









 本文提出了一种鲁棒多样化图对比网络(RDGC),通过多视图表示学习和多样性图对比正则化解决不完整多视图聚类中的数据相关性、噪声和视图缺失问题,实验结果显示优于现有方法。
本文提出了一种鲁棒多样化图对比网络(RDGC),通过多视图表示学习和多样性图对比正则化解决不完整多视图聚类中的数据相关性、噪声和视图缺失问题,实验结果显示优于现有方法。
翻译
不完整多视图聚类的鲁棒多样化图对比网络
引用:Xue Z, Du J, Zhu H, et al. Robust diversified graph contrastive network for incomplete multi-view clustering[C]//Proceedings of the 30th ACM International Conference on Multimedia. 2022: 3936-3944.
摘要
不完整多视图聚类是一项具有挑战性的任务,其目的是将没有标签的不完整多视图数据划分为多个类簇。现有的不完整多视图聚类方法忽略了利用数据固有的(内在的)多样性相关性和处理不同视图中包含的噪声。为了解决这个问题,我们提出了一种用于不完整多视图聚类的鲁棒多样化图对比网络(RDGC),它将多视图表示学习和多样化图对比正则化集成到一个统一的框架中。开发了多视图统一的特定编码网络,将不同的视图融合成统一的表示,可以灵活地估计不完整多视图数据的视图重要性。提出了一种鲁棒的多样化图对比正则化方法,通过捕获多样化的数据相关性来提高学习表示的判别能力,减少视图缺失问题带来的信息损失。此外,我们的方法通过利用鲁棒性对比学习损失,有效地抵抗噪声和不可靠视图的影响。在四个多视图聚类数据集上进行的大量实验表明,我们的方法优于最先进的方法。
引言
多媒体数据通常可以从多个角度来描述。例如,图像的内容可以通过不同的视觉特征或周围的文本来描述。网页可以通过文本、图像和超链接来描述。由于每个视图都包含一些唯一的数据描述,因此不同的视图通常是相互补充的。多视图聚类旨在利用不同视图的互补性,将相似的数据划分为同一组,已成为多媒体数据分析和机器学习领域的重要研究课题。
传统的多视图聚类方法假设数据是完整的,即每个样本在所有视图中都具有完整的特征。然而,在许多实际应用中,由于一些不可控因素导致数据丢失部分视图,导致多视图数据不完整的情况非常普遍。为了利用有限的和不完整的多视图特征进行聚类,提出了不完整的多视图聚类方法。一些IMC方法采用矩阵或张量分解[13,32,36,40]补全视图确实特征,然后聚类。图学习是对异构多视图特征建模并实现数据聚类的另一种重要方法[3,10,43]。此外,一些基于深度学习的IMC方法通过学习不完整多视图数据的高层表示进行聚类[26,29,37,39]。最近,对比学习由于其强大的自监督表示学习能力被应用到多视图聚类中[14,20],并取得了很好的聚类性能。
虽然已经提出了多种IMC方法,但仍有一些关键问题没有得到很好的解决。首先,多视图数据包含丰富的结构相关性,如视图内相关性、视图间相关性和类别相关性。现有的IMC方法未能共同利用这种多样化的相关性来增强数据表示,减少视图缺失问题带来的信息丢失的影响。其次,多视图数据通常包含一些噪声,并且视图的可靠性不同。现有的方法大多忽略了噪声样本和不可靠视图的影响。第三,多视图表示学习和聚类是两个密切相关的任务。适当的数据表示可以促进数据聚类,聚类结果是表示学习的有效指导。现有的IMC方法很少考虑这两个任务的相关性,因此这些方法的性能可能受到限制。
