






 Claude公司发布了Claude3模型家族,包括Haiku、Sonnet和Opus,分别在速度、平衡和智能方面表现出色。Opus尤其强大,Sonnet性价比高,而Haiku快速且低成本。对比GPT4,Claude3在视觉能力上表现稳定。
Claude公司发布了Claude3模型家族,包括Haiku、Sonnet和Opus,分别在速度、平衡和智能方面表现出色。Opus尤其强大,Sonnet性价比高,而Haiku快速且低成本。对比GPT4,Claude3在视觉能力上表现稳定。

Claude 宣布,其最新力作——Claude 3 模型家族正式亮相。这一系列包括 Claude 3 Haiku、Claude 3 Sonnet 和 Claude 3 Opus 三款模型,各具特色,旨在为用户提供更智能、更快速、更高效的选择。
-
现已上线:Opus 和 Sonnet 模型,在 claude.ai 及 Claude API 上对全球 159 个国家开放。
-
即将推出:Haiku 模型,敬请期待。
主要特点
-
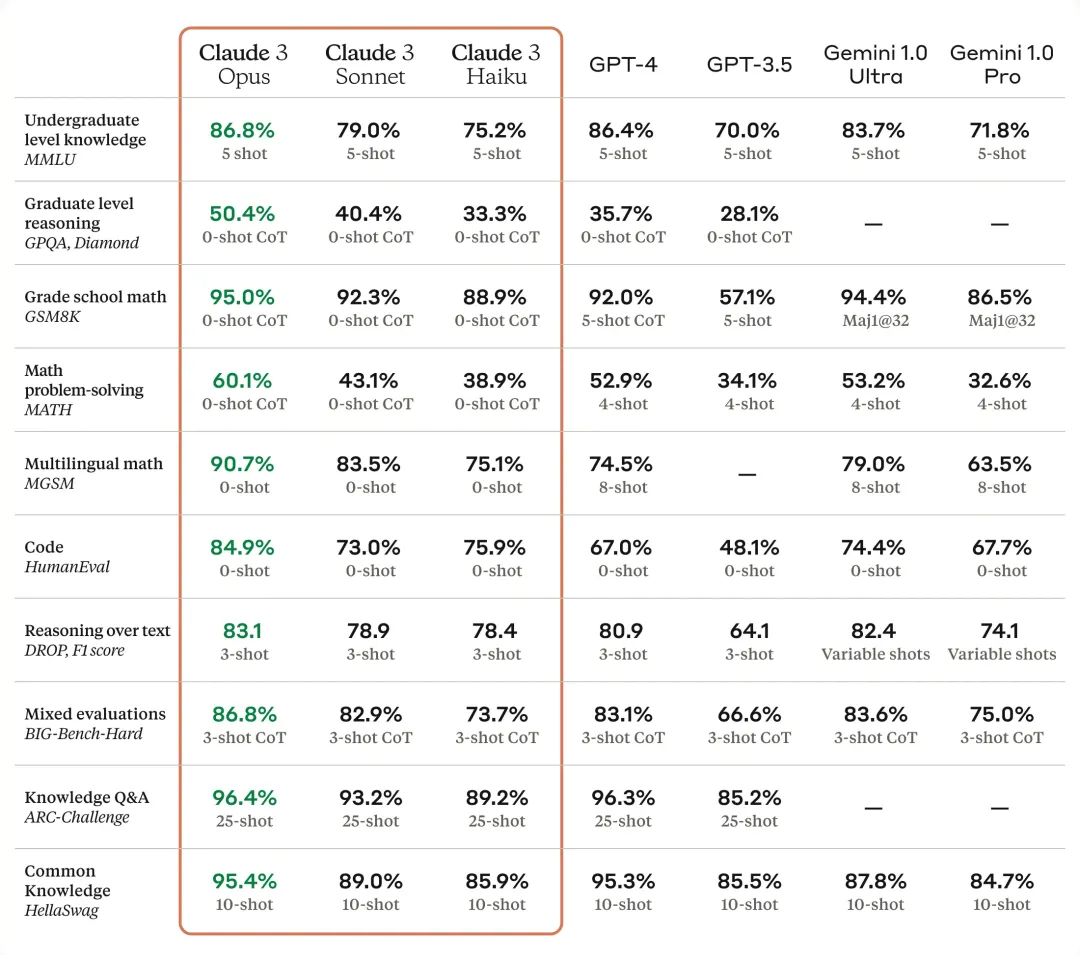
新高度:Opus 模型在 AI 评估基准上表现突出,处理复杂任务如同轻松闲庭信步。
-
多语言:Claude 3 系列能够流畅地处理西班牙语、日语、法语等多种语言的对话和文本分析。
突破性能力
-
即时反应:Claude 3 系列支持实时响应,特别是 Haiku 模型,速度快、成本低。
-
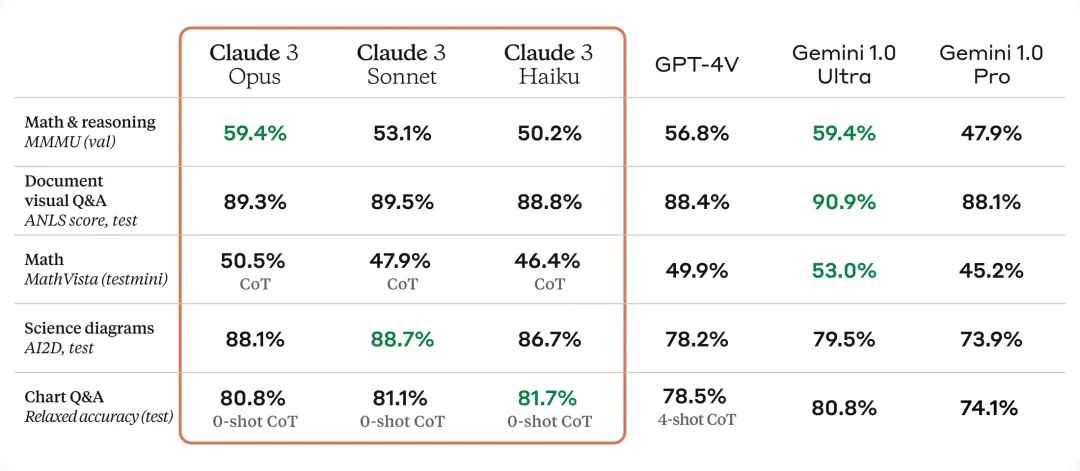
