






不懂RNNs,何以搞定时间序列分析?
本文将从RNN工作原理、LSTM工作原理、GRU工作原理三个方面,带您一文搞懂RNNs工作原理。

RNNs工作原理
一、RNN工作原理
RNN(Recurrent Neural Network):循环神经网络是一类专门用于处理序列数据的神经网络。
与传统的神经网络相比,RNN的最大区别在于其能够在不同时间点共享参数,并通过循环连接捕捉序列中的时间依赖关系。

RNN(循环神经网络)
RNN架构的核心特性在于其隐藏层中的节点之间存在循环连接,使得当前时刻的输出不仅依赖于当前时刻的输入,还依赖于之前时刻的输出或隐藏状态。
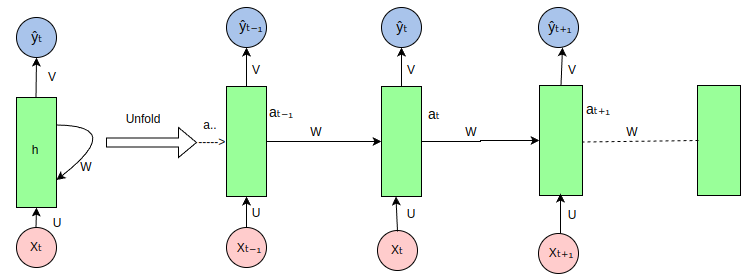
RNN(循环神经网络)架构
-
输入层:接收输入数据,并将其传递给隐藏层。输入不仅仅是静态的,还包含着序列中的历史信息。
-
隐藏层:核心部分,捕捉时序依赖性。隐藏层的输出不仅取决于当前的输入,还取决于前一时刻的隐藏状态。
-
输出层:根据隐藏层的输出生成最终的预测结果。
输入层- 隐藏层 - 输出层
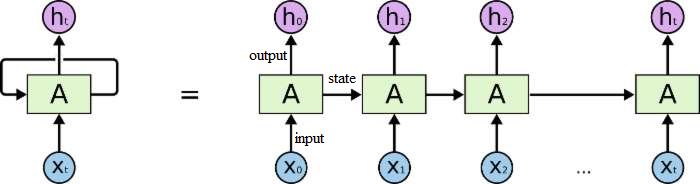
