








导入计算库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use("fivethirtyeight")
plt.rcParams["font.sans-serif"] = ["Microsoft YaHei"]
plt.rcParams["axes.unicode_minus"] = False
from sklearn.preprocessing import OneHotEncoder
import statsmodels.api as sm
from statsmodels.graphics.tsaplots import plot_acf,plot_pacf
from pandas.tseries.offsets import DateOffset
from statsmodels.tsa.arima.model import ARIMA
import warnings
warnings.filterwarnings("ignore")
导入数据
path_train = "../preocess_data/train_data_o.csv"
path_test = "../data/test_data.csv"
data = pd.read_csv(path_train)
data_test = pd.read_csv(path_test)
data["运营日期"] = pd.to_datetime(data["运营日期"] )
data_test["运营日期"] = pd.to_datetime(data_test["日期"])
data.drop(["行ID","日期"],axis=1,inplace=True)
data_test.drop(["行ID","日期"],axis=1,inplace=True)
折扣编码
enc = OneHotEncoder(drop="if_binary")
enc.fit(data["折扣"].values.reshape(-1,1))
enc.transform(data["折扣"].values.reshape(-1,1)).toarray()
enc.transform(data_test["折扣"].values.reshape(-1,1)).toarray()
array([[0.],
[0.],
[0.],
...,
[1.],
[0.],
[0.]])
data["折扣"] = enc.transform(data["折扣"].values.reshape(-1,1)).toarray()
data_test["折扣"] = enc.transform(data_test["折扣"].values.reshape(-1,1)).toarray()
日期衍生
def time_derivation(t,col="运营日期"):
t["year"] = t[col].dt.year
t["month"] = t[col].dt.month
t["day"] = t[col].dt.day
t["quarter"] = t[col].dt.quarter
t["weekofyear"] = t[col].dt.weekofyear
t["dayofweek"] = t[col].dt.dayofweek+1
t["weekend"] = (t["dayofweek"]>5).astype(int)
return t
data_train = time_derivation(data)
data_test_ = time_derivation(data_test)
对每家店进行探索
对第一家尝试
# 训练集合
data_train_1 = data_train[data_train["商店ID"] ==1]
# 测试集合
data_test_1 = data_test_[data_test_["商店ID"] ==1]
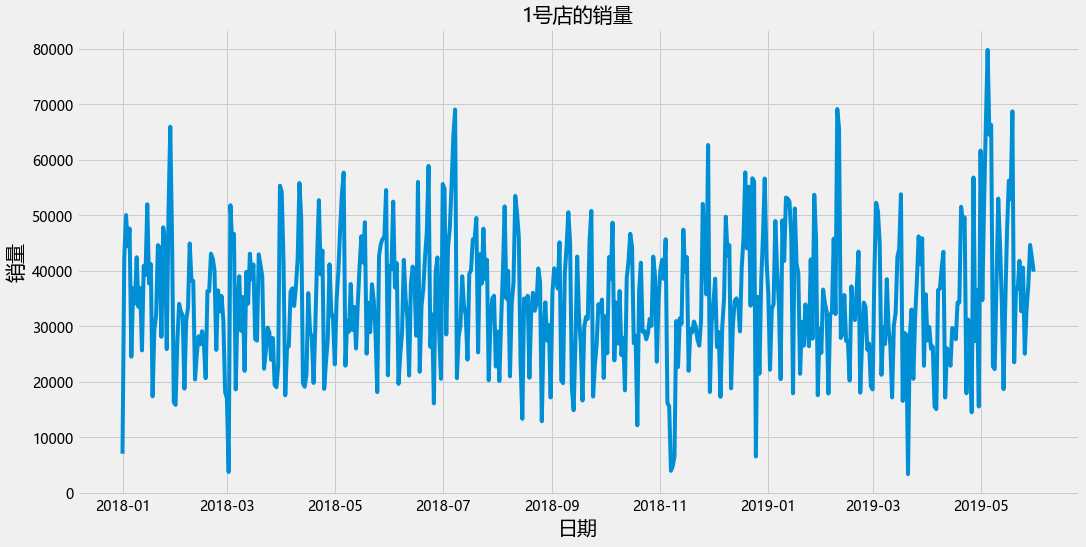
plt.figure(figsize=(16,8))
plt.plot(data_train_1["运营日期"],data_train_1["销量"])
plt.xlabel("日期",fontsize= 20)
plt.ylabel("销量",fontsize= 20)
plt.title("1号店的销量",fontsize=20)
Text(0.5, 1.0, '1号店的销量')
data_train_1
| 商店ID | 商店类型 | 位置 | 地区 | 节假日 | 折扣 | 销量 | 运营日期 | year | month | day | quarter | weekofyear | dayofweek | weekend | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | S1 | L3 | R1 | 1 | 1.0 | 7011.84 | 2018-01-01 | 2018 | 1 | 1 | 1 | 1 | 1 | 0 |
| 607 | 1 | S1 | L3 | R1 | 0 | 1.0 | 42369.00 | 2018-01-02 | 2018 | 1 | 2 | 1 | 1 | 2 | 0 |
