







 本文提出了一种稀疏慢特征分析(SparseSFA)模型,通过回归型重构和非凸优化,增强了过程数据的解释性和模型的稀疏性。研究展示了在过程监测和故障隔离中的应用,特别是在田纳西伊士曼过程中的案例研究,证明了这种方法的有效性和实用性。
本文提出了一种稀疏慢特征分析(SparseSFA)模型,通过回归型重构和非凸优化,增强了过程数据的解释性和模型的稀疏性。研究展示了在过程监测和故障隔离中的应用,特别是在田纳西伊士曼过程中的案例研究,证明了这种方法的有效性和实用性。
Sparse Slow Feature Analysis for Enhanced Control Monitoring and Fault Isolation 稀疏慢特征分析增强控制监测和故障隔离
Abstract
本文提出了一种新的时间序列数据潜变量模型——稀疏慢特征分析(SFA),用于过程监测和故障隔离。我们首先根据一种新的回归型问题对稀疏SFA进行了重新建模,并进一步将 l 1 l_1 l1范数惩罚纳入目标中以提高稀疏性。为了解决诱导非凸优化问题,提出了一种定制迭代算法。使用稀疏表示,可以完全省略贡献不显著的过程变量,并且与通用SFA相比,每个潜在变量仅与关键过程变量的一小部分相关。提出了一种基于稀疏SFA的过程监控与故障隔离方法,提高了监控性能,诊断结果易于理解,发现了有意义的过程知识。对田纳西伊士曼过程进行了案例研究,以解决所提出方法的适用性。
Introduction
由于智能制造技术的发展,工业数据的可用性正在爆炸式增长,这推动了过程数据分析的范式,并为实现过程工业的智能决策提供了巨大的机会。
在实际情况中收集的过程数据通常具有所谓的“数据丰富但信息贫乏”现象。为了解决这个问题,潜在变量模型(lvm),如主成分分析(PCA)、独立成分分析(ICA)、典型变量分析(CVA)和偏最小二乘(PLS)已经得到了广泛的研究,其中构建了低维子空间来解释基于各种标准的过程数据变化[2]。从动态系统中采样,过程数据本质上是时间序列数据。虽然经典的lvm已经扩展到它们的动态对应,如动态PCA[3]和动态ICA[4],但表征过程变化驱动力的诱导潜在变量仍然被假设为独立分布。从这个意义上说,它们在描述过程动力学方面显示出根本性的局限性。近年来,潜在变量具有时间相关性的潜在变量模型受到越来越多的关注,代表性的潜在变量模型包括动态内主成分分析[5]、协整分析[6]和慢特征分析(SFA)[7]。SFA作为时间序列数据降维的有效工具,在过程数据分析中具有独特的可解释性,近年来,SFA在过程监控[8]、[9]、[10]、故障诊断[11]、软测量[12]、[13]、振荡检测[14]等领域的应用越来越广泛。SFA的一个独特优点是,它能够根据
P
(
x
)
P(\textbf x)
P(x)和
P
(
x
˙
)
P(\dot {\textbf x})
P(x˙)对稳态和过程动力学进行判别描述,并且通过这种方式,标称操作条件的变化和实际故障可以被发现。明确区分,有利于排除虚警[8]。
在SFA的原始公式中,由于模型系数通常不为零,因此每个潜在变量都与所有输入相关。然而,已经发现SFA中的一部分系数趋于接近于零[8]。这是因为SFA中的潜在变量代表了过程变化的缓慢演变的驱动因素,这些因素可能在局部传播,只影响一小部分过程变量。因此,稀疏性是SFA模型的理想属性,它也有助于在存在测量噪声的情况下减轻过度拟合作为一种正则化方法。稀疏性最近被作为一种有用的先验知识来增强lvm的可解释性,激发了稀疏PCA[15]、稀疏PLS[16]和稀疏CVA[17]等简约模型。随着大多数模型系数被强制为零,潜在变量和过程变量之间的关系变得更加清晰,这允许更容易的解释和分析。
