






现在互联网上的可以使用的音视频声音识别文字,基本都是付费或者只有几条免费。所以开发一个工具以实现音频转文字功能,付费?不可能付费!
工具介绍:
- 该工具基于Python编程语言开发,使用了Tkinter库构建了简单直观的用户界面。
- 利用了第三方库如moviepy、pydub、speech_recognition等来处理音视频文件和进行语音识别。
- 利用ppasr自然语言对GoogleAPI返回的文本内容,进行标点符号标记
- 用户可以选择输入待识别的音视频文件目录以及输出转换后文本的目录,并可选择语种和关键词搜索功能。
功能实现:
- 文件支持: 工具支持多种常见音视频格式,音频:'.mp3', '.wav', '.aac', '.m4a', '.ogg', '.amr', '.awb';视频:'.mp4', '.avi', '.mov', '.wmv', '.flv', '.mkv'
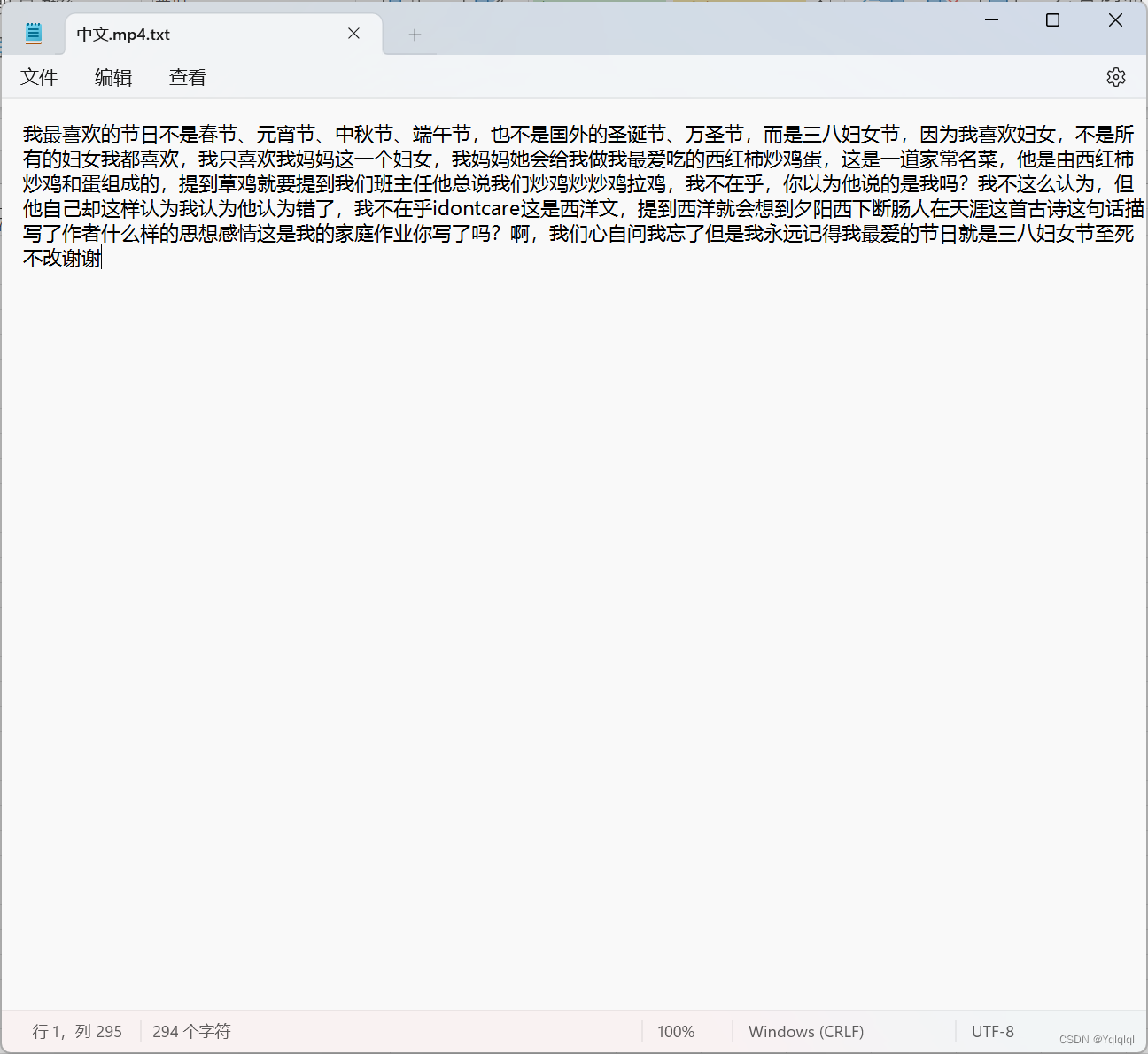