| 1046 | 1 | S1 | L3 | R1 | 0 | 1.0 | 50037.00 | 2018-01-03 | 2018 | 1 | 3 | 1 | 1 | 3 | 0 |
| 1207 | 1 | S1 | L3 | R1 | 0 | 1.0 | 44397.00 | 2018-01-04 | 2018 | 1 | 4 | 1 | 1 | 4 | 0 |
| 1752 | 1 | S1 | L3 | R1 | 0 | 1.0 | 47604.00 | 2018-01-05 | 2018 | 1 | 5 | 1 | 1 | 5 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 186569 | 1 | S1 | L3 | R1 | 0 | 1.0 | 33075.00 | 2019-05-27 | 2019 | 5 | 27 | 2 | 22 | 1 | 0 |
| 187165 | 1 | S1 | L3 | R1 | 0 | 1.0 | 37317.00 | 2019-05-28 | 2019 | 5 | 28 | 2 | 22 | 2 | 0 |
| 187391 | 1 | S1 | L3 | R1 | 0 | 1.0 | 44652.00 | 2019-05-29 | 2019 | 5 | 29 | 2 | 22 | 3 | 0 |
| 187962 | 1 | S1 | L3 | R1 | 0 | 1.0 | 42387.00 | 2019-05-30 | 2019 | 5 | 30 | 2 | 22 | 4 | 0 |
| 188113 | 1 | S1 | L3 | R1 | 1 | 1.0 | 39843.78 | 2019-05-31 | 2019 | 5 | 31 | 2 | 22 | 5 | 0 |
516 rows × 15 columns
假设检验: 平稳性检验
**原假设:**数据是不平稳序列,如果该假设未被拒绝,则表示时间序列中有单位根。
**备择假设:**数据是平稳的,拒绝原假设,说明该时间序列中没有单位根,数据平稳。
- p>0.05 无法拒绝原假设,数据有单位根并且不平稳。
- p<=0.05 拒绝原假设,数据没有单位根,并且数据是平稳的。
from statsmodels.tsa.stattools import adfuller
data_train_1["销量"].std()
11816.030434190745
result = adfuller(data_train_1["销量"])
result
(-4.0896913250202225,
0.0010072301346594798,
13,
502,
{'1%': -3.4434437319767452,
'5%': -2.8673146875484368,
'10%': -2.569845688481135},
10594.579494253907)
def adfuller_test(data):
from statsmodels.tsa.stattools import adfuller
result = adfuller(data)
labels = ["ADF Test Statistic","P-Value"]
for value,label in zip(result,labels):
print(label+":"+str(value))
if result[1]<=0.05:
print("拒绝原假设,数据具有平稳性!")
else:
print("无法拒绝原假设,数据不平稳!")
return result[1]
p_value = adfuller_test(data_train_1["销量"])
p_value
ADF Test Statistic:-4.0896913250202225
P-Value:0.0010072301346594798
拒绝原假设,数据具有平稳性!
0.0010072301346594798
def diff_test(data,col = "销量"):
columns = ["D1","D2","D3","D4","D5","D6","D7","D8","D9","D10","D11","D12","D24"]
pvalues = []
stds = []
for idx,degree in enumerate([*range(1,13),24]):
print("{}步差分".format(degree))
data[columns[idx]] = data[col] - data[col].shift(idx+1)
pvalue_ = adfuller_test(data[columns[idx]].dropna())
std_ = data[columns[idx]].std()
pvalues.append(pvalue_)
stds.append(std_)
print("差分后数据的标准差为{}".format(std_))
print("\n")
return pvalues,stds
pvalues,stds= diff_test(data_train_1,col = "销量")
1步差分
ADF Test Statistic:-8.464898318877633
P-Value:1.5318720959824456e-13
拒绝原假设,数据具有平稳性!
