







Trajectory-based operation monitoring of transition procedure in multimode process 基于轨迹的多模态过渡过程运行监测
- 作者信息
- 摘要 (Abstract)
- 关键词 (Keywords)
- Introduction 引言
- 2. Transition identification and trajectory-based monitoring scheme 过渡识别和基于轨迹的监测方案
- 3 案例研究
- Conclusion 结论
- Appendix 附录
作者信息

摘要 (Abstract)
许多连续的工业过程在不同的稳定状态下运行,具有不同的等级或产品。在两个稳态之间的转换被称为 过渡过程。过渡过程由一系列的操作变化组成,并应在一定的幅值和时间范围顺序下执行。由于错误的操作可能导致劣质产品的增加甚至危害事件,因此需要对过渡过程进行监控。本文提出了一种基于慢特征分析的过渡识别与监测方案。提出了两种表示轨迹位置和过渡速度的监测统计量。此外,运行故障是根据危害和可操作性分析(HAZOP)指南生成的。通过数值算例和存在灾难性破坏的Tennessee-Eastman过程的4-到-2模式转换,验证了所提方法的有效性。除了漏检率和虚警率外,还引入了*检测时间 detection time (DT)和救援时间 rescue time (RT)*两个性能指标。并与基于阶段的子主成分分析(sub- principal component analysis, sub- pca)和全局保持统计慢特征分析(global preserving statistics slow feature analysis, GSSFA)进行了比较。