在这项工作中,我们旨在开发一种具有稀疏特性的新型SFA模型,并揭示其在过程监控和故障根本原因分析方面的独特优势。需要注意的是,文献[18]中提出了一种稀疏核SFA算法,但该算法对数据样本而不是过程变量的系数施加了稀疏性。因此,[18]中的方法不能适用于我们的情况,需要进行特殊处理。我们首先将SFA重新定义为一种新的回归型优化问题,在此基础上,可以方便地将非规范稀疏性惩罚纳入原始目标。为了有效地解决诱导问题,提出了一种定制的算法,该算法在求解一般套索型问题和执行降阶procruste旋转之间迭代。提出的稀疏SFA允许通过调整正则化参数来方便地权衡慢度和稀疏度。在此基础上,我们明确了它在设计监测统计数据中的具体用途,这些统计数据分别用于检测操作条件偏差和过程动态异常。采用[19]中提出的两级贡献图,利用模型稀疏性实现高效的故障排除,其中大多数非决定性变量的贡献趋于缩小为零。基于田纳西伊士曼(TE)工艺,我们进行了全面的仿真案例研究。研究发现,诱导潜变量具有明确的结构性质,由于它们应该在全局范围内传播,较慢的特征往往会影响更多的变量,这与我们的共同过程知识相一致。此外,与传统的贡献图技术相比,模型稀疏性大大提高了监测灵敏度,获得了清晰的故障诊断结果。
本文的布局组织如下。在下一节中,我们将重新审视通用SFA模型,提出一种新的稀疏SFA公式,并开发一种定制的求解算法。第三节介绍了诱导过程监测和故障隔离策略。案例研究的结果载于第四节,然后是最后的结论。
SPARSE SFA MODEL
A. Generic SFA Model and Regression-Type Reformulation 通用SFA模型与回归型重构


Sparse SFA
为了提高 W j W_j Wj的稀疏性,我们解决了以下回归型问题:
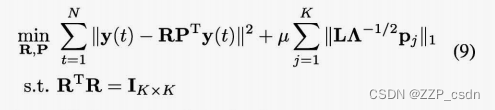
其中,(8)用于
l
1
l_1
l1范数项,以提高
W
j
W_j
Wj中的稀疏性。已知,
l
1
l_1
l1范数是精确评估模型稀疏性的
l
o
l_o
lo 范数的最紧凸松弛。此外,由
l
1
l_1
l1范数引起的优化问题通常允许有效的数值求解算法。引入正则化参数
μ
μ
μ来平衡两个相互冲突的目标,即模型稀疏性和特征的慢度。当
μ
μ
μ设为零时,(9)的解简化为一般的SFA。当
μ
>
0
μ > 0
μ>0时,
Q
Q
Q不再保持正交性。也可以使用单独的
{
u
j
}
\{ u_j \}
{uj}来惩罚不同慢速特征的系数。注意,我们只从最快的特征中寻找
K
<
m
K < m
K<m个慢速特征,类似于包含很少信息的短期噪声。然而,(9)本质上是一个非凸优化问题。为了解决计算问题,提出了一种迭代算法,其动机是[20]。其思想是迭代优化R和P,直到达到收敛,如下所述。

通过变换
Z
j
=
L
Λ
−
1
/
2
p
j
Z_j = L\Lambda ^{- 1/2}p_j
Zj=LΛ−1/2pj
Z
j
Z_j
Zj的更新本质上是Lasso估计:
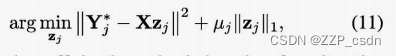
