







01
富媒体多模态理解
首先来介绍一下我们对多模态内容的感知。
1. 多模态理解
提升内容理解能力,让广告系统在细分场景下更懂内容

在提升内容理解能力时,会遇到很多现实的问题:
-
商业业务场景多、行业多,独立建模冗余且会导致过拟合,场景间分布共性和特异性,统一建模如何兼顾;
-
商业视觉物料周边文本差,易导致配图badcase;
-
系统充斥无意义ID类特征、泛化性差;
-
富媒体时代,如何高效利用视觉语义,这些内容特征、视频特征和其他特征如何融合,是我们需要去解决的,用以提升系统内对富媒体内容的感知力度。
什么是好的多模态基础表征
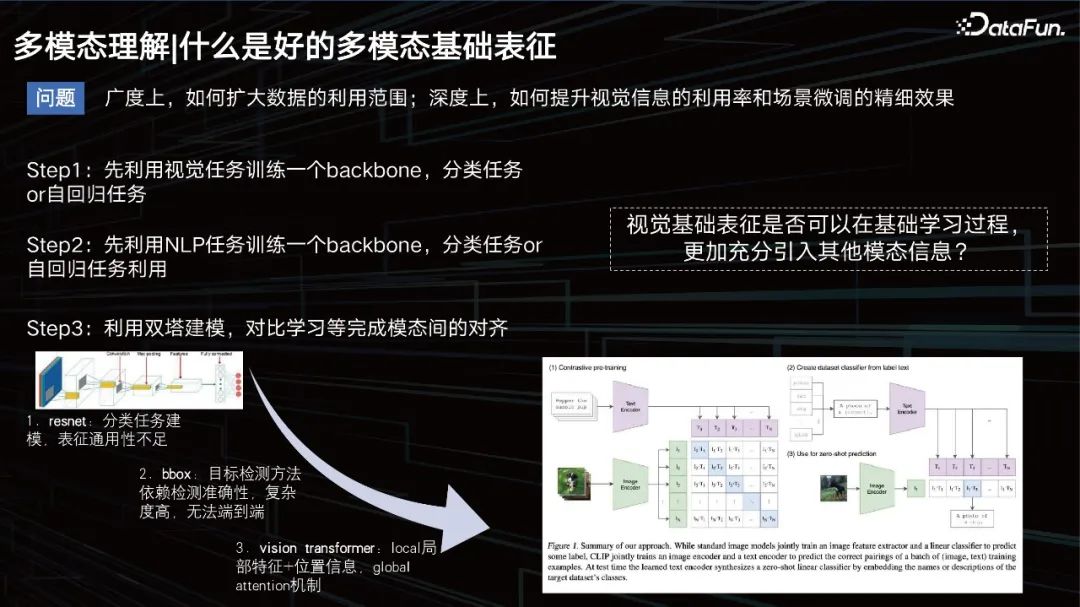
什么是一个好的多模态表征?
从广度上要扩大数据应用的范围,从深度上要提升视觉效果,同时保证场景的数据微调。
之前,常规的思路是,训练一个模型去学习图片的模态,一个自回归的任务,然后做文本的任务,再套用一些双塔的模式,去拉近二者的模态关系。那时的文本建模比较简单,大家更多的是在研究视觉怎么建模。最开始是CNN,后面包括一些基于目标检测的方式去提升视觉的表征,比如bbox方式,但这种方式的检测能力有限,并且太重了,并不利于大规模的数据训练。
到了2020年和2021年前后, VIT方式成为了主流。这里不得不提的一个比较有名的模型就是 OpenAI在20年发布的一个模型CLIP,基于双塔的架构分别去做文本和视觉的表征。再用cosine去拉进二者的距离。该模型在检索上面非常优秀,但在VQA任务等一些需要逻辑推理的任务上,就稍显能力不足了。
学表征:提升自然语言对视觉的基础感知能力
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









