






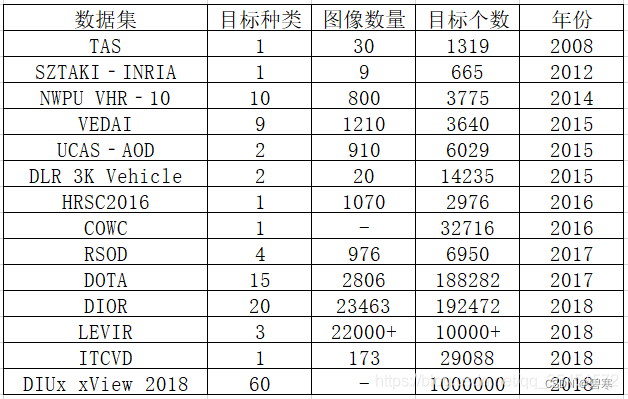
 本文介绍了多个用于遥感图像目标检测的数据集,包括TAS(专注于汽车检测)、DIOR(大规模光学遥感基准)、LEVIR(高分辨率场景)、DOTA、RSOD、UCAS-AOD、NWPUVHR-10、VEDAI和HRSC2016,涵盖了飞机、车辆、油罐等多种目标。这些数据集为遥感图像分析提供了丰富的训练资源和挑战。
本文介绍了多个用于遥感图像目标检测的数据集,包括TAS(专注于汽车检测)、DIOR(大规模光学遥感基准)、LEVIR(高分辨率场景)、DOTA、RSOD、UCAS-AOD、NWPUVHR-10、VEDAI和HRSC2016,涵盖了飞机、车辆、油罐等多种目标。这些数据集为遥感图像分析提供了丰富的训练资源和挑战。
1、TAS数据集
2、DIOR
3、LEVIR
4、DOTA
5、RSOD
6、UCAS-AOD
7、NWPU VHR-10
8、VEDAI
9、HRSC2016
1、TAS数据集
是为航空图像中的汽车检测而设计的。包含30张图片和1319辆手动标注的汽车。这些图像的空间分辨率相对较低,由建筑物和树木造成的阴影较多。
Heitz G, Koller D. Learning spatial context: Using stuff to find things[C]//European conference on computer vision. Springer, Berlin, Heidelberg, 2008: 30-43.
网页介绍链接http://ai.stanford.edu/~gaheitz/Research/TAS/
链接: https://pan.baidu.com/s/1fTl2ocIluJ8E9vMvCMP-lA 提取码: 2kca
2、DIOR
 用于光学遥感图像目标检测的大规模基准数据集。含23463张图片和190288实例,覆盖20种目标,比DOTA数据集更大!这20个对象类是飞机、机场、棒球场、篮球场、桥梁、烟囱、水坝、高速公路服务区、高速公路收费站、港口、高尔夫球场、地面田径场、天桥、船舶、体育场、储罐、网球场、火车站、车辆和风磨。
用于光学遥感图像目标检测的大规模基准数据集。含23463张图片和190288实例,覆盖20种目标,比DOTA数据集更大!这20个对象类是飞机、机场、棒球场、篮球场、桥梁、烟囱、水坝、高速公路服务区、高速公路收费站、港口、高尔夫球场、地面田径场、天桥、船舶、体育场、储罐、网球场、火车站、车辆和风磨。
Li K, Wan G, Cheng G, et al. Object detection in optical remote sensing images: A survey and a new benchmark[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2020, 159: 296-307.
下载地址:http://www.escience.cn/people/gongcheng/DIOR.html
3、LEVIR
 由大量 800 × 600 像素和0.2m〜1.0m /像素的高分辨率Google Earth图像和超过22k的图像组成。LEVIR数据集涵盖了人类居住环境的大多数类型地面特征,例如城市,乡村,山区和海洋。数据集中未考虑冰川,沙漠和戈壁等极端陆地环境。数据集中有3种目标类型:飞机,轮船(包括近海轮船和向海轮船)和油罐。所有图像总共标记了11k个独立边界框,包括4,724架飞机,3,025艘船和3,279个油罐。每个图像的平均目标数量为0.5。
由大量 800 × 600 像素和0.2m〜1.0m /像素的高分辨率Google Earth图像和超过22k的图像组成。LEVIR数据集涵盖了人类居住环境的大多数类型地面特征,例如城市,乡村,山区和海洋。数据集中未考虑冰川,沙漠和戈壁等极端陆地环境。数据集中有3种目标类型:飞机,轮船(包括近海轮船和向海轮船)和油罐。所有图像总共标记了11k个独立边界框,包括4,724架飞机,3,025艘船和3,279个油罐。每个图像的平均目标数量为0.5。
Zou Z, Shi Z. Random access memories: A new paradigm for target detection in high resolution aerial remote sensing images[J]. IEEE Transactions on Image Processing, 2017, 27(3): 1100-1111.
