






爬虫简介
网络爬虫,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,通俗的讲是指向网站/网络发起请求,获取资源后分析并提取有用数据的程序
获取网络数据的方式
方法1:浏览器提交请求->下载网页代码->解析成页面
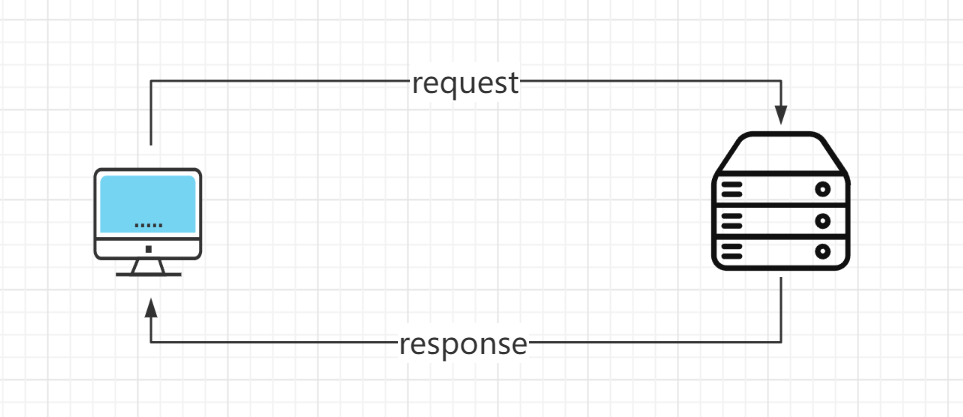
request:用户将自己的信息通过浏览器发送给服务器
response:服务器接收请求,分析用户发来的请求信息,然后返回数据
方法2:模拟浏览器发送请求->提取有用的数据->存放数据库或文件
爬虫获取数据方式
网络爬虫获取数据的方式即是方法2这种模式,通过爬虫程序模拟浏览器发送请求,然后接收服务器发来的响应,提取响应内有用的数据

发送请求
下载requests模块
pip install requestsrequests请求有两种常用的方式:GET/POST
import requests # 引入requests模块# 对B站发送一个get请求requests.get('https://www.bilibili.com/')
部分网站设置了反爬,在发送request请求时,如果未携带请求头headers则会将该请求视为非法请求,这时需在请求中加入headers参数、
headers = {'User-Agent': # 需要模拟浏览器发送请求'cookies': # 保存登录信息'Referrer': # 访问源至哪里}
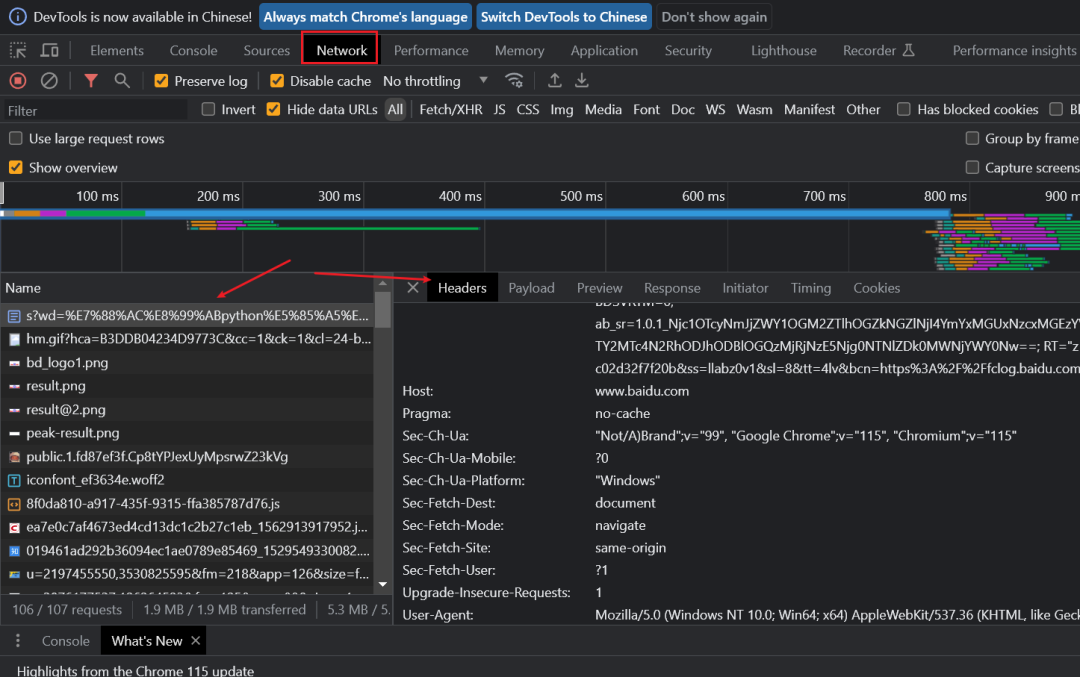
可打开浏览器,进入开发者模式,找到network中查看请求头参数
获取响应内容
使用response接收服务器的响应内容
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'}response = requests.get('https://www.bilibili.com/',headers=headers)print(response)
