







一、简介
Redis是完全开源的,遵守BSD协议,是一个高性能的key-value数据库。
1.Redis的特点:
- Redis支持数据持久化,可以将内存中的数据持久化保存在磁盘中,重启的时候可以再次加载进行使用
- Redis不仅仅支持简单的key-value(String)类型的数据,同时还提供list,set,zset和hash等数据结构的存储。
- Redis支持数据的备份,即master-slave模式的数据备份
2.Redis的优势
- 性能极高—Redis读的速度是110000次/s,写的速度是81000次/s
- 丰富的数据类型—Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 原子性—Redis的所有操作都是原子的,意思就是要么成功执行要么失败完全不执行。单个操作是原子的。多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来。
- 丰富的特性—Redis还支持publish/subscribe,通知,key过期等特性
3.Redis与其他key-value存储有什么不同?
- Redis有着更为复杂的数据结构并且提供对他们的原子性操作,这是一个不同于其他数据库的进化路径。Redis的数据类型都是基于基本数据结构的同时对程序员透明,无需进行额外的抽象。
- Redis运行在内存中但是可以持久化到磁盘,所以在对不同数据集进行高速读写时需要权衡内存,因为数据量不能大于硬件内存。在内存数据库方面的另一个优点是,相比在磁盘上相同的复杂的数据结构,在内存中操作起来非常简单,这样Redis可以做很多内部复杂性很强的事情。同时,在磁盘格式方面他们是紧凑的以追加的方式产生的,因为他们并不需要进行随机访问。
二、Redis的数据类型
常用的五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。
1.String
set/get
set key value [ex seconds] [px millseconds] [nx|xx]
get key
-
ex seconds: 键过期时间
-
px milliseconds: 为键设置毫秒级过期时间
-
nx: 键必须不存在才可以设置成功,用于添加
-
xx: 键必须存在,才可以设置成功,用于更新
#设置name ,过期时间15s ,且name必须不存在才能设置成功
set name tank ex 15 nx
mset,mget
批量设置和获取命令,在操作多个key的时候可以节省网络传输时间
mset key value [key value...]
mget key [key ...]
#eg
mset name1 tank1 name2 tank2
mget name1 name2
其他命令
incr 对值进行加1操作,如果不是整数,返回错误,如果不存在按照从0开始
decr 同incr,但是是减1操作
incrby,decrby ,增加减去指定的数
使用场景
缓存:将数据以字符串方式存储
计数器功能:比如视频播放次数,点赞次数。
共享session:数据共享的功能,redis作为单独的应用软件用来存储一些共享数据供多个实例访问。
字符串的使用空间非常大,可以结合字符串提供的命令充分发挥自己的想象力
2.hash(哈希)
Redis hash 是一个键值(key=>value)对集合。
Redis hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。
hset key field value
hsetnx key field value //与setnx命令一样,不存在则设置值,用于添加,作用在field上面
hget key field //获取值
hdel key field // 删除值
hlen key //子酸field的个数
hmset key field value [filed value] //批量设置field-value
hexists key field //判断filed是否存在
hkeys key //获取所有的field
hvals key //获取所有的value
hgetall key //获取所有的field-value ,如果元素数较多会存在阻塞redis的可能
hincreby key filed
#eg
hmset user name tank id 1560311139
hget user name
和字符串很像,基本上redis对字符串操作的命令,Redis的Hash一般也存在,不过在命令前多个一个h。
一些关系型数据库中不是特别复杂的表,也无需复杂的关系查询,可以使用Redis的Hash来存储,也可以用Hash做表数据缓存。
3.列表list
列表用来存储多个有序的字符串,一个列表最多可以存储2^32 - 1个元素,在redis中可以对列表的两端插入push和弹出pop,还可以取指定范围的元素。
rpush key value [value...] //从右插入元素
lpush key value [value...] //从左边插入元素
lrange key start end //获取指定范围的元素列表
lindex key index //获取列表指定索引下标的元素
llen key //获取列表的长度
lpop key // 从列表左侧弹出元素
rpop key // 从列表右侧弹出元素
lrem key count value //从列表中找到等于value的元素,并进行删除,根据count的不同有不同的情况
lset key index newValue //修改指定索引下标的元素
blpop key timeout //阻塞式左弹出key
brpop key timeout //阻塞式右弹出key
#eg
rpush cardIds card1 card2 card3
使用场景:
- 消息队列:使用redis做消息队列,lpush + brpop或rpop命令,实现先进先出,如果消费失败客户端把key再放回去,消费成功真的remove掉
4.集合set
集合是用来保存多个字符串的元素,内部不允许有重复远古三,集合内的元素是无序的,Redis支持集合的增删改查,同时支持多个集合取交集,并集,差集
sadd key value [value...] //添加元素
srem key value [value...] //删除元素
scard key //计算元素的个数
sismember key value //判断元素是否在集合中
srandmember key [count] //随机从集合中返回指定个数的元素,不写默认为1
spop key //从集合随机取出元素
smembers key //获取集合内的所有元素
sinter key1 key2 //求集合的交集
sunion key1 key2 //求集合的并集
sdiff key1 key2 //求集合的差集
#eg
sadd sts 123 345 123
使用场景
- 标签:例如博客标签,一篇博客可以有多个标签,且是不重复的
5.zset(sorted set:有序集合)
Redis zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
zset的成员是唯一的,但分数(score)却可以重复
zadd key score member //score是可以重复的,添加key的时候指定分数
zcard key //计算成员个数
zscore key member //计算某个成员的分数
zrank key member //计算成员排名,从低到高
zrevrank key member //计算成员排名,从高到低
zrem key member [member...] //删除成员
zincrby key increnment member //增加成员的分数
zrange key start end [withscores] //从低到高返回指定排名的分数
zrevrange key start end [withscores] //从高到低返回
zrangebyscore key min max [withscores] [limit offset count] //按照分数从低到高返回
zrevrange score key min max [withscores] [limit offset count] //按照分数从高到低返回成员
withscore 代表返回的时候带上成员的分数
...还有求交集,并集等操作
#eg
zadd mode 1 wangwu 2 wangsi
使用场景
- 排行榜
三、Redis发布订阅
Redis 发布订阅 (pub/sub) 是一种消息通信模式:发送者 (pub) 发送消息,订阅者 (sub) 接收消息。
Redis 客户端可以订阅任意数量的频道。
下图展示了频道 channel1 , 以及订阅这个频道的三个客户端 —— client2 、 client5 和 client1 之间的关系:

