







你真的会用join吗?
不知道有多少人会在平常工作中使用MySQL里的join,就我个人而言,从来没有用过,因为join的在MySQL中的应用场景有明显缺陷。假如通过join不同的表,最后用count()、sum()等去做数据统计,一旦数据量上升性能会急剧下降,尤其需要考虑最坏情况下产生笛卡尔积的影响(单表1万行,双表笛卡尔积就超过1亿行了)!
在这种情况下,实时数据分析应该由olap类型的数据仓库ClickHouse、AnalyticDB等来处理以保证性能。非实时情况下,比如报表类等T+1日产出的需求,只需要采用Hive、DataWorks等转存,然后每天统计一次,跑几个小时也没关系。
如果一定要在MySQL中用join
虽然非常不推荐这种做法,但是如果考虑到额外开发成本,我们至少要遵循一些MySQL中使用join的最佳实践:
-
小表驱动大表。小表定义:join相关表按照各自条件过滤,过滤完成后计算参与join的总数据量,量级较小的那个就是“小表”。
-
尽可能用上被驱动表的索引,可以通过explain看下有没有用到索引,这种join方式称为“Index Nested-Loop Join”。而通常笛卡尔积得到的join是“Simple Nested-Loop Join”,MySQL会用内存缓冲区优化,称为“Block Nested-Loop Join”,但是效率仍远不如能利用索引的join。

