







(论文研读后,感觉有用的一些笔记,主要是给自己记录)
论文:熊雨点,基于深度学习的表单识别系统的研究与实现
基于深度学习的表单识别
前言:
- 一般OCR识别主要分为两个阶段:文本检测与文本识别。 文本检测,通过检测出文档所在的位置信息和坐标信息;文本识别:将文本检测框中的文本值进行识别,得到文本值。
文档检测方法:
基于扩张卷积残差网络的表单文档定位方法:
- 表单文档的定位方法。通过两种网络架构对比与改进,确定采用带扩张卷积的残差网络首先粗定位文档的四个关键点,即左上角点,右上角点,右下角点和左下角点,接着利用这四个点将文档划分为四个区域,再将这四个区域依次送入带扩张卷积的残差网络,以递归的形式一步步地收敛得到准确的角点位置。
相比于自然场景的文字识别,对于图像中任意若干可见文字识别的任务,本文的表单识别是针对特定形式目标表单中的文字识别,所以,首先将目标表单与背景隔离开显得尤为重要。
扩张卷积:
- 扩张卷积,也称为带孔卷积或空洞卷积,是由Yu和Koltun[43]在2015年提出的,其可以大大增加感受野。在卷积神经网络中,确定输出中像素值的输入层区域被称为感受野,越大的感受野可以获得越多的上下文信息。对于扩张率为1的普通卷积,卷积层k∈{1,2…,n}的感受野大小计算公式如下所示。

- 扩张卷积可以理解为间隔着去做卷积操作,相当于把卷积核放大了,这样获得的感受野更大,这将提高CNN的性能。
基于扩张卷积残差网络的表单文档定位
- 表单文档定位的问题被处理为八个特征点的检测-左上角点、右上角点、右下角点、左下角点以及四个中点。通过中点约束来使角点的定位更加准确。以左上角点开始,余下三个点按顺时针方向标记,依次为TL,TR,BR和BL。
- 表单文档定位问题主要分为两个步骤。第一步是使用残差网络定位文档的四个角点,在网络训练优化过程中,通过一级这样的网络想要准确定位出四个角点的位置可能比较困难,此步骤提取的四个角点只是只是大致粗略估计四个角点的位置,所以,第二步依然使用第一步中的网络架构以递归形式细化每个角点。所有图像尺寸在送入网络前被调整为32×32。
- (1)角点检测
- 首先使用扩张卷积残差网络来获得四个预测的角点,即TL,TR,BR和BL。
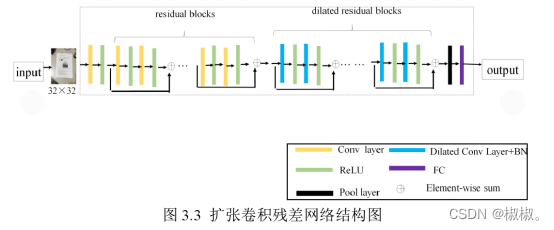
- (2)角点细化
- 在此步中,将四个区域中的每一个区域大小调整为32×32并送入到第一步中使用的残差网络,目的是以递归方式精确定位每一个角点。在每次迭代中,丢弃最不可能包含角落的全分辨率图像的一部分,并将剩余的图像再次发送到同一网络。超参数PF(PreserveFactor)用于量化每次迭代中应丢弃多少图像,PF的值在0和1之间。例如,PF值为0.95,在n次迭代后,尺寸大小为M×N的图像被裁剪为M×(PF)n,N×(PF)n。当图像大小小于12×12时,迭代过程停止。这种裁剪操作和递归网络使我们能够精确地收敛到角落。本文选择PF值为0.95。以左下角区域为例,细化过程如图所示。

