









在 Android Studio 中,Debug 版本和 Release 版本是两种常见的构建类型,用于不同的开发阶段和用途。它们的核心区别如下:
前言
Debug与Release区别
1. Debug 版本
-
用途:开发调试阶段使用。
-
特点:
-
调试信息:包含完整的调试符号(如行号、变量名),方便断点调试。
-
日志输出:默认启用
Log.d()、Log.v()等详细日志,方便排查问题。 -
未优化代码:代码未混淆、未压缩,保留原始结构,便于调试。
-
调试工具支持:支持 Android Profiler、内存分析器等工具。
-
签名:使用 Android Studio 自动生成的调试密钥签名(
debug.keystore)。 -
性能:可能运行较慢,未启用代码优化(如 ProGuard/R8)。
-
2. Release 版本
-
用途:正式发布到应用商店(即“正式版本”)。
-
特点:
-
代码优化:启用 ProGuard 或 R8 进行代码混淆、压缩和优化,减小 APK 体积并提高性能。
-
移除调试信息:删除调试符号和日志代码(如
Log语句默认被移除)。 -
正式签名:使用开发者自己的发布密钥签名(需保密密钥文件)。
-
禁用调试:无法通过 Android Studio 附加调试器。
-
性能:经过优化,运行速度更快,内存占用更低。
-
安全加固:混淆后的代码更难以逆向工程。
-
3. 正式版本(Release 版本)
-
本质:Release 版本经过签名、混淆和优化后,即可作为正式版本发布到 Google Play 等平台。
-
发布流程:
-
生成签名密钥(.jks 或 .keystore 文件)。
-
在
build.gradle中配置发布签名。 -
构建 Release APK/AAB(通过
Build > Generate Signed Bundle/APK)。 -
进行全面测试(性能、功能、兼容性等)。
-
上传到应用商店。
-
关键区别总结
| 特性 | Debug 版本 | Release 版本(正式版) |
|---|---|---|
| 调试支持 | 支持断点、日志、分析工具 | 无调试支持 |
| 代码优化 | 未优化,保留原始结构 | 混淆、压缩、优化 |
| 签名 | 调试密钥(自动生成) | 开发者正式密钥(需保密) |