所以join还能不能用?
join虽然不适合在MySQL中用,但是这并不意味join本身失去作用。join在大数据离线统计中是十分常用的,忽略了响应时间,我们就可以将不同表连接起来而无后顾之忧。我们对于join更应该掌握的是其在数据统计中的灵活运用,由于数据聚合后误差非常难以排查,出错只能逐条记录核对,正确理解join的结果将大大降低排查修复成本。
join怎么用?
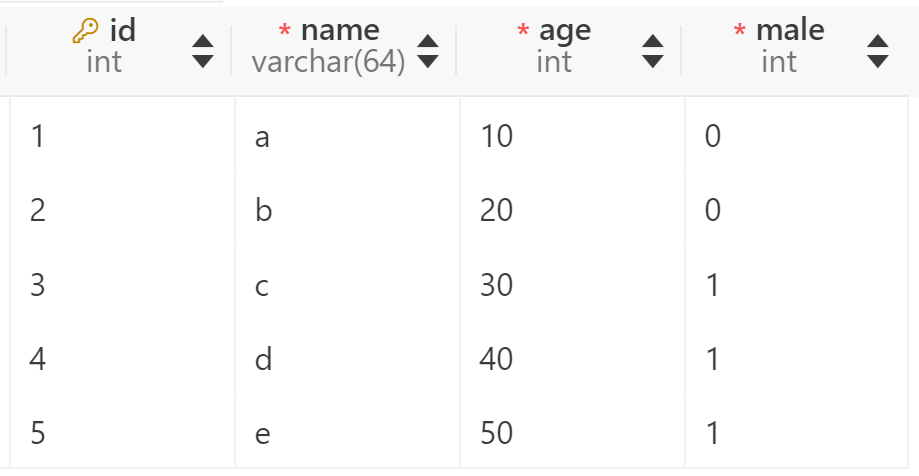
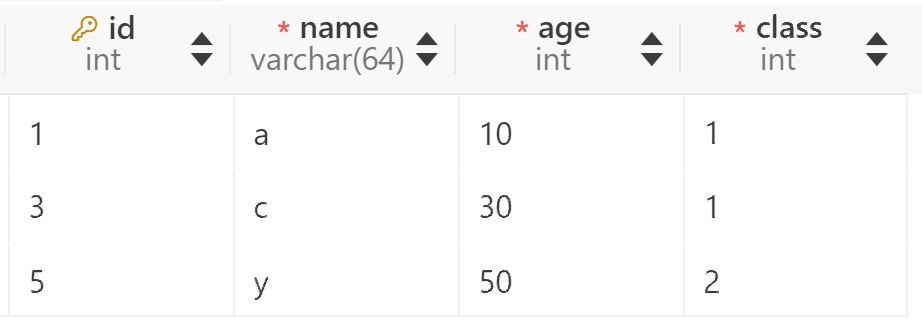
本文以下面两张表为例进行分析:
create table t1 (
id int not null,
name varchar(64) not null,
age int not null,
male int not null,
PRIMARY KEY (id),
key idx_age (age)
) ENGINE=InnoDB;
INSERT INTO t1 VALUES (1, 'a', 10, 0), (2, 'b', 20, 0), (3, 'c', 30, 1), (4, 'd', 40, 1), (5, 'e', 50, 1);
create table t2 (
id int not null,
name varchar(64) not null,