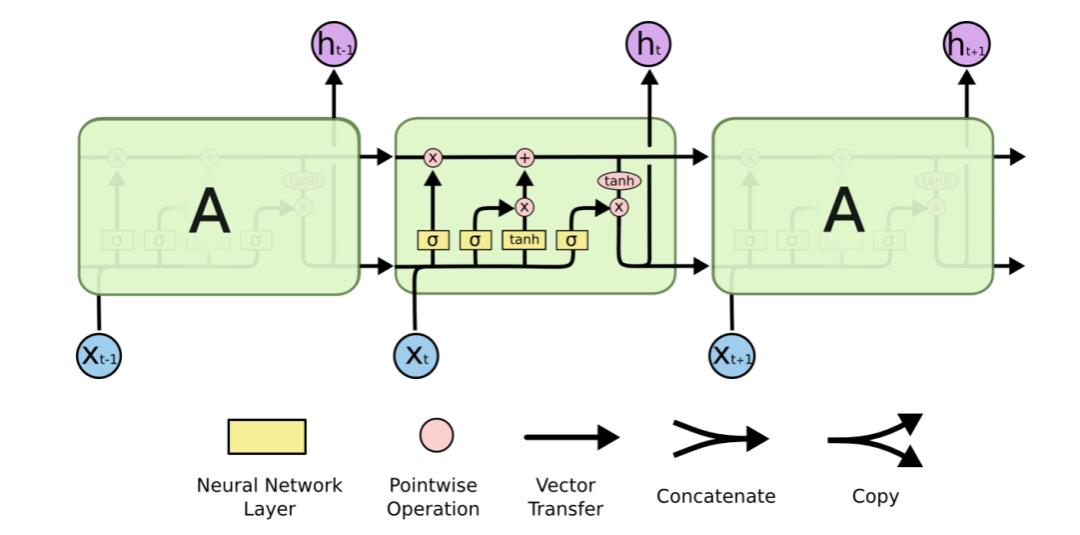
工作原理:第一个词被转换成了机器可读的向量,然后 RNN 逐个处理向量序列。
RNN(循环神经网络)工作原理
-
隐藏状态的传递
在处理序列数据时,RNN将前一时间步的隐藏状态传递给下一个时间步。
-
隐藏状态充当了神经网络的“记忆”,它包含了网络之前所见过的数据的相关信息。
-
这种传递机制使得RNN能够捕捉序列中的时序依赖关系。
隐藏状态的传递
-
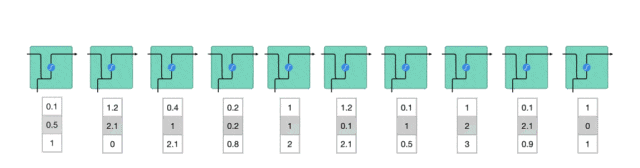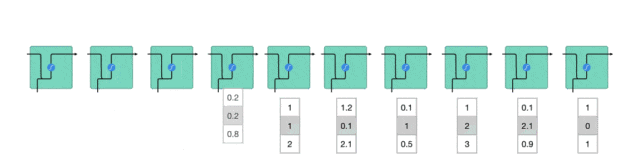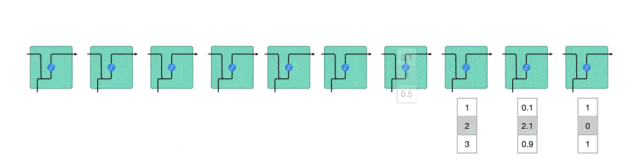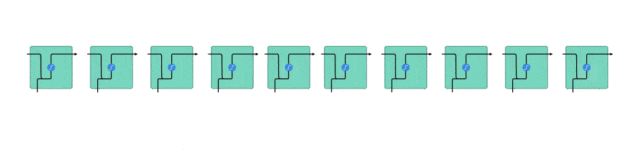
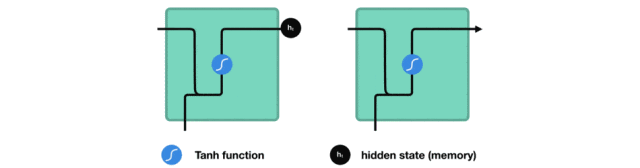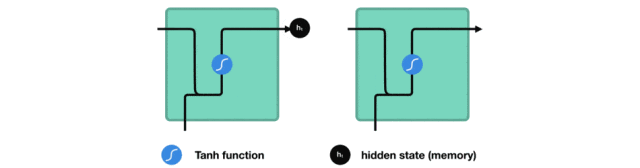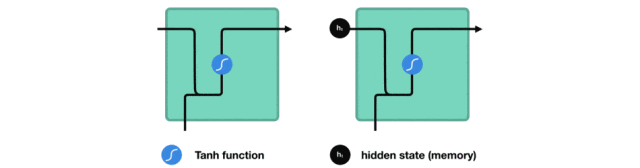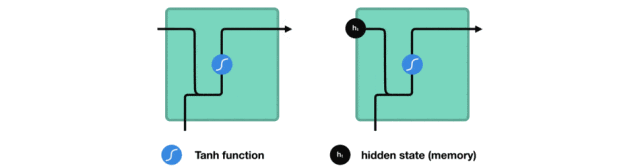