差分后数据的标准差为13817.551491473438
2步差分
ADF Test Statistic:-8.522739847666854
P-Value:1.0895357544082096e-13
拒绝原假设,数据具有平稳性!
差分后数据的标准差为15742.483969864334
3步差分
ADF Test Statistic:-8.735227057175196
P-Value:3.113347686828788e-14
拒绝原假设,数据具有平稳性!
差分后数据的标准差为17859.203983779495
4步差分
ADF Test Statistic:-9.58524793091614
P-Value:2.1057694542062046e-16
拒绝原假设,数据具有平稳性!
差分后数据的标准差为16987.96156086255
5步差分
ADF Test Statistic:-8.960763076444596
P-Value:8.236684531392401e-15
拒绝原假设,数据具有平稳性!
差分后数据的标准差为17033.86992851215
6步差分
ADF Test Statistic:-7.769437143794817
P-Value:9.003228411011962e-12
拒绝原假设,数据具有平稳性!
差分后数据的标准差为15529.629177726565
7步差分
ADF Test Statistic:-7.083109863637503
P-Value:4.611558193984965e-10
拒绝原假设,数据具有平稳性!
差分后数据的标准差为17024.943907771467
8步差分
ADF Test Statistic:-7.869282346208565
P-Value:5.035687145492254e-12
拒绝原假设,数据具有平稳性!
差分后数据的标准差为17695.94594762459
9步差分
ADF Test Statistic:-7.26305598879107
P-Value:1.662101581895993e-10
拒绝原假设,数据具有平稳性!
差分后数据的标准差为18068.592304247017
10步差分
ADF Test Statistic:-8.276441746470041
P-Value:4.642809018487743e-13
拒绝原假设,数据具有平稳性!
差分后数据的标准差为16707.40284171362
11步差分
ADF Test Statistic:-6.82747605010546
P-Value:1.931318243001963e-09
拒绝原假设,数据具有平稳性!
差分后数据的标准差为15272.56312237816
12步差分
ADF Test Statistic:-7.204131545505776
P-Value:2.3239728071593555e-10
拒绝原假设,数据具有平稳性!
差分后数据的标准差为13708.569562249815
24步差分
ADF Test Statistic:-6.063721465758527
P-Value:1.1955709996228333e-07
拒绝原假设,数据具有平稳性!
差分后数据的标准差为15386.586684555326
data_train_1["D12"].plot()
<AxesSubplot:>

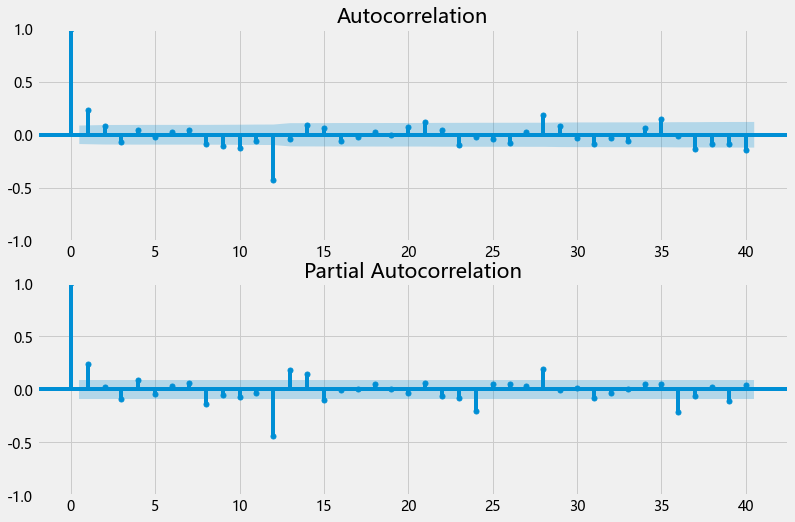
fig = plt.figure(figsize=(12,8))
ax1 = fig.add_subplot(211)
fig = sm.graphics.tsa.plot_acf(data_train_1["D12"].dropna(),lags=40,ax=ax1)
ax2 = fig.add_subplot(212)
fig = sm.graphics.tsa.plot_pacf(data_train_1["D12"].dropna(),lags=40,ax=ax2)
diff = [data_train_1["销量"],data_train_1["销量"].diff().dropna()
,data_train_1["销量"].diff().diff().dropna()
,data_train_1["销量"].diff().diff().diff().dropna()
]
titles = ["d=0","d=1","d=2","d=3"]
fig, (ax1, ax2, ax3, ax4) = plt.subplots(4,1,figsize=(8,14))
for idx, ts, fig, title in zip(range(4),diff,[ax1,ax2,ax3,ax4],titles):
print("{}阶差分的标准差为{}".format(idx,ts.std()))
plot_acf(ts, ax=fig, title=title)
0阶差分的标准差为11816.030434190745
1阶差分的标准差为13817.551491473438
2阶差分的标准差为22637.790854681327
3阶差分的标准差为41052.92772437857

由上图可知,d = 0,原始数据不会出现过差分的情况
data_train__1 =data_train_1[["运营日期","销量",'D1', 'D2',