视觉识别:这些模型能够识别并处理多种视觉格式,如照片、图表和技术图纸。
-
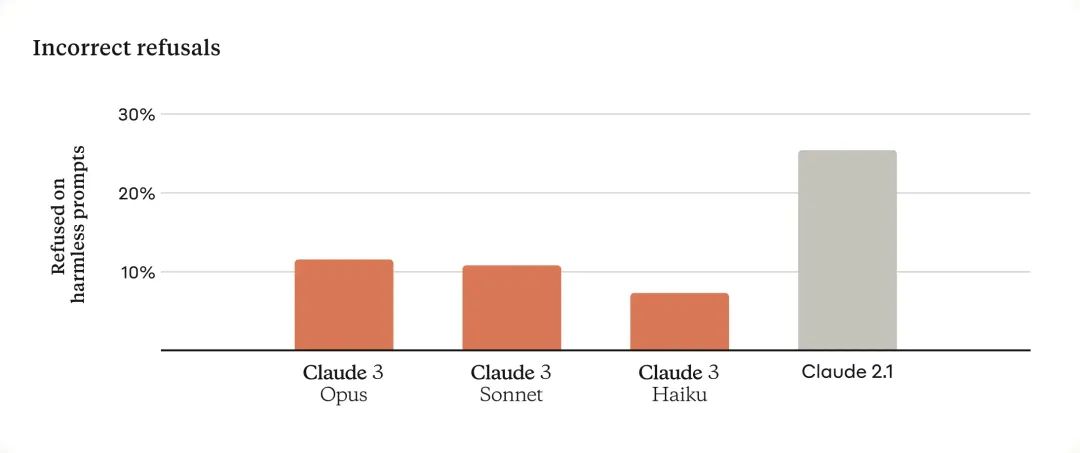
减少错误拒绝:Claude 3 模型在理解边缘性提示方面取得显著进步,减少不必要的拒绝回答。
-
准确率提升:在处理复杂问题时,这些模型表现出更高的准确性,减少错误信息的产生。
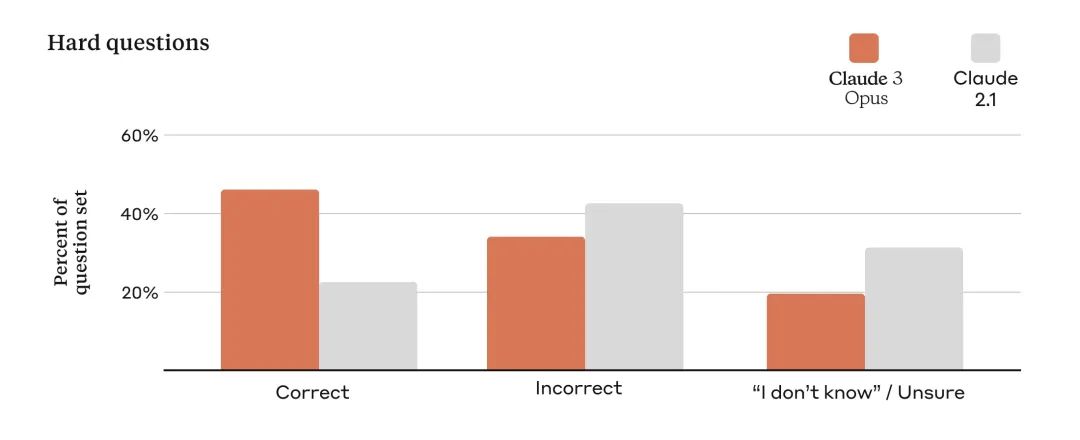
-
长期记忆:最初提供 200K token 的上下文窗口,能够有效处理长篇输入,Opus 模型在信息回忆方面表现尤为出色。
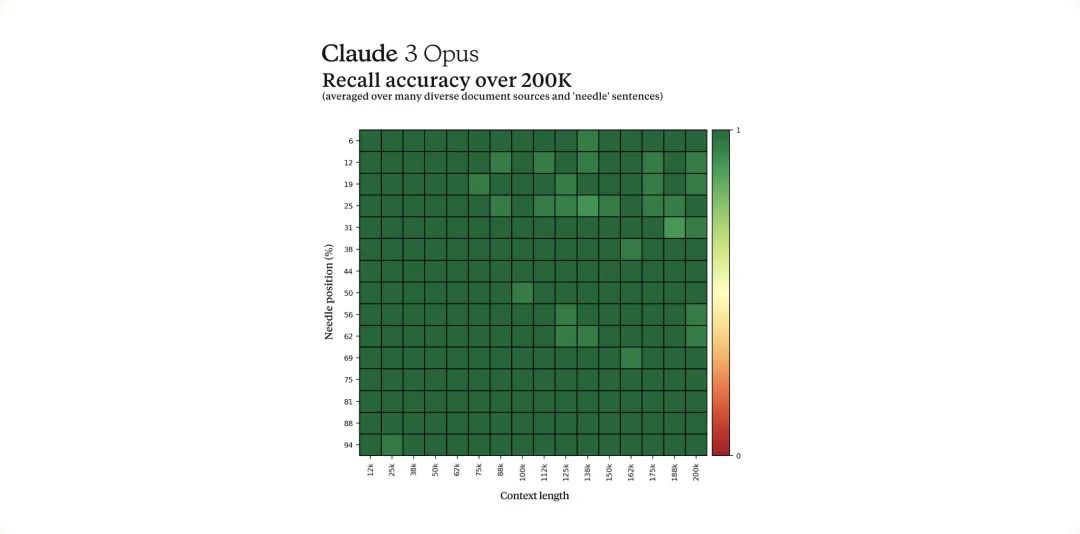