隐藏状态的计算
-
当前输入和先前隐藏状态被组合成一个向量,这个向量融合了当前和先前的信息。
-
组合后的向量经过一个tanh激活函数的处理,输出新的隐藏状态。这个新的隐藏状态既包含了当前输入的信息,也包含了之前所有输入的历史信息。
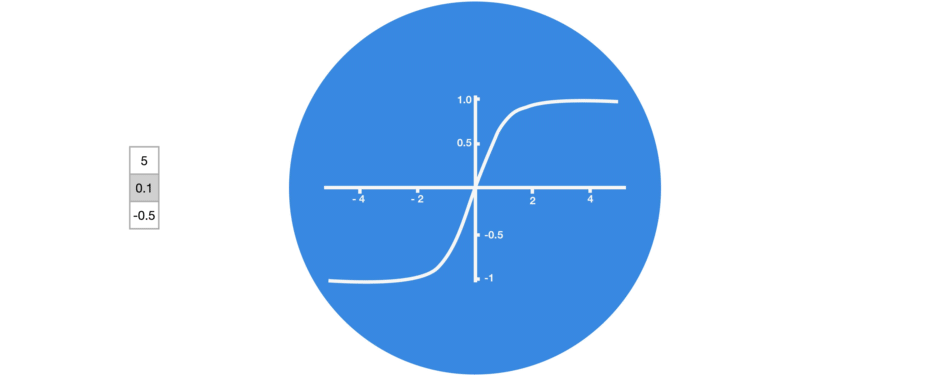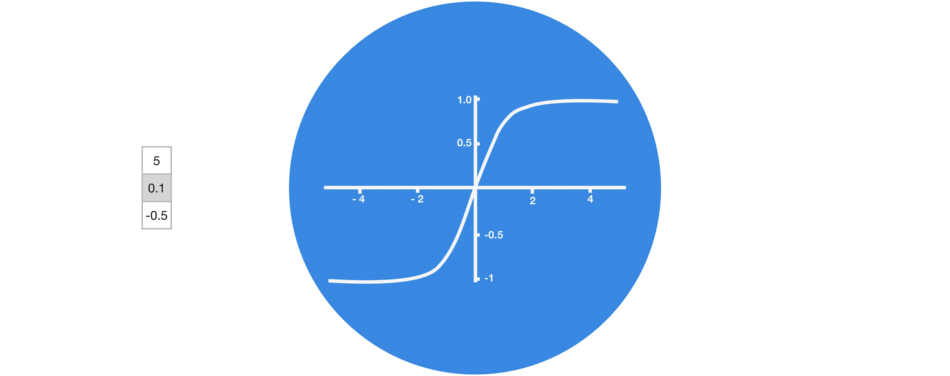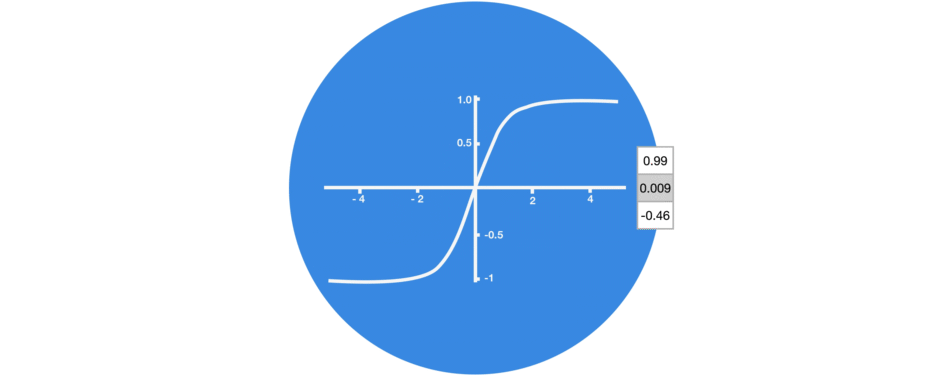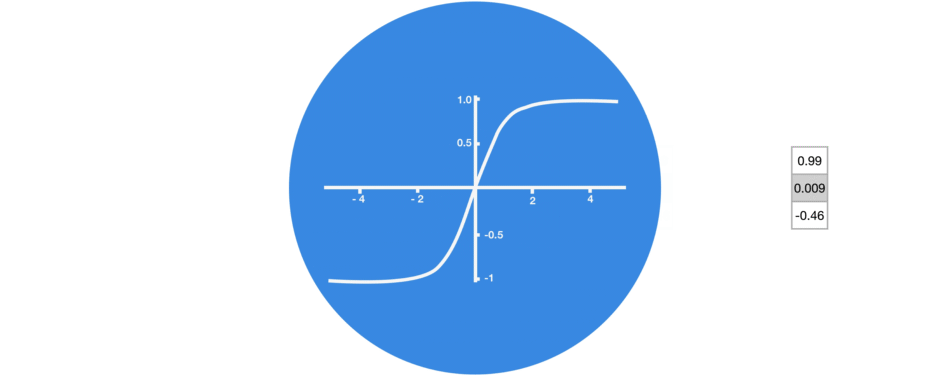
tanh激活函数(区间-1~1)
-
新的隐藏状态被输出,并被传递给下一个时间步,继续参与序列的处理过程。
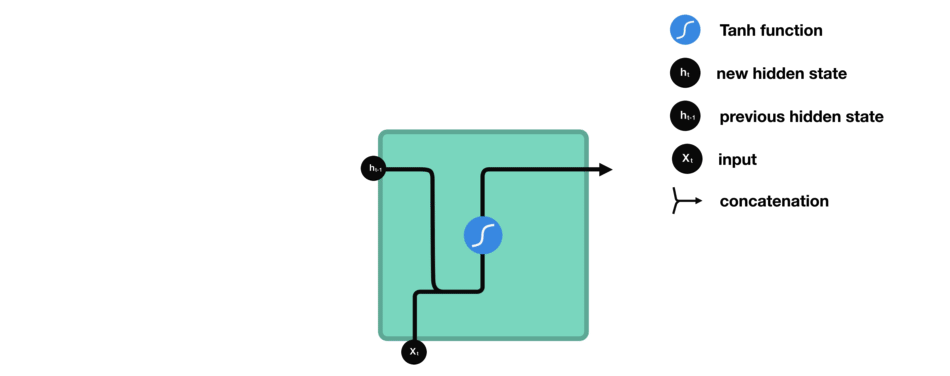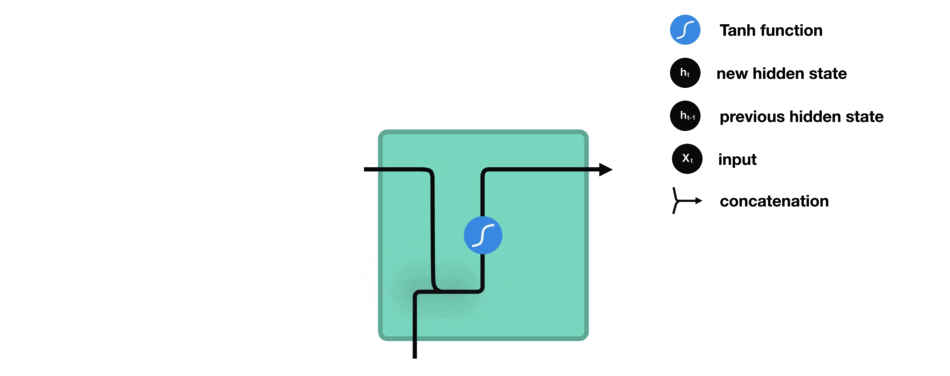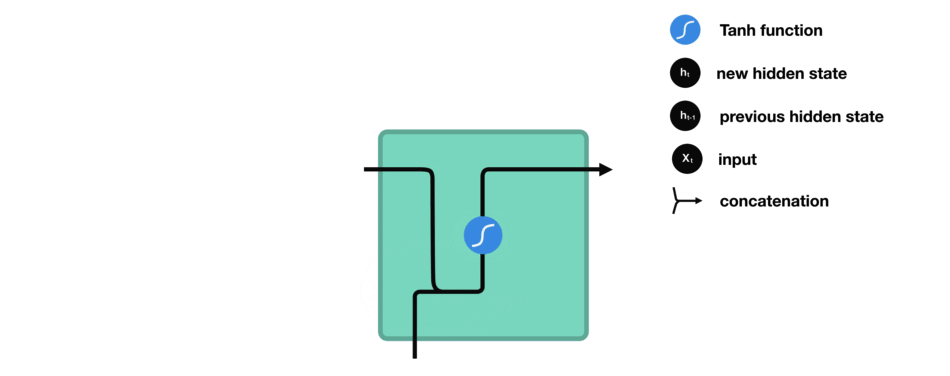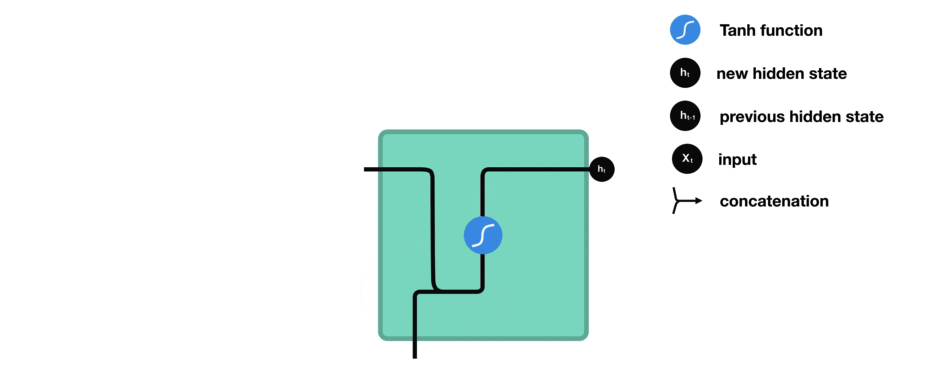