age int not null,
class int not null,
PRIMARY KEY (id),
key idx_age (age)
) ENGINE=InnoDB;
INSERT INTO t2 VALUES (1, 'a', 10, 1), (3, 'c', 30, 1), (5, 'y', 50, 2);
内连接
在MySQL中,JOIN 、 CROSS JOIN 和 INNER JOIN 是语法等价的。在其他数据库的SQL语法标准中,CROSS JOIN 语义可能会有所不同,但各个数据库使用JOIN/INNER JOIN传达的语义都是一样的,而我们通常也就是使用JOIN/INNER JOIN。 JOIN 通常与 ON 子句一起使用,用来过滤不符合条件的数据 。假如我们不添加任何条件,JOIN得到的结果就是笛卡尔积:
SELECT * FROM t1 JOIN t2;
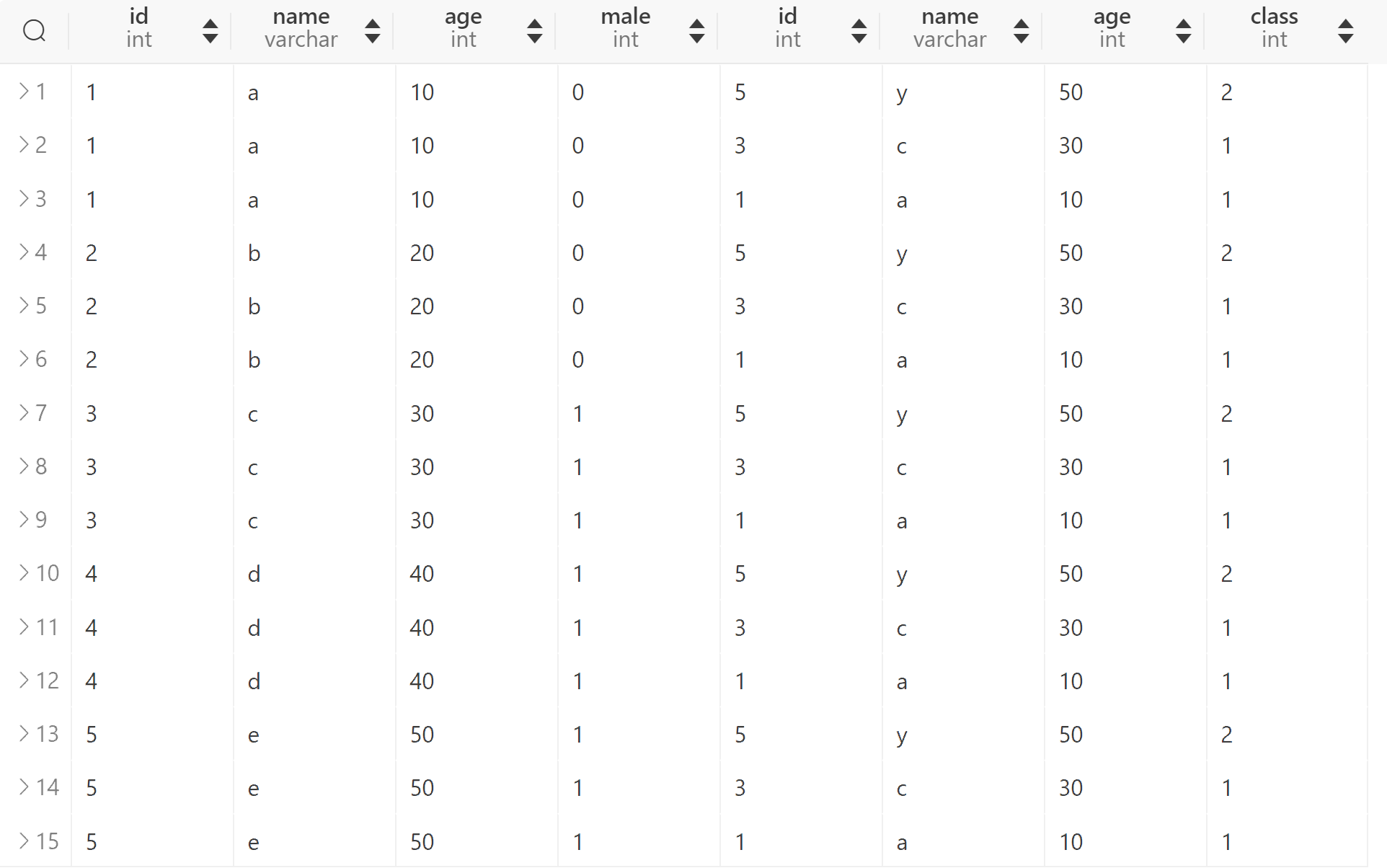
这通常不是我们想要的结果,实际使用中需要通过ON来指定需要等值连接的列。
SELECT * FROM t1 JOIN t2 on t1.id = t2.id;

自然连接
内连接也可以称为等值连接,这是与自然连接区别的一种方式,因为自然连接的结果中同名列只展示一次。其次,自然连接自动匹配所有同名列,所以不需要过滤条件。
