







Elasticsearch 是开源搜索和分析系统,目前被广泛用于互联网多种领域中。在搜索领域,相对于 solr,成为很多搜索的不二之选。Elasticsearch 作为一款高度分布式、面向海量数据的搜索引擎,其可靠性设计体现在多个层面,能够确保在面对各种故障场景时仍能提供稳定、准确、及时的数据服务。
下面就来详细介绍其可靠性保障的涉及。
一、分布式架构与数据冗余
Elasticsearch 将索引划分为多个分片,每个分片都可以独立存储、检索和管理数据。这样做的好处是将大规模数据集分散到多个节点上,实现水平扩展,同时允许对单个分片进行故障隔离和恢复。
同时每个分片可以有多个副本,分布在不同的节点上。主分片负责处理写操作,副本分片则保持与主分片的数据同步。当主分片发生故障时,系统可以自动将某个副本提升为主分片,确保数据的高可用性和读操作的连续性。
分片及副本关系如下图所示

1.1 主分片与副本分片复制机制
下图展示了数据的写入流程,详细的介绍请参考往期文章:深入探索Elasticsearch数据写入黑箱-CSDN博客
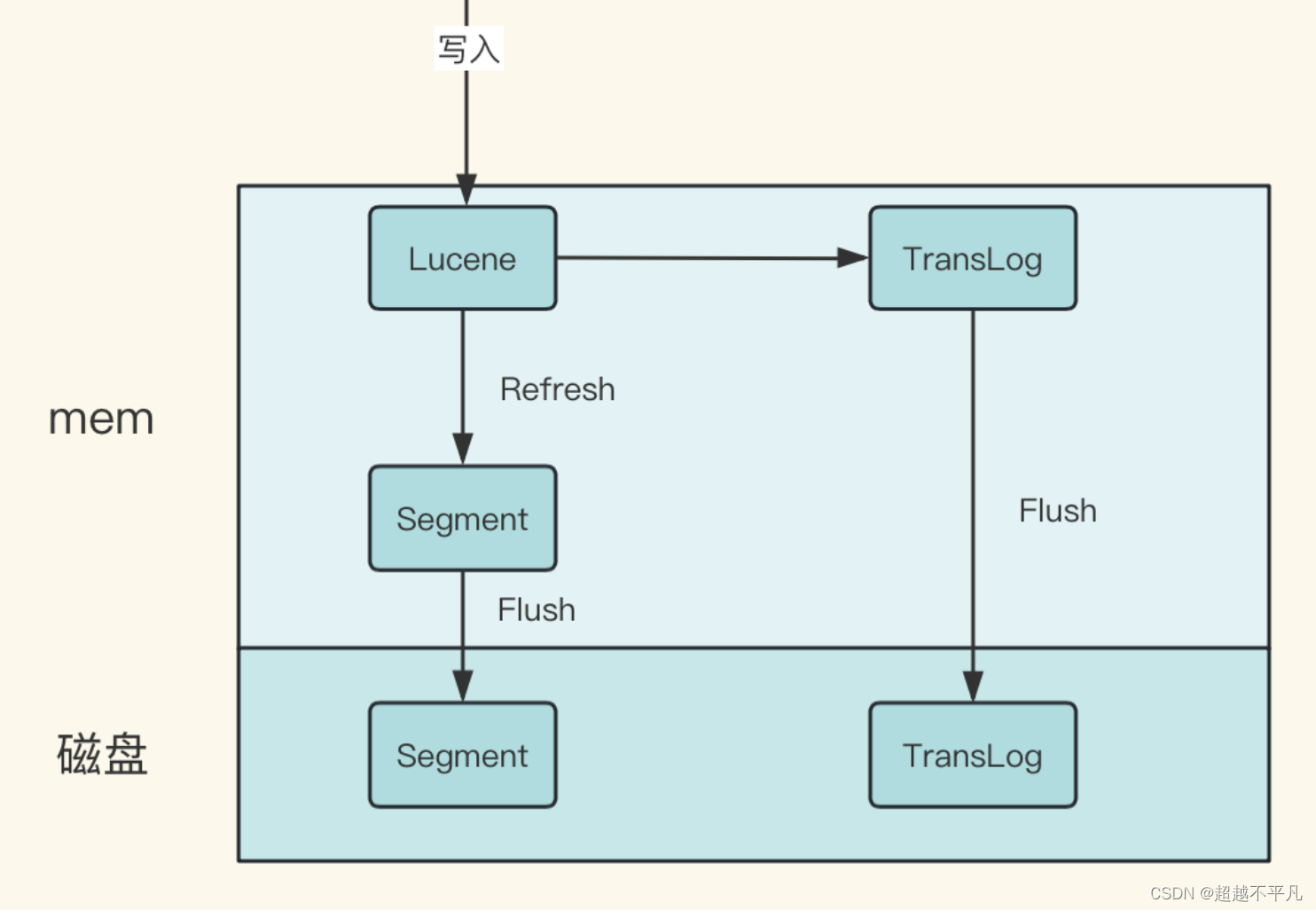
写入数据成功后就会进行数据同步工作 ,具体流程如下
1、首先是数据写入主阶段。当客户端向 Elasticsearch 发送索引、更新或删除请求时,这些请求首先被路由到对应的主分片上。主分片负责处理写入操作,执行数据验证、分析、索引构建等操作,并将变更持久化到磁盘。
2、主分片在处理写请求时,会将变更记录到一个名为“事务日志”(Transaction Log, translog)的文件中。translog 记录了尚未刷新到 Lucene 索引段(segment)的所有操作,提供了事务性和故障恢复能力。
3、主分片定期(或在 translog 达到一定大小时)将 translog 中的变更推送到其对应的副本分片。推送过程通过 Elasticsearch 的传输层(Transport Layer)进行,使用 HTTP 或内部专有协议。
4、副本分片接收到主分片推送的变更后,会按照相同的顺序应用这些变更。这个过程类似于在主分片上发生的操作,包括数据验证、分析、索引构建等。
5、副本分片完成变更应用后,会向主分片发送确认(acknowledgement)。主分片收到所有副本分片的确认后,才会认为此次写操作已完成,并清除 translog 中已确认的条目。这个过程确保了数据在主分片和所有副本分片间的一致性。
副本的一致性程度可以根据不同的配置来设置,可以设置三个值,分别为one、all、quorum。其中 all 是默认值,所有副本否确认写入成功后才会给客户端返回成功,这种方式数据最可靠,但是性能最差,尤其是副本数很大时。one 指的是只要主分片确认后就可确认写入成功,不过可能会有丢失数据的可能。quorum 是收到大多数副本确认后才确认成功。这三种方式需要根据自己的业务场景来进行权衡取舍。
6、在正常运行期间,主分片和副本分片通过持续的变更推送与确认机制保持数据同步。如果某个副本分片由于网络故障、节点故障等原因暂时不可达,主分片会记录下未收到确认的变更,并在副本分片恢复后重新推送这些变更,以完成数据同步。