| 日志输出 | 默认启用 | 默认移除或禁用 |
| 性能 | 较低(未优化) | 较高(优化后) |
| 安全性 | 低(代码易逆向) | 高(代码混淆) |
APK签名密钥与签名
在 Android 应用开发中,APK 签名密钥和签名是确保应用安全性和可信性的核心机制,其作用如下:
1. 签名密钥
-
定义:
签名密钥是一个加密文件(通常为.jks或.keystore格式),包含私钥(用于签名)和公钥(用于验证)。 -
类型:
-
调试密钥:由 Android Studio 自动生成(
debug.keystore),用于开发阶段临时签名,不可用于发布。 -
发布密钥:开发者手动生成并保管的正式密钥,用于应用商店发布的 APK/AAB 签名,必须严格保密。
-
2. 签名过程
-
如何签名:
使用私钥对 APK 的哈希值进行加密,生成数字签名,并将签名和公钥一同嵌入 APK。 -
工具:
通过 Android Studio 的Generate Signed Bundle/APK或命令行工具(jarsigner、apksigner)完成。
3. 核心作用
-
身份验证
-
证明 APK 的开发者身份(如 Google Play 要求同一应用的所有更新必须使用同一密钥签名)。
-
防止他人冒充开发者发布恶意应用。
-
-
完整性校验
-
确保 APK 未被篡改(任何对 APK 的修改都会导致签名失效,系统拒绝安装)。
-
-
应用更新权限
-
只有相同签名的 APK 才能覆盖安装旧版本,避免第三方劫持应用更新。
-
-
权限管理
-
相同签名的应用可共享数据(如通过
android:sharedUserId)。
-
Android studio正式打包发布
点击“构建-Generate Signed App Bundle”,进入打包界面

选择下方“APK”并点击“下一步”,
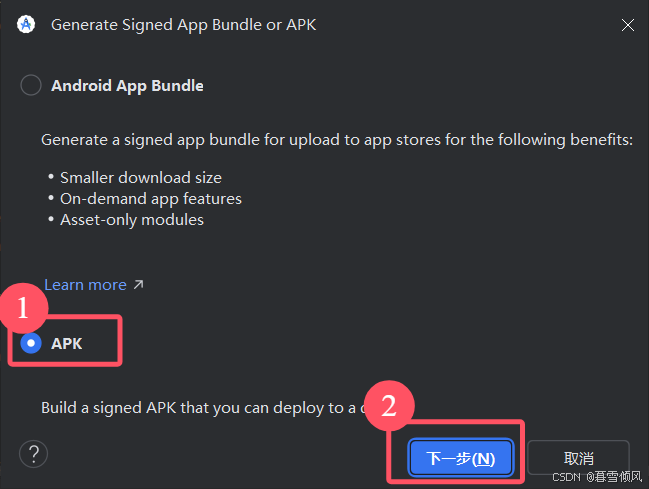
如果为第一次,需要选择签名密钥,如图新建密钥
点击“Create new”
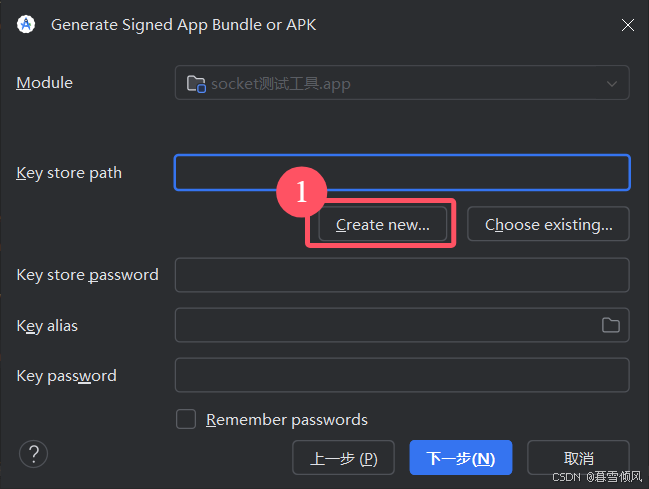
选择保存路径与名称
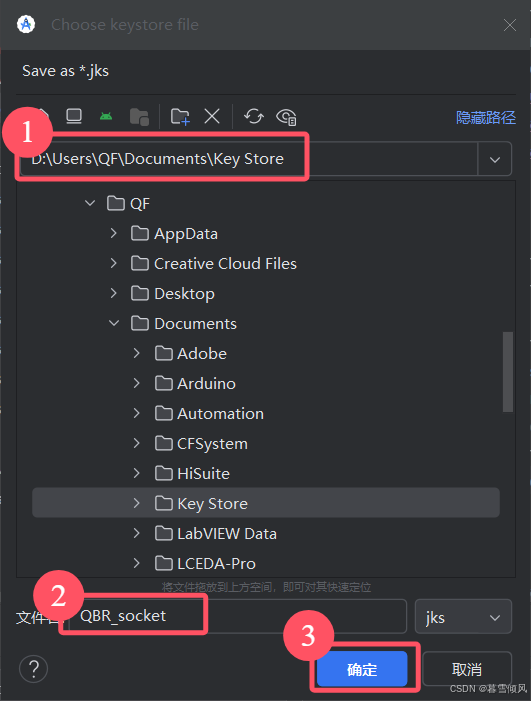
点击保存后填写签名密钥信息
!!!密钥的密码一定要记住!!!密钥的密码一定要记住!!!密钥的密码一定要记住!!!