即
SELECT * FROM t1 NATURAL JOIN t2;
等价于
SELECT * FROM t1 JOIN t2 on t1.id = t2.id AND t1.name = t2.name AND t1.age = t2.age;
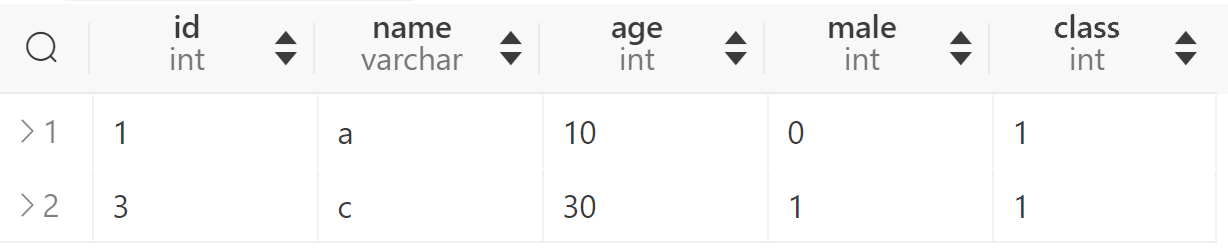
当然最终自然连接会进行去重:
而内连接不会:

实际使用中,我们通常需要明确知道SQL是在干什么以保证数据准确,所以还是尽量避免使用自然连接这种隐式表达的语法。使用内连接能够清晰表明要连接的列,同时列重复对求和、计数等统计也不会产生负面影响。
外连接
外连接是实际大数据离线统计中最常见的连接方式,它与内连接的使用区别也往往是最麻烦的地方,错误使用了外连接或者内连接都会导致统计偏差。左连接和右连接本质是一样的,只不过一个是以左表为驱动表,另一个是以右表为驱动表。在外连接中和内连接类似,OUTER是可以省去的,即LEFT OUTER JOIN等价于LEFT JOIN。下面就以左连接为例。
- 左连接
左连接相比内连接最大的区别就是会保留左表查出来的所有行,如果右表没有对应的匹配记录,则结果集中右表的列全部设为NULL,效果如下:
SELECT * FROM t1 LEFT JOIN t2 ON t1.id = t2.id;