文字识别:
-
Tesseract-OCR 和卷积神经网络对文字识别进行了研究,对于 Tesseract-OCR方法,主要介绍了方法步骤,对于卷积神经网络,从网络结构,滤波器的尺寸大小、Dropout技术以及与Gabor特征相结合等方面来对文字进行了识别。
-
OCR(OpticalCharacterRecognition,光学字符识别)是指通过扫描仪或数码相机等电子设备对文本资料进行扫描,然后对文本图像进行分析处理,获取其文字部分并转化为图像信息,再利用文字识别技术将图像信息转化为可以使用的文本的计算机输入技术。它可以快速地将纸质文档数字化,广泛应用于票据识别、表格识别、文案的录入和处理等领域。Tesseract是一个开源的OCR字符图像识别引擎,目前已支持100多种语言,其最先由惠普实验室于1985年开始研发,后来由Google维护与优化,目前已经作为开源项目发布在GoogleProject,其最新版本Tesseract4.0,支持中文识别,并提供了官方训练集以及字符库训练方法,用户可以根据自己的需要去训练所需语言的字符,从而有效地提高识别率。
以 tesseract 3.04为例来训练自己的数据集。
训练集:
- 训练的汉字字符集包含《通用规范汉字表》中收录的一级汉字的3500个常用汉字。
- 首先将要需要的字符图像合并为一个.tif 文件,命名为 chisim.font.exp0.tif,然后再使用命令 tesseract
chisim.font.exp0.tif chisim.font.exp0 -l chi_sim batch.nochop
makebox生成.box 文件,chisim.font.exp0.tif 是上一步生成的.tif
文件名,chisim.font.exp0 表示生成的 Box 文件名。

- Box文件校正:利用jTessBoxEditor工具来校正Box文件。通过运行j Tess Box Ed-itor
下的train.bat来打开工具,打开chisim.font.exp0.tif,可以通过此工具对识别错误的汉字进行校正。 - 定义字体特征文件:创建一个名为font_properties.txt 的字体特征文件:font 0 0 0 0
0,其中font表示自定义的字体名称,后面的0表示字体不是粗体,不是斜体等。 - 产生文字特征文件:使用如下命令:tesseract chisim.font…exp0.tif chisim.font.exp0 box.
train,会生成 chisim.font…exp0.tr 文件和 chisim.font…exp0.txt
文件,tr文件即为字符特征文件。 - 生成字符集文件:使用如下命令:unicharset_extractor
chisim.font…exp0.box,生成uni-charset 字符集文件。 - 生成聚类文件:使用如下命令:shapeclustering -F font_properties.txt -U unicharset chisim.font.exp0.tr 来生成 shapetabel 聚类文件。 使用如下命令:mftraining -F font_properties.txt -U unicharset -O chisim.unicharset
chisim.font.exp0.tr,会生成当前语言的字符集文件chisim.unicharset,同时还会生成 inttemp 文件和 pffmtable 文件,分别表示图形原型文件和每个字符所对应的字符特征数文件,其中 inttemp文件包含了所有需要产生的字的图形原型。 使用如下命令:cntraining chisim.font.exp0.tr 来生成字符形状正常化特征文件normproto。 - 合并:将以上步骤所产生的 unicharset、inttemp、pffmtable、shapetable、normproto 这五个文件前面都加上font,然后使用如下命令 :combine_tessdata
font,生成所需的.traineddata训练集。将此训练集复制到 Tesseract-OCR 安装目录下的 tessdata 文件夹中即可用来识别汉字。
Gabor变换
- 经典的傅里叶(Fourier)变换可以把时域信号转换到频域进行分析是线性系统分析的有力工具,其表达式如公式所示,
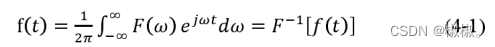
- 从以上定义可以看出,傅里叶变换表示的是信号在整个时域内的积分,因此反映的是信号频率的统计特性,没有对信号进行局部化分析,那么对傅里叶谱中的某一频率,无法知道此频率是在何时产生的。为解决傅里叶变换的局限性,产生了 Gabor 变换,Gabor 变换是通过 Fourier变换提取局部信息,引入了时间局部化的窗函数,得到了窗口 Fourier 变换,又称为加窗短时 Fourier 变换。利用 Gabor 变换可以在频域不同尺度、不同方向上提取相关的特征,Gabor 变换在图像处理方面得到了广泛的应用,在汉字识别上也获得了较好的效果。Gabor 变换表达式如公式4-2所示。
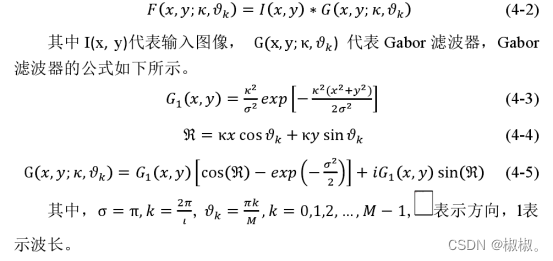
基于 Gabor 与卷积神经网络的文字识别
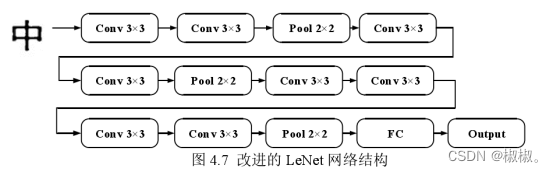
- Le Net 作为经典的 CNN 结构模型,在 MNIST 数据集上的识别率超过了99%。将在LeNet网络结构基础上通过调整网络层数、滤波器个数、卷积核大小,来设计出合适的网络结构,然后再与Gabor特征结合来进一步得到比较好的实验结果。如图所示,在Le Net结构基础上在第三层卷积层后加入一层卷积层,再增加了一个池化层,由此引入了卷积块的概念,即2-3个卷积层连续相连,此网络命名为Hyper-LeNet1。其中网络的输入为 64×64 的二值汉字图。
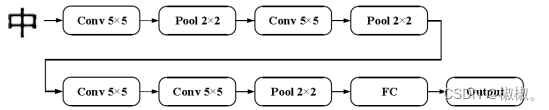
- 首先会通过对上图的网络结果进行改进根据实验结果对比选定合适的网络,然后与Gabor特征进行结合一起送入神经网络进行训练。选取的八个方向Gabor特征分别为0°,22.5°,45°,67.5°,90°, 112.5°,135°,157.5°,波长为4√2,以汉字“中”为例,获得的八个方向特征图如图示。