打印的结果,状态码为200代表成功

# 查看响应内容,返回的是Unicode格式的数据print(re.text)# 查看响应内容,返回的字节流数据print(re.content)# 查看完整的url地址print(re.url) # 输出 https://www.bilibili.com/# 查看响应头部的字符编码print(re.encoding) # 输出 utf-8# 查看响应码print(re.status_code) # 输出 200
解析内容
服务器响应后,可对response进行内容解析,不同的数据类型有不同的解析方式
解析html数据:正则表达式(RE模块)、Xpath、Beautiful soup、CSS
解析json数据:json模块
解析二进制数据:以wb的方式写入文件保存
保存数据
数据库(MySQL、Mongdb、Redis)或文件形式保存
爬取B站视频
对视频网页进行分析
在B站中找到想要爬取的视频网址,例如
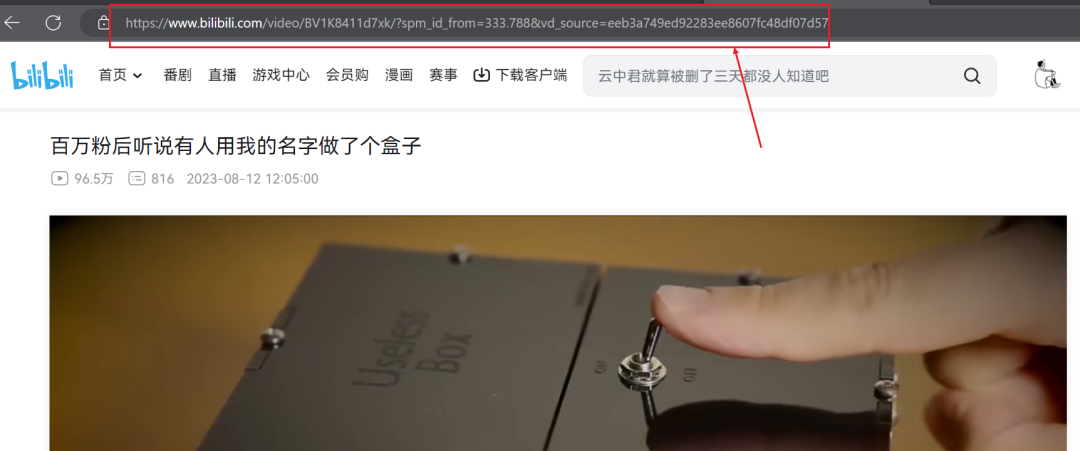
使用浏览器开发者模式,打开该网页的源代码,找到视频资源请求的url,如图所示
或者使用postman工具对该url地址发送请求,查看网页的源代码
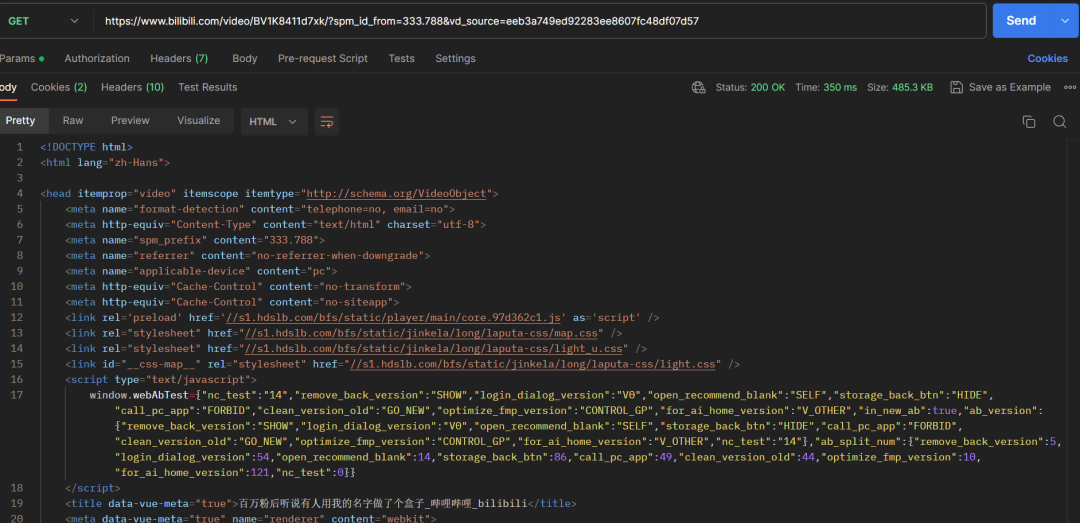
利用python获取该地址的源代码
import requestsheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36',}# 使用response接收服务器的响应url = 'https://www.bilibili.com/video/BV1K8411d7xk/?spm_id_from=333.788&vd_source=eeb3a749ed92283ee8607fc48df07d57'response = requests.get(url=url, headers=headers)print(response.text)
