







动机:
之前的大多都是试图从大规模的视频文本数据集中提取视频的时空特征以及视频和语言之间的多模式交互,作者将在图像语言中预训练的模型迁移到视频文本检索任务中,而之前这种使用这种方式的工作大多都是基于证明这种迁移学习是有效的,以验证CLIP模型在预训练中的效果。作者进一步研究了如何利用已有的显著的图像预训练模型,更好地建模视频帧与视频文本之间的时间依赖性。
由于CLIP模型在图像文本上旨在建模空间关系,而视频相比图像多了时间维度,因此作者进一步提出了TDB和TAB来探索时间关系
Temporal Difference BlockTemporal Difference Block

使用Vit得到帧特征,由于Vit只编码了每一帧的空间信息,作者提出使用一个Lt层的temporal transformer来编码视频特征
将vit的输出拼接起来作为frame tokens,由于两个连续的帧包含的内容会有变化,作者使用temproal difference block来指导temporal transformer编码动作相关的特征
作者使用帧嵌入差的转换来描述两个相邻时间戳之间的动作变化,具体方法是首先计算相邻时间戳之间的特征差,加上位置编码,输入到一个一层的transformer中,然后再接一个sigmoid函数,将其正则化为【-1,1】之间来表示这个动作的变化
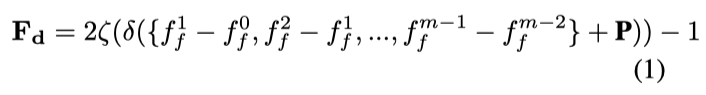
之后,作者将differenceenhanced tokens Fd插入到相邻帧之间

其中P是位置编码,T是类型信息
将Fte输入到temporal transformer中,将输出{ fv0, fv1, fv2, ..., fvm−1}作为最终的视频嵌入,最后,使用全局平均池化来得到最终的视频特征fgv
Temporal Alignment Block
(和t2vlad一样,其实就是全局和局部的对齐)

作者使用CLIP的text encoder来生成文本特征,Ft= { ftcls, ft0, ft1, ..., ftn−1} ,将[cls]的输出ftcls作为文本的全局特征,和视频特征fgv进行全局匹配
受Netvlad的启发,作者提出了一个temporal alignment block通过使用共享的center来聚合不同模态的token嵌入
使用点积来计算模态特征和shared center之间的相似度,为每一个cluster分配不同的权重

其中,pi表示第i个模态特征,cj表示第j个shared center
然后,计算center cj聚合的嵌入对齐
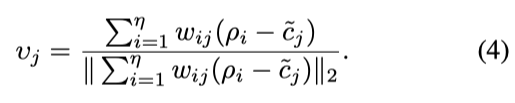
C~j是可训练的权重,和cj有相同的shape
通过上述步骤,可以得到center特征υ = { υ 1, υ 2, ..., υ K},由于视频和文本是通过有相同内容的shared center进行聚合的,因此在联合空间中计算相似度之前就已经完全对齐了
使用更大帧率的特征来得到视频的center特征
为了重新调整动作相关center的权重分布,作者进行了对Ff(应该是vit输出的特征拼接)稀疏采样,隔一帧取一帧,虽然这样会丢失大量的语义信息,但是更加强调了动作的变化,接下来,作者采用一个一层的transformer来关联每个temporal token,得到输出特征Fdl,并将Fdl和Ff进行拼接得到Fml=[Ff, Fdl]
使用Fml得到对齐的视频文本特征

σv and σt表示l2正则化
然后使用全局平均池化层来得到最终的对齐特征fav 和 fat
Loss function
使用对称交叉熵损失函数来进行训练

<f, f>为余弦相似度,使用fg和fa来分别计算
![]()
![]()
Experiments
探索Temporal Difference Block的有效性
直接使用减法插值(TDB-Sub)
使用MLP(TDB-MLP)
difference-level attention (TDB)
在所有输出token上使用全局平均池化(TDB-All)