当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端:

#分别开启三个客户端界面
一个发布者,两个订阅者
两个订阅者都执行 subscribe testchat #订阅
发布者执行 publish testchat "test message" #发布消息

四、Redis事务
redis事务提供了一种“将多个命令打包, 然后一次性、按顺序地执行”的机制, 并且事务在执行的期间不会主动中断 —— 服务器在执行完事务中的所有命令之后, 才会继续处理其他客户端的其他命令。关系型数据中的事务都是原子性的,而redis 的事务是非原子性的。
Redis 事务可以一次执行多个命令, 并且带有以下三个重要的保证:
- 批量操作在发送 EXEC 命令前被放入队列缓存。
- 收到 EXEC 命令后进入事务执行,事务中任意命令执行失败,其余的命令依然被执行。
- 在事务执行过程,其他客户端提交的命令请求不会插入到事务执行命令序列中。
一个事务从开始到执行会经历以下三个阶段:
- 开始事务。
- 命令入队。
- 执行事务。
实例
以下是一个事务的例子, 它先以 MULTI 开始一个事务, 然后将多个命令入队到事务中, 最后由 EXEC 命令触发事务, 一并执行事务中的所有命令:

单个 Redis 命令的执行是原子性的,但 Redis 没有在事务上增加任何维持原子性的机制,所以 Redis 事务的执行并不是原子性的。
事务可以理解为一个打包的批量执行脚本,但批量指令并非原子化的操作。
事务失败处理:
-
语法错误(编译器错误),在开启事务后,修改k1值为11,k2值为22,但k2语法错误,最终导致事务提交失败,k1、k2保留原值。