隐藏状态的计算
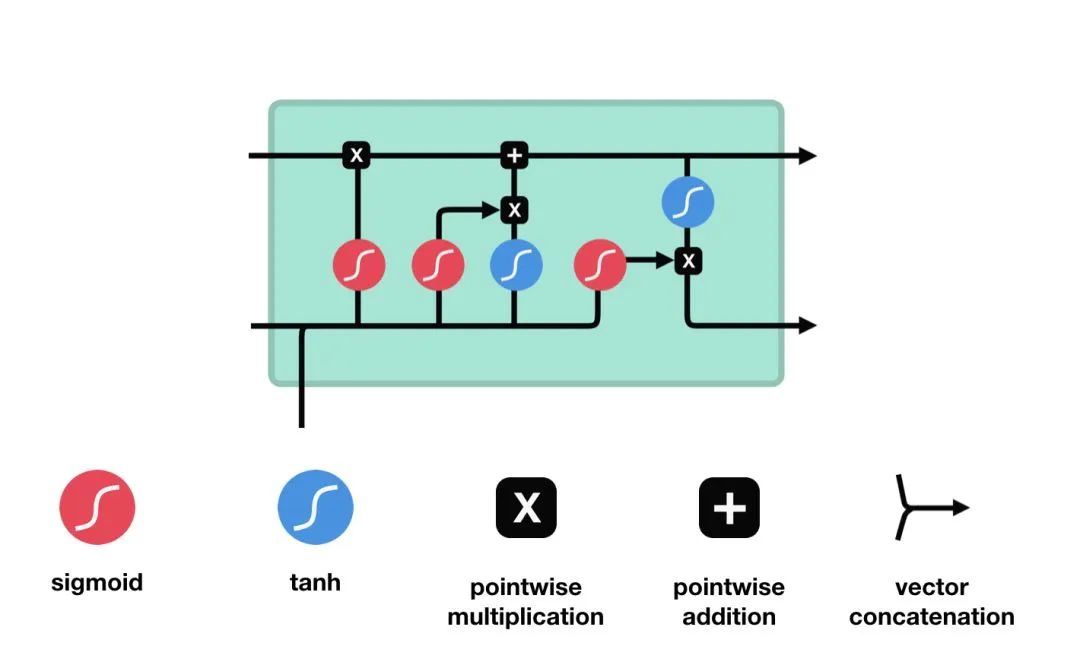
二、LSTM工作原理
LSTM(Long Short Term Memory):长短期记忆是一种特殊的循环神经网络(RNN),旨在解决传统RNN在处理长序列时面临的梯度消失和梯度爆炸问题。
通过引入记忆单元、输入门、遗忘门和输出门等机制,LSTM能够在更长的序列中有效捕捉和传递信息,从而展现出更优越的性能。
LSTM(长短期记忆)
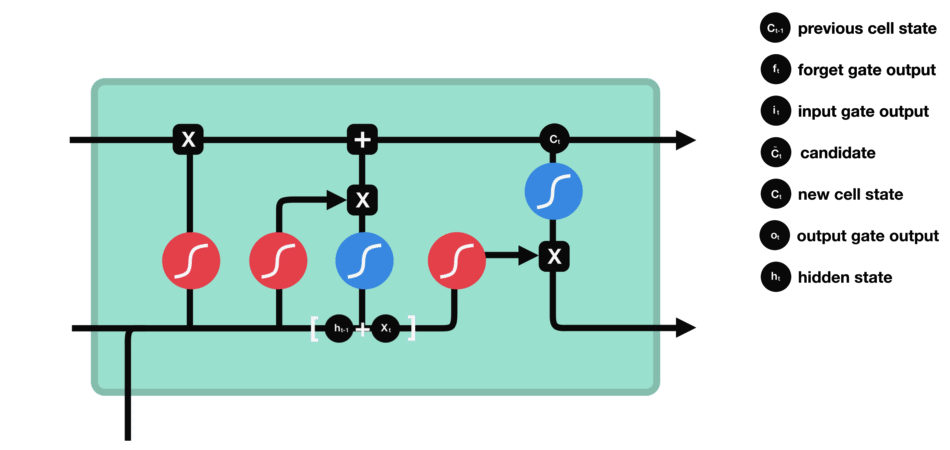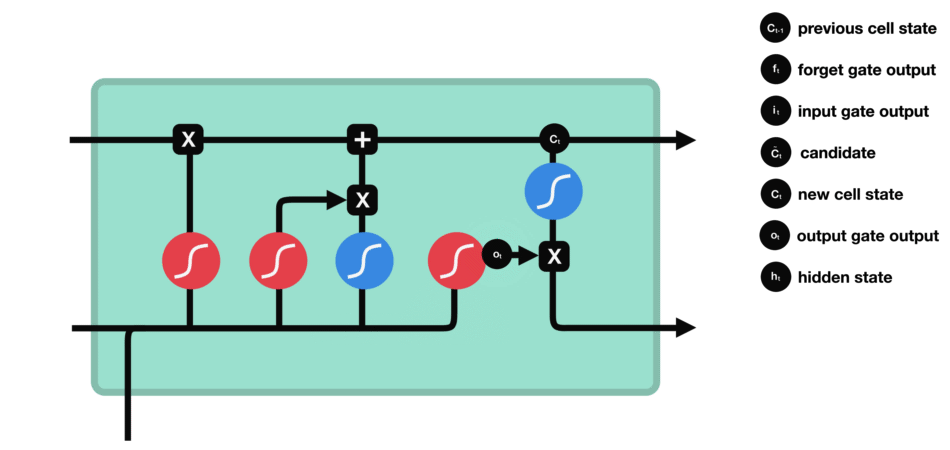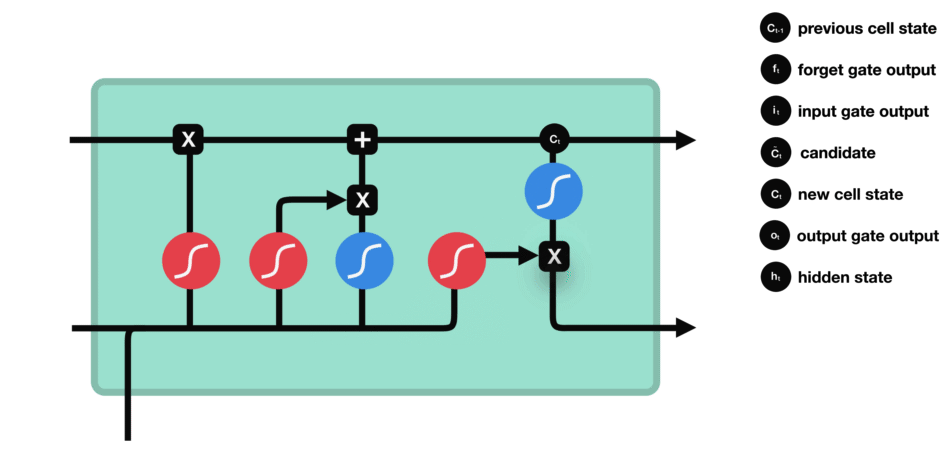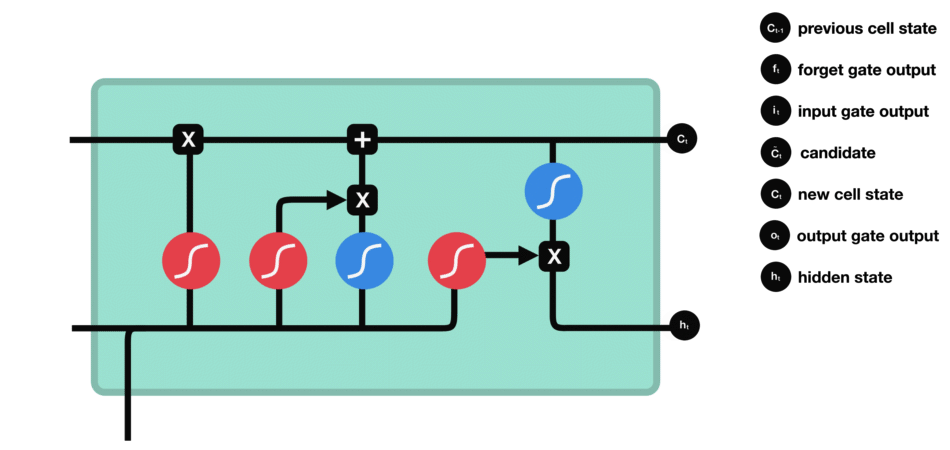
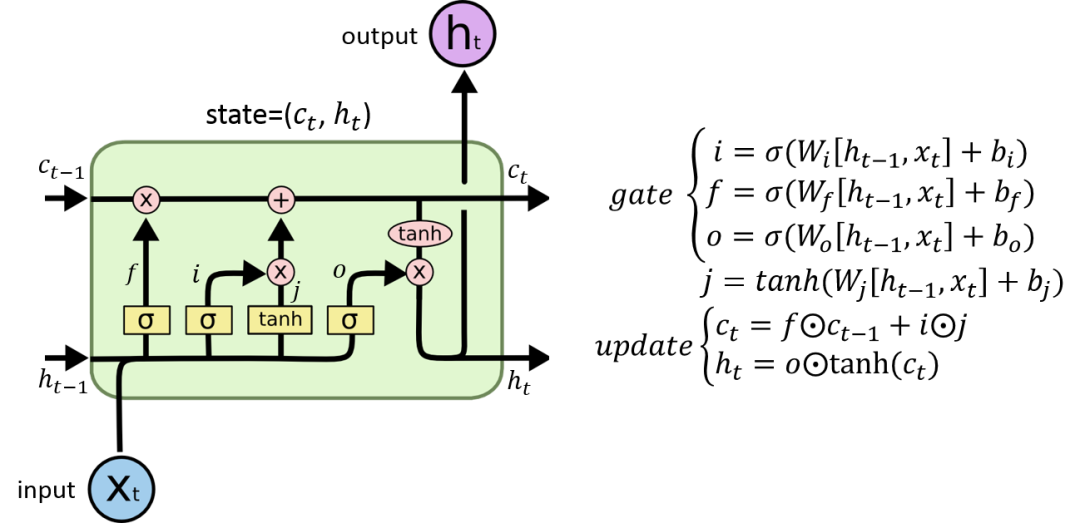
LSTM架构的核心特性在于一个LSTM单元中包括三个门结构,即输入门(Input Gate)、遗忘门(Forget Gate)和输出门(Output Gate)。