7、如果主分片所在节点发生故障,集群会自动从副本分片中选出一个新的主分片。这个过程称为“分片恢复”(Shard Recovery)。新主分片会从其自身的 Lucene 索引段以及可能存在的未应用的 translog 条目中恢复数据。其他副本分片则开始与新的主分片同步数据。
下面看下分片恢复,也就是重新选取主分片的流程。
1.2 主分片选举流程
首先是故障检测,Zen Discovery 模块负责节点间的健康检查。通过发送和接收心跳消息(Heartbeat),节点可以监测到其他节点或分片的存活状态。当一个主分片所在的节点长时间未响应心跳,或者节点明确报告分片故障,集群会标记该主分片为“不可用”(Unassigned)。
集群中的任一节点注意到主分片故障后,会启动主分片选举流程。
Elasticsearch 有一套优先级规则来决定哪个副本分片应该晋升为主分片。具体为:
- 数据最新性:选择数据与原主分片差距最小的副本分片,通常通过比较各副本分片的序列号(seq_no)和主分片最后一次已知的序列号来确定。
- 节点负载:选择所在节点负载较低的副本分片,以均衡集群资源。
- 其他配置因素:如节点的角色、磁盘空间、网络状况等,可能在集群配置中定义了影响选举的规则。
根据上述优先级评估,主节点会选择一个最高优先级的副本分片作为新的主分片。这一决策过程通常是快速且自动化的。
主节点将选举结果通知给集群中的其他节点,并指示被选中的副本分片晋升为主分片。同时,更新集群元数据,将原主分片标记为“已遗失”(Missing)或“待恢复”(Pending)状态。
新主分片开始提供读写服务,并与剩余的副本分片同步数据。其他副本分片会从新主分片处拉取缺失的变更,以达到数据一致性。客户端查询和写入请求会逐渐转向新的主分片。
二、数据持久化与备份恢复
上文中提到的事务日志(Translog) 是用来做数据持久化和备份恢复的。写入请求到达 Shard后,先写 Lucene 文件,创建好索引,此时索引还在内存里面,接着去写 TransLog,写完TransLog 后,刷新 TransLog 数据到磁盘上,写磁盘成功后,请求返回给用户。
此时即使在节点突然宕机或电源故障的情况下,重启后可以通过重放 Translog 恢复未持久化的数据。
三、数据一致性
Elasticsearch 为每个文档维护一个版本号。在更新或删除文档时,客户端需提交当前版本号。服务端在处理请求时会验证版本号,确保并发操作的正确顺序和数据一致性。
如果有两个客户端 A 和 B,分别修改同一个文档,每个文档都有一个版本号,加入A和B都查到了要修改的文档,但是 A 先修改文档,将版本号加1,并进行了保存,那么 B 在进行修改前要先进行版本号判断,如果发现是老版本,就会对其进行拒绝,需要重新执行更新流程。
通过版本号来保证了在并发环境下数据的一致性。
四、总结
综上所述,Elasticsearch的可靠性设计涵盖了分布式架构、数据冗余、健康监测、数据一致性、数据持久化、高效同步等多个维度,通过一系列精心设计的机制和功能,确保在大规模、复杂环境下提供稳定、可靠的数据服务。实际应用中,还需结合业务特性和运维需求,进行合理的配置与监控,进一步强化系统的可靠性。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











