






 本文介绍了如何使用SpaCy库进行英语文本处理,包括获取词语的基本形式(词干)、词性标签(POS)以及更详细的词性子类别(tag),展示了如何遍历文档并打印每个标记的相关信息。
本文介绍了如何使用SpaCy库进行英语文本处理,包括获取词语的基本形式(词干)、词性标签(POS)以及更详细的词性子类别(tag),展示了如何遍历文档并打印每个标记的相关信息。
spacy github链接:https://github.com/howl-anderson/Chinese_models_for_SpaCy
一、特性
doc="王小明在北京大学的清华大读书”
doc对象的属性如下:
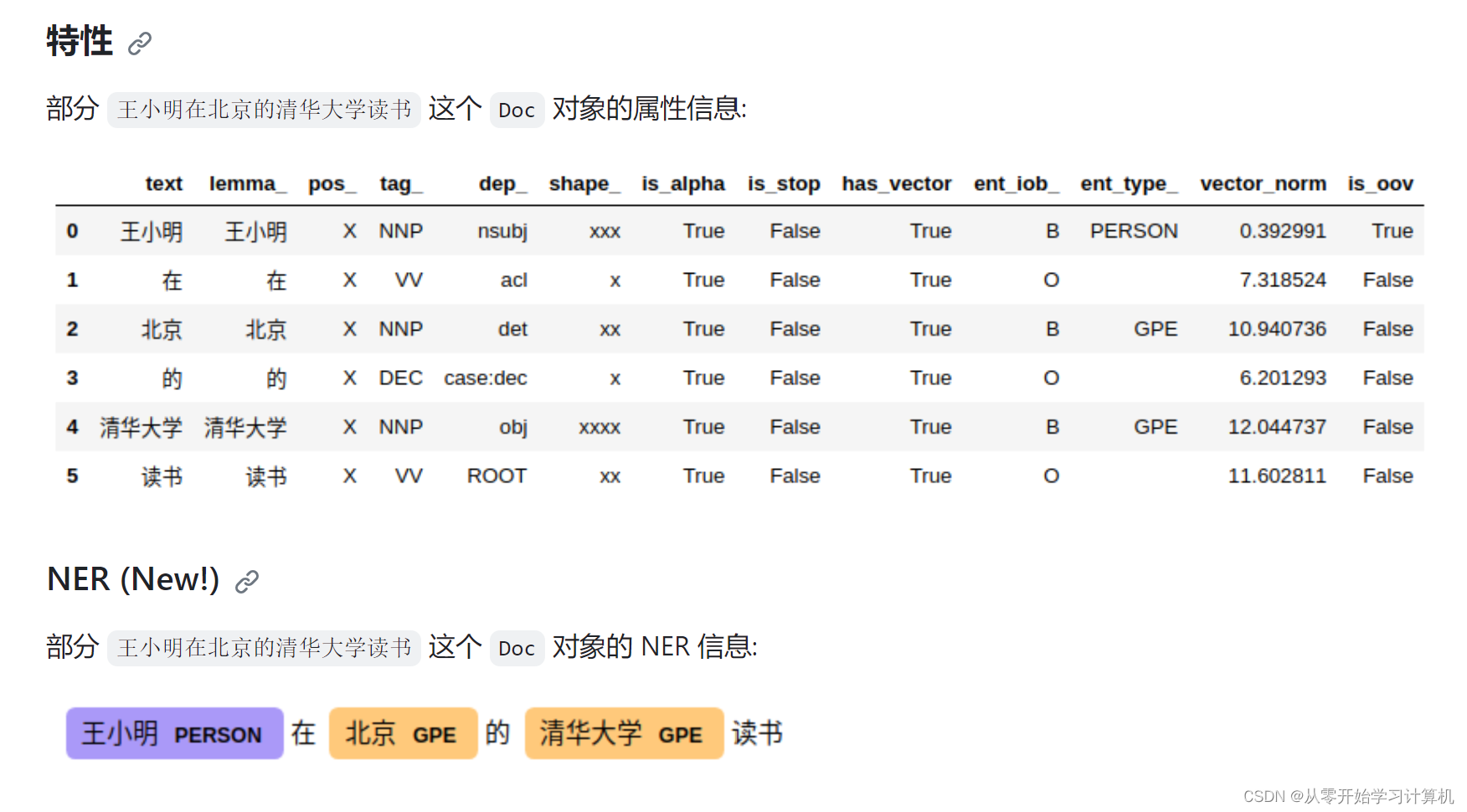
text属性:原始文本字符串
lemma_: 用于获取一个标记(token)的基本形式或词干形式。基本形式通常是一个单词的原始形式,不包含时态、语态等变化。例如,对于英语中的动词,基本形式通常是不定式形式,如 “walk” 的基本形式是 “walk”,而 “walked” 的基本形式仍然是 “walk”。
#代码运行前需要先安装spacy和对应的语言模型
# pip install spacy
# python -m spacy download en_core_web_sm
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("I walked to the park")
# 遍历文档中的每个标记并打印其基本形式
for token in doc:
print(token.text, token.lemma_)
# 输出结果:
# I I
# walked walk
# to to
# the the
# park park
pos_: ,用于获取特定词语的词性标签(Part of Speech,词性)的文本表示。这属性提供了一个字符串,表示与给定词语相关联的词性标签。
import spacy
# 加载 SpaCy 的英语模型
nlp = spacy.load("en_core_web_sm")
# 处理文本
doc = nlp("SpaCy is a popular natural language processing library.")
# 遍历文档中的词语并获取它们的词性标签
for token in doc:
print(token.text, token.pos_)
输出结果:

“PROPN” 表示专有名词
“AUX” 表示助动词
“ADJ” 表示形容词
“NOUN” 表示名词
“PUNCT” 表示标点符号
tag_: 用于获取特定词语的更详细的词性标签(Part of Speech,词性)的文本表示。这一属性提供了更具体的词性信息,包括词性子类别。tag_ 属性通常提供了比 pos_ 属性更详细的词性信息。
import spacy
# 加载 SpaCy 的英语模型
nlp = spacy.load("en_core_web_sm")
# 处理文本
doc = nlp("SpaCy is a popular natural language processing library.")
# 遍历文档中的词语并获取它们的词性标签
for token in doc:
print(token.text, token.tag_)
运行结果:
















 1035
1035











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









