







 本文详细介绍了BERT(Bidirectional Encoder Representations from Transformers)的本质、原理及应用,包括其预训练任务(Masked Language Model和Next Sentence Prediction)、在问答系统和聊天机器人中的应用,并探讨了如何利用Transformer的自注意力机制捕捉上下文信息。
本文详细介绍了BERT(Bidirectional Encoder Representations from Transformers)的本质、原理及应用,包括其预训练任务(Masked Language Model和Next Sentence Prediction)、在问答系统和聊天机器人中的应用,并探讨了如何利用Transformer的自注意力机制捕捉上下文信息。
本文将从BERT的本质、BERT的原理、BERT的应用三个方面,带您一文搞懂Bidirectional Encoder Representations from Transformers | BERT。

Google BERT
一、BERT的本质
BERT架构:一种基于多层Transformer编码器的预训练语言模型,通过结合Tokenization、多种Embeddings和特定任务的输出层,能够捕捉文本的双向上下文信息,并在各种自然语言处理任务中表现出色。
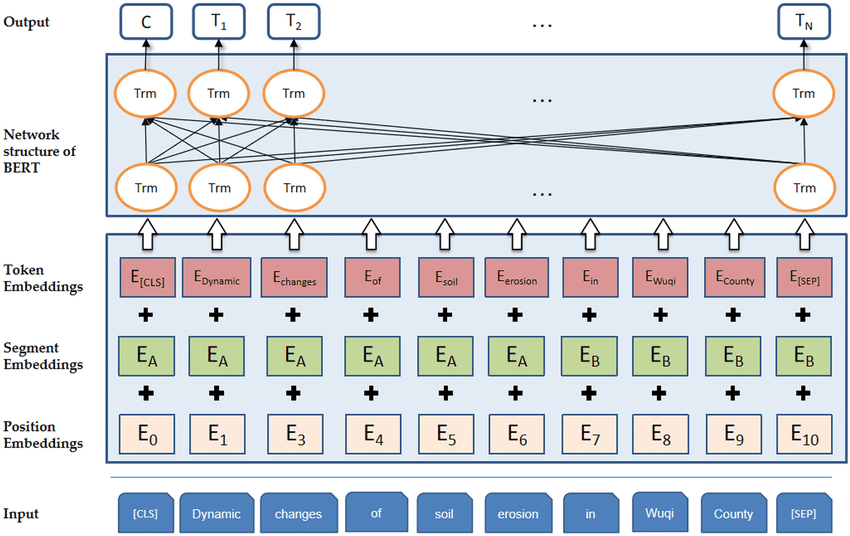
BERT架构
-
输入层 (Input)
BERT的输入是一个原始的文本序列,它可以是单个句子,也可以是两个句子(例如,问答任务中的问题和答案)。在输入到模型之前,这些文本需要经过特定的预处理步骤。
-
Tokenization 和 Embeddings
Tokenization: 输入文本首先通过分词器(Tokenizer)被分割成Token。这一步通常包括将文本转换为小写、去除标点符号、分词等。BERT使用WordPiece分词方法,将单词进一步拆分成子词(subwords),以优化词汇表的大小和模型的泛化能力。
Token Embeddings: 分词后的Token被映射到一个高维空间,形成Token Embeddings。这是通过查找一个预训练的嵌入矩阵来实现的,该矩阵为每个Token提供一个固定大小的向量表示。
Segment Embeddings: 由于BERT能够处理两个句子作为输入(例如,在句子对分类任务中),因此需要一种方法来区分两个句子。Segment Embeddings用于此目的,为每个Token添加一个额外的嵌入,以指示它属于哪个句子(通常是“A”或“B”)。
Position Embeddings: 由于Transformer模型本身不具有处理序列中Token位置信息的能力,因此需要位置嵌入来提供这一信息。每个位置都有一个独特的嵌入向量,这些向量在训练过程中学习得到。
Token Embeddings、Segment Embeddings和Position Embeddings三者相加,得到每个Token的最终输入嵌入。
-
BERT的网络结构 (Network Structure of BERT)
BERT的核心是由多个Transformer编码器层堆叠而成的。每个编码器层都包含自注意力机制和前馈神经网络,允许模型捕捉输入序列中的复杂依赖关系。
-
自注意力机制: 允许模型在处理序列时关注不同位置的Token,并
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