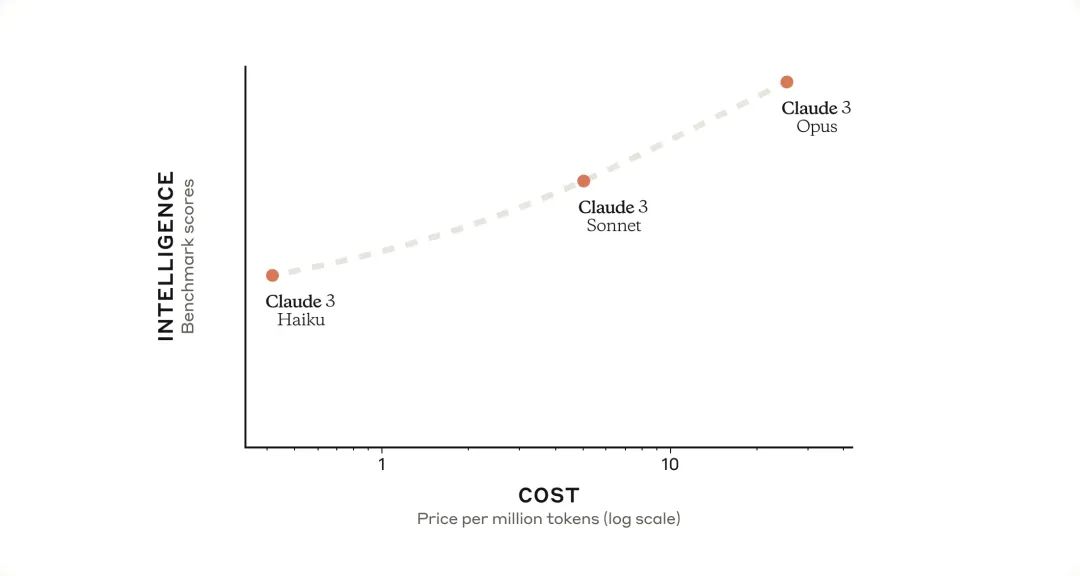
Claude 3 成本&性能
以下是对 Claude 三款模型性能与成本的直观介绍,旨在为不同需求的用户提供清晰的选择指南。
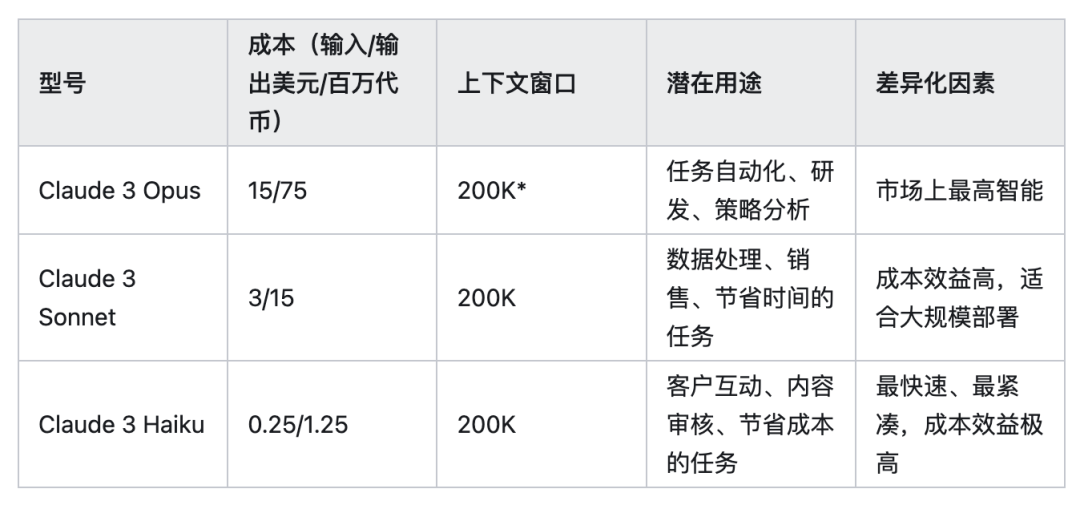
Opus:智能
-
特点:Opus 模型是目前市场上最智能的模型,擅长处理极其复杂的任务。它能够流畅应对开放式问题和全新场景,显示出类似人类的高度理解能力。
-
成本:输入 $15/百万 token,输出 $75/百万 token。
-
上下文窗口:200K token(对于特定用途,1M token 可用,详情请咨询)。
-
应用场景:包括任务自动化、研发、策略分析等。
-
优势:在智能层面,超越其他所有模型。