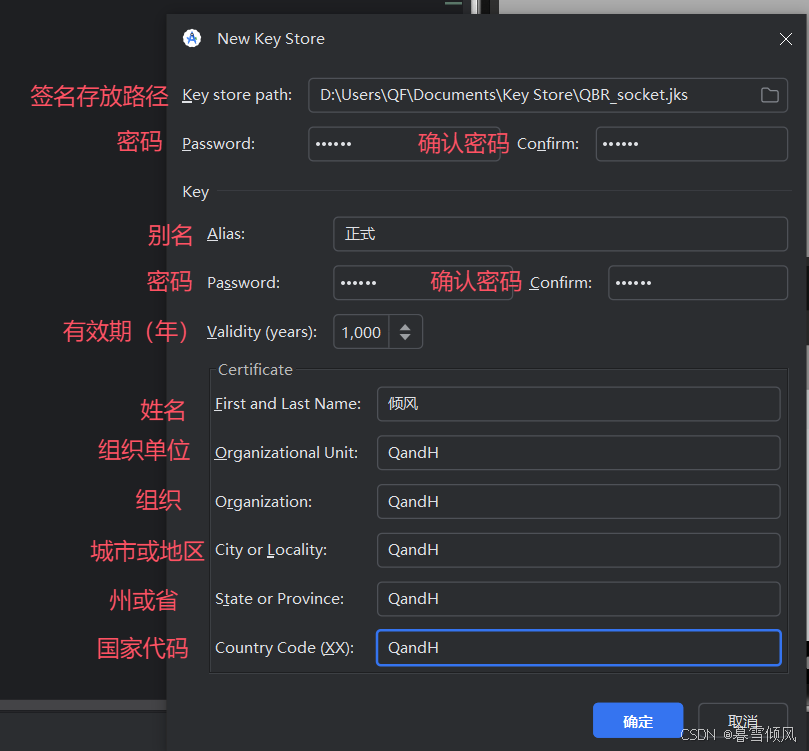
点击确认后,会自动填写刚才保存的密钥信息,记得点击“Remember passwords”记住密码并点击下一步
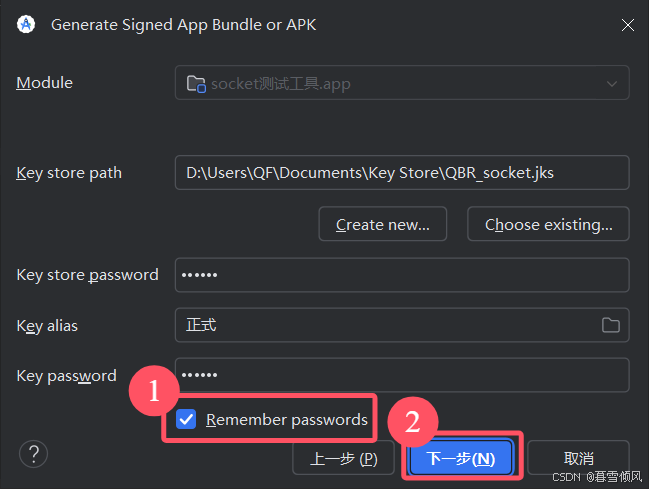
点击签名“release”并选择上方的保存路径。点击“创建”