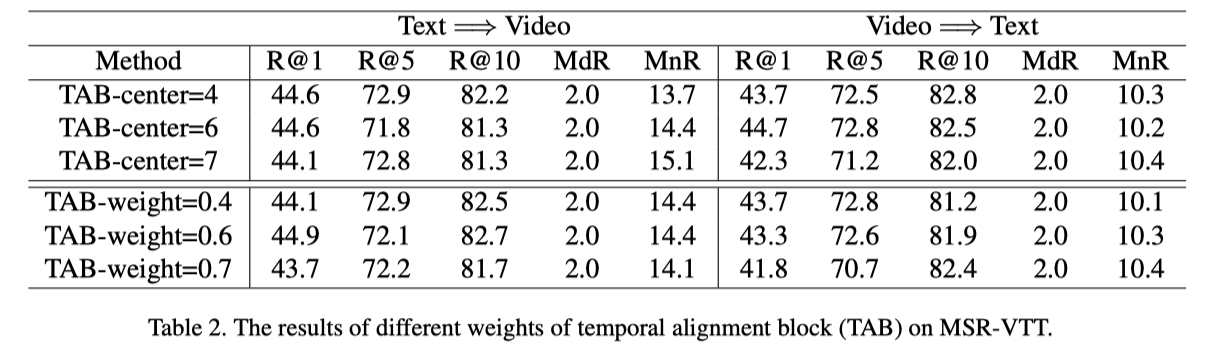
探索Temporal Alignment Block的有效性
应该是直接使用TDB的输出来进行对齐(TDB+TAB-Temporal)
使用帧嵌入作为basic alignment,并添加了额外的稀疏帧嵌入经过transformer(TDB+TAB-Transformer),这种较大帧率的特征将运动的表观变化编码在更少的帧中,重新分配运动相关中心的权重,使其与文本的上下文保持一致。
使用TDB (TDB+TAB-TDB)进一步编码了大帧率特征的时间关系