- 语音识别: 使用Google的语音识别API对音频文件进行文本转换,支持语多种种,暂时只测试了中文。
- 关键词搜索: 用户可以输入关键词,在转换后的文本中进行搜索,以便快速找到相关内容。
工作流程:
- 用户选择待识别的音视频文件目录和输出目录。
- 用户可以选择语种和输入关键词(可选)。
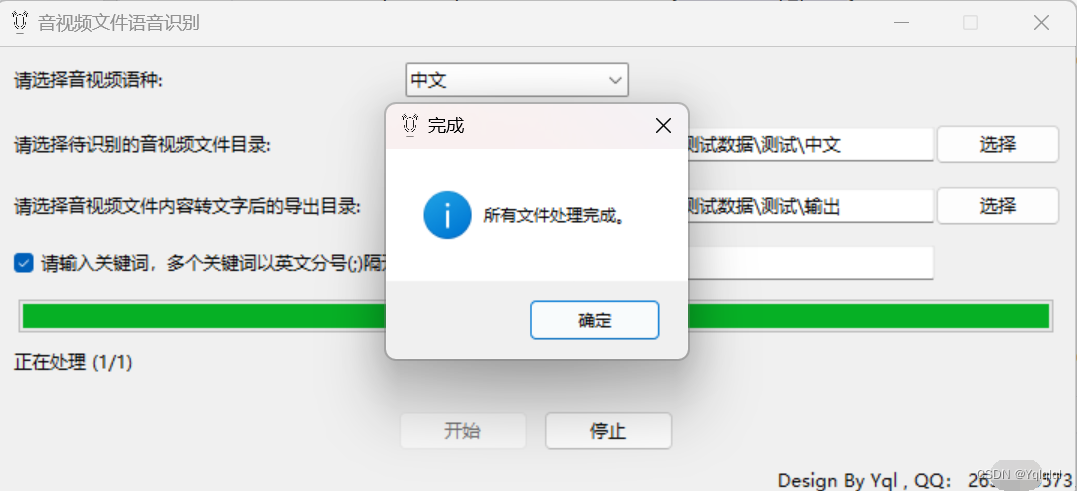
- 用户点击开始按钮,工具开始批量处理音视频文件。
- 工具将音视频文件转换为文本,并保存到指定目录下。
- 如果启用了关键词搜索,工具将在文本中搜索关键词并提取相关信息。
结果预览:
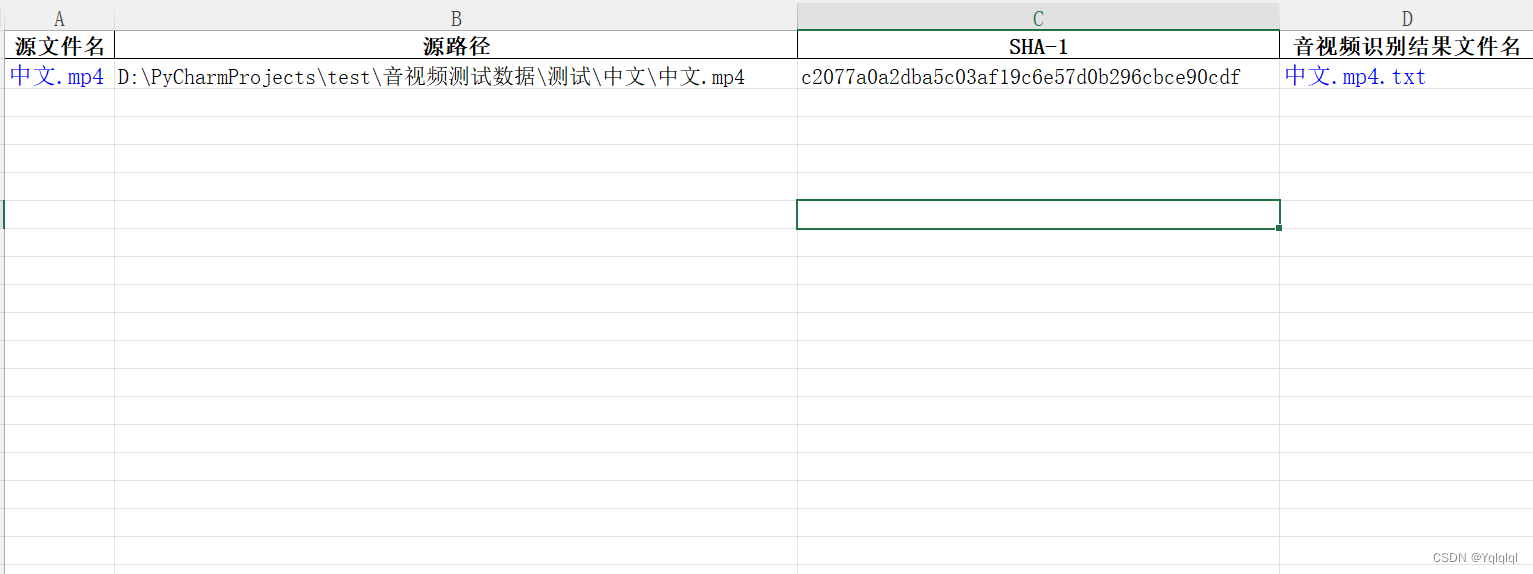
- 工具会生成一个Excel文件,记录了每个音视频文件的处理情况和转换后文本的位置。
- 用户可以通过Excel文件快速查看和定位转换后的文本内容。


















 875
875

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









