







前言
人工神经网络主要根据大脑神经元构建人工神经元,并且按照一定的拓扑结构建立神经元之间的连接,模拟生物神经网络。早期模型强调生物合理性,目前更加强调对认知能力的模拟,完成某种特定任务。
人工神经网络系列博客持续更新。由于本人更喜欢使用Word和Mathtype,所以较多截图。如果我的理解有欠缺或者错误,望指出。
目录
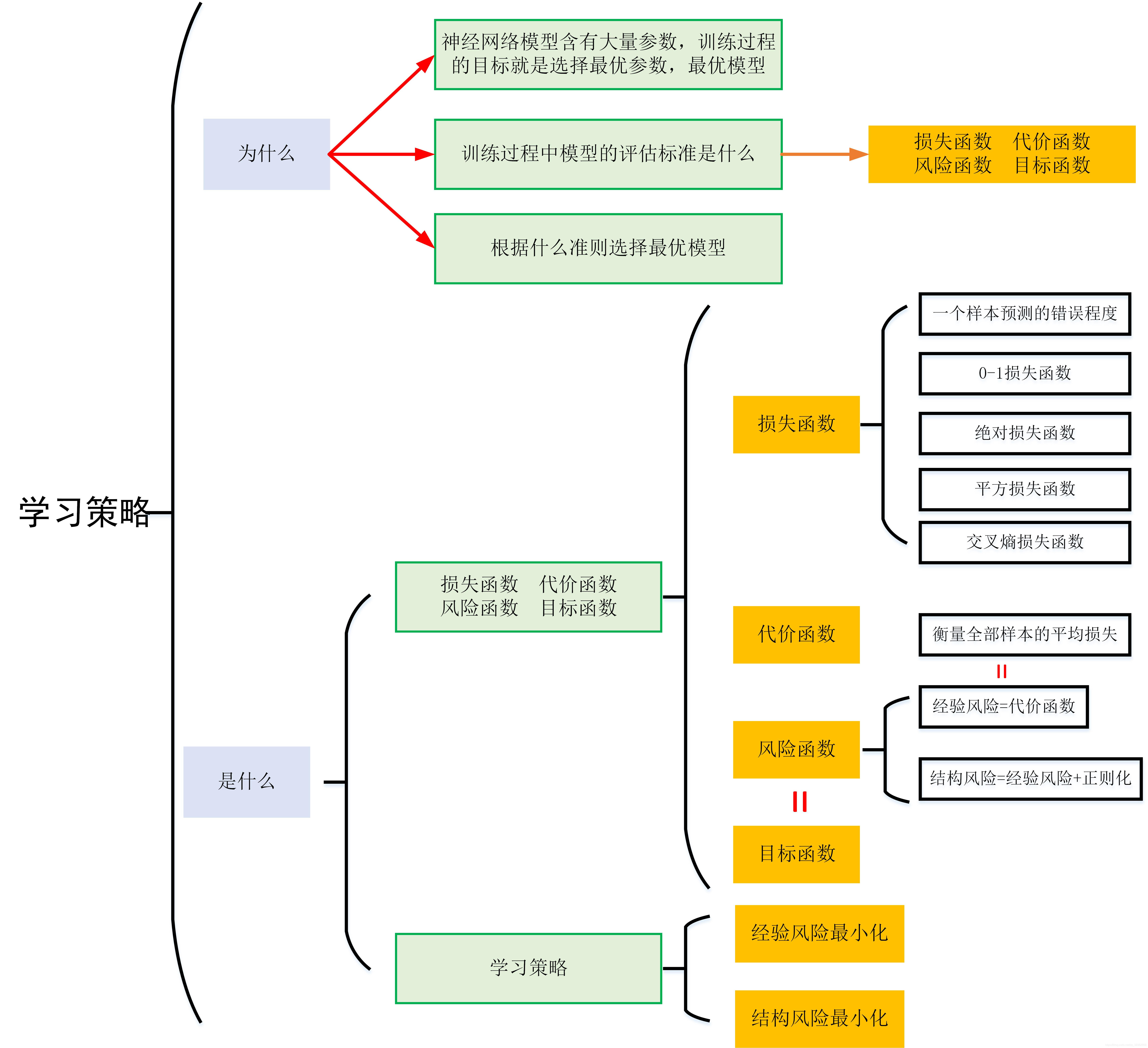
一、为什么需要学习策略
《人工神经网络—理解人工神经元和神经网络》一文介绍了根据生物学领域知识设计人工神经元和人工神经网络,而且我们得知构建的人工神经网络含有大量的参数,包括权重w和阈值b。在网络训练过程中,这些参数取值有成千上万个组合,一个组合对应一个模型,定义模型的集合为假设空间。训练过程的目标就是选择使得模型性能最佳的参数组合或者从假设空间选择最优模型。
(1)训练过程到底按照什么样的准则去学习或者选择?这个准则就是学习策略。
(2)既然要选择最优模型,那么该如何衡量模型的性能呢?度量标准就是损失函数、代价函数、风险函数和目标函数(下文也会介绍四者的区别)。
以背英语单词进行通俗解释,每天需要背一定数目的单词,而且单词要重复一定天数。单词的重复天数和每天背多少个单词为参数,需要进行选择。我们的目标是选择最佳重复天数和每天背单词个数(最优模型)。首先我们要选择度量背单词模型效果的标准,例如看单词意思写单词,看单词写单词意思,上述二者结合,考试或者老师听写。然后我们根据学习策略选择最优的重复天数,比如对的多,错的少,考试分数高或者得到老师表扬。
二、什么是学习策略
2.1 训练过程的模型评估标准
既然要学习最优模型,必须首先定义模型评估的标准,即损失函数、代价函数、风险函数和目标函数。下面对四者进行介绍,以清楚四者的区别和联系:
1、损失函数(loss function):度量模型一次预测的错误程度,例如背单词某天测试的错误程度,和背单词有多种测试方法一样,损失函数也有多种。假设第i个样本的特征为,便签为
,模型为
,则:

交叉熵损失主要用于计算分类问题的损失,以类别分类概率和样本one-hot标签为输入,以损失为输出,因此上式中的表示第i个样本正确类别的分类概率,是softmax函数计算输出的结果。我们希望正确类别分类概率为1,其他类别分类概率为0,与one-hot标签无限接近。由于log函数为单调函数,易于寻找最大值,我们要最大化log(正确类别分类概率),但损失函数衡量错误程度,因此添加负号,而且概率为1时,损失为0,满足最小化损失的要求。
2、代价函数(cost function):度量全部样本的平均损失:
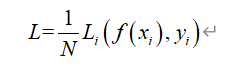
0-1损失函数的代价函数为训练数据集的错误率;平方损失函数的代价函数为均方误差,存在扩大异常值损失的缺点,鲁棒性差,其算术平方根为均方误差;绝对损失函数的的代价函数平均绝对误差;交叉熵损失函数的的代价函数为深度学习尤其分类问题经常使用的代价函数。