-
Redis类型错误(运行时错误),在开启事务后,修改k1值为11,k2值为22,但将k2的类型作为List,在运行时检测类型错误,最终导致事务提交失败,此时事务并没有回滚,而是跳过错误命令继续执行, 结果k1值改变、k2保留原值。

五、持久化
Redis支持两种持久化机制,分别是RDB(Redis DataBase)和AOF(Append Only File)。持久化功能有效地避免因进程退出造成的数据丢失问题,当下次重启时利用之前持久化的文件即可实现数 据恢复。安装redis时默认使用RDB的方式持久化
1.RDB持久化
RDB持久化是把当前进程数据生成快照保存在硬盘里的过程,触发RDB持久化过程分为手动触发和自动触发。
手动触发:分为save命令和bgsave
save命令:阻塞当前redis服务器,直到RDB过程完成为止,对于内存比较大的实例会造成长时间阻塞,线上环境不建议使用。
bgsave命令:redis执行fork操作创建子线程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短。
自动触发:
1)使用save相关配置,如“save m n”。表示m秒内数据集存在n次修改 时,自动触发bgsave。
2)如果从节点执行全量复制操作,主节点自动执行bgsave生成RDB文件并发送给从节点,更多细节见6.3节介绍的复制原理。
3)执行debug reload命令重新加载Redis时,也会自动触发save操作。
4)默认情况下执行shutdown命令时,如果没有开启AOF持久化功能则 自动执行bgsave。
bgsave是主流的触发RDB持久化方式
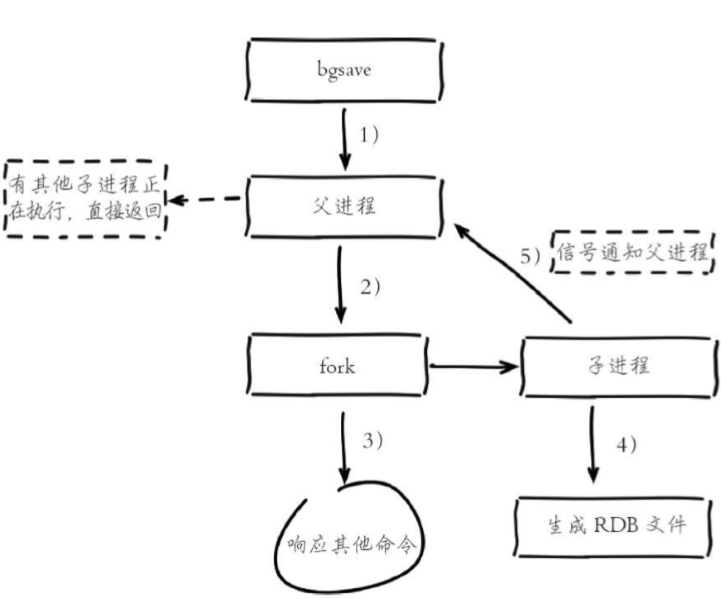
1)执行bgsave命令,Redis父进程判断当前是否存在正在执行的子进 程,如RDB/AOF子进程,如果存在bgsave命令直接返回。
2)父进程执行fork操作创建子进程,fork操作过程中父进程会阻塞,通 过info stats命令查看latest_fork_usec选项,可以获取最近一个fork操作的耗时,单位为微秒
3)父进程fork完成后,bgsave命令返回“Background saving started”信息并不再阻塞父进程,可以继续响应其他命令。
4)子进程创建RDB文件,根据父进程内存生成临时快照文件,完成后 对原有文件进行原子替换。执行lastsave命令可以获取最后一次生成RDB的 时间,对应info统计的rdb_last_save_time选项。
5)进程发送信号给父进程表示完成,父进程更新统计信息,具体见 info Persistence下的rdb_*相关选项。
RDB文件的处理
保存:RDB文件保存在dir配置指定的目录下,文件名通过dbfilename配 置指定。
RDB的优点:
RDB是一个紧凑压缩的二进制文件,代表Redis在某个时间点上的数据 快照。非常适用于备份,全量复制等场景。比如每6小时执行bgsave备份, 并把RDB文件拷贝到远程机器或者文件系统中(如hdfs),用于灾难恢复。