数据下载地址:http://levir.buaa.edu.cn/Code.htm
链接: https://pan.baidu.com/s/1-eUAq2PszdHeE2VSG3q5cw 提取码: j9jp
4、DOTA

2806张遥感图像(大小约4000*4000),188,282个instances,分为15个类别:飞机、船只、储蓄罐、棒球场、网球场、篮球场、田径场、海港、桥、大型车辆、小型车辆、直升飞机、英式足球场、环形路线、游泳池。每个实例都由一个四边形边界框标注,顶点按顺时针顺序排列。
更新:DOTA-v1.5在16个类别中包含40万个带注释的对象实例,这是DOTA-v1.0的更新版本。 它们都使用相同的航拍图像,但是DOTA-v1.5修改并更新了对象的注释,其中在DOTA-v1.0中缺少了许多大约10个像素以下的小对象实例,并对其进行了附加注释。 DOTA-v1.5的类别也得到了扩展。 具体地,增加了集装箱起重机的类别。
Xia G S, Bai X, Ding J, et al. DOTA: A large-scale dataset for object detection in aerial images[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 3974-3983.
数据下载网页地址:https://captain-whu.github.io/DOTA/dataset.html>
链接: https://pan.baidu.com/s/1o4Tsx7hgh2a2O73kxJRVLg 提取码: yvi1
5、RSOD
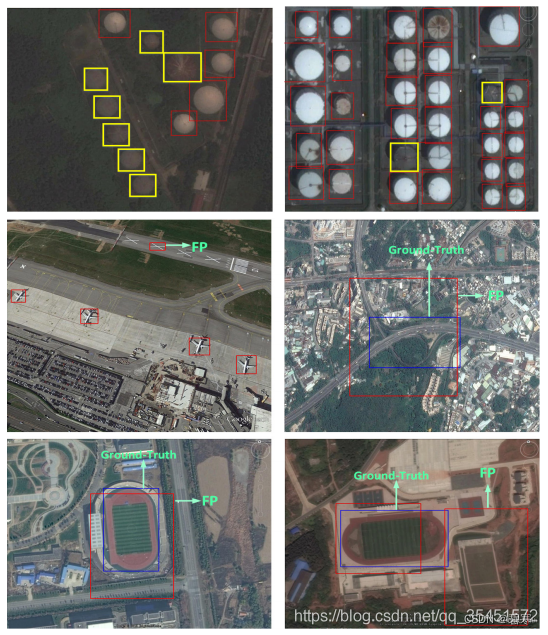 一个开放的目标检测数据集,用于遥感图像中的目标检测。数据集包含飞机,油箱,运动场和立交桥,以PASCAL VOC数据集的格式进行标注。
一个开放的目标检测数据集,用于遥感图像中的目标检测。数据集包含飞机,油箱,运动场和立交桥,以PASCAL VOC数据集的格式进行标注。
数据集包括4个文件夹,每个文件夹包含一种对象:
1.飞机数据集,446幅图像中的4993架飞机
2.操场,189副图像中的191个操场。
3.立交桥,176副图像中的180座立交桥。
4.油箱,165副图像中的1586个 油箱。
Li K, Wan G, Cheng G, et al. Object detection in optical remote sensing images: A survey and a new benchmark[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2020, 159: 296-307.