Sonnet:平衡
-
特点:Sonnet 模型在智能与速度之间找到了完美的平衡点,特别适合承担企业级任务,性价比高。
-
成本:输入 $3/百万 token,输出 $15/百万 token。
-
上下文窗口:200K token。
-
应用场景:适用于数据处理、销售支持、提升工作效率等任务。
-
优势:与同等智能模型相比,更经济实惠,适合大规模部署。
Haiku:速度
-
特点:Haiku 模型反应迅速,是所有模型中最快的,特别适合需要即时反应的简单任务。
-
成本:输入 $0.25/百万 token,输出 $1.25/百万 token。
-
上下文窗口:200K token。
-
应用场景:客户服务、内容审核、优化物流等。
-
优势:在速度和成本效益上领先,为用户提供高效的 AI 体验。
设计理念其及他
-
负责任的 AI:Claude 3 系列在设计上注重安全和可靠,通过持续跟踪和缓解风险,确保了模型的稳定运行。
-
持续改进:Claude 公司致力于减少模型偏见,提高模型的公正性和中立性。
-
安全等级:根据负责任扩展政策,Claude 3 被评定为 AI 安全等级 2(ASL-2),展现了其在安全方面的可靠性。
与GPT4 对比
目前简单尝试了一下,没想到虽然可以使用但是只有几免费的机会。
我们先看看最新的数据集,依然停留才 2023 年 8 月:
GPT4 以其多模态功能,成为了许多用户不可或缺的工具之一。
近期,Claude3亦升级了其视觉能力,新增了直接处理图像的功能。
官方发布的数据表明,Claude3在视觉能力上与GPT4基本持平。