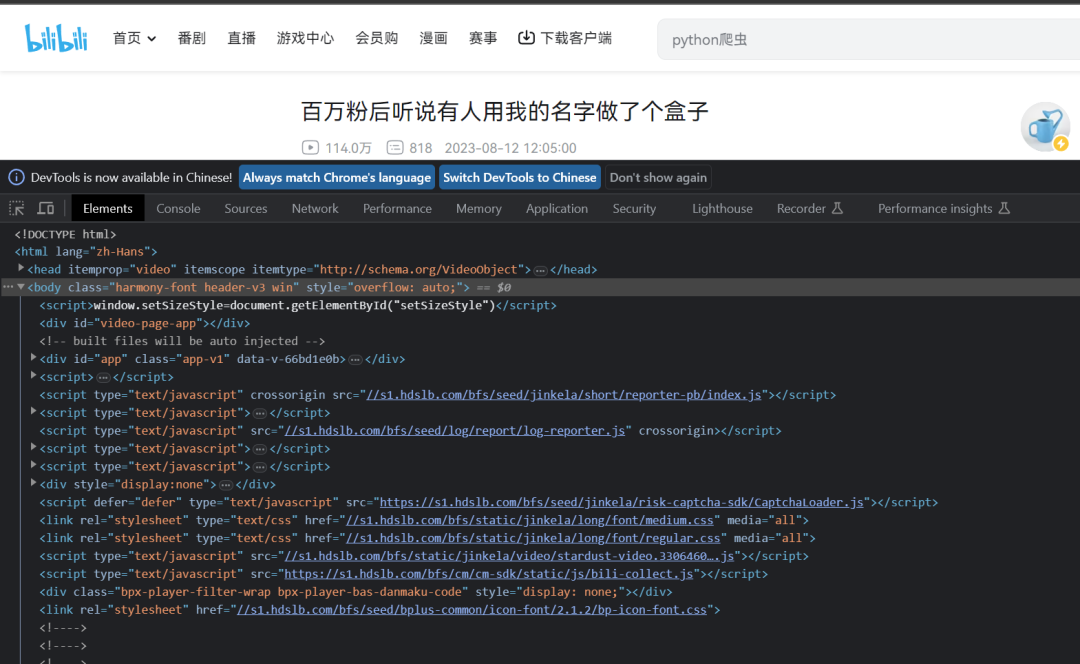
查看网页源代码发现第三个script标签中有请求视频资源地址的url
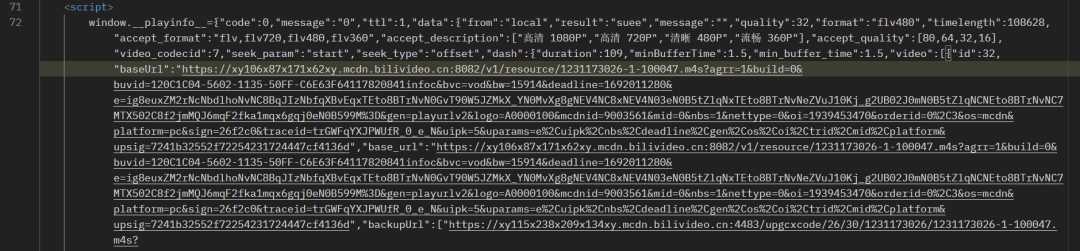
# script标签内的内容window.__playinfo__={json格式数据}
在该script标签中去除首部的window.__playinfo__=后,大括号内是一个json格式的数据,里面有需要的视频资源地址信息,对该json进行格式化显示后

大致的json内容
{...,'data':{...,'video':[{'id': ,'baseUrl': ,}],'audio':[{'id': ,'baseUrl': ,}],...}}
B站的视频资源在script标签中的data中的dash内,视频资源的音频和视频是分开的两个url地址
代码实现
发送请求至服务器,并接收服务器的响应
import requests, json, osfrom bs4 import BeautifulSoupheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36',}# 使用response接收服务器的响应url = 'https://www.bilibili.com/video/BV1K8411d7xk/?spm_id_from=333.788&vd_source=eeb3a749ed92283ee8607fc48df07d57'response = requests.get(url=url, headers=headers)