可通过快速迭代收缩阈值算法(FISTA)有效求解[21]。我们强调,最小角度回归(LARS)算法[22]不能在这里应用,因为输入不具有单位长度。
在给定P的情况下优化R,注意
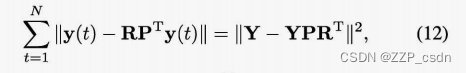
其中
Y
=
[
y
(
1
)
,
⋅
⋅
⋅
,
Y
(
N
)
]
T
Y = [y (1),···,Y (N)]^T
Y=[y(1),⋅⋅⋅,Y(N)]T。因此,固定P后,(9)化简为如下约束最小化问题:
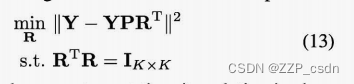
通过降阶procrusti旋转,其解为
R
^
=
U
V
T
\hat R = UV^T
R^=UVT[20],其中
U
U
U和
Y
Y
Y对
Y
T
Y
P
=
U
D
V
T
Y^TYP = UDV^T
YTYP=UDVT进行SVD计算。
可以通过检查(9)的目标是否收敛来停止迭代,然后推导出最优解。案例研究将表明该算法确实具有收敛性,而理论分析将推迟到未来的工作中。同时,隐含的优点是它避免了连续导出潜在变量,就像在PLS中所做的那样。
C. Parameter Selection 参数选择
由于SFA可以用回归型公式来解释,模型拟合的性能可以很容易地通过求助于回归模型的准则来评估。例如,可以采用贝叶斯信息准则(BIC)来适当地选择
μ
μ
μ:
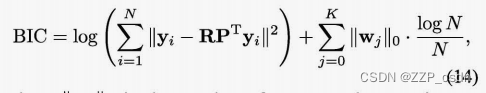
其中
∣
∣
w
j
∣
∣
0
||w_j||_0
∣∣wj∣∣0为
w
j
w_j
wj中非零元素的个数。也可以通过检查所选变量是否符合工艺知识来确定
μ
\mu
μ:
与导出的慢特征个数K一样,文献[8]表明,
s
j
s_j
sj的慢度是所有相关过程变量慢度的加权平均值,即:
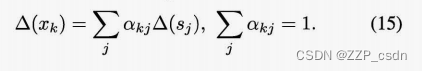
因此,如果
Δ
(
s
j
)
≤
m
a
x
{
Δ
(
x
k
)
}
\Delta(s_j)\le max \{\Delta(x_k) \}
Δ(sj)≤max{Δ(xk)} ,
s
j
s_j
sj倾向于使一些过程变量变化缓慢,因此可以认为是占主导地位的。我们建议逐步增加
K
K
K,并检查是否所有慢特征都占主导地位。
III. SPARSE SFA-INDUCED PROCESS DATA ANALYTICS 稀疏sfa诱导的过程数据分析
A. Monitoring Statistics Design A.监控统计设计
稀疏SFA模型对于给定的输入x给出了主导的慢特征。

随后,定义了
T
2
T^2
T2统计量以定量描述主要慢特征的稳态变化:

由于我们只从n个过程变量中提取出K个慢特征,慢特征可以捕获过程数据中的大部分变化,因此只需要监测未被T2统计量捕获的残余空间就足够了。重构误差或残余信号可以表示为:
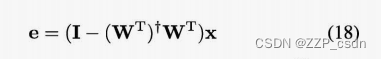
其中
(
W
T
)
+
(W^T)^+
(WT)+是矩阵
W
T
W ^T
WT 的 Moore-Penrose 逆。然后,预测误差的平方被定义为:

为了监控过程动态,我们可以定义
S
2
S^2
S2统计量:

如文献[10]所指出,
S
2
S^2
S2统计量由于其优越的灵敏度,足以监测过程动态.
