preference Optimization,DPO)
- 聚焦数据与目标:DPO阶段专注于图像 - 文本和纯文本数据,利用偏好数据使模型与人类偏好对齐,每个样本仅处理一次以提高优化效率。
- 训练方式:通过对比不同模型生成的回答,根据人类偏好确定奖励信号,优化模型参数,使模型生成更符合人类期望的输出。
- 拒绝采样提升推理能力(Rejection Sampling for Enhanced Reasoning)
- 数据选择与评估:针对需要复杂推理的任务,如数学问题解决、代码生成和特定领域的视觉问答,使用包含真实标注的数据集。用中间版本的Qwen2.5-VL模型评估生成的响应与真实答案的匹配度,仅保留匹配的样本。
- 额外筛选标准:为提高数据质量,排除表现出代码切换、过长或重复模式的响应,确保推理过程清晰连贯。同时开发规则和模型驱动的过滤策略,验证中间推理步骤对视觉信息的整合准确性,但实现模态的完美对齐仍是挑战。
实验结果
Table 3展示了Qwen2.5-VL与当前其他先进模型在多个任务上的性能对比,包括大学水平问题、数学任务、通用视觉问答等方面,具体如下:
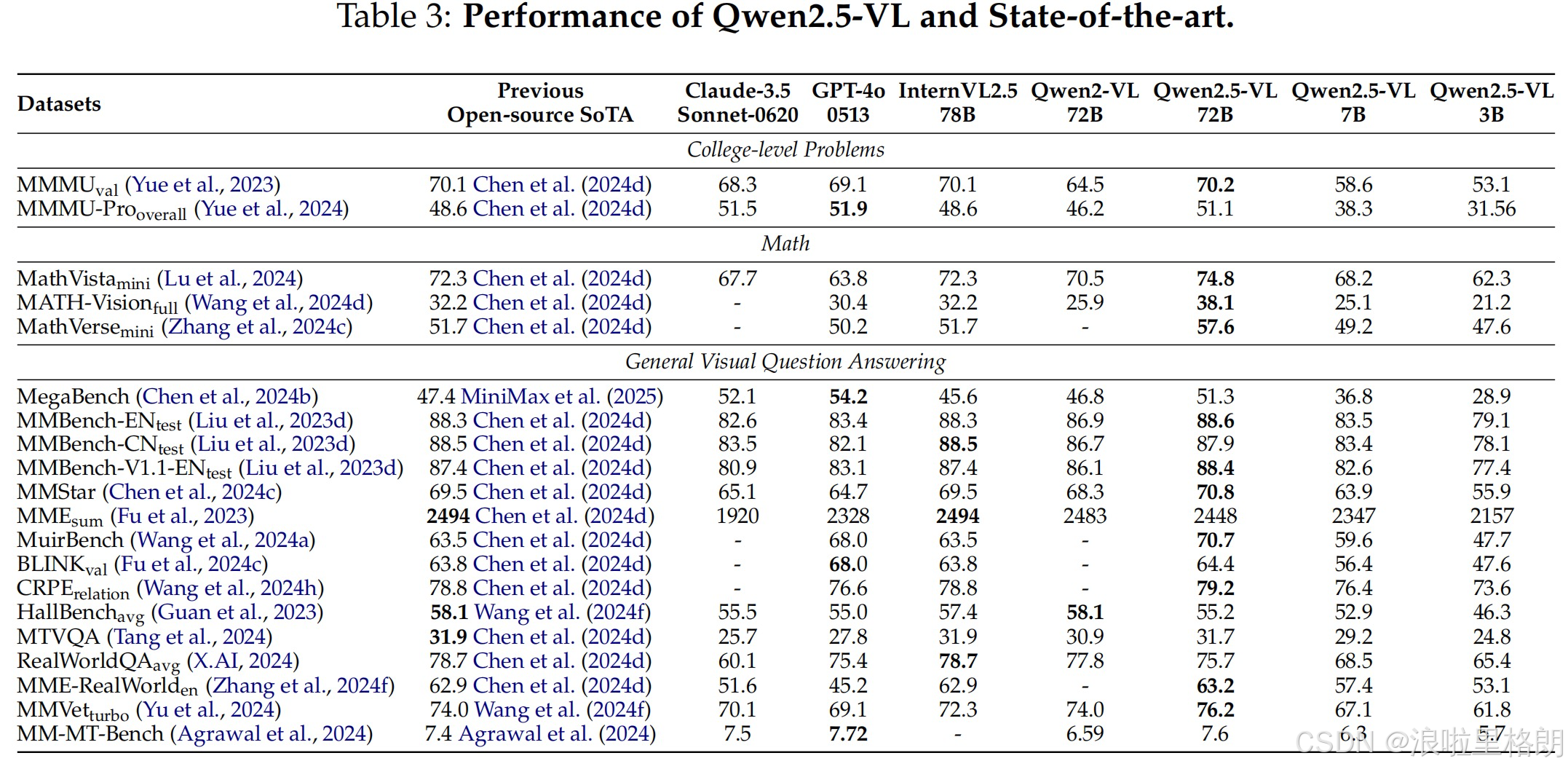
- 对比模型:涉及Claude-3.5 Sonnet-0620、GPT-4o 0513、InternVL2.5 78B、Qwen2-VL 72B等多个当前先进模型,与Qwen2.5-VL的不同版本(72B、7B、3B)进行性能对比。
- 任务及数据集
- 大学水平问题:使用MMMUval和MMMU-Prooverall数据集评估。Qwen2.5-VL-72B在MMMU-Prooverall上得分为51.1,超越之前的开源模型,性能与GPT-4o相当,展示出在综合知识理解方面的优势。
- 数学任务:通过MathVistamini、MATH-Visionfull、MathVersemini等数据集测试。Qwen2.5-VL-72B在MathVista上取得74.8的分数,优于之前开源模型的72.3分,表明其在数学相关的视觉理解和推理任务上能力较强。
- 通用视觉问答:涵盖MegaBench、MMBench系列、MMStar等多个数据集。在MMbench-EN测试中,Qwen2.5-VL-72B取得88.6分,超越此前最好成绩88.3分;在MMStar数据集上,Qwen2.5-VL-72B得分70.8%,领先于其他模型。这体现出该模型在多种视觉问答场景下,对视觉细节的理解和推理能力突出,且在多语言场景下也有良好表现,如在MTVQA测试中,展示了其强大的多语言文本识别能力。
- 整体结论:在大多数任务中,Qwen2.5-VL-72B表现出色,达到或超越了其他对比模型的性能,在一些任务上甚至远超同类模型。即使是较小规模的Qwen2.5-VL-7B和Qwen2.5-VL-3B也展现出了高度的竞争力,表明Qwen2.5-VL的架构具有良好的扩展性和适应性 。
架构演进总结
| 维度 | Qwen VL | Qwen2 VL | Qwen2.5 VL |
|---|---|---|---|
| 分辨率处理 | 固定分辨率(224×224) | 动态分辨率(任意尺寸) | 动态分辨率+坐标映射 |
| 位置编码 | 二维绝对位置编码 | M-RoPE(时空多维度融合) | 动态时间编码+空间坐标映射 |
| 视觉编码器 | ViT-bigG(固定参数) | ViT+MLP压缩(675M参数) | 窗口注意力+RMSNorm/SwiGLU |
| 视频支持 | 20分钟视频理解 | 2帧/秒采样+3D卷积 | 小时级视频+动态FPS训练 |
| 输出能力 | 文本描述/问答 | 多语言OCR/事件定位 | JSON结构化输出/设备操控 |

















 1154
1154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