'D3', 'D4', 'D5', 'D6', 'D7', 'D8', 'D9', 'D10', 'D11', 'D12', 'D24']].copy()
data_train__1
| 运营日期 | 销量 | D1 | D2 | D3 | D4 | D5 | D6 | D7 | D8 | D9 | D10 | D11 | D12 | D24 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2018-01-01 | 7011.84 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 607 | 2018-01-02 | 42369.00 | 35357.16 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1046 | 2018-01-03 | 50037.00 | 7668.00 | 43025.16 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1207 | 2018-01-04 | 44397.00 | -5640.00 | 2028.00 | 37385.16 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1752 | 2018-01-05 | 47604.00 | 3207.00 | -2433.00 | 5235.00 | 40592.16 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 186569 | 2019-05-27 | 33075.00 | 8040.00 | -7479.00 | 375.00 | -8715.00 | -3678.00 | -3537.00 | 9579.00 | -35658.00 | -19802.82 | -23178.00 | -14544.00 | -1383.00 | 14415.00 |
| 187165 | 2019-05-28 | 37317.00 | 4242.00 | 12282.00 | -3237.00 | 4617.00 | -4473.00 | 564.00 | 705.00 | 13821.00 | -31416.00 | -15560.82 | -18936.00 | -10302.00 | 2859.00 |
| 187391 | 2019-05-29 | 44652.00 | 7335.00 | 11577.00 | 19617.00 | 4098.00 | 11952.00 | 2862.00 | 7899.00 | 8040.00 | 21156.00 | -24081.00 | -8225.82 | -11601.00 | -2967.00 |
| 187962 | 2019-05-30 | 42387.00 | -2265.00 | 5070.00 | 9312.00 | 17352.00 | 1833.00 | 9687.00 | 597.00 | 5634.00 | 5775.00 | 18891.00 | -26346.00 | -10490.82 | -13866.00 |
| 188113 | 2019-05-31 | 39843.78 | -2543.22 | -4808.22 | 2526.78 | 6768.78 | 14808.78 | -710.22 | 7143.78 | -1946.22 | 3090.78 | 3231.78 | 16347.78 | -28889.22 | -13034.04 |
516 rows × 15 columns
data_train__1.index =pd.DatetimeIndex(data_train__1.index.values)
arima_0 = ARIMA(endog = data_train__1["销量"],order = (1,0,1))
ARIMA(endog =data_train__1["销量"],seasonal_order=(5,1,3,3))
arima_0 = arima_0.fit()
data_train__1["arima"] = arima_0.predict(start =456,endogd = 516,dynamic =True)
arima_0 = ARIMA(endog =data_train__1["销量"],seasonal_order=(5,1,3,3))
arima_0 = arima_0.fit()
data_train__1["arima"] = arima_0.predict(start =456,endogd = 516,dynamic =True)
arima_0.predict(start =516,endogd = 577)
516 26816.992973
dtype: float64
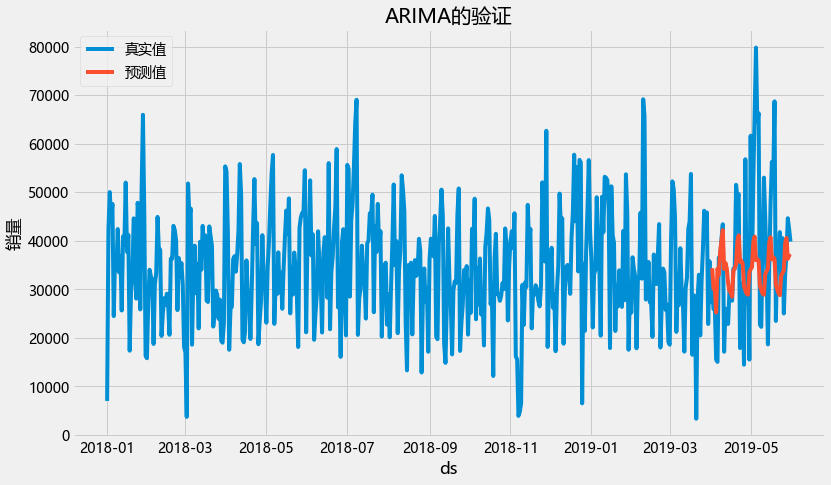
plt.figure(figsize=(12,7))
plt.plot(data_train__1["运营日期"],data_train__1["销量"],label="真实值")
plt.plot(data_train__1["运营日期"],data_train__1["arima"],label="预测值")