使用上述监视统计数据的原理可以解释如下。一旦
T
2
T^2
T2或SPE统计量超过控制极限,P(x)被中断,则认为过程偏离了其原始稳态操作条件。或者,如果由
S
2
S^2
S2统计数据引起警报,则
P
(
X
)
P(X)
P(X)中断,过程动态可能异常。通过综合这两组具有不同物理含义的统计信息,过程工程能够更好地理解工业过程的运行状态。最重要的是,当流程在新创建的工作点上受到控制时,只需检查统计数据就可以有效地撤销由经典监控统计数据发出的滋扰警报。
B. Fault Isolation
本文采用[19]中提出的两级贡献图进行故障排除,这是因为它们具有系数稀疏性的优势。由于每个慢速特征可以理解为表示在系统周围传播并影响一组过程变量的一些变化,因此基于
S
2
S^2
S2的第
i
i
i个慢速特征的群明智贡献定义为:

定位故障组
i
∗
=
a
r
g
m
a
x
i
c
i
i^* = arg max_ic_i
i∗=argmaxici后,可以通过计算组变量贡献图来识别故障变量:
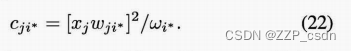
由于模型的稀疏性,系数为
W
j
i
∗
=
0
W_{j i *} = 0
Wji∗=0的变量的贡献为零,从而为故障隔离提供了清晰的信息。在这项工作中,我们特别注意使用82来确定动力学异常的根本原因。事实上,两水平贡献图也可以结合
T
2
T^2
T2和SPE统计来诊断异常的运行状况。
IV. CASE STUDIES
在本节中,使用TE基准流程[23]进行案例研究。该过程基于[24]中提出的全厂控制策略在闭环条件下运行。选取22个过程变量XMEAS(I- 22)和11个操纵变量XMV(I-11)作为监测变量[Xl(t),···,X33(t)jT],采样间隔为3 min。为了提高SFA的性能,我们为每个过程变量增加了一个滞后测量:
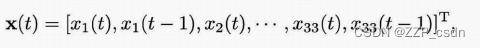
这就产生了总共66个监控变量。使用在正常运行状态下采集的500个数据样本建立稀疏SFA模型,占主导地位的数量
sf取K = 30。