-
输入门(Input Gate):输入门的作用是决定哪些新信息应该被添加到记忆单元中。
-
遗忘门(Forget Gate):遗忘门的作用是决定哪些旧信息应该从记忆单元中遗忘或移除。
-
输出门(Output Gate):输出门的作用是决定记忆单元中的哪些信息应该被输出到当前时间步的隐藏状态中。
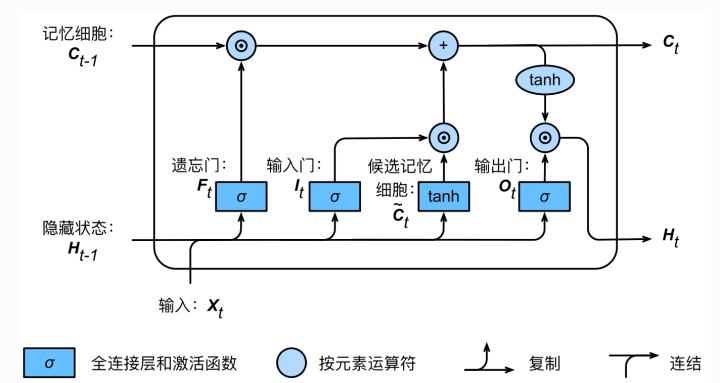
LSTM(长短期记忆)架构
工作原理:通过输入门筛选重要信息并生成候选记忆,通过遗忘门决定保留哪些旧记忆,最后通过输出门结合筛选后的记忆与当前状态,生成隐藏状态以传递信息。
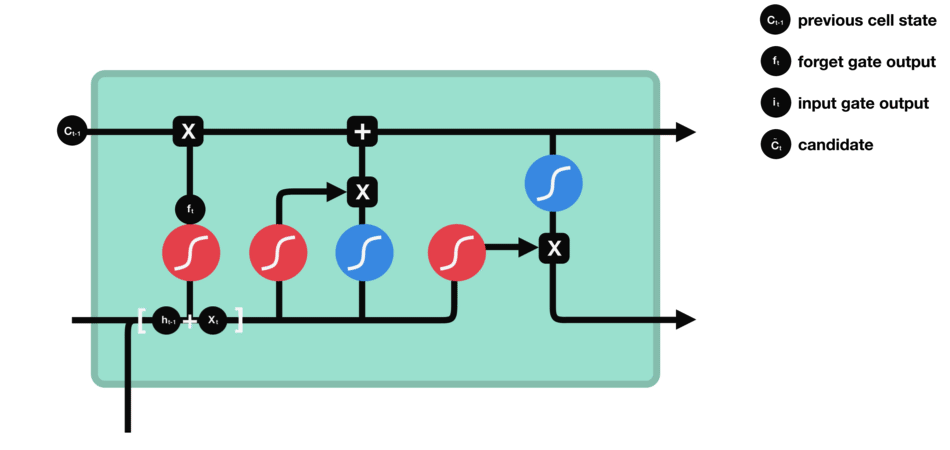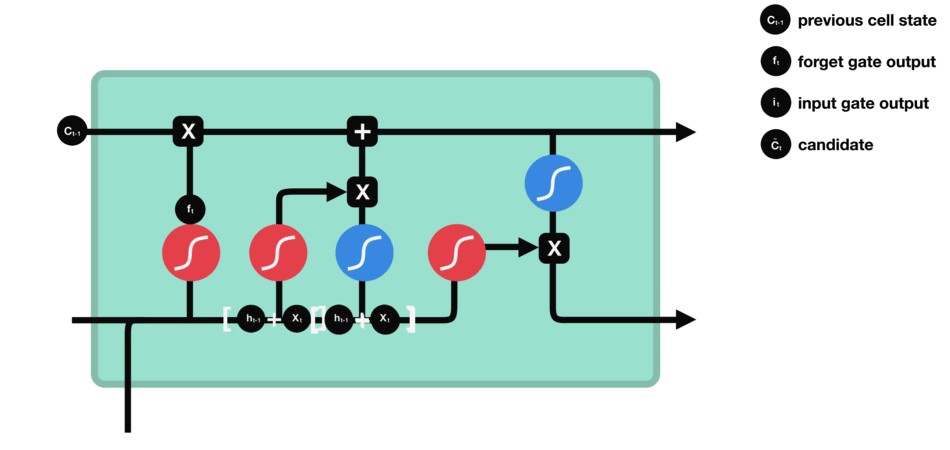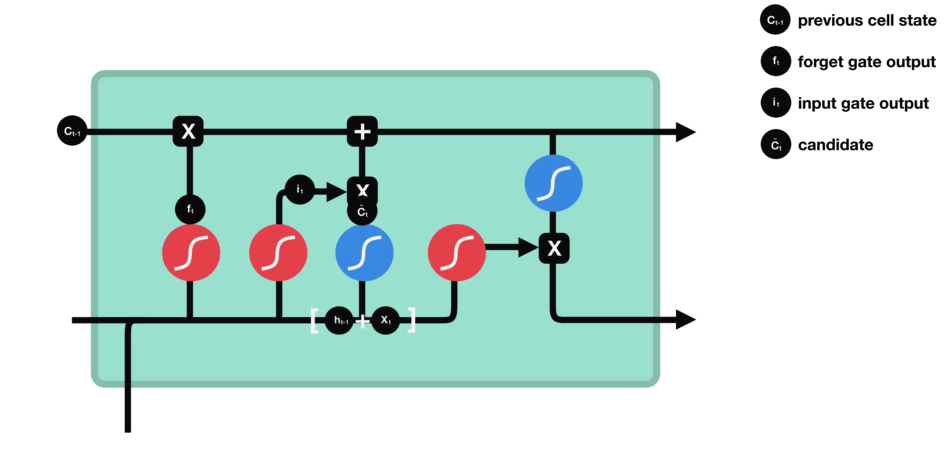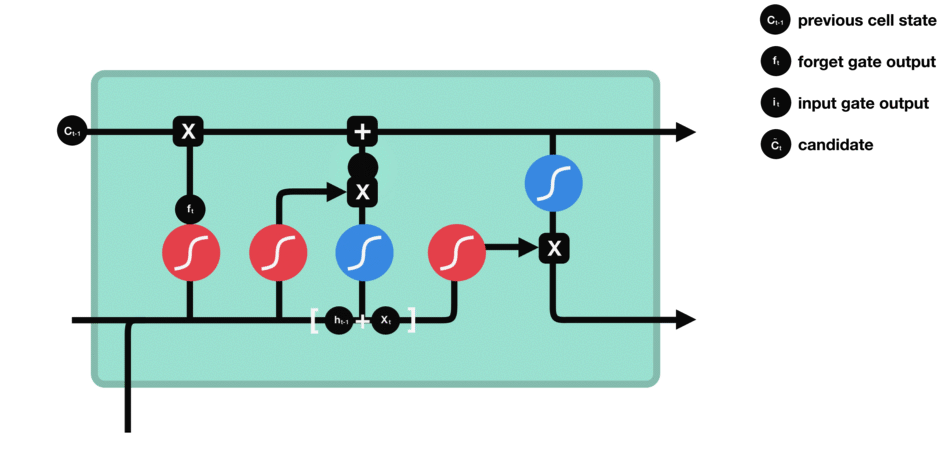
LSTM(长短期记忆)工作原理
-
输入门:输入门由一个sigmoid激活函数和一个tanh激活函数组成。通过sigmoid函数筛选重要信息并结合tanh函数生成的新候选信息,共同决定哪些新内容应被添加到记忆单元中。