Redis加载RDB恢复数据远远快于AOF的方式。
RDB的缺点:
RDB方式数据没办法做到实时持久化/秒级持久化。因为bgsave每次运 行都要执行fork操作创建子进程,属于重量级操作,频繁执行成本过高。
RDB文件使用特定二进制格式保存,Redis版本演进过程中有多个格式 的RDB版本,存在老版本Redis服务无法兼容新版RDB格式的问题。
针对RDB不适合实时持久化的问题,Redis提供了AOF持久化方式来解决。
2.AOF持久化
AOF(append only file)持久化:以独立日志的方式记录每次写命令, 重启时再重新执行AOF文件中的命令达到恢复数据的目的。AOF的主要作用 是解决了数据持久化的实时性,目前已经是Redis持久化的主流方式
1)使用AOF
开启AOF功能需要设置配置:appendonly yes,默认不开启。AOF文件名 通过appendfilename配置设置,默认文件名是appendonly.aof。保存路径同 RDB持久化方式一致,通过dir配置指定。AOF的工作流程操作:命令写入 (append)、文件同步(sync)、文件重写(rewrite)、重启加载 (load)
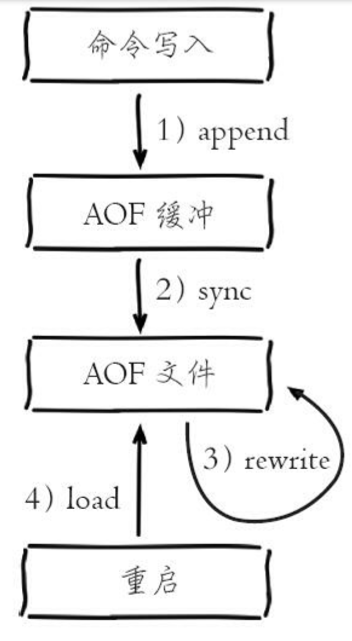
1)所有的写入命令会追加到aof_buf(缓冲区)中。
2)AOF缓冲区根据对应的策略向硬盘做同步操作。AOF为什么把命令追加到aof_buf中?Redis使用单线程响应命令,如 果每次写AOF文件命令都直接追加到硬盘,那么性能完全取决于当前硬盘负 载。先写入缓冲区aof_buf中,还有另一个好处,Redis可以提供多种缓冲区同步硬盘的策略,在性能和安全性方面做出平衡
3)随着AOF文件越来越大,需要定期对AOF文件进行重写,达到压缩的目的。
重写后的AOF文件为什么可以变小?有如下原因:
1)进程内已经超时的数据不再写入文件。
2)旧的AOF文件含有无效命令,如del key1、hdel key2、srem keys、set a111、set a222等。重写使用进程内数据直接生成,这样新的AOF文件只保
留最终数据的写入命令。u.getProvinceIds().split(",");
3)多条写命令可以合并为一个,如:lpush list a、lpush list b、lpush list c可以转化为:lpush list a b c。为了防止单条命令过大造成客户端缓冲区溢 出,对于list、set、hash、zset等类型操作,以64个元素为界拆分为多条。
AOF重写降低了文件占用空间,除此之外,另一个目的是:更小的AOF 文件可以更快地被Redis加载
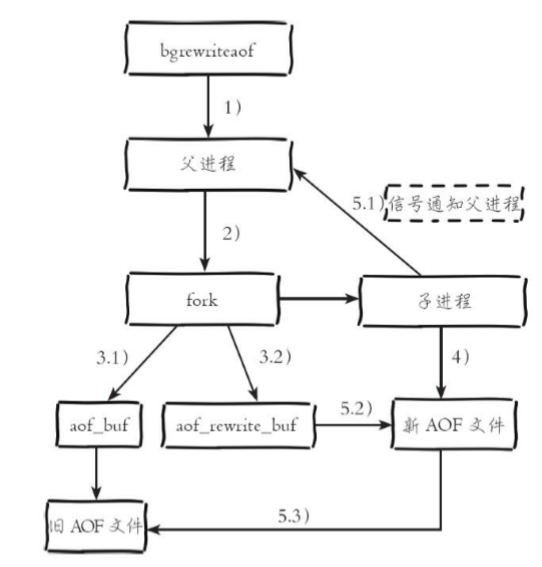
AOF重写过程可以手动触发和自动触发:
·手动触发:直接调用bgrewriteaof命令。
·自动触发:根据auto-aof-rewrite-min-size和auto-aof-rewrite-percentage参数确定自动触发时机