接下来,我们研究了不同正则化参数f1 E {O, I '…7}。图1 (a)报告了稀疏SFA中非零系数过程变量的数量。随着f1的增大,零系数过程变量的数量增多,表明模型稀疏性增强。同时,一个有趣的观察是,较慢的特征有更多的相关过程变量,而最快的特征的系数更多地缩小到零。这是合理的,因为由于显著的惯性特性和较大的沉降时间,植物范围的变化直观地比局部变化慢。因此,较慢的特征通常是影响大多数过程变量的全厂变化的特征,而局部变化往往更快,只与局部变量有关。
增强的模型稀疏性是以牺牲慢特性的慢速度为代价的。从图1 (b)中可以看出,对于5个最慢的特征,其慢度值随着f1的增加有轻微增加的趋势。然而,诱导的剩余特征变得更慢,这表明利用结构稀疏性有助于解开过程变量之间的内在动态关联,揭示过程变化的缓慢驱动因素。由于测量噪声的存在和数据可用性的限制,在最慢特征的推导中不可避免地会出现过拟合,从而在推导其余特征时引入累积误差。这表明细读稀疏度是一种有效的启发式方法,可以缓解过拟合并提高SFA的模型性能。
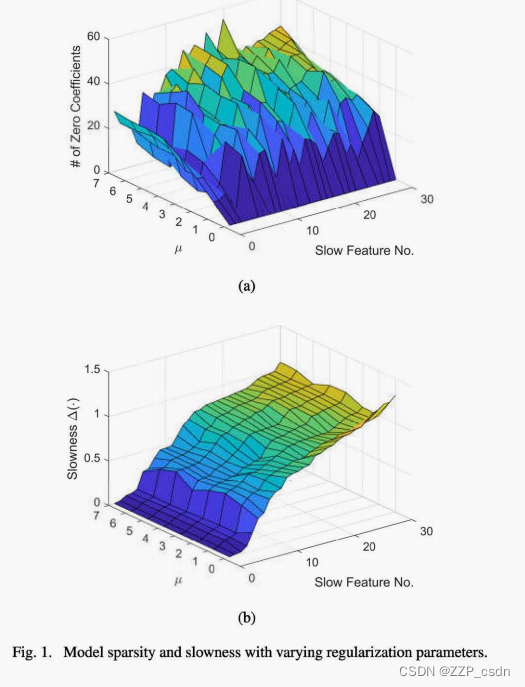
然后研究了稀疏SFA在过程监控和故障诊断中的应用。已知TE过程中的IDV(8)、IDV(lO)、IDV(lI)和IDV(12)是由随机变化的扰动引起的,这些扰动导致持续的动态异常,可以通过82统计量有效识别[8]。因此,我们在这四种错误情况下计算了三个统计量,并研究了正则化参数f1对基于82的动态异常检测率的影响,如表1所示。为了进行公平的比较,在一个独立的验证数据集上故意调整了控制限制,使诱导虚警率(FARs)为5%。可以看出,随着f1的增大,动态异常的检出率越来越高,当f1 = 5时表现最佳。这从根本上归功于SFA的稀疏性,这有助于更合理地提取慢速特征并提高对动态异常的灵敏度。当f1的值继续增大时,监测性能趋于下降,这表明过度惩罚非零系数会破坏模型性能。
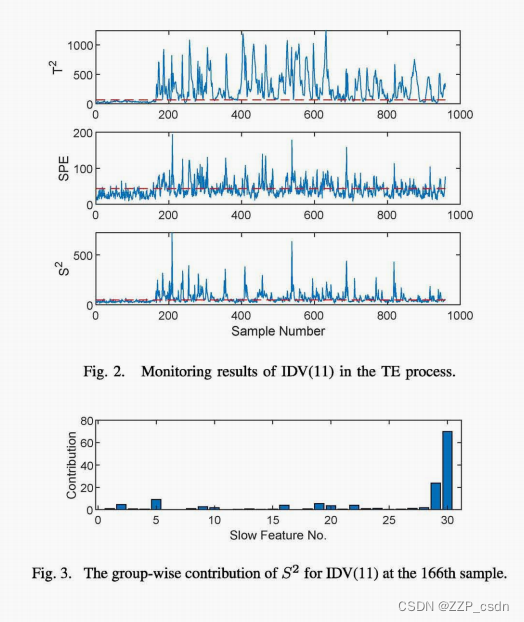
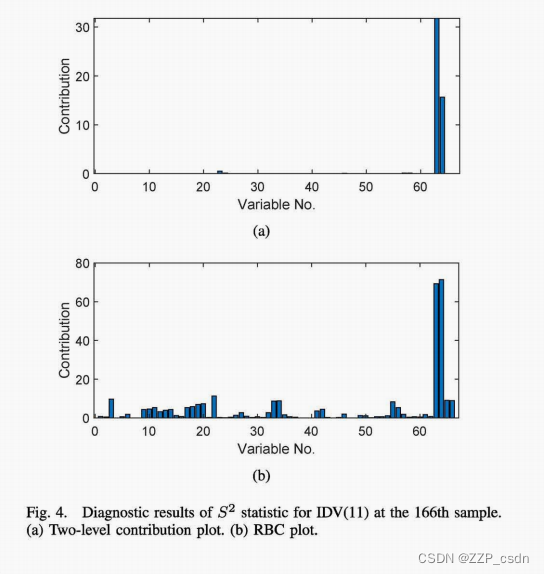