实验分析:
- (1)将 Hyper-Le Net1与原始Le Net进行对比实验:

-
(2)随着网络层数在一定范围内的增加,网络模型识别率得到提高,Hyper-Le Net1显示出更好的网络性能。
-
为了验证卷积核大小对识别率的影响,将修改卷积核做如下实验。
-
1、将网络中所有卷积核大小改为 3×3,在所有的卷积层后添加激活函数 Re
LU 层,命名网络为 Le Net3×3;
2、将网络中所有卷积核大小改为 7×7,在所有的卷积层后添加激活函数 Re LU层,命名网络为 Le Net7×7;
3、将网络中所有卷积核大小改为 9×9,在所有的卷积层后添加激活函数 Re LU 层,命名网络为Le Net9×9;
4、将卷积层中所有的 5×5 卷积核的卷积核用两个 3×3 的卷积核代替,在所有的卷积层后添加激活函数 Re LU层,命名网络为 Hyper-Le Net2。 -
实验结果如表 4-2 所示。

- 在一定范围内,随着卷积核增大,学习到的特征越丰富,识别率有所提高,而使用2个3×3的卷积核的效果最佳,减少了网络参数的数量,同时在保证具有相同感知野的条件下,也提升了网络的深度,一定程度上提升了网络的效果。同时,小尺寸滤波器需要更多的激活层,所以网络的非线性特征增强,可在一定程度上加快收敛速度。
- 经过多次实验,最终确定使用 3×3 卷积核,并在每一层卷积层后加入 Re LU 层,网络结构图如图 4.7 所示,汉字识别的正确率为
0.9634。
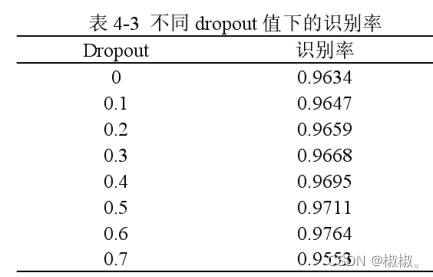
- 为了验证Dropout对网络识别率的影响,接下来将在隐藏层采用Dropout技术,实验结果如表4-3所示。分析可知,在一定范围内,随着dropout值的增大,识别率有所提高,此时的网络可以看作是多个子网络模型的平均结合,减少了网络对某些局部特征的依赖,具有较强的泛化能力。当dropout值大于0.6时,网络性能降低,识别率下降,所以本章采用0.6作为dropout值。
- 多种特征融合的方法更有利于特征的提取[17],接下来将采用Gabor 特征与神经网络学习特征相结合的方法提高了汉字识别率,所以本章将利用
Gabor 提取的特征图与原图一起送入网络训练。实现结果如表4-4所示。

- 由表实验结果可知,Gabor变换有效地反映了汉字不同尺度下的信息,将 Gabor 特征与神经网络学习的特征相融合,有效地提高汉字识别准确率。















 615
615











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