对response.text中的html内容进行解析,转化为json对象进行后续操作
使用BeautifulSoup以及json模块对服务器响应的请求结果进行解析
# 对html文本进行解析soup = BeautifulSoup(response.text, 'html.parser')tags_script = soup.find_all('script') # 找到html文件对象中的所有script标签target_script = tags_script[2] # 第三个script标签内的请求是资源文件请求(索引从0开始# 去除掉头部的部分数据temp = target_script.contents[0].replace('window.__playinfo__=', '')"""json.load(): 将文件内的内容解析为json对象json.loads(): 将字符串解析为json对象"""json_data = json.loads(temp)
获取json数据内的视频请求地址以及音频的请求地址
# B站内的资源视频和音频资源分开了video_urls = json_data['data']['dash']['video']audio_urls = json_data['data']['dash']['audio']# 第一个url的清晰度最高video_url = video_urls[0]['baseUrl']audio_url = audio_urls[0]['baseUrl']
爬取视频和音频资源,并写入文件中保存到本地
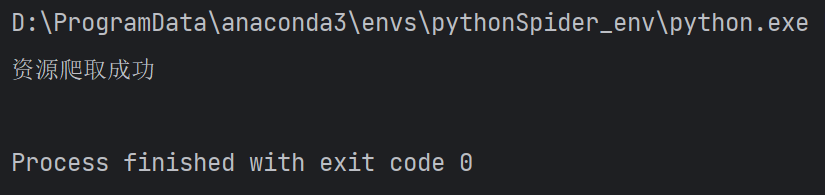
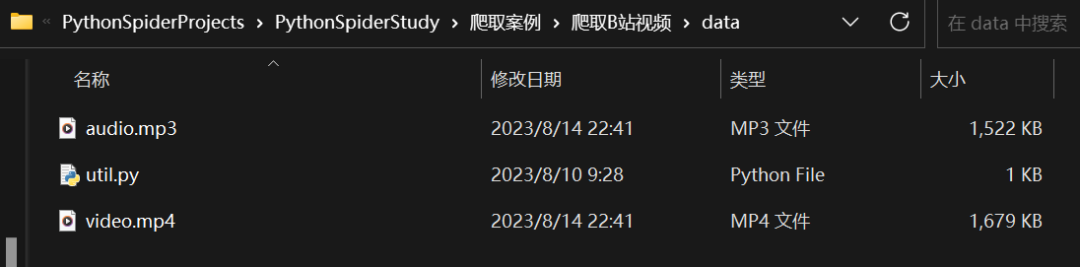
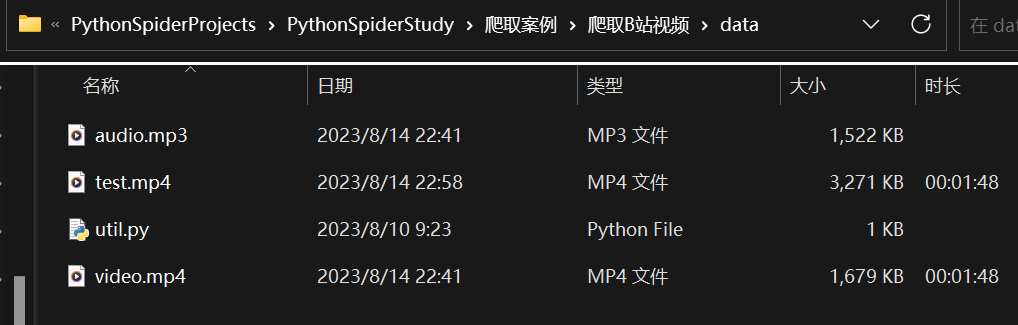