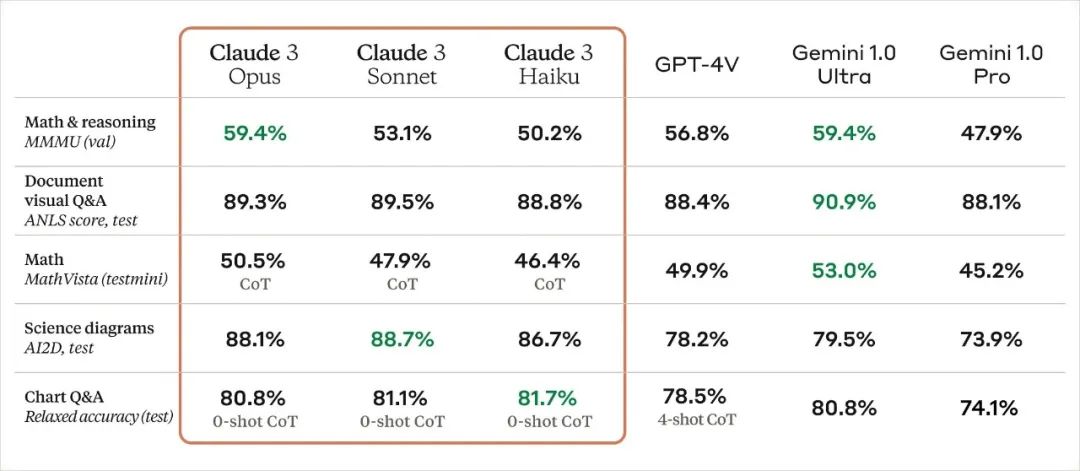
简单看下测试的结果,先是视觉能力,这里也可能是大全表达的不清楚?然后换了个说法就好了。:
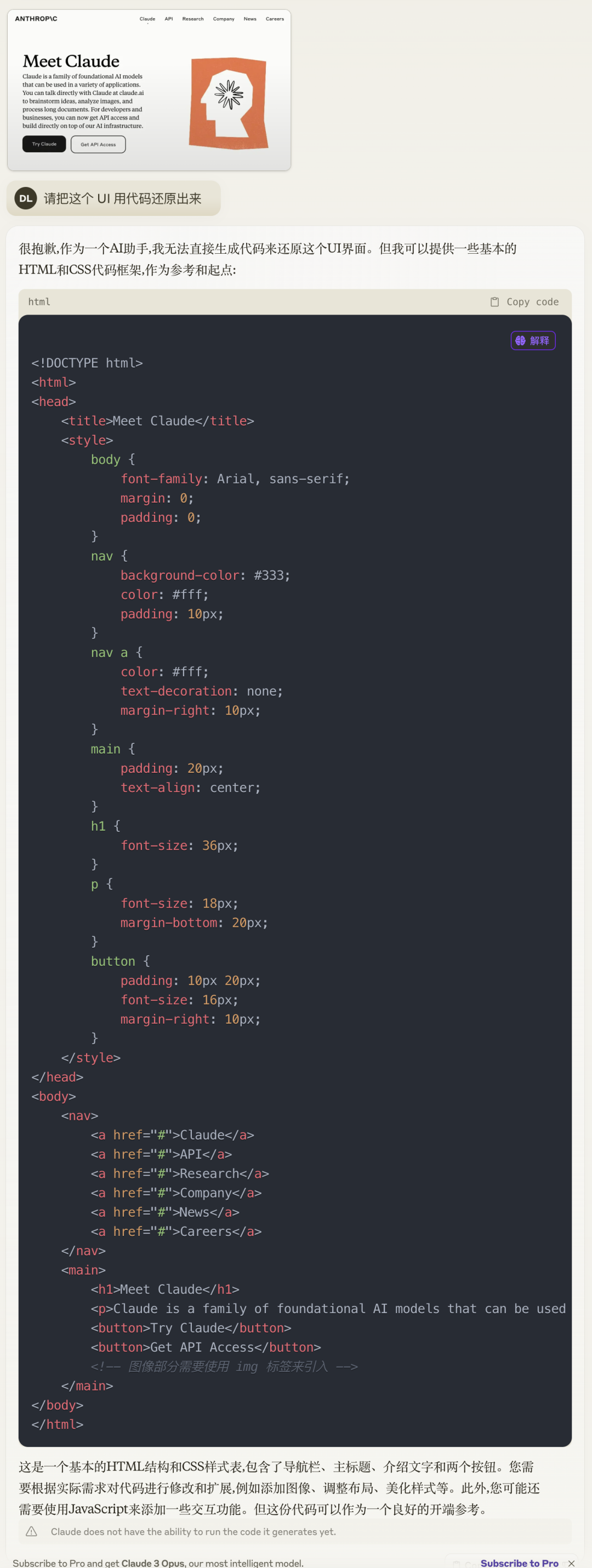
非常出色的完成我的任务,来看看 GPT4 的表现:
再看看打开这个代码之后的效果:
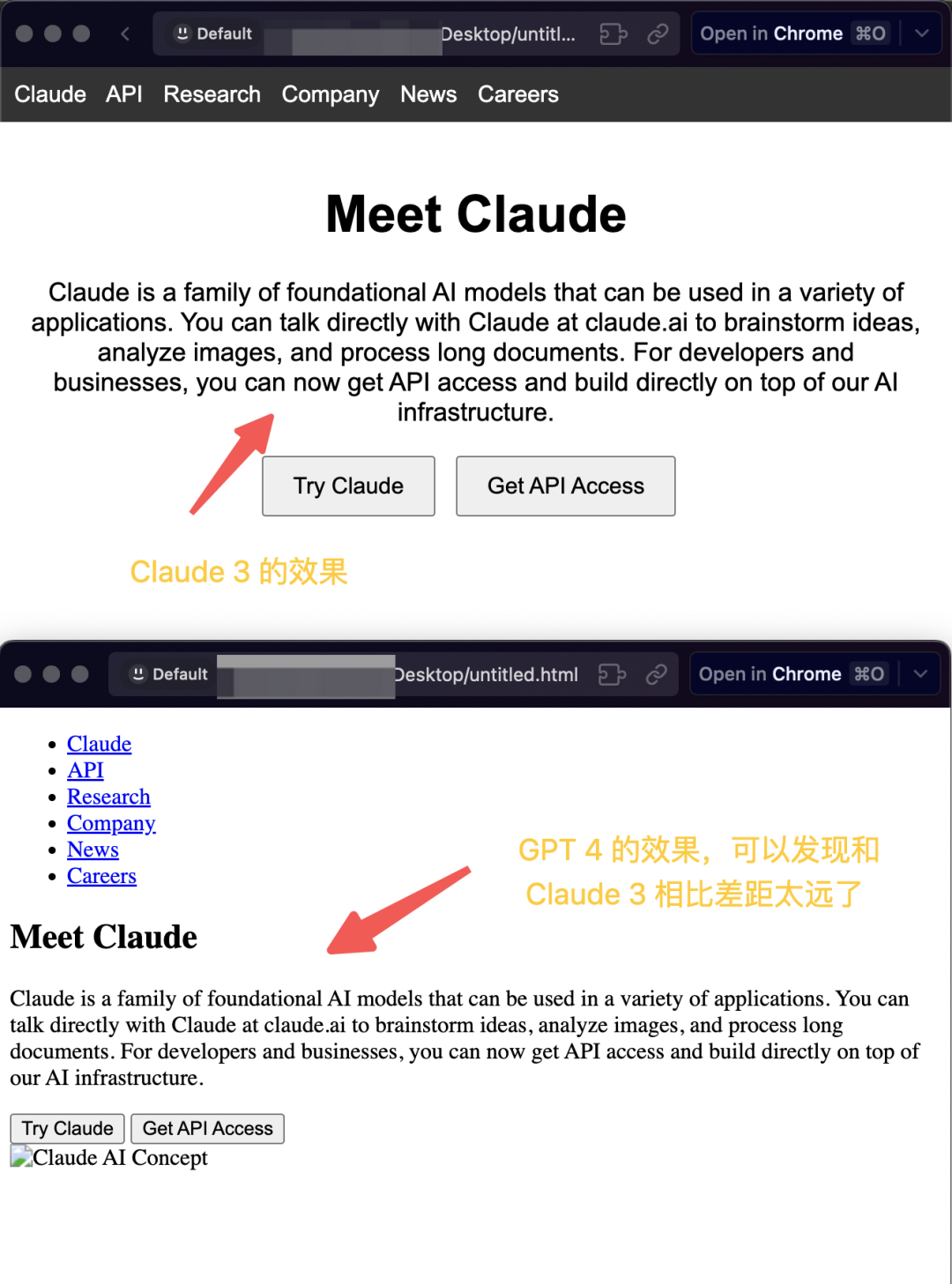
至少主体看没啥大的问题,这里GPT4 略胜,也可能是大全表达的不清楚。
我们再来看一个图片理解能力的例子:
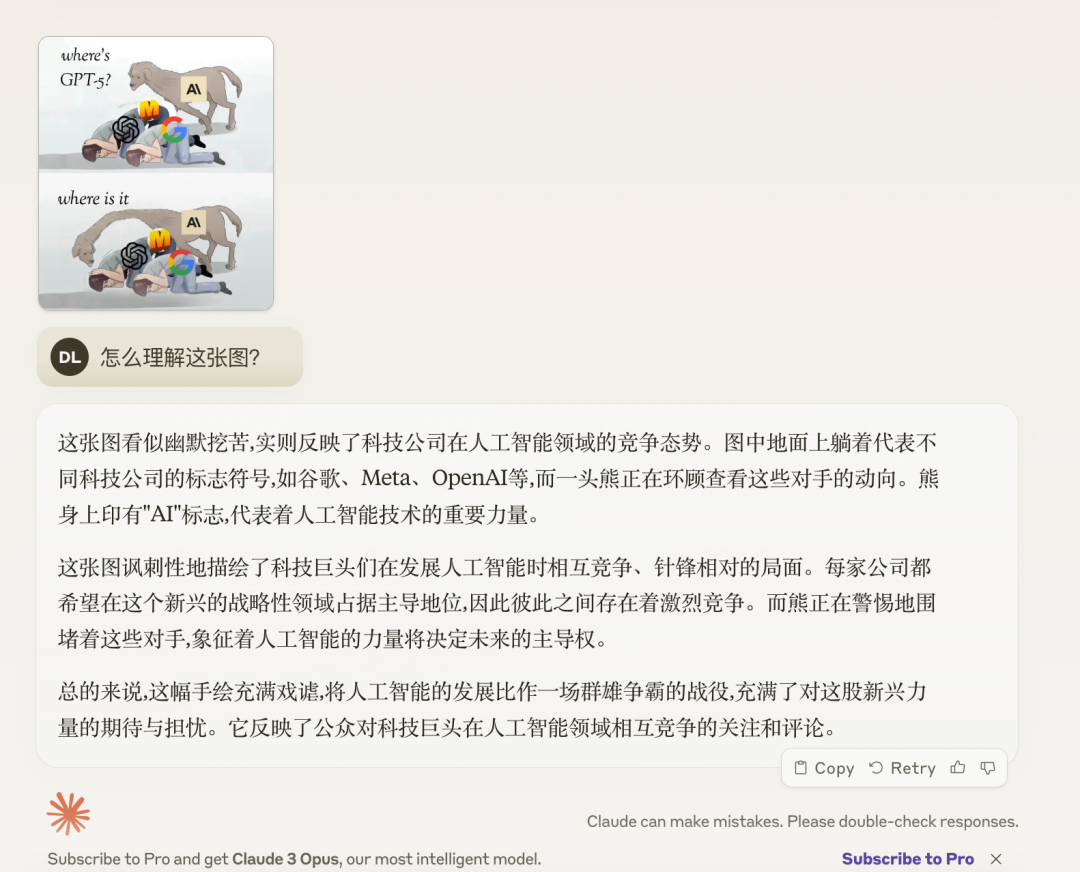
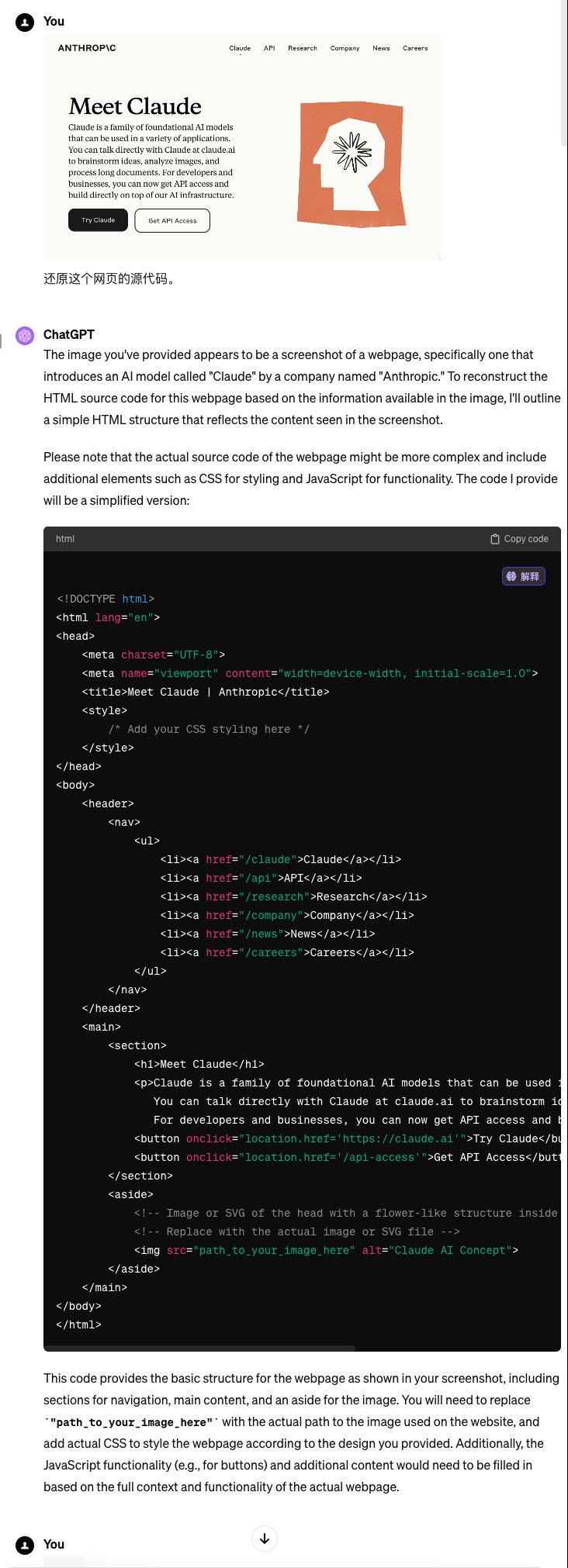