3、风险函数(risk function):包括经验风险和结构风险。
(1)经验风险(empirical risk)指的是训练数据集全部样本的平均损失,等同于代价函数。精确衡量数据集全部样本损失的标准应该为期望损失,但是由于无法得知真实的数据分布,所以无法计算期望损失。根据大数定律,当样本数趋向去无穷大,则经验风险和代价函数接近期望风险(概率论知识)。
(2)结构风险(structutal risk):为了防止过拟合(在训练集错误率低,在测试集上错误率高;大家可以查找相关知识了解)而提出。结构风险=经验风险+正则化函数=代价函数+正则化函数(正则化知识,大家可以查找了解)。
式中,J(f)为模型复杂度,用于权衡经验风险和正则化项。
4、目标函数:最终要学习的函数,包括经验风险(代价函数)、结构风险(经验风险+正则化函数,代价函数+正则化函数)。
2.2 学习策略
学习策略就是使得目标函数最小化,包括经验风险最小化和结构风险最小化。
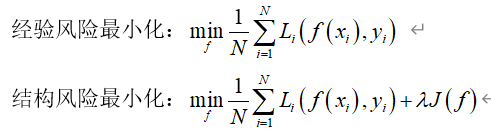
三、如何使用学习策略
深度学习的参数过多,很容易导致过拟合的产生,因此经常使用正则化防止过拟合。在编写网络结构的时候可以设置正则化项,详细可见TensorFlow官网https://tensorflow.google.cn/api_docs/python/tf/keras/regularizers/Regularizer。深度学习更常用Dropout策略防止过拟合。
四、总结
背英语单词模型含有单词的重复天数和每天背多少个单词两个参数(神经网络模型可学习参数),两个参数不同的取值对应不同的模型,因此我们拥有了背单词模型的集合(模型的假设空间),我们的目标是选择最佳重复天数和每天背单词个数(从假设空间选择最优模型)。我们要选择测试我们背单词效果的标准,例如看单词意思写单词,看单词写单词意思,上述二者结合,考试或者老师听写。首先选择每天的测试标准(损失函数衡量模型一次预测的错误程度,包括多种形式:0-1损失、绝对损失、平方损失和交叉熵损失);背单词一天测试结果好不代表真的好,要使用多天的测试结果(代价函数,经验风险衡量训练样本集全部样本的平均损失);重复天数和每天背多少个单词两个参数的选择存在一些问题,如果重复天数过大,每天背单词过多,会导致一天中复习之前单词花费太多精力,没有时间学习今天需要背的单词,不可避免引起测试中对之前单词记得特别清楚,对今天的单词表现不好,因此需要对两个参数的选择进行一些限制(采用策略结构风险=经验风险+正则化=代价函数+正则化项)
强行解释一波,如有不妥或者大家有更好的例子,还请留言。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