关键词 (Keywords)
Transition monitoring 过渡过程监测
Operating faults 操作故障
Transition identification 过渡过程识别
Trajectory-based method 基于轨迹的方法
Introduction 引言
1.1 Background 研究背景
在大数据时代,数据驱动的工业过程监控备受关注[1-3]。然而,大多数工业过程以不同的模式运行,生产不同等级(grades)或不同吞吐量(throughput)的产品。最近,Quiones-Grueiro等人对这种多模式过程的监测进行了广泛的综述[4]。多模式过程的监测需要将操作分类为不同的模式,并为这些模式开发统一或单独的检测方法。对于具有多模式的连续制造,存在稳态模式之间的转换。例如,聚合物等级转变的控制和优化是一个已经被广泛研究的课题[5,6]。许多转换是由操作员按照标准操作程序(SOP)执行的。然而,由于经验的不同,不同的操作员之间仍然存在差异。此外,在这种过渡过程中,报警限值通常被忽略。错误的操作可能会导致灾难性的故障。因此,迫切需要一个有效的监测方案。然而,根据上述调查[4],83%的被审查出版物没有考虑过渡监测。
1.2 Literature survey 文献综述
为了监视过渡过程,应该考虑数据的动态相关性。采用[7]中提出的模间相对分析算法探索不同稳态模态间的关系。与此思路类似,文献[8]提出了一种通过捕获交叉模态信息来监测模间转换的方法。此外,许多建议的批处理方法也可以使用。开创性的多向主成分分析(MultiwayPCA)是在[9]中提出的,Nomikos和McGregor通过考虑批处理过程中的不同时间点来纳入时间相关。Kourti及其同事首次报道了将该方法应用于诸如启动、关闭和等级变化等过渡监测[10,11]。等级转换的问题之一是确定稳定状态的起始点和终点。
应该指出的是,多路PCA要求在做出监测决策之前对整个过程进行抽样。因此,可以使用多块PCA来缩短检测时间。另一种方法是将过程划分为不同的阶段,并假设每个阶段的变量相关性是不变的。如Lu等人[12]通过聚类方法将一批数据分成若干阶段,提出了一种基于阶段的子主成分分析(sub- pca)监测方法。Wang等人[13]将这一思想应用于退火炉的过渡监测。提出了一种聚类算法来识别离线建模阶段的稳定模式和过渡模式,并创建了模式转换概率指数来将在线样本分配到正确的模式。应该指出的是,在过渡过程中,假设过程可以分为平稳变量相关结构的部分可能是无效的。数据的动态特性可以使用样本窗口包括在内。例如,Zhu等[14]基于动态k独立成分分析-主成分分析(k-ICA-PCA)将过渡过程划分为几个阶段。采用基于多类支持向量数据描述(SVDD)的模式分类策略对在线监测模型进行分配。他等人[15]使用k-偏最小二乘(k-PLS)方法,通过PLS模型捕获当前样本和过去样本之间的时间相关性。然后将提取的特征聚类到局部模型中以进行监控。基于局部核密度估计的算法用于识别稳定模式和过渡,并提出了基于距离的过渡监测方法[16]。隐马尔可夫模型(HMM)也可用于过渡模式识别[17,18]。
在上述方法中,将过渡数据划分为不同阶段,并建立局部模型进行监测。因此需要三个步骤:(1)阶段分类,(2)在模型构建阶段将时间相关性纳入局部模型,(3)在在线应用阶段分配在线数据。
或者,考虑到正常的过渡过程在时间上应该有相似的趋势,使用趋势分析和时间序列相似性度量来检测故障。Srinivasan等[19]提出了增强趋势分析来监测过渡的初步尝试,将过渡的实时演变抽象为单个关键过程变量的半定量趋势。在进一步的研究中,动态轨迹分析在[20]中被发展用于在线故障诊断和过程转移的状态识别,该分析使用与不同变量的加权距离相关的不相似矩阵。近年来,在监测转换过程中,对变量之间的相关性进行了进一步的探讨。Zhu等[21]提出了一种动态报警管理策略,采用动态时间规整(dynamic time warping, DTW)方法构造动态报警限值进行故障检测和诊断。Shen等人[22]通过计算有限窗口长度之间的变量差异来表示过渡轨迹,并将其与多变量趋势分析和主成分分析(PCA)相结合,用于多相过程监测。
1.3 Motivation 研究动机
在等级转换中,认识到这个过程是比正常情况快还是慢是非常重要的。积极的转换操作可能导致灾难性的故障,而缓慢的操作可能导致大量的劣等产品。然而,据我们所知,文献中还没有一种监测方法能够区分这两种类型的故障。
最近,Wiskott和Sejnowski提出了一种动态分析技术,称为慢特征分析(slow feature analysis, SFA),用于从输入数据集中学习不变或慢变化的特征[23]。报道了一系列基于sfa的过程监测方法[24-26]。具体而言,Zhang等[27]采用SFA将静态和时间分布抽象为两个子空间,并通过典型变量分析(canonical variate analysis, CVA)对其进行划分,为正常运行状态的精细尺度识别提供了有意义的解释。这些例子是关于某稳态过程的故障检测,并讨论了故障的时变性质。目前,将SFA应用于多模态监测的论文不多。考虑到运行工况频繁变化,慢速特征不能被合适的置信区间很好地封闭,Zhao和Huang将SFA与平稳变量一起进行基于慢/快特征的监测[28]。经过阶段划分,建立了全局保持统计SFA (GSSFA)模型来监测具有过渡的批处理过程,并使用即时学习方法在线建模和监测过渡[29]。在这项工作中,我们打算使用SFA来识别稳定和过渡模式,监测过渡过程,甚至区分积极过渡和缓慢过渡。
Srinivasan等[19]探讨了过渡性故障的原因,误操作是关键因素之一。然而,大多数研究并未考虑监测过渡过程中与操作错误相关的常见故障。在模式切换过程中,经常需要工人或机器进行频繁的操作。不遵守操作规程或操作人员偶尔失误是不可避免的,这将导致异常[30]。因此,对运行故障进行归纳、分类并制定相应的监测方案显得十分紧迫和重要。危害和可操作性分析(HAZOP)对批处理和过渡操作进行了广泛的研究[31-33]。在本研究中,我们将生成与操作故障中指导语相关的故障操作,并使用它们进行基准测试。此外,能够在不可恢复的灾难性故障发生之前检测到故障是很重要的。在本研究中,我们将以TE问题中的4-to-2转换为例,生成[34]中提到的灾难性故障,并使用它们来基准测试监测方法在故障不可恢复之前检测故障的能力。
1.4 Organization and scope 内容及组织结构
本文的其余部分组织如下。第2节介绍了SFA的原理、提出的过渡识别和监测方案以及运行故障。在第3节中,给出了一个数值示例来演示所提出方法的实现;采用TE过程来证明算法的有效性,并定义了灾难性故障的检测时间(DT)和救援时间(RT)来评估监测方法。最后一节给出结论。
2. Transition identification and trajectory-based monitoring scheme 过渡识别和基于轨迹的监测方案
我们假设,在正确的顺序、适当的时间和一定的范围内进行操作变化,就会发生正常的过渡。此外,有足够的此类正常过渡的历史数据可用于计算试验统计量的极限。基于上述假设,本文提出了一种基于慢特征分析的基于过渡识别轨迹的监测方案,并在本节中进行了详细说明。
2.1 Slow Feature Analysis (SFA) 慢特征分析
2.1.1 Projection 投影
SFA通常用于估计数据集在时间尺度[24]上的内在驱动力。给定一个m维输入
X
=
[
X
1
T
,
X
2
T
,
…
,
X
M
T
]
T
∈
R
M
×
N
X = [X_1^T, X_2^T,…,X_M^T]^T∈R^{M×N}
X=[X1T,X2T,…,XMT]T∈RM×N对于N个样本的序列,SFA的目标是找到一个变换
s
(
N
)
=
g
(
X
(
N
)
)
s(N) = g(X (N))
s(N)=g(X(N)),该变换产生一系列慢特征(SFs),
s
(
N
)
=
[
s
1
(
n
)
,
s
2
(
n
)
,
…
,
s
M
(
n
)
]
,
n
=
1
,
…
,
N
s(N) = [s_1(n), s_2(n),…, s_M (n)], n = 1,…, N
s(N)=[s1(n),s2(n),…,sM(n)],n=1,…,N.使SFs的变化尽可能慢,通过求解以下优化问题[23]来实现:
m
i
n
g
(
⋅
)
<
s
˙
i
2
>
n
,
i
=
1
,
2
,
…
,
M
(1)
\mathop{min}\limits_{g(\cdot)}<\dot{s}_i^2>_n,i=1,2,…,M \tag{1}
g(⋅)min<s˙i2>n,i=1,2,…,M(1)
具有以下约束条件:
<
s
i
>
n
=
0
(2)
<s_i>_n=0 \tag{2}
<si>n=0(2)
<
s
i
2
>
=
1
(3)
<s_i^2>=1 \tag{3}
<si2>=1(3)
∀
i
≠
j
,
<
s
i
s
j
>
n
=
0
(4)
\forall i\neq j,<s_is_j>_n=0 \tag{4}
∀i=j,<sisj>n=0(4)
其中⟨·⟩n表示所有n个测量值的平均值,并且
s
˙
i
(
n
)
=
s
i
(
n
)
−
s
i
(
n
−
1
)
\dot{s}_i(n) = s_i(n) - s_i(n - 1)
s˙i(n)=si(n)−si(n−1)。约束(2)和(3)要求每个慢特征应该具有零平均值和单位方差。约束(4)保证不同的慢特征彼此正交。慢特征按顺序排列,即第一个特征
s
1
s_1
s1是最慢的,第二个特征
s
2
s_2
s2是第二慢的,等等。
对于线性慢速特征分析,慢速特征
s
(
n
)
\textbf{s}(n)
s(n)可以用所有变量的线性组合来表示。
s
(
n
)
=
WX
(
n
)
(5)
\textbf{s}(n)=\textbf{WX}(n) \tag{5}
s(n)=WX(n)(5)
其中,
W
=
[
w
1
,
w
2
,
…
,
w
m
]
T
=
P
Λ
−
1
2
U
T
\textbf{W}=[w_1,w_2,\dots,w_m]^T=\textbf{P}\Lambda^{-\frac{1}{2}}\textbf{U}^T
W=[w1,w2,…,wm]T=PΛ−21UT
其中
U
\textbf{U}
U和
Λ
\Lambda
Λ可通过对
<
XX
T
>
n
<\textbf{XX}^T>_n
<XXT>n进行奇异值分解(SVD)得到。即,
<
XX
T
>
n
=
U
Λ
U
T
<\textbf{XX}^T>_n=\textbf{U}\Lambda\textbf{U}^T
<XXT>n=UΛUT。
P
\textbf{P}
P可以通过对
<
z
˙
z
˙
T
>
n
<\dot{\textbf{z}}\dot{\textbf{z}}^T>_n
<z˙z˙T>n进行奇异值分解计算得到。即,
<
z
˙
z
˙
T
>
n
=
P
Λ
P
T
<\dot{\textbf{z}}\dot{\textbf{z}}^T>_n=\textbf{P}\Lambda\textbf{P}^T
<z˙z˙T>n=PΛPT。其中,
z
=
Λ
−
1
/
2
U
T
X
\textbf{z}=\Lambda ^{-1/2}\textbf{U}^T\textbf{X}
z=Λ−1/2UTX,
Ω
=
d
i
a
g
{
λ
1
,
λ
2
,
…
,
λ
M
}
\Omega =diag{\{ \lambda _1,\lambda _2,\dots,\lambda _M\}}
Ω=diag{λ1,λ2,…,λM},
λ
1
,
λ
2
,
…
,
λ
M
\lambda _1,\lambda _2,\dots,\lambda _M
λ1,λ2,…,λM是
<
z
˙
z
˙
T
>
n
<\dot{\textbf{z}}\dot{\textbf{z}}^T>_n
<z˙z˙T>n的特征值,按升序排列。需要强调的是,我们提出的方法是基于线性慢速特征分析的。
2.1.2 Dimension reduction 降维
为了消除噪声的影响,将慢速特征截断(truncated)[25]。

