







最近稍微有点时间,所以自己简单研究了一下爬虫。原理其实很简单,就是通过url获取当前页面的html文档,根据文档来获取我们需要的数据。爬虫其实就是模仿我们进行鼠标点击操作,只要鼠标点击能获取的文档,爬虫都可以获取。
话不多说,下面直接上代码吧。其实就是一个简单的实现,大家如果看到需要改进的地方,还希望能指点指点。
爬虫需要jar包下载地址:http://download.csdn.net/download/qq_39101581/10271411
package com.test.httpclient;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.security.KeyStoreException;
import java.security.NoSuchAlgorithmException;
import java.util.ArrayList;
import java.util.List;
import org.apache.http.Consts;
import org.apache.http.NameValuePair;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.config.Registry;
import org.apache.http.config.RegistryBuilder;
import org.apache.http.conn.socket.ConnectionSocketFactory;
import org.apache.http.conn.socket.PlainConnectionSocketFactory;
import org.apache.http.conn.ssl.NoopHostnameVerifier;
import org.apache.http.conn.ssl.SSLConnectionSocketFactory;
import org.apache.http.conn.ssl.TrustSelfSignedStrategy;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.impl.conn.PoolingHttpClientConnectionManager;
import org.apache.http.message.BasicNameValuePair;
import org.apache.http.ssl.SSLContextBuilder;
import org.apache.http.util.EntityUtils;
public class TestHttpClient {
// 创建HttpClient对象
private static CloseableHttpClient httpClient = null;
public static void testHttp(String url) {
CloseableHttpResponse response = null;
try {
if (httpClient != null)
httpClient.close();
httpClient = getHttpClient();
// 封装请求参数
List<NameValuePair> params = new ArrayList<NameValuePair>();
params.add(new BasicNameValuePair("paramName", "paramValue"));
// 请求参数转为字符串
String paramsStr = EntityUtils.toString(new UrlEncodedFormEntity(params, Consts.UTF_8));
// 爬虫URL大部分都是get请求,创建get请求对象
HttpGet httpGet = new HttpGet(url + "?" + paramsStr);
// 向传智播客官方网站发送请求,获取网页源码
response = httpClient.execute(httpGet);
// EntityUtils工具类把网页实体转换成字符串
String entity = EntityUtils.toString(response.getEntity(), "UTF-8");
System.out.println(entity);
String urlpath = getFileName(url);// 根据url来获取文件名(去掉https://和.)
List<String> list = getSplitList();// 获取所有的特殊符号
urlpath = splitstr(urlpath, list);// 去掉文件名中的所有特殊符号
String path = "D:\\html\\" + urlpath + ".html";// 指定爬虫获取文件存放地址
File file = new File(path);
if (!file.exists())
try {
file.createNewFile();
} catch (Exception e) {
System.out.println("createNewFile失败" + urlpath);
e.printStackTrace();
}
BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(file), "utf-8"));
writer.write(entity);
writer.close();
System.out.println("---------------------------------------------------------------------------");
String str = "<a href=";
List<Integer> allIndex = getAllIndex(str, entity);// 获取所有str在entity中的索引
for (Integer index : allIndex) {
System.out.println(index);
int indexOfstart = index;
int indexOfend1 = entity.indexOf(" ", indexOfstart + str.length());
int indexOfend2 = entity.indexOf(">", indexOfstart + str.length());
int indexOfend = indexOfend1 <= indexOfend2 ? indexOfend1 : indexOfend2;