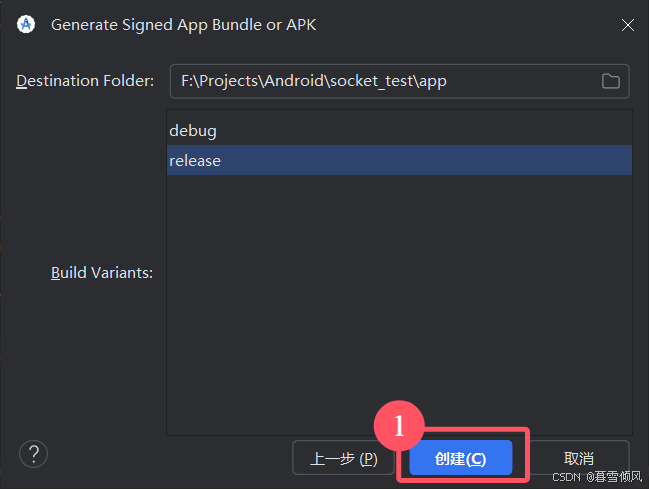
等待签名完成
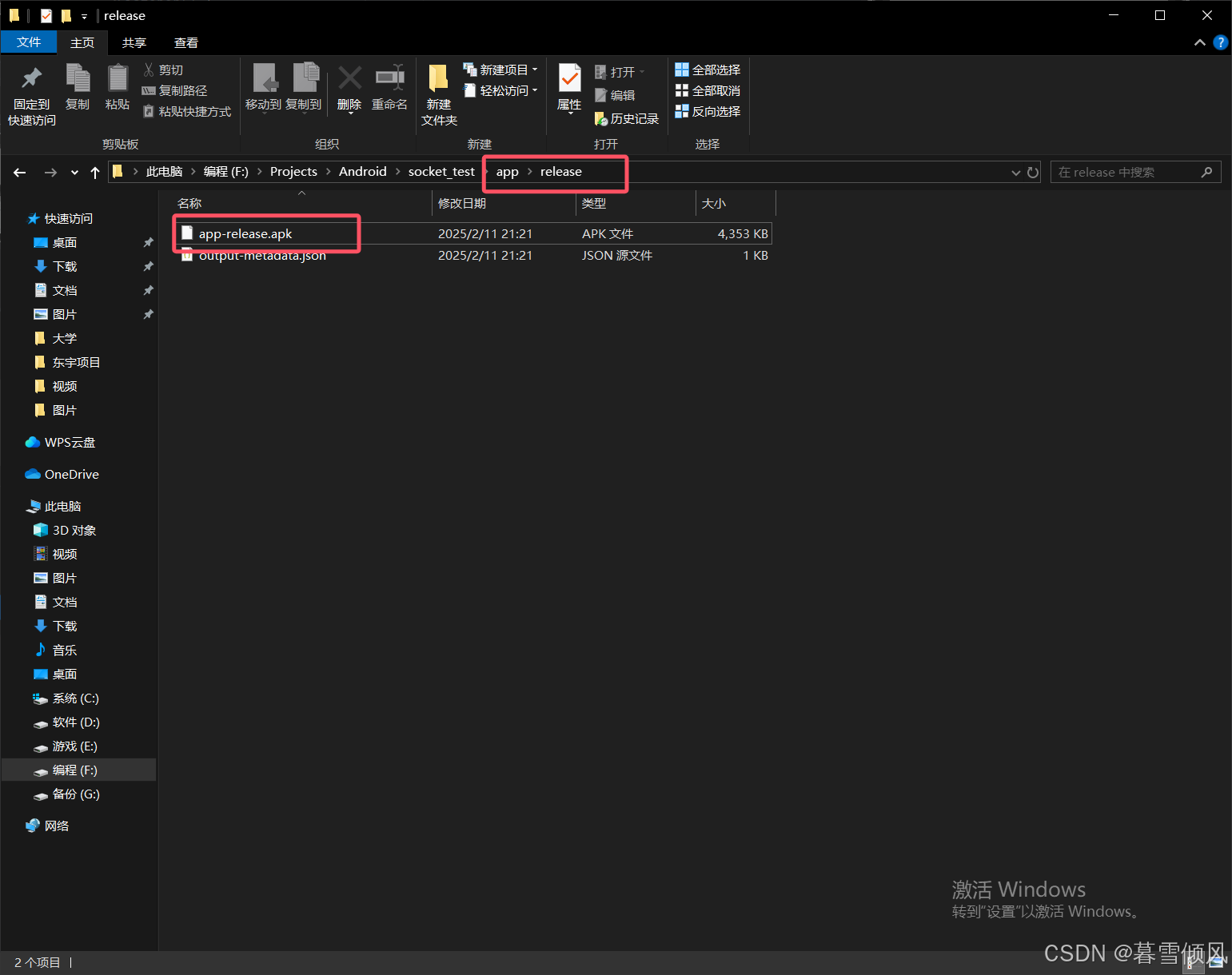
最后就能在刚才选择的路径中找到生成的“release”安装包啦

















 459
459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









