







 本文介绍了操作系统的功能,包括进程管理、内存管理、设备管理和文件管理,并详细阐述了操作系统的定义和发展历程,特别关注了分时技术及其在分时操作系统中的应用,如UNIX系统。此外,还概述了典型操作系统类型,如微机、多处理机、网络和实时操作系统。
本文介绍了操作系统的功能,包括进程管理、内存管理、设备管理和文件管理,并详细阐述了操作系统的定义和发展历程,特别关注了分时技术及其在分时操作系统中的应用,如UNIX系统。此外,还概述了典型操作系统类型,如微机、多处理机、网络和实时操作系统。
1、操作系统初步认识
基本功能:
- 提供操作界面
- 控制程序运行
- 管理系统资源
- 配置系统参数
- 监控系统状态
- 工具软件集合
2、操作系统功能和定义
-
进程管理(CPU管理)
进程控制:创建、暂停、唤醒、撤销
进程调度:调度策略、优先级
进程通信:进程间通信
-
内存管理
内存分配、内存共享、内存保护、虚拟内存
-
设备管理
设备的分配和调度、设备无关性、设备传输控制、设备驱动
-
文件管理
存储空间管理、文件的操作、目录的操作、文件和目录的存取权限管理
操作系统的定义:操作系统是一个大型系统程序,提供用户接口,方便控制计算机,负责为应用程序分配和调度软硬件资源,并控制与协调应用程序并发活动,帮助用户存取和保护信息
操作系统地位(如下图):
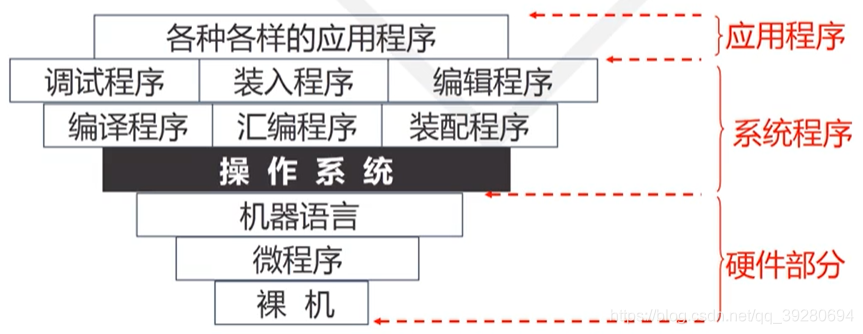
3、操作系统发展历史
用户需求提升和硬件技术进步是操作系统发展的两大动力
-
计算机硬件发展的四个典型阶段
电子管时代(1946-1955)
晶体管时代(1955-1965)
集成电路时代(1965-1980)
大规模集成电路时代(1980-至今)
-
操作系统发展的四个典型阶段
手工操作(无操作系统)50年代早期
单道批处理系统 50年代
多道批处理系统 60年代初
分时系统 60年代中
4、分时技术与分时操作系统
4.1、60年代硬件的两个重大进展
-
中断技术
CPU收到外部信号(中断信号)后,停止当前工作,转去处理该外部事件,处理完毕后回到原来工作的中断处(断点)继续原来的工作。
-
通道技术
专门处理外设和内存之间的数据传输的处理机
4.2、分时操作系统的背景
-
事务性任务的涌现
交互性高
响应迅速
-
要求支持多任务/多用户
-
多终端计算机
-
高性能主机+多个终端
主机:运算,CPU+内存,
终端:输入和显示
-
主机采用分时技术轮流为每个终端服务。每个终端都感受到是“独占”主机!
-
4.3、分时技术
概念
-
主机以很短的“时间片”为单位,把CPU轮流分配给每个终端使用,直到全部作业被运行完。
-
由于时间片很短,在终端数量不多的情况下,每个终端都能很快重新获得CPU,使得每个终端都能得到及时响应
等待周期=时间片*终端数量
分时系统的特点
-
多路调制性
多用户联机使用同一台计算机
-
独占性
用户感觉独占计算机
-
交互性
及时响应用户的请求
UNIX
-
第一个实用化的分时操作系统
第一个真正体现操作系统领域各种先进概念和技术的操作系统
-
革新和创造
实现操作系统的可移植性;实现了硬件无关性;引进了“特殊文件”(Special File)的概念,把外设看作文件,实现对外设统一管理
5、典型操作系统类型
操作系统的进一步发展(分时系统的衍化)
- 微机操作系统
- 多处理机操作系统
- 网络操作系统
- 实时操作系统
- 嵌入式操作系统

















 6350
6350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