video_data = requests.get(video_url, headers=headers)audio_data = requests.get(audio_url, headers=headers)# 存放在data文件中dir = 'data\\'if not os.path.exists(dir): # 如果该文件夹不存在则创建data文件夹os.mkdir(dir)filename_video = './' + dir + '/' + 'video.mp4'filename_audio = './' + dir + '/' + 'audio.mp3'with open(filename_video, mode='wb') as f:f.write(video_data.content)with open(filename_audio, mode='wb') as f:f.write(audio_data.content)print('资源爬取成功')
运行结果
安装ffmpeg,并配置好环境变量后,也可通过代码将音频和视频资源合成完整的视频资源,该工具类的实现代码
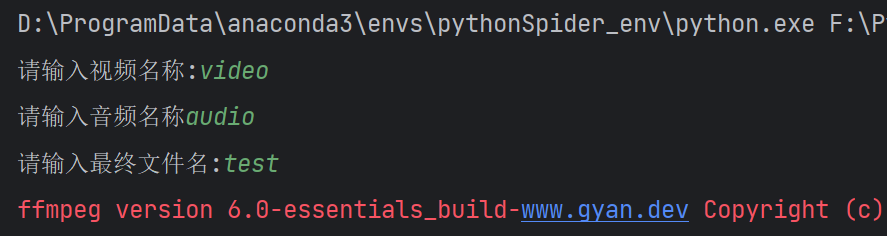
import osvideo = input('请输入视频名称:')audio = input('请输入音频名称')filename = input('请输入最终文件名:')cmd = f'ffmpeg -i {video}.mp4 -i {audio}.mp3 -vcodec copy -acodec copy {filename}.mp4'os.system(cmd)
运行结果
以上就是本次分享的内容,感谢大家支持。您的关注、点赞、收藏是我创作的动力。
万水千山总是情,点个 👍 行不行。














 2842
2842











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