·auto-aof-rewrite-min-size:表示运行AOF重写时文件最小体积,默认 为64MB。
·auto-aof-rewrite-percentage:代表当前AOF文件空间 (aof_current_size)和上一次重写后AOF文件空间(aof_base_size)的比值。
自动触发时机=aof_current_size>auto-aof-rewrite-minsize&&(aof_current_size-aof_base_size)/aof_base_size>=auto-aof-rewritepercentage
其中aof_current_size和aof_base_size可以在info Persistence统计信息中查看。
4)当Redis服务器重启时,可以加载AOF文件进行数据恢复。
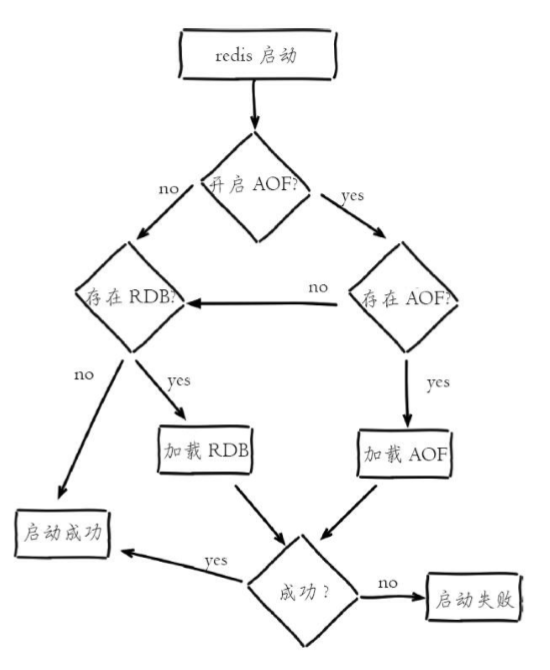
流程说明:
1)AOF持久化开启且存在AOF文件时,优先加载AOF文件,打印如下日志:
* DB loaded from append only file: 5.841 seconds
2)AOF关闭或者AOF文件不存在时,加载RDB文件,打印如下日志:
* DB loaded from disk: 5.586 seconds
3)加载AOF/RDB文件成功后,Redis启动成功。
4)AOF/RDB文件存在错误时,Redis启动失败并打印错误信息。
3.混合持久化
描述: 混合持久化并不是一种全新的持久化方式,而是对已有方式的优化。混合持久化只发生于 AOF 重写过程。使用了混合持久化,重写后的新 AOF 文件前半段是 RDB 格式的全量数据,后半段是 AOF 格式的增量数据。
整体格式为: [RDB file][AOF tail]
开启: 混合持久化的配置参数为 aof-use-rdb-preamble,配置为 yes 时开启混合持久化,在 Redis4 刚引入时,默认是关闭混合持久化的,但是在 Redis5 中默认已经打开了。
关闭: 使用 aof-use-rdb-preamble no 配置即可关闭混合持久化。
混合持久化本质是通过 AOF 后台重写(bgrewriteaof 命令)完成的,不同的是当开启混合持久化时,fork 出的子进程先将当前全量数据以 RDB 方式写入新的 AOF 文件,然后再将 AOF 重写缓冲区(aof_rewrite_buf_blocks)的增量命令以 AOF 方式写入到文件,写入完成后通知主进程将新的含有 RDB 格式和 AOF 格式的 AOF 文件替换旧的的 AOF 文件。
优点: 结合 RDB 和 AOF 的优点, 更快的重写和恢复。增量的数据以AOF方式保存了,数据更少的丢失。
缺点: AOF 文件里面的 RDB 部分不再是 AOF 格式,可读性差。在4.0之前版本都不识别该aof文件。















 1076
1076











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