plt.xlabel("ds")
plt.ylabel("销量")
plt.title("ARIMA的验证")
plt.legend()
<matplotlib.legend.Legend at 0x14693679cc8>
def symmetric_mean_absolute_percentage_error(y_true, y_pred):
y_true, y_pred = np.array(y_true), np.array(y_pred)
return np.sum(np.abs(y_true - y_pred) * 2) / np.sum(np.abs(y_true) + np.abs(y_pred))
def arima_smape(y_true, y_pred):
smape_val = symmetric_mean_absolute_percentage_error(y_true, y_pred)
return 'SMAPE', smape_val, False
data_train__1[["运营日期","arima"]].loc[]
| 运营日期 | arima | |
|---|---|---|
| 1970-01-01 00:00:00.000000000 | 2018-01-01 | NaN |
| 1970-01-01 00:00:00.000000607 | 2018-01-02 | NaN |
| 1970-01-01 00:00:00.000001046 | 2018-01-03 | NaN |
| 1970-01-01 00:00:00.000001207 | 2018-01-04 | NaN |
| 1970-01-01 00:00:00.000001752 | 2018-01-05 | NaN |
| ... | ... | ... |
| 1970-01-01 00:00:00.000186569 | 2019-05-27 | 39525.339871 |
| 1970-01-01 00:00:00.000187165 | 2019-05-28 | 40588.767755 |
| 1970-01-01 00:00:00.000187391 | 2019-05-29 | 36283.064445 |
| 1970-01-01 00:00:00.000187962 | 2019-05-30 | 36961.130673 |
| 1970-01-01 00:00:00.000188113 | 2019-05-31 | 36744.677331 |
516 rows × 2 columns
np.array(data_train__1.tail(60)["销量"])
array([29886. , 25941. , 26334. , 15522. , 15056.34, 36531. ,
36753. , 40422. , 43416. , 17151. , 26004. , 24963.84,
22871.25, 29687.04, 29430. , 27664.2 , 34278. , 34278. ,
51531. , 48954.45, 49641. , 17910. , 31206. , 27207. ,
14484. , 56808. , 27330. , 36516. , 15531. , 61656. ,
34710. , 52362. , 66564. , 79806. , 64491. , 66288. ,
22731. , 22276.38, 37437. , 53016. , 44736. , 34479. ,
18660. , 34458. , 47619. , 56253. , 52877.82, 68733. ,
23496. , 36612. , 36753. , 41790. , 32700. , 40554. ,
25035. , 33075. , 37317. , 44652. , 42387. , 39843.78])
np.array(data_train__1.tail(60)["arima"])
array([34356.47414133, 30091.17999724, 30376.52066402, 25228.70141222,
34244.25905574, 32995.51895358, 37726.00344591, 40044.53290539,
42214.3534088 , 34202.13819704, 35451.01651558, 34338.58535838,
31275.42293545, 29675.36232876, 29506.96478827, 28477.909069 ,
33900.40136957, 34297.3848415 , 35255.19304449, 39942.21217251,
41116.3200547 , 35621.55813049, 35888.26578326, 35328.00500634,
30599.00844142, 29755.72777736, 29110.97021646, 28915.11380027,
33544.52883198, 34129.90655345, 34610.741271 , 39822.63505499,
40867.2933485 , 36014.714246 , 36260.94281065, 35881.50575625,