看到8 2统计触发的告警,需要进行故障隔离,找出动态异常的根本原因。接下来,我们将深入研究IDV(lI),其中反应堆冷却水进口温度发生随机变化。图2绘制了J1> = 5的稀疏SFA的监测统计量,其中运行状态偏差由t2和SPE统计量表示,过程动态异常由第166个样本的8.2识别。然后采用双贡献图进行进一步的故障排除。图3显示了各种慢速特征对群体的贡献,其中830个特征的贡献最为显著。因此,可以认为这是一个局部故障,因为扰动的缓慢特征只与一部分变量有关。正如预期的那样,在图4(a)中,组变量贡献给出了清晰准确的诊断结果,X32(t)和X32(t - 1),即XMV(lO)(反应堆冷却水流量的操纵变量)的测量值是主要原因。为了进行比较,图4(b)也计算了[25]中提出的基于重建的贡献(RBC)图。尽管RBC给出了正确的故障隔离结论,但大量变量仍有非零贡献。原因是RBC没有充分利用监测模型的稀疏特性,容易受到所谓的涂抹效应的影响。
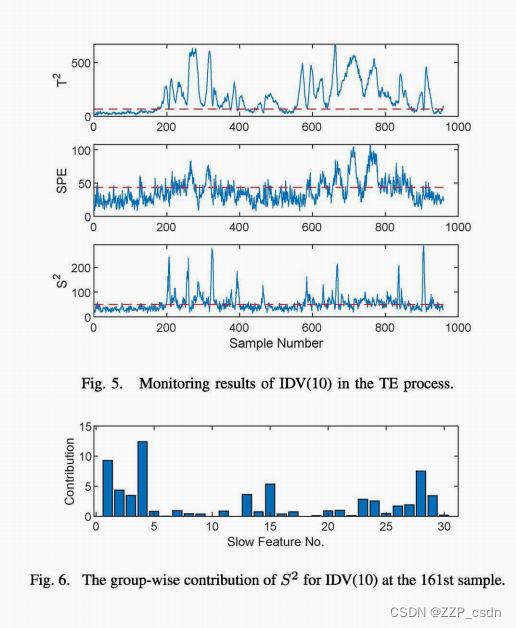
最后,我们转向IDV(lO),其中C进料温度发生随机变化,导致暂时的动态异常[8],可以通过图5中的
S
2
S^2
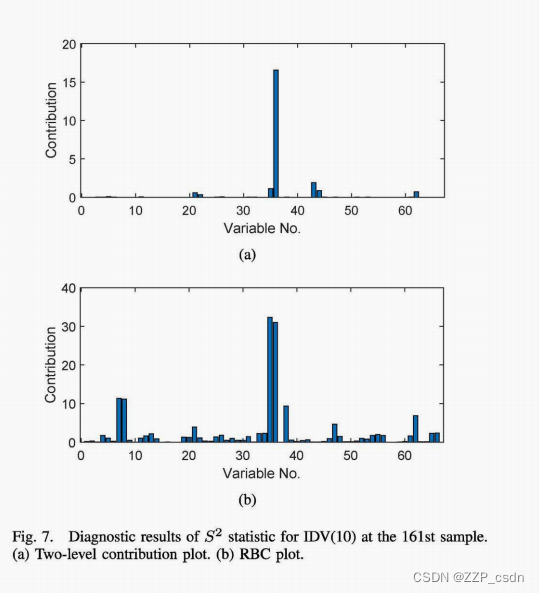
S2从第200个样本中检测到。因此,图6和**图7(a)**分析了第200个样本的贡献,其中第36个变量被认为是主要贡献者,其余大多数变量的贡献为零。这对应于XMEAS(18),即汽提塔温度,这与根本原因密切相关,因为C进料直接进入汽提塔。相反,**图7(b)**中的RBC图表明大量变量的非零贡献,因此不太明显。
V. CONCLUSIONS
本文提出了一种新的稀疏SFA模型,该模型引入了基于回归型SFA重新表述的h范数惩罚。开发了一种有效的算法来解决计算问题。结果表明,稀疏度作为有用的先验知识有助于提高基于sfa的过程监测技术的灵敏度,并通过两级贡献图获得清晰的故障诊断信息。值得一提的是,本文提出的稀疏SFA不仅适用于过程数据分析,还广泛适用于一般时间序列数据处理任务。在未来的工作中,值得研究在动态SFA中使用群套索来施加稀疏性。

















 9082
9082

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