随着center数量的增加,性能逐渐退化,作者的解释为由于msrvtt视频数量的限制,更多数量的center很难收敛,因此作者对于msrvtt和msvd数据集选择k=5,而vatex相对有更多的视频数量,k=7
作者对loss的权重也进行了实验,
L o= w(L og)+(1−w)L oa, w=0.5更合适
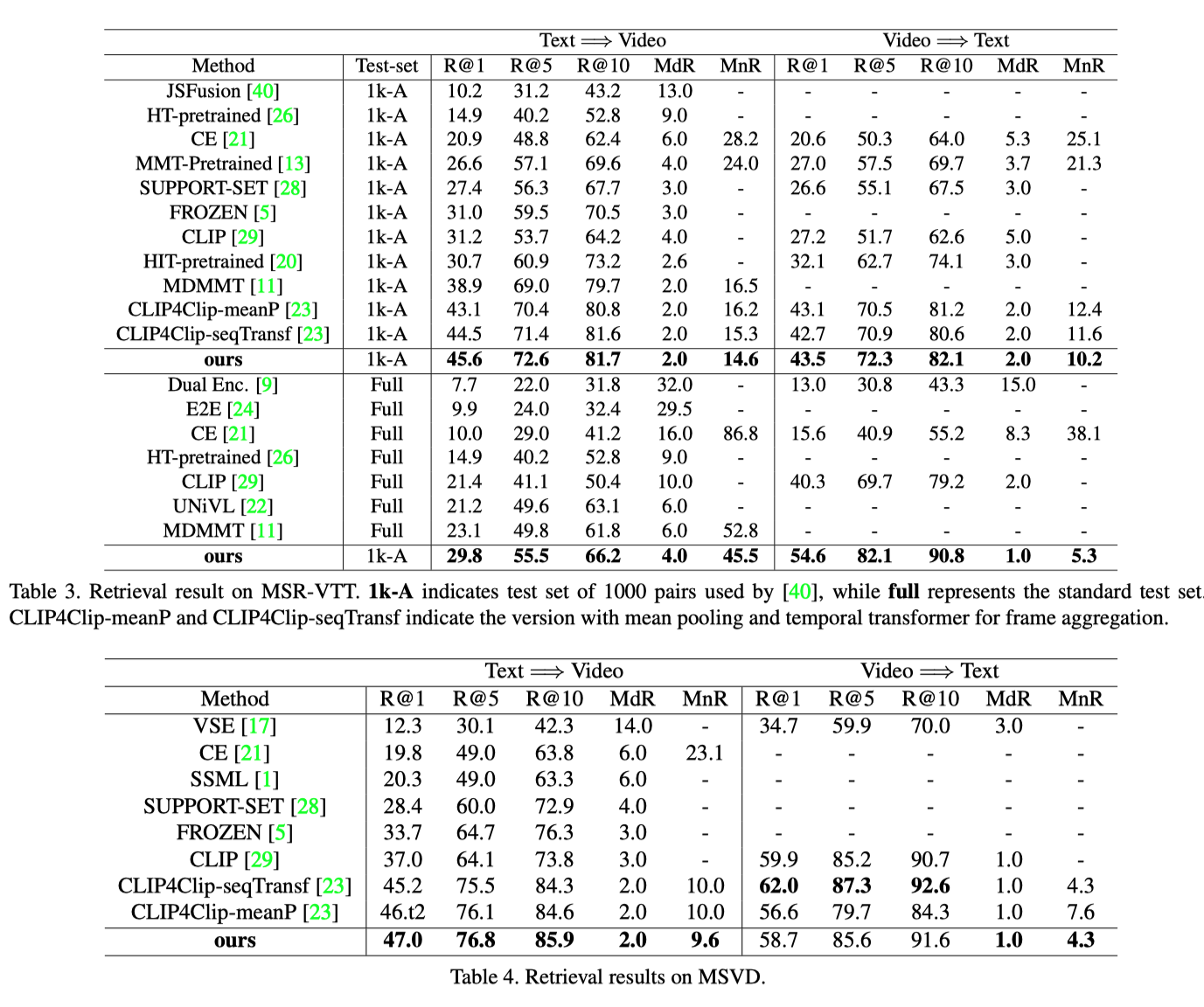
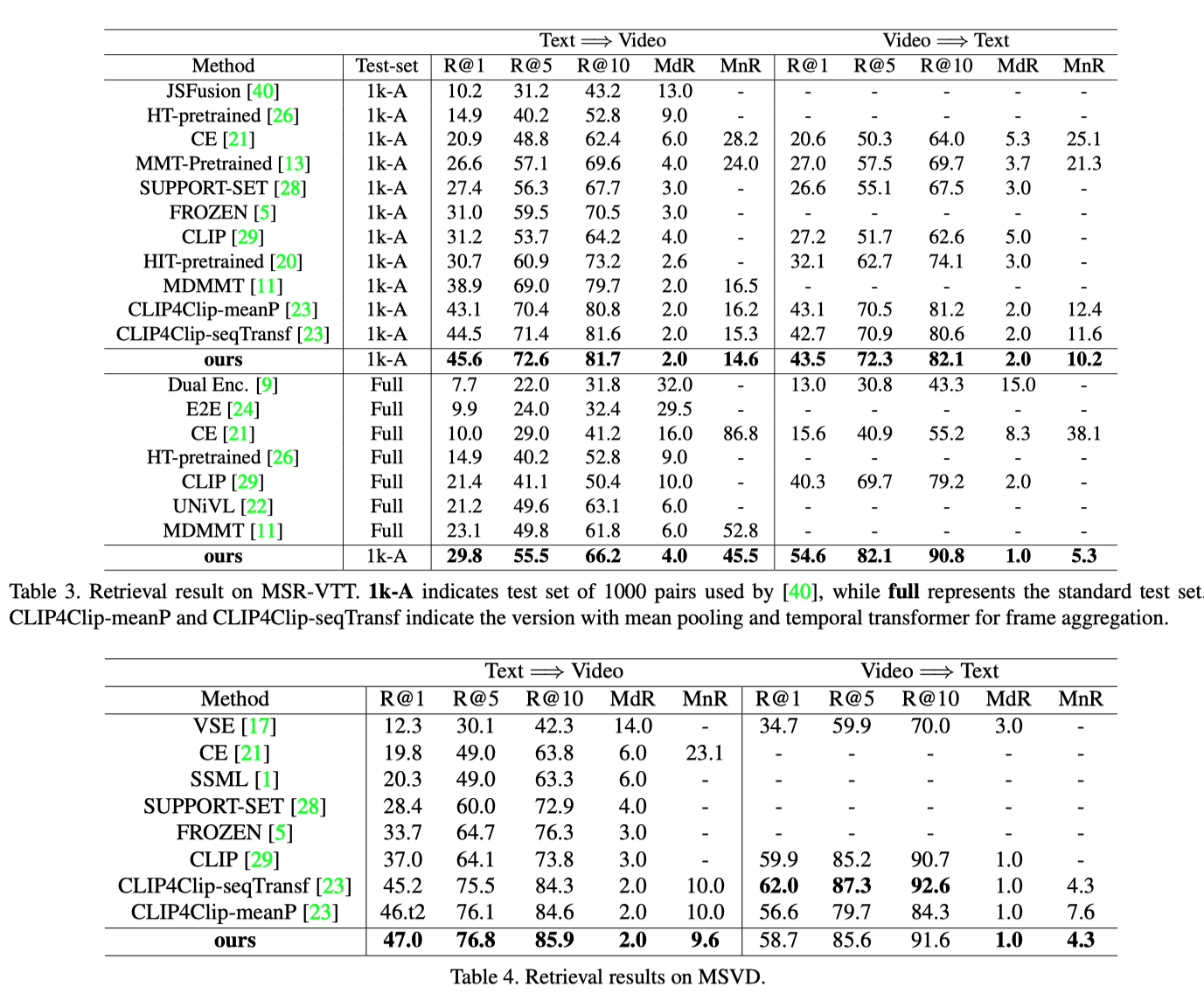
性能对比















 4414
4414











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