30702.6187137 , 29872.99671427, 29123.33802667, 28896.08000654,
33185.78296174, 33751.32898899, 34267.22060165, 39685.9774967 ,
40729.80605295, 36178.33135918, 36617.97940246, 36327.50562255,
30948.14619832, 30019.91310149, 29228.82155029, 28809.38738525,
32836.70491725, 33341.59736765, 33974.7119752 , 39525.33987072,
40588.76775503, 36283.06444474, 36961.13067342, 36744.67733075])
from sklearn.metrics import mean_squared_error
mean_squared_error(np.array(data_train__1.tail(60)["销量"]).reshape(-1,1),
np.array(data_train__1.tail(60)["arima"]).reshape(-1,1))**0.5
14166.52822810936
arima_smape(np.array(data_train__1.tail(60)["销量"]).reshape(-1,1),
np.array(data_train__1.tail(60)["arima"]).reshape(-1,1))
('SMAPE', 0.2935515805745867, False)
很显然,预测失效。
print(arima_0.summary(alpha = 0.05))
SARIMAX Results
==============================================================================
Dep. Variable: 销量 No. Observations: 516
Model: ARIMA(1, 0, 1) Log Likelihood -5543.620
Date: Mon, 05 Dec 2022 AIC 11095.239
Time: 19:40:59 BIC 11112.224
Sample: 0 HQIC 11101.895
- 516
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
const 3.47e+04 745.604 46.537 0.000 3.32e+04 3.62e+04
ar.L1 0.3295 0.128 2.566 0.010 0.078 0.581
ma.L1 -0.0161 0.148 -0.109 0.914 -0.307 0.275
sigma2 1.243e+08 0.001 8.4e+10 0.000 1.24e+08 1.24e+08
===================================================================================
Ljung-Box (L1) (Q): 0.01 Jarque-Bera (JB): 0.76
Prob(Q): 0.93 Prob(JB): 0.68
Heteroskedasticity (H): 1.48 Skew: 0.02
Prob(H) (two-sided): 0.01 Kurtosis: 3.18
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
[2] Covariance matrix is singular or near-singular, with condition number 1e+27. Standard errors may be unstable.
arima_0.resid
1970-01-01 00:00:00.000000000 -27686.602325
1970-01-01 00:00:00.000000607 16390.813526
1970-01-01 00:00:00.000001046 13075.357759
1970-01-01 00:00:00.000001207 4855.537661
1970-01-01 00:00:00.000001752 9788.351222
...
1970-01-01 00:00:00.000186569 1375.328883
1970-01-01 00:00:00.000187165 3175.598301
1970-01-01 00:00:00.000187391 9141.968919
1970-01-01 00:00:00.000187962 4556.391375
1970-01-01 00:00:00.000188113 2685.556382
Length: 516, dtype: float64
LJung-Box test : 检验样本和样本之间的相关性,LBQ下的Prob(Q)项大于0.05时候模型可用,否则可以考虑更换模型的超参数组合。