其中,
Δ
(
x
j
)
=
<
x
˙
j
2
>
n
\Delta (\textbf{x}_j)=<\dot{x}_j^2>_n
Δ(xj)=<x˙j2>n和
Δ
(
s
i
)
=
<
s
˙
i
2
>
n
\Delta (\textbf{s}_i)=<\dot{s}_i^2>_n
Δ(si)=<s˙i2>n分别是第j个变量和第i个慢特征的评价变化。
c
o
u
n
t
<
⋅
>
count<\cdot>
count<⋅>表示数据集中元素的个数。因此,用于构造轨迹统计量慢特征个数由一下给出:

因此,轨迹慢特征矩阵由
s
˜
=
[
s
˜
1
,
…
,
s
˜
n
]
∈
R
M
˜
×
N
\~{\textbf{s}}=[\~{\textbf{s}}_1,\dots,\~{\textbf{s}}_n]\in\mathbb{R}^{\~{M}\times N}
s˜=[s˜1,…,s˜n]∈RM˜×N给出,其中,
s
˜
=
[
s
1
,
n
,
…
,
s
M
˜
,
n
]
T
\~{\textbf{s}}=[{s}_{1,n},\dots,{s}_{\~{M},n}]^T
s˜=[s1,n,…,sM˜,n]T,相应的统计量为:

其中,
Ω
˜
=
d
i
a
g
{
λ
1
,
…
,
λ
M
˜
}
\~{\Omega}=diag{ \{\lambda_1,\dots,\lambda_{\~{M}}\} }
Ω˜=diag{λ1,…,λM˜}。然而,然而,如果过程数据变化缓慢,则
S
˙
n
2
\dot{S}_n^2
S˙n2对于
M
˜
\~{M}
M˜最慢特征的变化和幅度非常小。为了使该方法对时间变化更加敏感,设计基于移动窗口的统计量为:

