







1Tengine简介
Tengine 由 OPEN AI LAB 主导开发,该项目实现了深度学习神经网络模型在嵌入式设备上的快速、高效部署需求。为实现在众多 AIoT 应用中的跨平台部署,本项目基于原有 Tengine 项目使用 C 语言进行重构,针对嵌入式设备资源有限的特点进行了深度框架裁剪。同时采用了完全分离的前后端设计,有利于 CPU、GPU、NPU 等异构计算单元的快速移植和部署,同时降低评估和迁移成本。
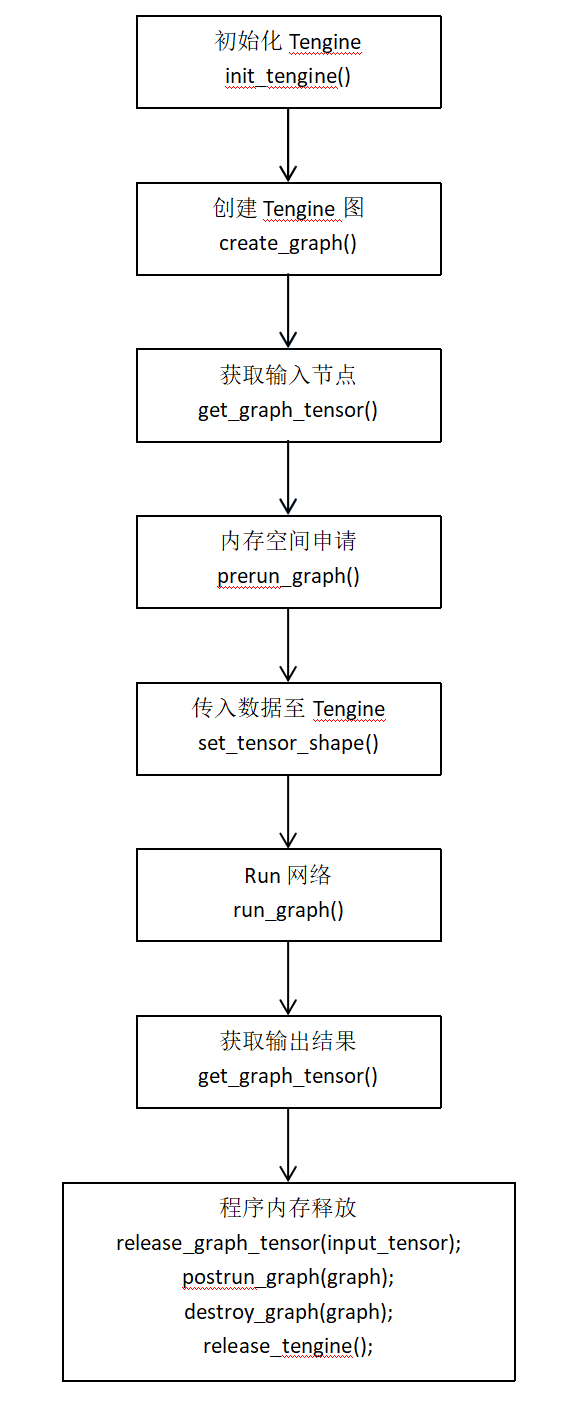
Tengine推理流程
依照顺序调用Tengine核心API如下:
2模块实现
1 模型转换
第1步:转换到onnx模型
model_path = "models/pretrained/version-RFB-320.pth"
net = create_Mb_Tiny_RFB_fd(len(class_names), is_test=True)
net.load(model_path)
net.eval()
net.to("cuda")
model_name = model_path.split("/")[-1].split(".")[0]
model_path = f"models/onnx/{model_name}.onnx"
dummy_input = torch.randn(1, 3, 240, 320).to("cuda")
torch.onnx.export(net, dummy_input, model_path, verbose=False, input_names=['input'], output_names=['scores', 'boxes'])
第2步:编译Tengine模型转换工具
依赖库安装
sudo apt install libprotobuf-dev protobuf-compiler
源码编译
mkdir build && cd build
cmake ..
make -j`nproc` && make install
编译完成后,生成的可行性文件tm_convert_tool存放在 ./build/install/bin/ 目录下。
第3步:转换onnx模型为tmfile模型
./tm_convert_tool -m xxx.onnx -o xxx.tmfile
-
-m 为*.caffemodel, *.params, *.weight, *.pb, *.onnx, *.tflite等模型;
-
-o 为output fp32 tmfile
2 NMS计算
伪代码:
-
1 将各组box按照score降序排列;
-
2 从score最大值开始,置为当前box,保存idex,然后依次遍历后面的box,计算与当前box的IOU值,若大于阈值,则抑制,不会输出;
-
3 完成一轮遍历后,继续选择下一个非抑制的box作为当前box,重复步骤2;
-
4 返回没有被抑制的index即符合条件的box;
python版本
def NMS(dects,threshhold 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