https://github.com/RSIA-LIESMARS-WHU/RSOD-Dataset-
6、UCAS-AOD
用于飞机和车辆检测。具体来说,飞机数据集包括600张图像和3210架飞机,而车辆数据集包括310张图像和2819辆车辆。所有的图像都经过精心挑选,使数据集中的物体方向分布均匀。
下载地址https://pan.baidu.com/s/1Poo0zEHTHDfBTnKPb5YTCg 提取码: 7zsi
7、NWPU VHR-10
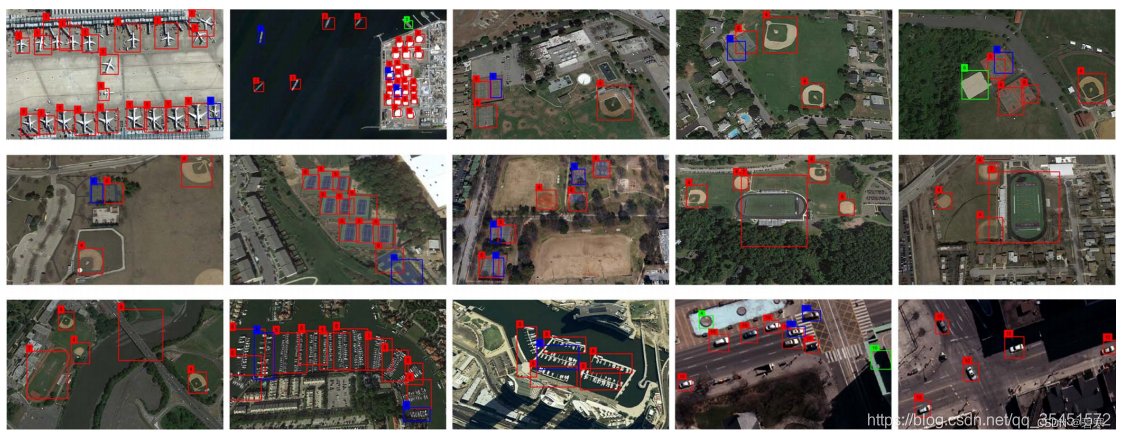
10个地理空间对象类,包括飞机、棒球场、篮球场、桥梁、港口、地面田径场、船舶、储罐、网球场和车辆。它由715幅RGB图像和85幅锐化彩色红外图像组成。其中715幅RGB图像采集自谷歌地球,空间分辨率从0.5m到2m不等。85幅经过pan‐锐化的红外图像,空间分辨率为0.08m,来自Vaihingen数据。该数据集共包含3775个对象实例,其中包括757架飞机、390个棒球方块、159个篮球场、124座桥梁、224个港口、163个田径场、302艘船、655个储罐、524个网球场和477辆汽车,这些对象实例都是用水平边框手工标注的。
Cheng G, Zhou P, Han J. Learning rotation-invariant convolutional neural networks for object detection in VHR optical remote sensing images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2016, 54(12): 7405-7415.
链接: https://pan.baidu.com/s/1YJXr1jlwgJVVX9hl8v93lw 提取码: jpuz
8、VEDAI
VEDAI数据集用于航空图像中的多类车辆检测。它包含3640个车辆实例,包括9个类别,包括船、车、露营车、飞机、接送车、拖拉机、卡车、货车和其他类别。该数据集共包含来自 犹他州AGRC 的1210张1024×1024的航空图像,空间分辨率12.5 cm。数据集中的图像采集于2012年春季,每张图像都有四个未压缩的彩色通道,包括三个RGB彩色通道和一个近红外通道。
Razakarivony S, Jurie F. Vehicle detection in aerial imagery: A small target detection benchmark[J]. Journal of Visual Communication and Image Representation, 2016, 34: 187-203.
下载地址:https://downloads.greyc.fr/vedai/
9、HRSC2016
用于舰船检测,含1070张图片 (Google Earth) 和2976个实例,使用旋转框标注。遥感舰船公开数据集所有图像均来自六个著名的港口。分辨率从2米到0.4米不等,图像大小从300300到1500900不等,大部分比1000*600大。含有3个级别任务(分别为单类class、4类category和19类type舰船检测识别)训练,验证和测试集分别包含436个图像(包括1207个样本),181个图像(包括541个样本)和444个图像(包括1228个样本)。
链接: https://pan.baidu.com/s/1Sz2aohknDVCYrnXcnPQuaQ 提取码: 7fx1
Liu Z, Yuan L, Weng L, et al. A high resolution optical satellite image dataset for ship recognition and some new baselines[C]//International conference on pattern recognition applications and methods. SciTePress, 2017, 2: 324-331.


















 5656
5656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