-
输入门(sigmoid激活函数 + tanh激活函数)
-
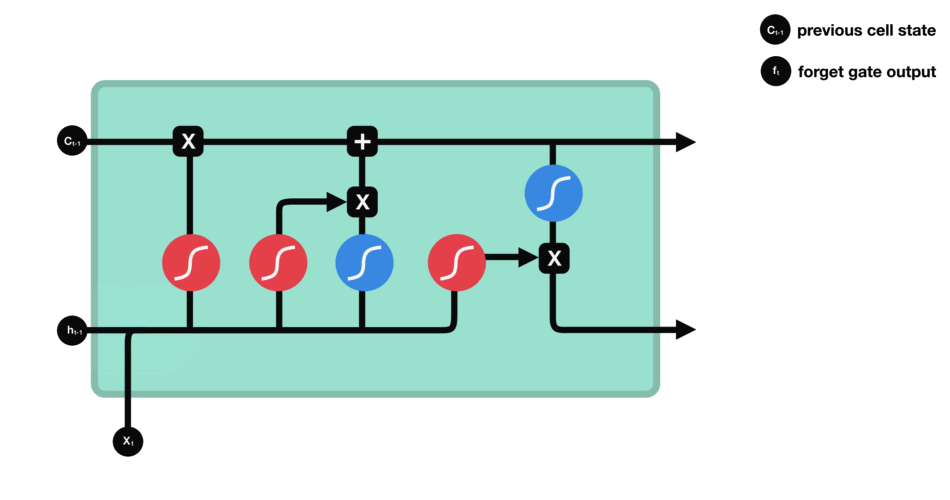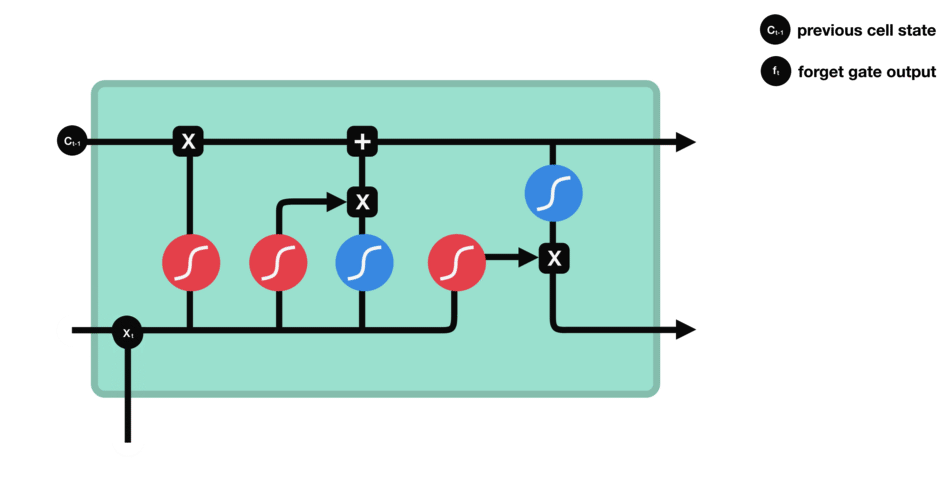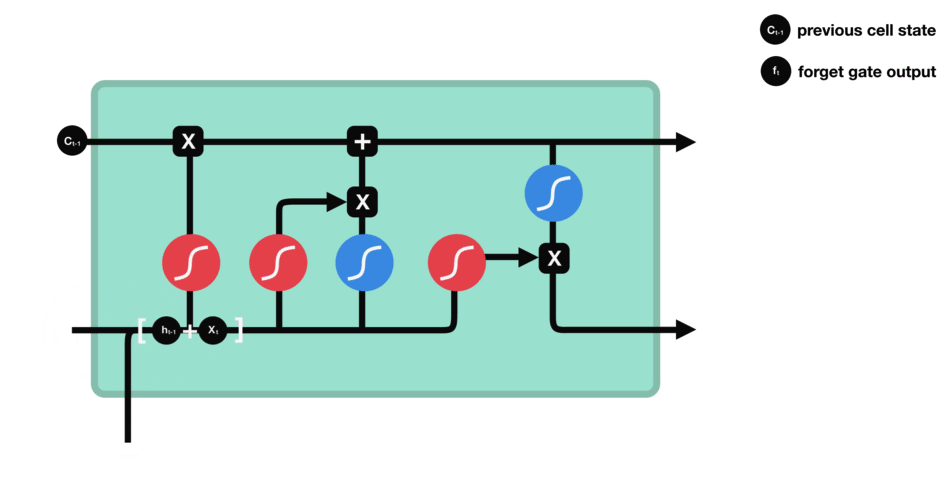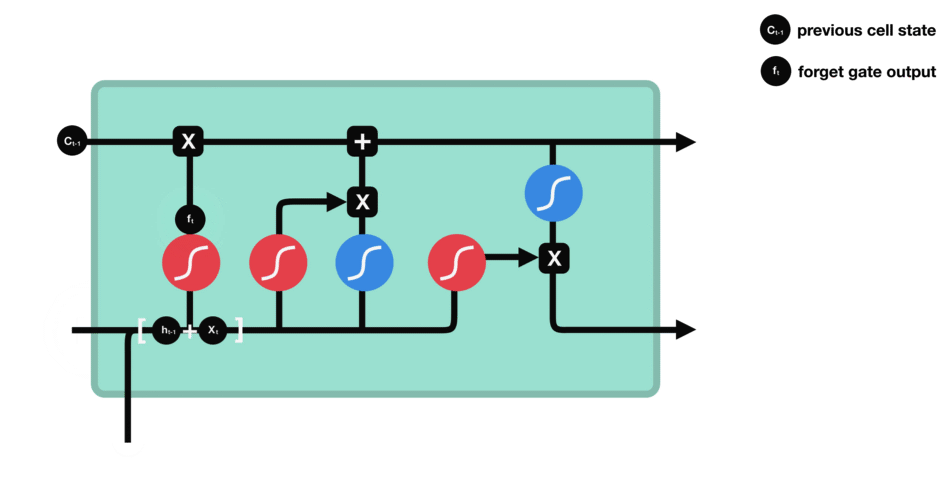
遗忘门:遗忘门仅由一个sigmoid激活函数组成。
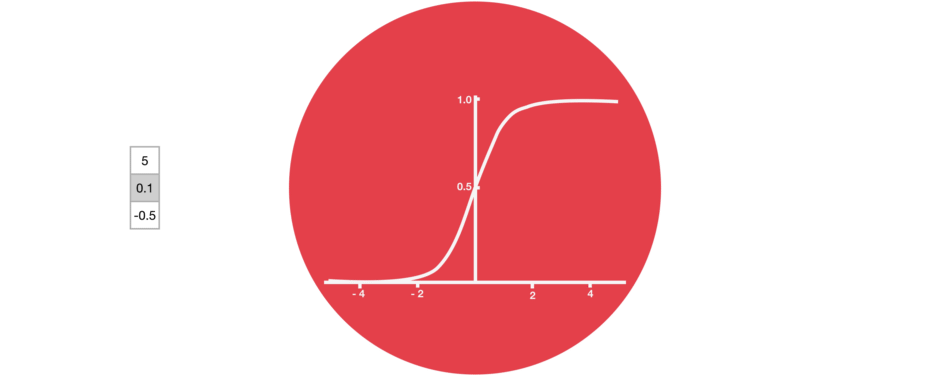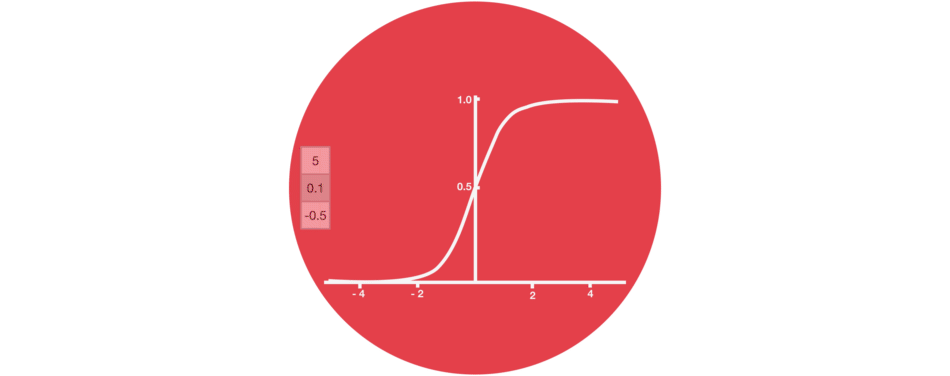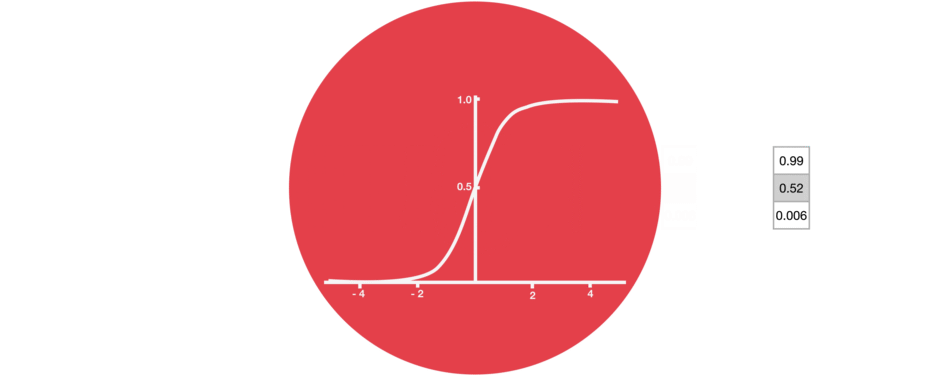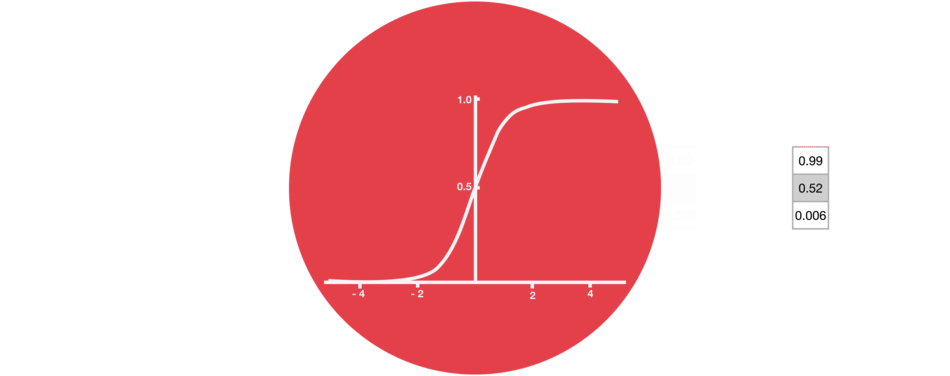
sigmoid激活函数(区间0~1)
-
-
sigmoid函数的输出直接与记忆单元的当前状态相乘,用于决定哪些信息应该被保留,哪些应该被遗忘。输出值越接近1的信息将被保留,而输出值越接近0的信息将被遗忘。