其中,K是滑动窗口的长度,
<
s
˜
˙
>
k
=
1
K
∑
K
=
1
K
s
˜
˙
n
−
k
<\dot{\~{\textbf{s}}}>_k=\frac{1}{K}\sum_{K=1}^{K}\dot{\~{\textbf{s}}}_{n-k}
<s˜˙>k=K1∑K=1Ks˜˙n−k
是移动窗口中缓慢特征向量的平均值。
2.2 Kernel Density Estimation (KDE) 核密度估计
通常采用KDE来估计随机变量的概率分布,给定一个不知道其分布的样本数据集。使用高斯核函数的单变量KDE定义为[35]:

其中
φ
1
,
…
,
φ
I
φ_1,…, φ_I
φ1,…,φI为变量
φ
φ
φ 的
I
I
I 个样本,
δ
δ
δ为平滑系数,必须通过[36]中的方法确定。
给定置信系数
α
α
α,由累积概率可得
φ
L
φ_L
φL和
φ
U
φ_U
φU(下标“L”和“U”分别为下限和上限):

利用KDE方法估计了确定的过渡化指标的控制极限和基于轨迹监测的测试统计量。
2.3 Slowest Slow Factor (SSF) for transition identification 用于过渡识别的最慢因子
过渡过程监控的第一步是确定流程是否进入或离开过渡模态。在这项工作中,提出了以下指标,最慢慢特征(SSF):
S
S
F
n
=
s
i
∗
(14)
SSF_n=s_i* \tag{14}
SSFn=si∗(14)
其中,
i
∗
=
a
r
g
m
i
n
i
<
s
˜
i
2
˙
>
n
i*=argmin_i<\dot{\~{\textbf{s}}_i^2}>_n
i∗=argmini<s˜i2˙>n
必须注意的是,以不同频率为特征的慢特征是多元过程变量变化的“共同原因”,高频慢特征可能是由噪声引起的;低频慢速特征更能代表系统的运行状态,其中SSF最为典型。稳态模式下的SSF值可能是平稳的,而过渡过程中的SSF值则是时变的。因此,SSF可以跟随系统切换的趋势。因此,采用SSF来判断系统是处于稳定模式还是过渡模式。相应的识别步骤如下:
步骤1:收集数据集
X
∈
R
M
˜
×
N
X\in\mathbb{R}^{\~{M}\times N}
X∈RM˜×N。
步骤2:对
X
X
X执行SFA,得到每个数据点的
s
˜
n
\~{\textbf{s}}_n
s˜n和SSF。
步骤3:用前1个数据创建一个窗口
Φ
Φ
Φ。
第四步:在
Φ
Φ
Φ上进行KDE,计算极限值
Φ
U
Φ_U
ΦU和
Φ
L
Φ_L
ΦL。
步骤5:将下一个SSF添加到窗口
Φ
Φ
Φ,重复步骤4,直到SSF不在
[
Φ
L
,
Φ
U
]
[Φ_L, Φ_U]
[ΦL,ΦU]范围内。
步骤6:一旦SSFs不在限制范围内,就开始过渡程序。最后两个极限被存储为对应的稳态模式。
步骤7:为以下SSFs进行固定长度的移动窗口;在这些窗口上执行KDE并计算相应的限制。
步骤8:一旦当前窗口和前一个窗口之间的界限的变化小于定义的阈值,过渡过程被认为在前一个窗口结束时终止。
步骤9:重复步骤2到步骤8,识别所有数据点的模式。
如图1所示,稳态过程中的移动窗长逐渐增大。与定长移动窗口不同的是,随着时间的推移,移动窗口的右侧会向前移动,而左侧则保持不变[37]。这样,窗口大小的选择对过渡起始点的识别没有明显的影响。一旦确定了转换开始,窗口长度将固定,直到转换结束。而且,终点的识别对监测结果影响不大。综上所述,窗口长度对监测方法的性能影响不大。
对于在线识别,将新数据
x
o
n
\textbf{x}_{on}
xon用
W
W
W投影得到
s
˜
o
n
\textbf{\~{s}}_{on}
s˜on和
S
S
F
o
n
SSF_{on}
SSFon。如果
S
S
F
o
n
SSF_{on}
SSFon在稳态模式范围内,则
x
o
n
\textbf{x}_{on}
xon属于稳态模式;否则,如果其上一个/下一个数据点属于当前/下一个稳定模式,则
x
o
n
\textbf{x}_{on}
xon为过渡过程的起始/结束点。