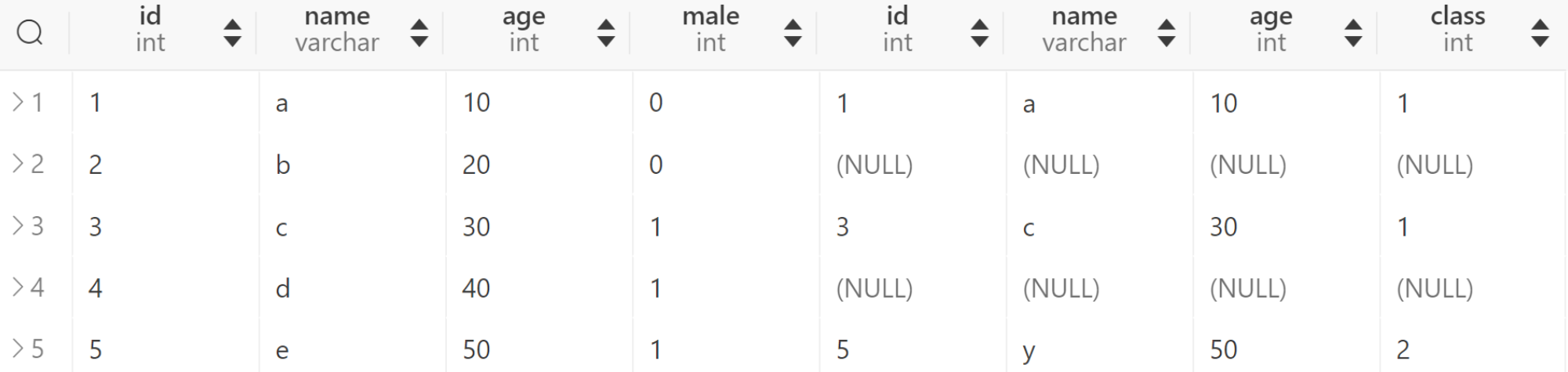
这是一个很重要的特性,在做数据分析的时候,我们需要保证符合条件的主体记录不遗漏。例如我们往往会以符合条件的订单作为左表,此时不管是否能从其他表查到相关的优惠活动明细信息,我们都必须保证结果集中包含每一条符合条件的订单记录,相关优惠信息的列可以为NULL。
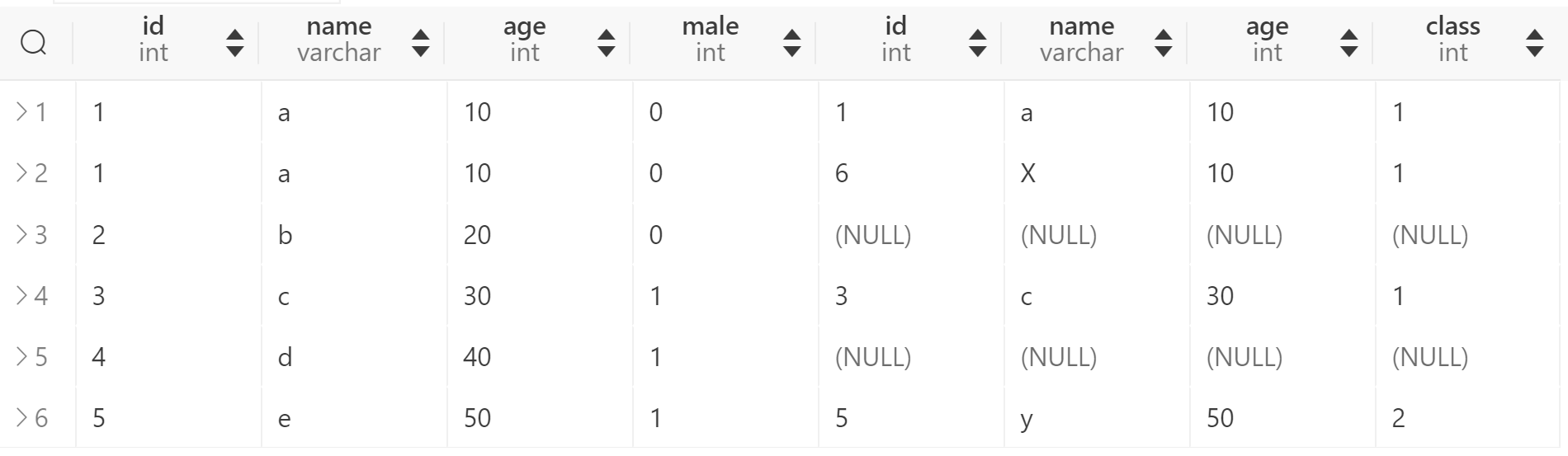
但是,最终结果集的行数只多不少,这是很多人可能会忽略的点。以左表为准,并不代表总数与左表返回的行数丝毫不差,假如右表有符合join条件的N行,那么原来左表返回的一行记录就会存成N行记录。假如我们往t2表再插入一行:
INSERT INTO t2 VALUES (6, 'X', 10, 1);
那么此时根据age来进行join会返回6行记录,这比t1的总行数还要多!
SELECT * FROM t1 LEFT JOIN t2 ON t1.age = t2.age;
- 全外连接
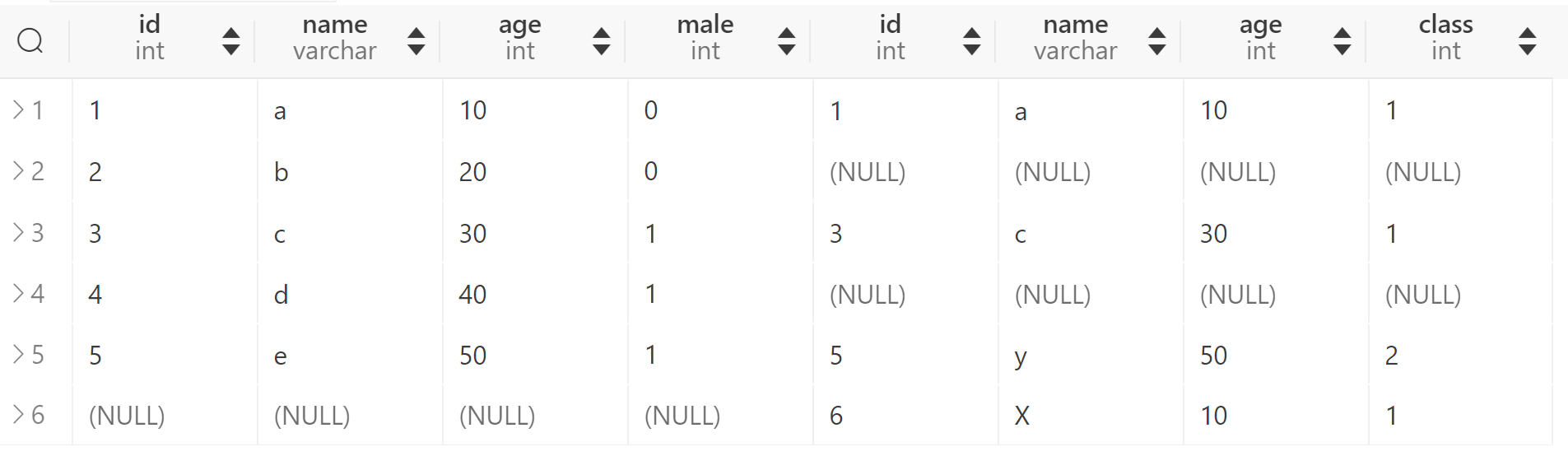
全外连接(FULL OUTER JOIN)并不被MySQL官方支持,但是我们可以通过UNION来模拟其效果,即
SELECT * FROM t1 FULL OUTER JOIN t2 ON t1.id = t2.id;
等价于