-
-
遗忘门(sigmoid激活函数)
-
输出门:输出门同样由一个sigmoid激活函数和一个tanh激活函数组成。通过sigmoid函数筛选应输出的内容,并与tanh函数处理的记忆单元状态结合,生成当前时间步的隐藏状态。
-
输出门(sigmoid激活函数 + tanh激活函数)
三、GRU工作原理
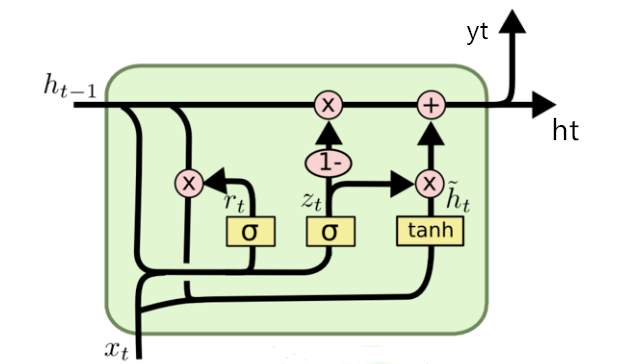
GRU(Gated Recurrent Unit):门控循环单元也是RNN的一种改进结构,同样旨在解决长序列处理中的梯度问题。它通过重置门和更新门来控制信息的流动,使得模型能更有效地捕捉长期依赖关系。
相比LSTM,GRU结构更简洁、高效,且在多数序列建模任务中表现相当甚至更好。
GRU(门控循环单元)
GRU架构的核心特性在于其内部包含两个关键的门控结构,重置门(Reset Gate)和更新门(Update Gate)。
-
重置门(Reset Gate):重置门的作用在于控制前一时刻的隐藏状态在当前时刻的计算中的影响程度。
-
更新门(Update Gate):更新门的核心功能是控制前一时刻的状态信息被带入到当前状态中的程度。