2.4 Modeling and fault detection 建模和故障检测
2.4.1 Control limits 控制限
与任何统计过程控制(SPC)过程一样,让我们假设在模型构建阶段可以获得许多正常转换的历史数据。尽管这样的转换被认为是正常的,但它们仍然有不同的长度。将基于SSF的方法确定的平均过渡长度记为
N
′
N '
N′,则标准过渡和其他正常过渡的数据集记为
X
1
M
×
N
′
,
X
2
M
×
N
′
,
…
,
X
l
M
×
N
′
\textbf{X}_1^{M×N '} , \textbf{X}_2^{M×N '},…, \textbf{X}_l^{M×N '}
X1M×N′,X2M×N′,…,XlM×N′。它们在过渡开始后的每个采样时间的统计量的控制极限可通过以下步骤计算:
步骤1:使用
X
l
M
×
N
′
\textbf{X}_l^{M×N '}
XlM×N′建立SFA模型,得到权值矩阵
S
S
S。
步骤2:确定主要慢特征的个数
M
˜
\~{ M}
M˜,得到慢特征
s
˜
n
1
\~{ s}^1_n
s˜n1。
步骤3:对每一个正常的过渡,数据由
W
W
W投影。
步骤4:计算所有正常转换数据集在过渡开始后的每个采样时间的
L
o
n
Lo_n
Lon和
S
p
Sp
Sp统计量的值。
步骤5:给定一个置信水平
α
α
α,
L
o
n
Lo_n
Lon的低限和高限分别是
L
o
n
L
Lo_{nL}
LonL和
L
o
n
U
Lo_{nU}
LonU,
S
p
Sp
Sp的低限和高限分别是
S
P
L
SP_L
SPL和
S
P
U
SP_U
SPU,其可由2.2节提到的KDE计算得到。
特别的,测试统计量“位置”写做
L
o
=
∣
L
o
n
−
1
2
(
L
o
n
L
+
L
o
n
U
)
∣
Lo=|Lo_n-\frac{1}{2}(Lo_{nL}+Lo_{nU})|
Lo=∣Lon−21(LonL+LonU)∣,相应的控制限就变成了单边的(unilateral),即,
L
o
T
=
1
2
(
L
o
n
U
−
L
o
n
L
)
Lo_T=\frac{1}{2}(Lo_{nU}-Lo_{nL})
LoT=21(LonU−LonL)。
2.4.2 Fault detection and performance index 故障检测和性能指标
在在线应用程序中,第2.3节介绍了基于SSF的方法来识别传入数据是否正在进入过渡过程。本文只对过渡过程进行监测,计算在线样本在过渡过程中的统计量
L
o
Lo
Lo和
S
p
Sp
Sp。如果连续
L
o
Lo
Lo值超过相应的限定
L
o
T
Lo_T
LoT值或
S
p
Sp
Sp值不在
[
S
p
L
,
S
p
U
]
[Sp_L, Sp_U]
[SpL,SpU]的控制区间内,则表明检测到了一个故障。
在我们后续的讨论中,我们使用了以下性能指标:漏报率 missed alarm rate(MAR)和误报率 false alarm rate(FAR)[38]。MAR是缺失报警数与故障样本总数的比值。由于当
L
o
Lo
Lo和
S
p
Sp
Sp中的任何一个失控时,即判定一个样本为故障,因此采用联合漏警率J,即Lo和Sp同时存在的漏警数与故障样本总数之比。FAR是错误报警数与正常数据数的比值。
2.5 Classification of operation faults 分类和操作故障
在数据驱动监测研究中,很少讨论过渡故障的性质。此外,在常用的基准示例(如TE问题)中没有错误的转换数据。在本节中,我们将介绍一个生成错误操作的程序,以评估我们和其他监测方案。表1列出了HAZOP的引导词及其解释[31]。根据这些引导词,表2定义了8种过渡过程操作故障。具体来说,OF1被定义为生成场景相关的指导词“Before”和“After”。OF2和OF3分别与指导词“More”和“Less”相关。OF4是根据指导词“反向”来定义的。OF5和OF6指的是指导词“早”和“晚”;导语“Part of”引出OF7的定义;OF8是根据指导词“Other than”给出的。


应该指出的是,我们提出的基于轨迹的监测方案只适用于已知过程在过渡模式下开始运行的情况。一旦故障的特征在观测变量中得到充分反映,就可以用我们提出的方法检测故障。
综上所述,本文提出了一种基于慢特征分析的过渡识别与监测方案。具体来说,使用基于SSF的方法来识别转换的开始和结束;提出了一种基于轨迹的监测方案,该方案采用了表示轨迹位置和过渡速度的两个监测统计量。此外,根据危害与可操作性分析指南(HAZOP)生成过渡过程转换的操作故障。并将提出的过渡识别与监测方案应用于运行故障。
3 案例研究
为了证明所提出的过渡监测方法的可行性,文中给出了两个算例(数值算例和TE过程)。将该方法与基于阶段的sub-PCA方法进行了比较,其中包括基于阶段的识别方法和sub-PCA的故障检测方法。此外,应用[29]提出的GSSFA (global preserving statistics slow feature analysis,全局保持统计慢特征分析)验证了我们的方法在故障检测上的优势。
3.1 A numerical example 一个数值例子
数值算例的正常过渡和8个运行故障数据集的生成步骤与TE过程相似。因此,为了简单起见,在附录中给出了数值例子的细节。
3.1.1 Process description 过程描述
在这个例子中,我们考虑了一个模拟的过程。有六个变量
V
1
,
…
,
V
6
V_1,…,V_6
V1,…,V6其中
V
1
V_1
V1和
V
2
V_2
V2为两个操作变量。在初始稳态期间,它们在噪声
e
1
e_1
e1和
e
2
e_2
e2的作用下处于零。两个过程变量
V
3
、
V
4
V_3、V_4
V3、V4与
V
1
、
V
2
V_1、V_2
V1、V2的关系为:

V
5
V_5
V5 and
V
6
V_6
V6 are related to operating/process variables
V
1
,
.
.
.
,
V
4
V_1, . . . , V_4
V1,...,V4 by
 其中
e
1
,
…
,
e
6
∼
N
(
0
,
0.01
)
e_1,…, e_6 \sim \mathbb {N}(0,0.01)
e1,…,e6∼N(0,0.01)为白噪声。正常过程的总模拟时间为
400
h
400 h
400h,采样时间为
0.1
h
0.1 h
0.1h。
其中
e
1
,
…
,
e
6
∼
N
(
0
,
0.01
)
e_1,…, e_6 \sim \mathbb {N}(0,0.01)
e1,…,e6∼N(0,0.01)为白噪声。正常过程的总模拟时间为
400
h
400 h
400h,采样时间为
0.1
h
0.1 h
0.1h。
必须注意的是,系统在1501个样品时进入过渡,在2328个样品左右进入下一个稳定模式。整个过程产生4000个原始正常样本。正常稳态及其转变如图2所示。

3.1.2 Transition identification 过渡过程识别
在本节中,将本文提出的方法与基于阶段的子主成分分析方法进行比较,其中包括基于阶段的识别方法和基于子主成分分析的监测方法。在正常数据集上进行了基于ssf方法的过渡识别和基于阶段方法的离线模式分类。对于所提出的基于ssf的识别方案,我们设置
α
=
99
%
,
l
=
10
α = 99\%, l = 10
α=99%,l=10。在基于阶段的方法中,使用K-means聚类方法。最初的方法不包括确定实际簇数的方法。因此,本研究采用减法聚类方法[39]来识别3个聚类。簇1和簇3是初始稳定状态,而簇2是过渡状态。
表3显示了转换开始/结束标识中的平均偏差。基于阶段的方法始终在起始点识别中较晚,在终点识别中较早。基于ssf的方法可以准确地找到起点,也可以识别出更接近的端点,与基于阶段的方法相比,误差减少了181.28个采样瞬间。

3.1.3 Fault detection 故障识别
根据表A.1中的步骤生成转换的故障数据集。在过渡过程中,基于轨迹的方法的故障检测是基于表3所示的基于ssf的方法识别的过渡开始/结束结果,我们的方法使用了两个慢特征,即
M
˜
=
2
\~{M} = 2
M˜=2。转换开始后每个后续点的控制限使用2.2节中描述的KDE计算,置信水平为95%。为了更好地比较基于轨迹的方法和子主成分分析方法的监测性能,子主成分分析方法采用基于ssf方法识别的正确过渡起点到终点的范围,并进一步细分为三个阶段。PCA中潜在空间的累积贡献率为90%,并计算了
T
2
T^2
T2和SPE在95%置信水平下的控制限。
所有过渡过程操作故障的MAR和FAR如表4所示,其中
H
o
t
e
l
l
i
n
g
’
s
T
2
Hotelling’s T^2
Hotelling’sT2统计量为PCA归一化平方分数之和;平方预测误差(SPE)被称为Q统计量,用来度量原始空间在PCA残差子空间上的投影[40]。基于轨迹的方法能够检测到错误操作,其MAR在0到4%之间,OF3和OF6的FAR在10%左右,而其余的几乎为零。sub-pca方法对OF2、3、5、6等半故障(half faults)具有较大的MAR,对OF2、3、5等半故障具有约20%的FAR。对于OF1和OF8,它们从转换的开始到结束都存在,因此在转换过程中不存在虚警。

具体而言,对于OF2,采用传统的SFA监测前稳态模式下的第1001 - 1500个样本,采用基于轨迹的方法监测过渡过程,故障发生在第1501个样本,并持续到第2100个样本。OF2的检测结果如图3(a)所示。根据
S
p
Sp
Sp统计量,基于轨迹的方法识别出系统在步骤1OF2中比预期的更快,而在步骤2OF2中比预期的更慢。此外,
L
o
Lo
Lo统计量表明,基于轨迹的方法从正常的过渡轨迹中识别出实际不在变化范围内的系统。由于所提出的方法成功地检测到了OF2,所以对应的MARs很低,
L
o
Lo
Lo为0.055,Sp为0.0559。从表A.1可以看出,步骤1OF2和步骤2OF2中V2的变化之和等于标准操作中V2的变化,因此系统在步骤2OF2结束时达到了正常状态。通过我们的方法,在步骤3OF2之后,几乎所有的正常样本都在控制范围内,这导致了较低的FARs,即
L
o
Lo
Lo为0.016,
S
p
Sp
Sp为0.0186。对于图3(b)所示的子PCA方法(前一稳定模式的第1001 - 1500个样本由PCA模型监测),由于所有spe都失控,第一阶段没有MARs。然而,在第二阶段有大量的
T
2
T^2
T2和SPE的漏报。子主成分分析方法检测到的是初始故障,但不能检测到后期故障。另外,以下阶段2的样本实际上是在步骤3OF2之后,大部分都被认为是有缺陷的。

OF5的类似结果如图4所示。在OF5中,步骤2OF5的开始时间比平时早了100个采样瞬间,因此故障发生在第1701个采样点,一直持续到第2100个采样点。基于轨迹的方法立即识别故障,并保持报警直到步骤2OF5结束,并且步骤2OF5之后的样本几乎在限制范围内(图4(a))。子pca方法也可以识别步骤2OF5的早期操作。然而,之后的样本(从1801到2100)被判定为正常。在步骤2OF5和步骤3OF5边界附近的正常样本被检测为故障(图4(b))。因此,基于轨迹的方法的MAR和FAR均低于子主成分分析方法。
通过实例,我们证明了基于ssf的方法比基于阶段的方法具有更好的过渡识别性能,而基于轨迹的监测方法能够从位置和速度两方面检测过渡中的故障,且性能优于子主成分分析方法。