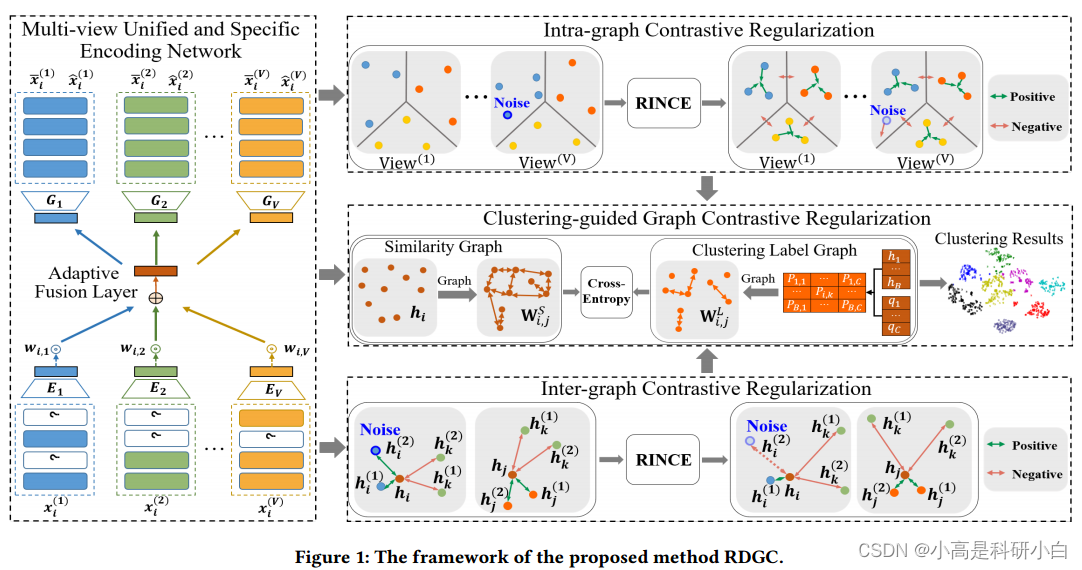
为了解决上述问题,我们提出了一种用于不完整多视图聚类的鲁棒多样化图对比网络RDGC。RDGC是一种新颖的深度IMC框架,它将多视图表示学习和鲁棒多样化图对比正则化相结合,从而获得更具判别性的多视图表示和有效的聚类结果。RDGC的框架如图1所示。多视图表示学习是通过多视图统一的特定编码网络来实现的,该编码网络可以准确地捕获不同视图的共享信息和唯一信息。多样化图对比正则化包括图内对比正则化、图间对比正则化和聚类引导图对比正则化。它可以利用多视图数据所固有的多样化的相关性,减少由于视图缺失问题而造成的信息丢失。引入鲁棒对比学习损失来处理噪声样本和不可靠视图。并将多视图表示学习与数据聚类结合起来,使两者相互促进。在四个数据集上的大量实验表明,RDGC显著优于其他竞争性聚类方法。
本文的主要贡献总结如下:
(1)在多视图统一和特定编码网络中引入自适应融合层,以获得不完整多视图数据的有效表示。我们的方法可以准确地评估不同观点的重要性,以抵抗不可靠观点和不完整观点的影响。
(2)我们提出了一种鲁棒的多样化图对比正则化方法,以捕获丰富的多视图相关性,并抵抗噪声和不可靠视图。该方法可以有效地减少视图缺失问题带来的信息丢失的影响,产生更具判别性的多视图表示.
(3)我们提出了一种聚类引导图对比正则化方法,它将多视图表示学习和数据聚类结合起来,使两者相互促进,获得更好的聚类性能。
相关工作
近年来,人们提出了多种从不完全多视图数据中发现聚类的IMC方法。一些IMC方法是基于矩阵或张量分解。部分多视图聚类[11]建立了一个潜在空间,其中对应于同一实例的嵌入表示彼此接近。使用低秩矩阵或张量学习模型来补全缺失的视图,探索视图的完整信息[15,28,32,35]。DAIMC采用实例对齐信息学习所有视图的通用潜在矩阵,然后借助𝐿2,1范数正则化回归建立一致性基矩阵,以减少缺失实例的影响[5]。CLIMC[15]结合自表示、索引矩阵和一致性项来学习一致性相似图,并进一步用于探索底层的多视图数据关系。多图学习和多核学习是另一种常见的IMC方法。谱聚类旨在最大化所有视图的融合结果。[10]提出了一种联合划分和图学习方法来揭示数据结构并学习一致性图矩阵。[18]提出了带不完整核的多核k-means算法,将核输入和聚类集成到一个统一的框架中。[17]提出了一种后期融合不完全多视图聚类方法,用于对不完全视图生成的不完整聚类矩阵进行整合。EE-IMVC[16]将不完整视图生成的每个不完整基矩阵用一致聚类矩阵进行归算,并通过先验知识进一步正则化。IMVC[27]是一个基于二部图模型的不完全大规模多视图聚类框架。与基于矩阵分解的IMC方法相比,基于多图/核学习的IMC方法能够挖掘多视图数据的内在结构,获得更好的聚类性能。
