









主要解决不同域之间的对齐问题
Lc强迫来自两个域的特征去组成鉴别性的cluster
La对齐不同域的相同class的特征
Ly有标签数据的训练
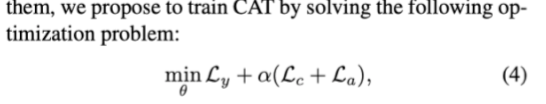
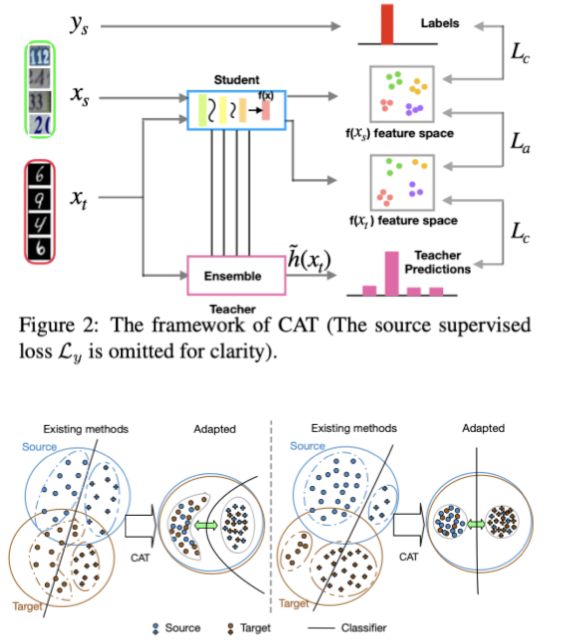
两个域在数据分布等其他特征数据不同时,全局的对齐会造成对齐错误
discriminative clustering loss
对于target domain,label是通过teacher生成的伪标签
使相同类别的样本聚集在一起,同时推远不同类别的样本

对于teacher分类器产生的不正确预测是否会影响模型的训练,作者说,在之前的半监督工作中,已经被证明这种训练方法会有很好的收敛性并且证明了对错误标签的鲁棒性
Cluster alignment via conditional feature matching
当聚类完成后,接下来就开始考虑不同域之间的对齐
由于跨域不匹配,所以训练好的label predictor g可能会失败
因此作者对不同的域进行对齐,来学习域不变性特征,最小化source domain和teacher-annoted target domain对应的cluster之间的差异

取两个域对应cluster的特征的平均值,让这两个平均值特征的尽量靠近

Improved marginal distribution alignment
一开始训练的时候,一部分分类结果更多聚集在分类边界附近,而不是类别中心
作者受brief RevGrad的启发,并提出了更加鲁棒的RevGrad
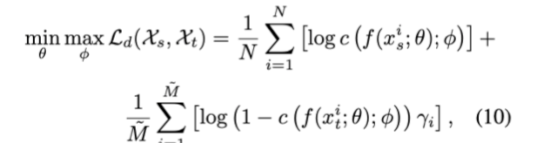
随着两个域之间的差异越来越小,越来越多的目标样本被选择到对抗性训练域中。
这应该是过滤掉置信度低的target样本,随着模型的训练,域差异减小,就会有越来越多的target样本加入到训练中,最终几乎所有的target样本都加入到训练中,避免了target信息的丢失



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