3.2 TE Process TE 过程
为了进一步验证我们提出的方法的优势,我们以广泛使用的Tennessee Eastman (TE)过程作为验证对象,并在本节中对[29]中提出的最新技术GSSFA (global preserving statistics slow feature analysis)进行对比。
3.2.1 Process and simulator description TE过程和仿真器描述
Tennessee Eastman (TE)工艺由Downs和Vogel[41]于1993年提出,并被广泛应用于科学研究。共有5个单元,53个变量,其中12个被操纵变量和41个过程变量。控制方案及正常操作由Ricker提供[42],相应的仿真平台可从 http://depts.washington.edu/control/LARRY/TE/download.html下载。设计了12个控制回路设定值,其中表5中的XMEAS(17)、XMEAS(40)、XMEAS(23)、XMEAS(25)、XMV(10)相关的生产设定值、摩尔% G设定值、yA设定值、yAC设定值和反应器温度设定值分别标记为 O V 1 − O V 5 OV_1−OV_5 OV1−OV5。通过改变这五种设置,可以得到6种稳定模式及其之间的转换,6种模式的不同参数如表6所示[42],其中G和H为TE过程中的两种产物,“G/H”为质量比。由于循环值、蒸汽值和搅拌速率在模拟过程中没有变化,因此这三个变量不包括在监测变量中。表5所示的其余41个过程变量和9个被操纵的变量被选择用于过程监控。


3.2.2 Normal and faulty datasets 正常和故障数据集
6种模式之间的大部分转换都可以通过一步操作获得。然而,模式4到模式2的切换需要通过合理的多步操作才能实现,我们选择这一步作为我们的测试例。每次转换的模拟时间为
400
h
400 h
400h,间隔为
0.05
h
0.05 h
0.05h。正常转换首先在模式4下运行,在第3201个样本时切换到模式2。
O
V
1
−
O
V
5
OV_1−OV_5
OV1−OV5的设置范围分别为36.04、53.35、61.95、58.76、128.2 ~ 22.73、11.66、64.18、54.25、124.2。如果一步到位,会导致系统崩溃。因此,通常的操作是这样设计的:
O
V
2
OV_2
OV2在第3201个采样瞬间首先减小-18,然后在第4801个采样瞬间减小- 23.69。生成30个额外的正常数据集,其
β
=
[
0.95
,
1.05
]
β=[0.95, 1.05]
β=[0.95,1.05],切换时间变化为±5个采样瞬间。
另外,根据表2的描述,生成了8个故障OF1-OF8,列于表7中。其中OF2、OF4、OF7、OF8属于灾难性故障,会导致系统崩溃。转换只能在OF1, OF3, OF5和OF6中成功实现。

3.2.3 Transition identification 过渡过程识别
在正常数据集上分别采用基于ssf的方法和基于阶段的方法来识别过渡模式。正态过渡的SSF变化及识别结果如图5所示,基于阶段方法的模态识别结果如图6所示。

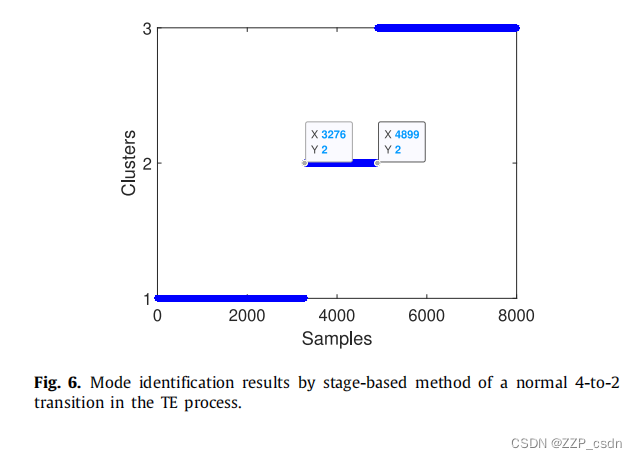
对于过渡过程的真正终点,没有可靠的结论。在这项工作中,我们使用A Feed的变化(XMEAS(1))来确定终点,因为它的不稳定持续时间几乎是所有变量中最长的。结果在图7所示的第5387个样本附近。开始和结束识别的平均偏差如表8所示。同样,基于ssf的方法在起点识别方面相对准确,但在终点确定方面稍晚,而基于阶段的方法在起点识别方面一贯较晚,在终点确定方面较早。


3.2.4 Fault detection 故障检测
对于所提出的基于轨迹的监测方法,计算出的
M
˜
\~{M}
M˜为13。 图8(a)和(b显示了基于轨迹的方法对转换开始后Lo和Sp的正常转换和逐点控制极限的监测结果。由于整个转换存在较大变化,因此也提供了Sp的局部放大视图 (图8 c ),以证明在每个时间点确实存在允许的变化范围。