以上方法主要基于浅层模型。由于深度学习在抽象表示提取和复杂数据聚类方面的强大能力,越来越多的基于深度IMC方法被提出。深度自编码器和图结构保持被用于学习多视图聚类的有效数据表示[29,31,37]。一些IMC方法[25,26,33]采用生成式对抗网络在已有视图的基础上生成缺失视图。近年来,对比学习[2,12,42]已成为无监督学习和多视图聚类的研究热点。一些多视图聚类方法[22,34]利用对比学习来预测聚类分配。提出了多视图对比图聚类[20],通过对比学习共同学习节点的一致性表示和一致性图。[14]提出了一种集表示学习和数据恢复于一体的IMC统一框架,该框架采用对比学习的方法最大化不同视图间的互信息。需要注意的是,对比学习受数据中所含噪声的影响,只能得到次优解。因此,一些鲁棒对比学习方法被开发出来[4,38],以减轻有噪声样本的影响,进一步提高了对比学习的适用性,取得了令人满意的聚类性能。
方法
Notation and Preliminary

给定具有V视图和N样本的多视图数据,它们可以表示为(见上图)。其中,x_(𝑣)∈𝑅^𝑚_𝑣为𝑣-th视图中𝑖-th样本的特征。对于不完整的多视图数据,我们采用一个指标矩阵I∈𝑅操作向量来记录缺失的样本。I= 1表示𝑖-th样本存在于𝑗-th视图中,I= 0表示𝑖-th样本不存在于𝑗-th视图中。对于缺失的特征,例如I ω,𝑗= 0,对应的特征向量x(𝑗)ω用零填充。我们假设每个样本不会缺失所有视图中的特征。设Mi和M𝑗分别表示矩阵M的𝑖-th行和𝑗-th列。不完整多视图聚类的目的是在不使用任何标签信息的情况下,将不完整的多视图数据样本划分为几个变量。
传统的对比学习方法容易受到不相关样本对等噪声的影响,往往导致只获得伪相关或平凡解的次优解。为了解决这一问题,最近提出了鲁棒信息集(Robust InfoNCE, RINCE)[4],它可以被视为一种广义的对比学习形式。RINCE的对称特性为调整样本重要性以减轻噪声的影响提供了一种有效的方法,特别是对于没有明显共享信息的假阳性对。理论分析表明,RINCE是WDM (Wassersein Dependency Measure)[19]在噪声环境下的下界,WDM能够捕捉特征空间的内在结构,对噪声的鲁棒性优于KL散度。因此,RINCE具有很强的理论依据和抗噪声保证。RINCE的损失函数表示为:
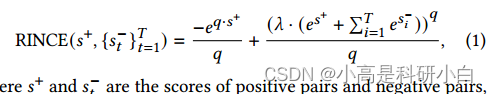
其中𝑠+和𝑠−分别是正对和负对的分数。𝑞,∈(0,1)。𝑞是用来平衡对称性的。当𝑞→1时,RINCE成为完全满足对称性的对比损失。在𝑞→0的极限下,RINCE渐近等价于InfoNCE[23]。
是一个权重参数,用于控制正对和负对之间的比率。
Multi-view Unified and Specific Encoding Network
由于视图的统计性质不同,并且存在视图缺失问题,因此如何对不完整的多视图数据进行正确的表示是一项具有挑战性的任务。请注意,有些信息在多个视图之间共享,而有些信息对每个视图来说是唯一的。为此,提出了一种多视图统一和特定的编码网络,学习统一和特定于视图的数据表示,分别捕获视图的共享信息和唯一信息。具体来说,该网络由编码器和解码器组成。编码器提取特定于视图的表示并将它们融合到统一的表示中。提出了一种自适应融合层来学习统一的表示,可以评估视图的重要性以抵抗不可靠的或缺失视图的影响。解码器的目标是通过使用特定视图表示和统一表示来重构多视图数据。通过最小化重构损失,多视图统一、特定于视图的编码网络可以准确捕获多视图数据的共享和唯一信息。