String suburl = entity.substring(indexOfstart + str.length(), indexOfend);
String suffix = "";
if (suburl.startsWith("http://")) {
suffix = "http://";
} else if (suburl.startsWith("https://")) {
suffix = "https://";
} else if (suburl.startsWith("//")) {
suffix = "//";
} else if (suburl.startsWith("\"")) {
continue;
}
suburl = "https://" + suburl.substring(suffix.length());
System.out.println(suburl);
testHttp(suburl);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (response != null) {
try {
response.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (httpClient != null) {
try {
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
/**
* 创建HttpClient
*
* @return
* @throws Exception
*/
public static CloseableHttpClient getHttpClient() throws Exception {
/*
* javax.net.ssl.SSLPeerUnverifiedException你的测试服务器常常没有一个(有效的)SSL证书
*/
SSLContextBuilder builder = new SSLContextBuilder();
builder.loadTrustMaterial(null, new TrustSelfSignedStrategy());
SSLConnectionSocketFactory sslConnectionSocketFactory = new SSLConnectionSocketFactory(builder.build(),
NoopHostnameVerifier.INSTANCE);
Registry<ConnectionSocketFactory> registry = RegistryBuilder.<ConnectionSocketFactory>create()
.register("http", new PlainConnectionSocketFactory()).register("https", sslConnectionSocketFactory)
.build();
PoolingHttpClientConnectionManager cm = new PoolingHttpClientConnectionManager(registry);
cm.setMaxTotal(100);
CloseableHttpClient httpClient = HttpClients.custom().setSSLSocketFactory(sslConnectionSocketFactory)
.setConnectionManager(cm).build();
return httpClient;
}
/**
* 获取所有str在string中的位置索引
*
* @param str
* @param string
* @return
*/
public static List<Integer> getAllIndex(String str, String string) {
List<Integer> list = new ArrayList<Integer>();
for (int i = 0; i < string.lastIndexOf(str); i++) {
i = string.indexOf(str, i);
list.add(i);
}
return list;
}
/**
* 根据url来获取文件名(去掉https://和.)
*
* @param url
* @return
*/
public static String getFileName(String url) {
String suffix = "https://";
String[] urlchar = url.substring(url.indexOf(suffix) + suffix.length()).split("\\.");
String urlpath = "";
for (String str : urlchar) {
urlpath += str;
}
return urlpath;
}
/**
* 去掉字符串中所有的特殊符号
*
* @param str
* @param list
* @return
*/
public static String splitstr(String str, List<String> list) {
for (String string : list) {
String newStr = "";
String[] split = str.split(string);
for (String string2 : split) {
newStr += string2;
str = newStr;
}
}
return str;
}
/**
* 获取所有的特殊符号
*
* @return
*/
public static List<String> getSplitList() {
List<String> list = new ArrayList<String>();
list.add("\\.");
list.add("\\/");
list.add("\\?");
list.add("\\,");
return list;
}
/**
* 程序入口
*
* @param args
*/
public static void main(String[] args) {
String url = "https://www.baidu.com";
testHttp(url);
}
}
代码中初始url是百度首页,最终能获得的结果如图所示
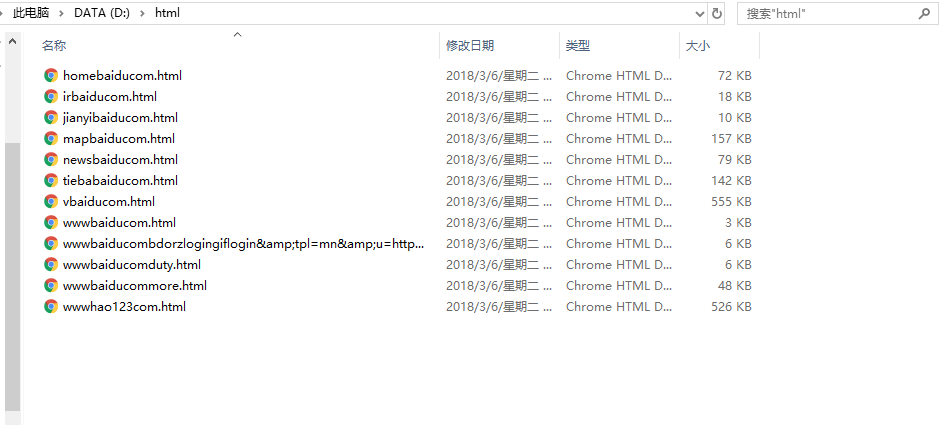
在此记录一下,希望对有些朋友有些许帮助,不足的地方,希望指正!谢谢!















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