SELECT * FROM t1 LEFT JOIN t2 ON t1.id = t2.id
UNION
SELECT * FROM t1 RIGHT JOIN t2 ON t1.id = t2.id;
- 求差集
左外连接还有一个重要的小技巧就是求差集。目前为止,外连接对于驱动表来说都是补充信息的作用。假如我们想要删除信息应该怎么办呢?我们还是可以利用左连接,只不过我们得到结果集之后需要利用WHERE进行一次过滤,得到差集:
SELECT * FROM t1 LEFT JOIN t2 ON t1.id = t2.id WHERE t2.id IS NULL;

这么做的意义是什么呢?一个主要作用就是对左驱动表进行二次过滤,例如我们要找订单完成计费的记录,但是订单完成计费和订单取消计费是两条记录,我们要找出无取消退款的完单计费记录就需要利用左连接求差集。
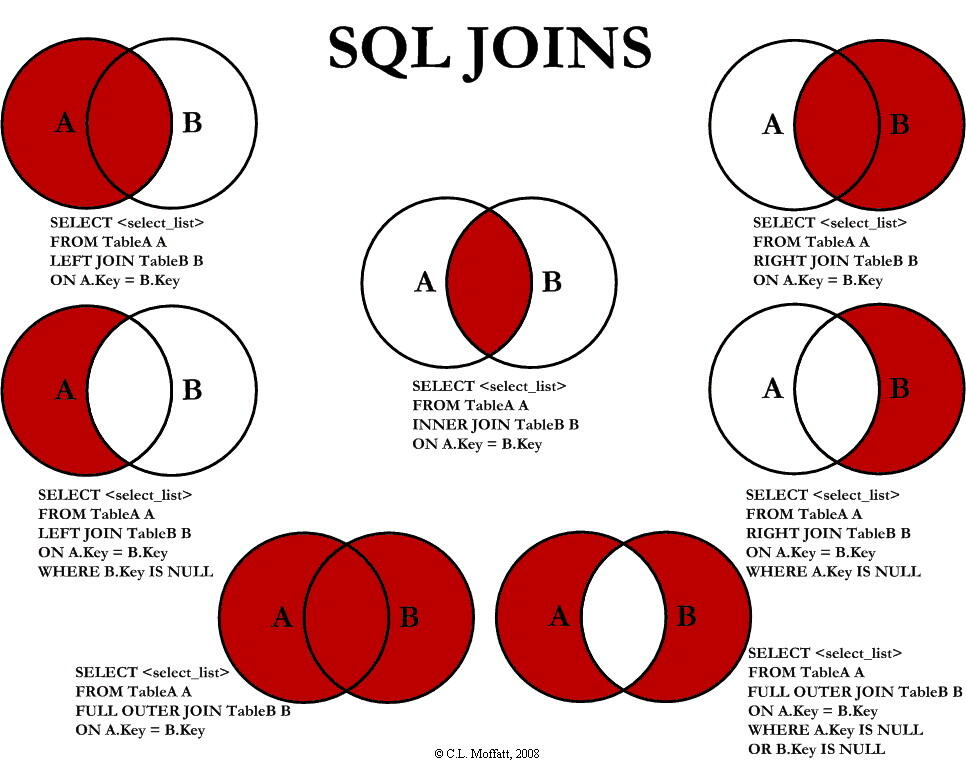
在我实际工作开发中,左连接是最常见的统计方式,因为能够保证主体信息不缺漏,至于从其他表获取的次要信息只是作为补充,而且默认值为MULL并不影响SUM()等聚合函数的统计。最后,我们用一张网络上流传广泛的JOIN示意图作为结尾:















 598
598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