**Heteroskedasticity test:**异方差检验用于检验序列中的方差是否稳定。 异方差检验下的Prob(H)项大于0.05时候模型可用,否则可以考虑更换模型的超参数组合。
Jarque-Bera test: 雅克贝拉检验是正态性检验中的一种方法,用于检验当前序列是否符合正太分布。雅克贝拉检验下的Prob(JB)项大于0.05时候模型可用,否则可以考虑更换模型的超参数组合。
确定模型
data_arima = data_train__1["销量"].copy()
arimas = arimas = [ARIMA(endog = data_arima,order=(1,0,1))
,ARIMA(endog = data_arima,order=(1,0,2))
,ARIMA(endog = data_arima,order=(2,0,1))
,ARIMA(endog = data_arima,order=(2,0,2))
,ARIMA(endog = data_arima,order=(1,0,3))
,ARIMA(endog = data_arima,order=(3,0,1))
,ARIMA(endog = data_arima,order=(3,0,2))
,ARIMA(endog = data_arima,order=(2,0,3))
,ARIMA(endog = data_arima,order=(3,0,3))
]
sarimas = [ARIMA(endog = data_arima,seasonal_order=(1,0,1,12))
,ARIMA(endog = data_arima,seasonal_order=(1,0,2,12))
,ARIMA(endog = data_arima,seasonal_order=(2,0,1,12))
,ARIMA(endog = data_arima,seasonal_order=(2,0,2,12))
,ARIMA(endog = data_arima,seasonal_order=(1,0,3,12))
,ARIMA(endog = data_arima,seasonal_order=(3,0,1,12))
,ARIMA(endog = data_arima,seasonal_order=(3,0,2,12))
,ARIMA(endog = data_arima,seasonal_order=(2,0,3,12))
,ARIMA(endog = data_arima,seasonal_order=(3,0,3,12))
,ARIMA(endog = data_arima,seasonal_order=(1,0,1,4))
,ARIMA(endog = data_arima,seasonal_order=(1,0,2,4))
,ARIMA(endog = data_arima,seasonal_order=(2,0,1,4))
,ARIMA(endog = data_arima,seasonal_order=(2,0,2,4))
,ARIMA(endog = data_arima,seasonal_order=(1,0,3,4))
,ARIMA(endog = data_arima,seasonal_order=(3,0,1,4))
,ARIMA(endog = data_arima,seasonal_order=(3,0,2,4))
,ARIMA(endog = data_arima,seasonal_order=(2,0,3,4))
,ARIMA(endog = data_arima,seasonal_order=(3,0,3,4)) ,
]
sarimas_ = [
ARIMA(endog = data_arima,seasonal_order=(4,0,1,12))
,ARIMA(endog = data_arima,seasonal_order=(4,0,2,12))
,ARIMA(endog = data_arima,seasonal_order=(4,0,3,12))
,ARIMA(endog = data_arima,seasonal_order=(4,0,4,12))
,ARIMA(endog = data_arima,seasonal_order=(4,0,1,3))
,ARIMA(endog = data_arima,seasonal_order=(4,0,2,3))
,ARIMA(endog = data_arima,seasonal_order=(4,0,3,3))
,ARIMA(endog = data_arima,seasonal_order=(4,0,4,3))
,ARIMA(endog = data_arima,seasonal_order=(4,0,1,4))
,ARIMA(endog = data_arima,seasonal_order=(4,0,2,4))
,ARIMA(endog = data_arima,seasonal_order=(4,0,3,4))
,ARIMA(endog = data_arima,seasonal_order=(4,0,4,4))
]
sarimas__ = [
ARIMA(endog = data_arima,seasonal_order=(5,0,1,12))
,ARIMA(endog = data_arima,seasonal_order=(5,0,2,12))
,ARIMA(endog = data_arima,seasonal_order=(5,0,3,12))
,ARIMA(endog = data_arima,seasonal_order=(5,0,4,12))