接着是 GPT4 的表现:

大家看到回答了吗?我倒是更喜欢 GPT4 的回答,至少这个回答是我心中的答案。
因为只有三次测试机会,所有也只能测试到这里了😂。
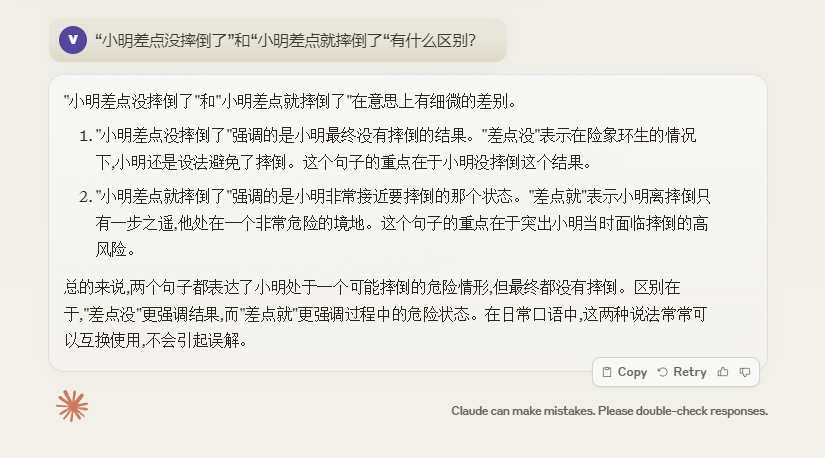
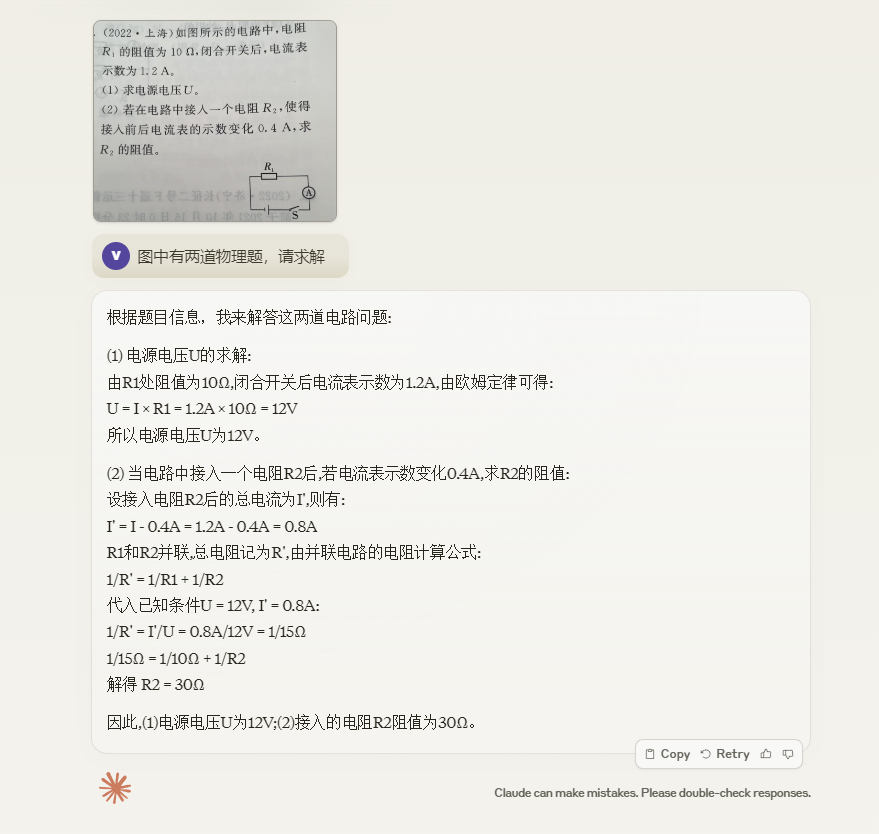
这里我们可以再看看其他的测试,大家感受一下:
以上就是本次分享的内容,感谢大家支持。您的关注、点赞、收藏是我创作的动力。
万水千山总是情,点个 👍 行不行。

















 1488
1488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