将基于ssf的方法识别出的正确过渡起始点到结束点的范围应用于子pca和GSSFA方法。子pca方法将过渡范围细分为3个阶段,分别采用95%置信水平得到t2和SPE的3个极限,对一个正态过渡的监测如图9所示。Dp和Dr为GSSFA的两个检验统计量,其极限值由KDE计算,置信水平为95%,正常过渡的监测结果如图10所示。


MAR/FAR结果如表9所示。除了对于OF2的灾难性故障具有高MAR(74.42%)外,基于轨迹的方法对于其余故障具有低MARs(低于3%)。对于OF1、OF2、OF3、OF5、OF7, GSSFA的大部分MARs都高于基于轨迹的方法。只有使用子pca方法才能对OF1和OF8进行合理的检测。轨迹法和亚主成分分析法的准确率均小于5%。而GSSFA法Dp的FARs均超过10%。8条断层的可视化对比如图11所示。

具体到OF2,操作变量OV2变化了−19.5,略大于正常值−18。如图11(b所示,基于轨迹的方法和两种比较算法最初都无法检测到这种差异。然而,基于轨迹的方法能够在第166个样本附近报警,比GSSFA早8个样本。对于子主成分分析方法,在系统崩溃之前无法检测到故障。本文提出的方法在故障发生前检测到灾难性故障的能力,下一节将详细讨论系统故障。
在OF3中,OV2的初始减少小于要求的。如图11(c所示,子pca方法最初没有检测到OF3,该方法和GSSFA方法都可以识别,且持续偏差超出了控制极限。然而,在GSSFA方法中有更多的统计数据属于控制极限。

OF5的特征是第二步的提前开始。如图11(e所示,子PCA方法能够报警过早启动,但后期报警消失;虽然前部分GSSFA方法对OF5表现良好,但过程结束时有一些漏报报警;基于轨迹的方法报警持续超出控制范围的小偏差,直到过程结束。报警性质上的差异反映了三种方法在监测理念上的差异。


在OF7中,OV1中的更改被遗忘。断层的初始轨迹与正线非常相似。我们的方法在整个过程中几乎检测到所有的故障样本,但GSSFA方法从一开始就没有检测到少数故障样本,如图11(g所示。子主成分分析法在初始阶段报警,但统计量很快回归到控制限以下。这是因为OV1几乎是恒定的,不会对PCA产生影响。


3.2.5 Detection Time(DT)and Rescue Time (RT)for catastrophic failure 灾难性故障的检测时间和营救时间
如3.2.2节所述,导致系统崩溃的OF2、OF4、OF7、OF8被视为灾难性故障。TE过程中不可恢复故障的概念最早由Chen和Wong提出[34]。对于这些故障,通过在一定时间内纠正故障,系统有可能恢复正常。但是,如果故障持续一段时间,即使采取纠正措施,系统仍然无法正常运行。这个特定的时间在这里定义为救援时间 rescue time (RT)。RT只有在可以模拟的TE过程等基准问题中才能确定。RT的值是通过在不同时间实施纠正动作的重复模拟得到的。RT是故障开始后,即使执行了纠正措施,系统仍会崩溃的最晚时间。对于灾难性故障,该监测方法只有在其检测时间detection time(DT)早于RT时才有效。因此,应用RT和DT来评估所提出方法的可行性。必须注意的是,DT = ta−t0,其中ta是样品报警的时间瞬间,t0是过程从正常状态到异常状态变化的实际时间瞬间。另外,选择ι为3来计算DT。
如图12所示,OF2的E进料(XMV(2))和反应器压力(XMEAS(7))的变化。本次故障中,运行变量OV2的变化值为- 19.5,略大于正常值- 18。表10中OF2的RT表示,如果在9.45 h前故障得到纠正,系统是可恢复的;否则,系统将崩溃。通过对4-to-2转换的模拟,可以找到不同灾难性故障的RTs。为了恢复故障,必须在RTs之前检测到故障。因此,我们关注的是监测方法是否能够在rt之前提前很长时间检测到故障。我们认为这是文献中第一次系统地讨论灾难性故障前的检测。
对于所有的运行故障,故障的rt值和三种方法的dt值如表10所示。基于轨迹的方法对所有故障的dt都比基于子主成分分析的方法短。特别是对于灾难性故障OF4和OF8,有三种方法能够检测到故障,并有大量的时间来恢复系统。对于所提出的方法,OF2的系统恢复时间为1.15 h,比GSSFA方法多0.4 h。基于轨迹的OF2和OF7检测比GSSFA方法更早,但子pca方法无法在RT之前检测到OF2和OF7并提供预警。


Conclusion 结论
连续工业过程的正常运行不仅应包括在不同稳定状态下的运行,还应包括稳定状态之间的正常转换。与现有的过渡监测研究不同,我们将正常过渡描述为以允许的速度沿着定义的轨迹通过可变空间。位置上的大偏差和实质上更快或更慢的速度应被认为是故障。具体来说,基于慢特征分析,提出了一种基于轨迹的方法。提出了两种包含位置和速度信息的统计方法。利用一系列正态过渡数据得到逐点控制极限。同时,转换过程中的操作故障作为第一次监控的对象产生。我们的新监测方法能够对各种类型的运行故障提供更好、更详细的警报。特别是,该方法能够提供更早的检测时间(DT)比救援时间(RT)对灾难性故障。
















 1638
1638











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