对于编码器网络{E𝑣}𝑣=1,每个𝑣通过 学习𝑣-th视图的特定于视图的表示。为了使不同的视图具有可比性,每个视图的特定于视图的表示共享相同的维度h(𝑣)∈R𝑘。然后,引入自适应融合层,将特定于视图的表示融合到统一表示中。自适应融合层能够区分融合过程中不同视图的重要性,以抵御不可靠视图的影响。形式化表示为:
学习𝑣-th视图的特定于视图的表示。为了使不同的视图具有可比性,每个视图的特定于视图的表示共享相同的维度h(𝑣)∈R𝑘。然后,引入自适应融合层,将特定于视图的表示融合到统一表示中。自适应融合层能够区分融合过程中不同视图的重要性,以抵御不可靠视图的影响。形式化表示为:
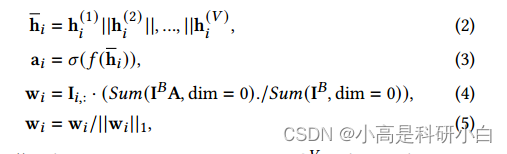
 通过自适应融合层,对不同的视图赋予不同的权重。重要的视图可以被赋予更高的权重,不可靠的视图可以被赋予更低的权重,缺失视图的权重为零。此外,通过对批内所有权值进行平均得到融合权值,可以获得更稳健的权值估计。因此,所提出的自适应融合层能够灵活地处理不完整的多视图数据,并能准确地捕获多视图互补信息。第𝑖-th样本的统一表示形式化为:
通过自适应融合层,对不同的视图赋予不同的权重。重要的视图可以被赋予更高的权重,不可靠的视图可以被赋予更低的权重,缺失视图的权重为零。此外,通过对批内所有权值进行平均得到融合权值,可以获得更稳健的权值估计。因此,所提出的自适应融合层能够灵活地处理不完整的多视图数据,并能准确地捕获多视图互补信息。第𝑖-th样本的统一表示形式化为:

解码器网络{𝐺}的目的是重建原始数据。为了保证学习到的潜在表示能很好地编码多视图信息,采用了统一表示和特定视图表示两种方法进行数据重构。统一表示重构的数据和特定视图表示重构的数据分别用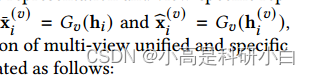 表示。多视图统一特定编码网络的损失函数公式为
表示。多视图统一特定编码网络的损失函数公式为
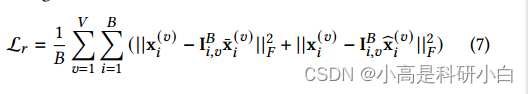
Intra-graph Contrastive Regularization
图内对比正则化:多视图数据包含丰富的局部结构相关性,可以用来提高潜在表示的判别能力。图内对比正则化的目标是为每个视图构建一个最近邻图,以模拟该视图内的局部结构相关性。将最近邻设置为正对,非最近邻设置为负对进行对比学习。具体地说,如果h(𝑣)i和h(𝑣)𝑗是邻居,我们就使它们接近;如果h(𝑣)i和h(𝑣)𝑗不是邻居,我们就使它们远离。为了对数据的邻域关系进行建模,我们为每个视图构建了一个KNN图,并将邻接矩阵A(𝑣)∈R∗定义为:
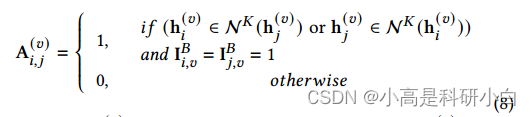
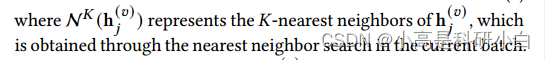
他是通过当前批中最近邻搜索获得的。
基于邻接矩阵A(𝑣),我们构造一组正对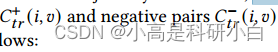 用于对比学习,方法如下:
用于对比学习,方法如下:
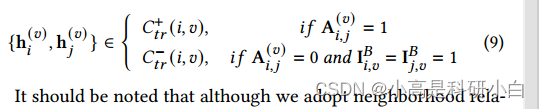