,ARIMA(endog = data_arima,seasonal_order=(5,0,5,12))
,ARIMA(endog = data_arima,seasonal_order=(5,0,1,3))
,ARIMA(endog = data_arima,seasonal_order=(5,0,2,3))
,ARIMA(endog = data_arima,seasonal_order=(5,0,3,3))
,ARIMA(endog = data_arima,seasonal_order=(5,0,4,3))
,ARIMA(endog = data_arima,seasonal_order=(5,0,5,3))
,ARIMA(endog = data_arima,seasonal_order=(5,0,1,4))
,ARIMA(endog = data_arima,seasonal_order=(5,0,2,4))
,ARIMA(endog = data_arima,seasonal_order=(5,0,3,4))
,ARIMA(endog = data_arima,seasonal_order=(5,0,4,4))
,ARIMA(endog = data_arima,seasonal_order=(5,0,5,4))
]
sarimas___ = [
ARIMA(endog = data_arima,seasonal_order=(5,1,1,12))
,ARIMA(endog = data_arima,seasonal_order=(5,1,2,12))
,ARIMA(endog = data_arima,seasonal_order=(5,1,3,12))
,ARIMA(endog = data_arima,seasonal_order=(5,1,4,12))
,ARIMA(endog = data_arima,seasonal_order=(5,1,5,12))
,ARIMA(endog = data_arima,seasonal_order=(5,1,1,3))
,ARIMA(endog = data_arima,seasonal_order=(5,1,2,3))
,ARIMA(endog = data_arima,seasonal_order=(5,1,3,3))
,ARIMA(endog = data_arima,seasonal_order=(5,1,4,3))
,ARIMA(endog = data_arima,seasonal_order=(5,1,5,3))
,ARIMA(endog = data_arima,seasonal_order=(5,1,1,4))
,ARIMA(endog = data_arima,seasonal_order=(5,1,2,4))
,ARIMA(endog = data_arima,seasonal_order=(5,1,3,4))
,ARIMA(endog = data_arima,seasonal_order=(5,1,4,4))
,ARIMA(endog = data_arima,seasonal_order=(5,1,5,4))
]
def plot_summary(models,summary=True,model_name=[]):
for idx,model in enumerate(models):
m = model.fit()
if summary:
print("\n")
print(model_name[idx])
print(m.summary(alpha=0.01))
else:
data_train__1["arima"] = m.predict(start =456,endogd = 516,dynamic=True)
data_train__1[["销量","arima"]].plot(figsize=(12,2),title="Model {}".format(idx))
plot_summary(arimas,False)
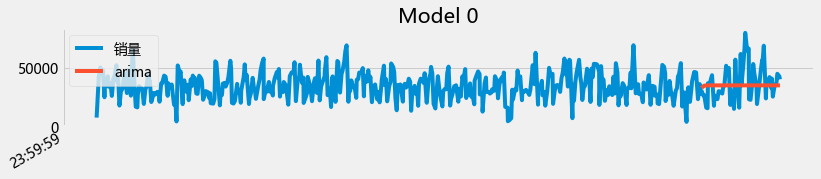
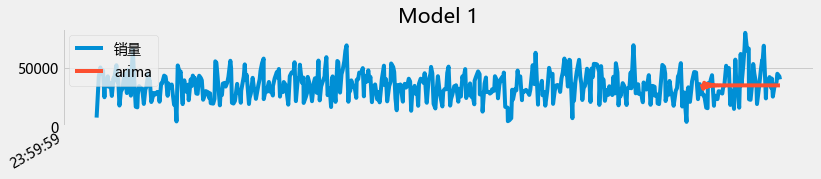

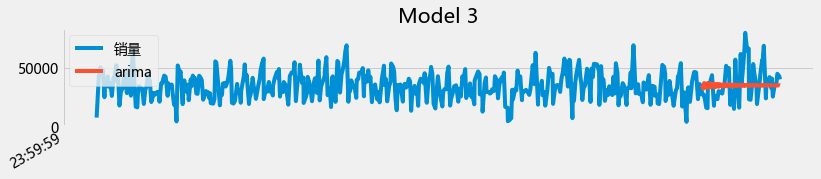
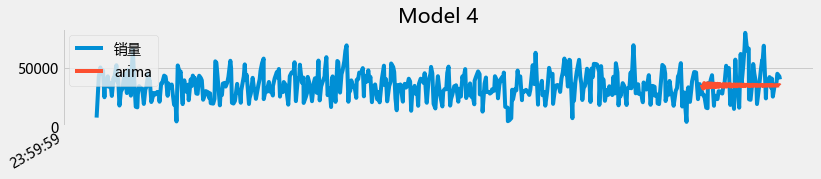
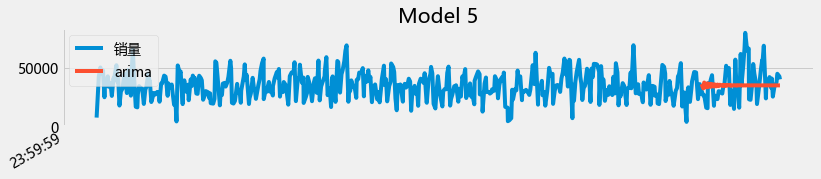

从上面的图初步来看,用arima 直接预测未来两个月的是有困难的。至此,ARIMA和prophet都对每天的销量预测进行了尝试(并且对其进行了初步的掌握),但是效果目前都不让人满意,因此,对每天的销量预测可以继续尝试:
- 从时间窗历史数据预测未来的时刻,就从构造特征的角度去考虑,或者二者相结合。
- 机器学习的角度思考。
- 深度学习的角度思考。
思考: 在这里发现数据是平稳的,但是如果从机器学习的角度来考虑的话,在arima中, 一般获取差分当中不存在过差分问题的、方差较小、噪音较少的阶数作为d的取值。方差较小的话,从方差过滤的角度来讲是否可以考虑去时序化呢?















 4185
4185











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