GRU(门控循环单元)架构
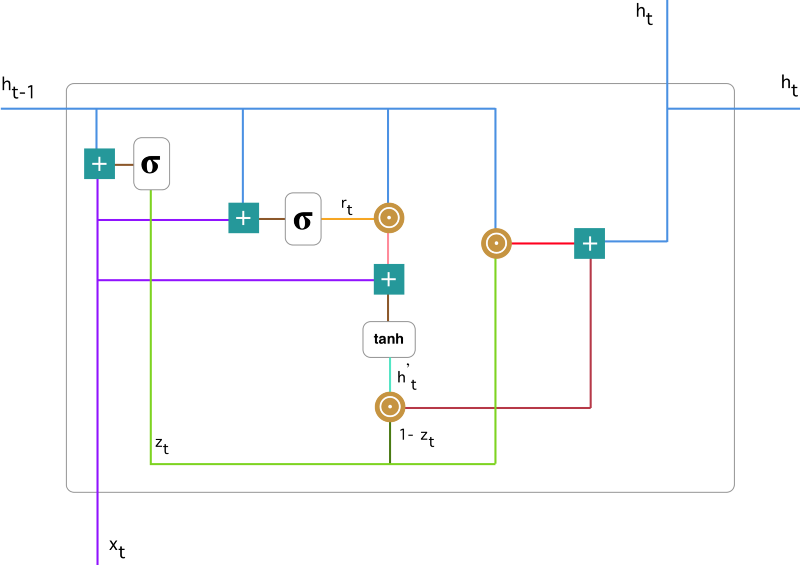
工作原理:GRU通过重置门和更新门机制来灵活控制信息的保留与传递,从而有效处理长序列数据并避免梯度消失问题。
GRU(门控循环单元)工作原理
-
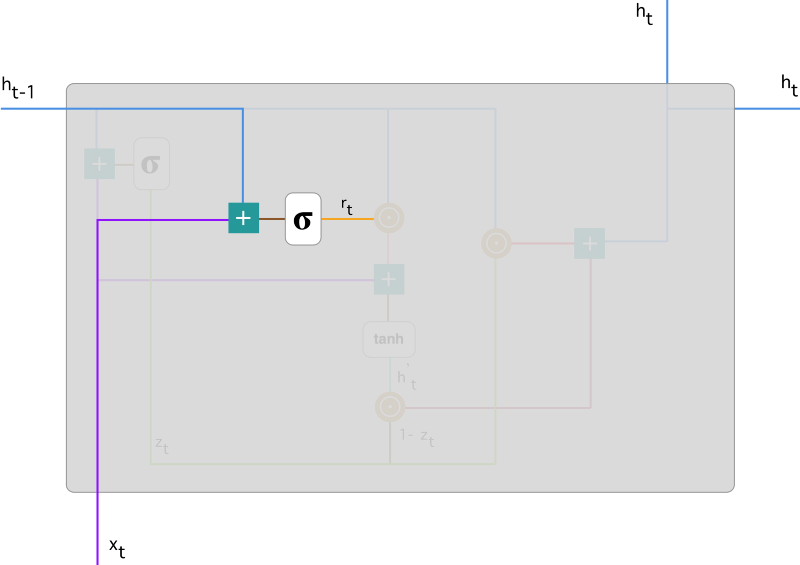
重置门(Reset Gate):重置门决定如何结合新输入与前一时间步的隐藏状态。通过Sigmoid激活,输出0到1之间的值,控制前一时间步隐藏状态的保留或重置。
重置门(Reset Gate)
-
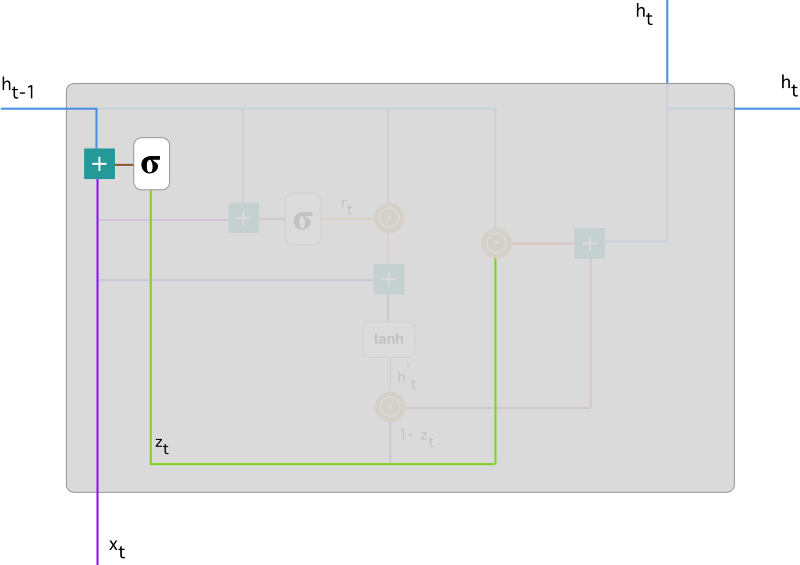
更新门(Update Gate):更新门决定前一时间步隐藏状态在当前更新的贡献。通过Sigmoid激活,输出0到1之间的值,决定前一步隐藏状态的保留程度和新信息的引入量。
更新门(Update Gate)















 4582
4582











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