需要注意的是,尽管我们采用邻域关系来构造正对,但由于噪声问题,仍然可能出现一些假正例(一对标记为正但属于不同类别的样本)。为了减少假阳性对学习到的潜在表征的影响,使用RINCE[4]进行图内对比正则化。
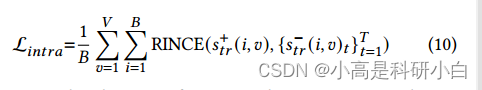
通过优化图内对比正则化的目标,可以很好地保留每个视图的局部结构在特定于视图的表示h(𝑣)中,有效地提高h(𝑣)的可判别性。
Inter-graph Contrastive Regularization
图间正则化:除了利用每个视图中的局部结构相关性之外,还应该利用不同视图之间的相关性。通过将特定视图表示与同一样本的统一表示对齐,可以使不同的视图相互补充,从而获得更有效的表示。因此,我们提出了图间对比正则化,它可以对齐不同视图的图,并利用不同视图的互补性。
具体地说,对于𝑖-th样本,视图的特定表示h(𝑣)应类似于对应的统一表示h,因此正对由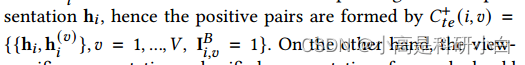 另一方面,一个样本的特定表示和统一表示应该不同于其他样本。因此,负样本对由
另一方面,一个样本的特定表示和统一表示应该不同于其他样本。因此,负样本对由![]()
![]() 考虑到视图的可靠性不同,视图的一些特定表示可能不准确。直接对齐正对会使统一表示受到不准确视图的影响。为了解决不可靠视图引起的假阳性对,采用RINCE进行图间对比正则化。
考虑到视图的可靠性不同,视图的一些特定表示可能不准确。直接对齐正对会使统一表示受到不准确视图的影响。为了解决不可靠视图引起的假阳性对,采用RINCE进行图间对比正则化。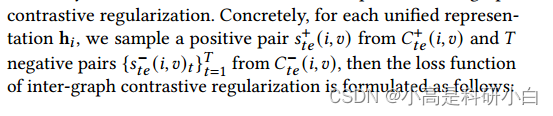 则图间对比正则化的损失函数表示为:
则图间对比正则化的损失函数表示为:
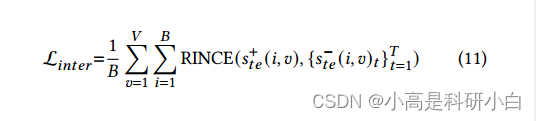
Clustering-guided Graph Contrastive Regularization
聚类引导图对比正则化:为了使学习到的友好的统一表示用于多视图聚类任务,提出了聚类引导图对比正则化,将统一表示学习与数据聚类结合起来进行。我们的方法能够利用两个任务之间的相关性,使它们相互作用,进一步提高多视图聚类的性能。
首先,采用聚类方法对每个样本的聚类概率进行评估。由于K-means聚类的有效性和高效性,本文采用了K-means聚类。将统一的表示h聚为C个类簇,且聚类中心表示为![]() 然后,得到聚类概率矩阵P被表示为:
然后,得到聚类概率矩阵P被表示为:
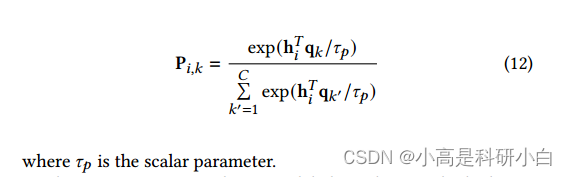
然后,我们构建了一个聚类标签图来指导统一表示的学习过程。利用聚类概率P,将聚类标签图W𝐿构造为:

其中,将W𝐿中小于𝛿的元素设置为0,这样可以增强聚类分布更相似的样本之间的相关性。进一步,为了从统一表示中获得样本的相似度,我们构造相似图W𝑆,通过![]() 对样本之间的关系进行建模。
对样本之间的关系进行建模。
最后,为了使多视图聚类任务和统一表示学习任务相互促进,使相似图W𝑆和聚类标签图W𝐿具有相似的结构。为此,我们对W𝑆和W𝐿执行行规范化,让两个矩阵的每一行总和为1,归一化矩阵用W𝑆和W𝐿。这个损失函数通过最小化两个图之间的交叉熵来定义:
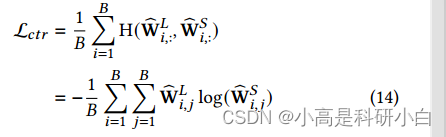
其中H(·,·)为两个分布间的交叉熵。通过最小化损失函数,可以利用数据聚类和表示学习的相关性。一方面,聚类标签图可以作为训练统一表示学习的指导。损失函数鼓励具有相似聚类标签的样本具有相似的统一表示。另一方面,增强的统一表示可以进一步得到更有效的聚类结果。因此,这两个任务可以相互促进,可以获得更好的聚类性能。
The Overall Loss Function
综合上述目标,RDGC的整体损失函数为:
![]()
其中, 和𝜂是用来平衡不同的对比正则化的超参数。该方法的整个学习过程如算法1所示。

实验
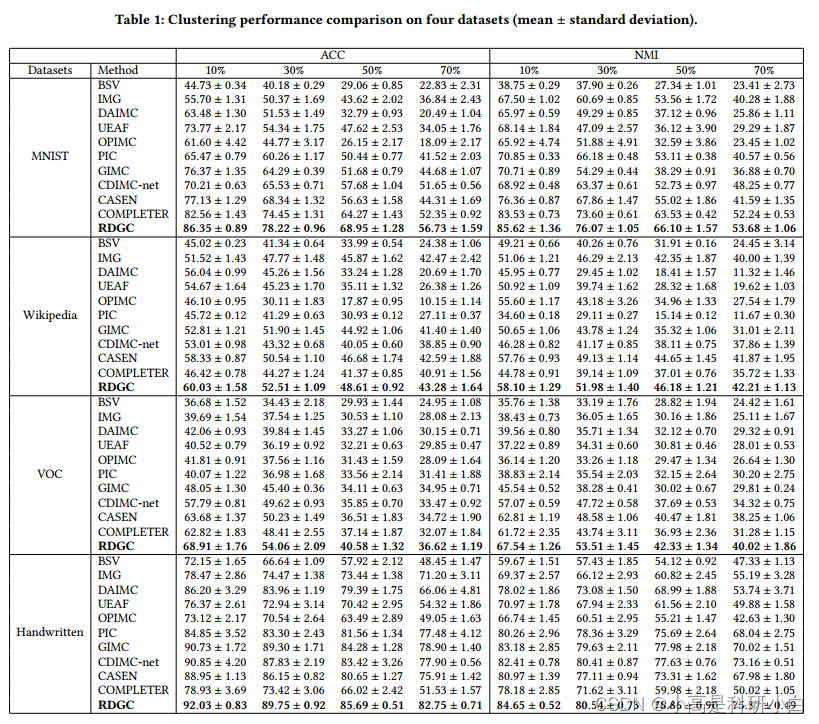
结论
本文提出了一种针对IMC的鲁棒多样化图对比网络RDGC,它将多视图表示学习和鲁棒多样化图对比正则化集成到一个统一的框架中。与现有的IMC方法相比,该方法利用鲁棒性对比学习损失来抵抗不可靠视图和噪声,提高了多视图表示的鲁棒性。我们提出了多样化的图对比正则化来捕捉多视图数据中丰富的数据相关性,从而提高数据表示的判别能力。此外,我们的方法可以联合进行数据聚类和表示学习,使两个任务相互促进。大量的实验表明,与最先进的IMC方法相比,RDGC具有良好的性能。
好句积累
注:只针对于论文写作小白
(1)Incomplete multi-view clustering is a challenging task which aims to partition the unlabeled incomplete multi-view data into several clusters. The existing incomplete multi-view clustering methods neglect to......
(2)Extensive experiments conducted on four multi-view clustering datasets demonstrate the superiority of our method over the state-of-the-art methods.
(3)Multi-view clustering aims to partition similar data into the same group by exploiting the complementarity nature of different views, which has become an important research topic in multimedia data analysis and machine learning.
(4)Although a variety of IMC methods have been developed, there are still some critical issues that have not been well solved.
(5)To solve the aforementioned issues, we propose a...................


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









