







Spacy的安装与使用教程
1官网安装指导教程
1.1安装指令
需要根据自己系统的cuda版本选择
nvcc -V
pip install -U pip setuptools wheel
pip install -U 'spacy[cuda12x]'
python -m spacy download zh_core_web_sm #模型安装命令
python -m spacy download en_core_web_sm #模型安装命令
单独安装模型的命令,安装后可以直接nlp = spacy.load('model_name')
pip install spacy
python -m spacy download en_core_web_trf
2official tutorial
https://spacy.io/usage/spacy-101
#example
import spacy
from spacy.lang.en.examples import sentences
nlp = spacy.load("en_core_web_sm")
doc = nlp(sentences[0])
print(doc.text)
for token in doc:
print(token.text, token.pos_, token.dep_)
import spacy
nlp = spacy.load("en_core_web_sm")
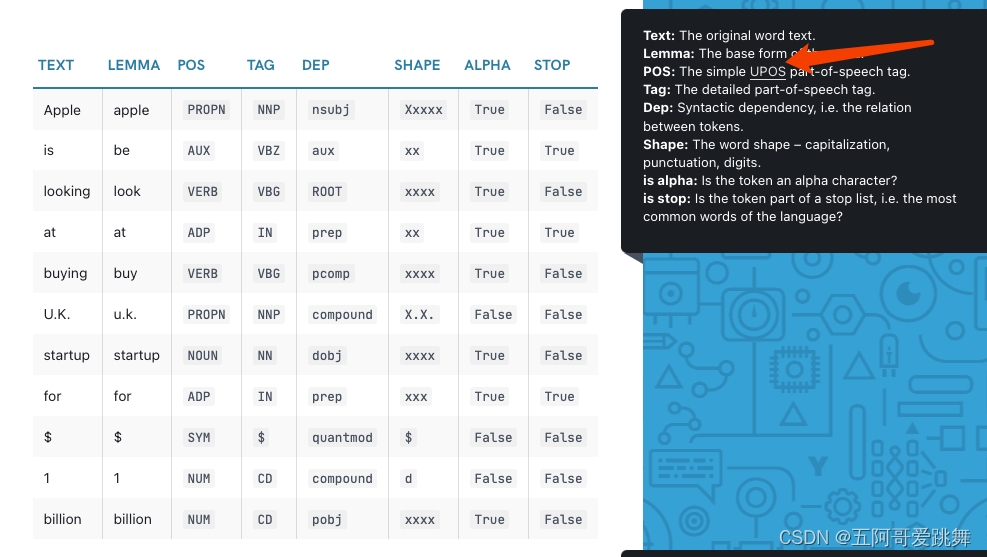
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
for token in doc:
print(token.text, token.lemma_, token.pos_, token.tag_, token.dep_,
token.shape_, token.is_alpha, token.is_stop)
Text: The original word text. #原始单词文本
Lemma: The base form of the word.#词目,单词的初始形态
POS: The simple UPOS part-of-speech tag. #简单的词性标签
Tag: The detailed part-of-speech tag. #详细的词性标签
Dep: Syntactic dependency, i.e. the relation between tokens. # 句法依赖
Shape: The word shape – capitalization, punctuation, digits. # 单词的形状(大写、标点和数字)
is alpha: Is the token an alpha character? # alpha字符
is stop: Is the token part of a stop list, i.e. the most common words of the language? # 停止列表的标记部分,即该语言中最常见的单词(这类单词通常无意义)
3 Spacy词性标签part-of-speech变量: token.tag_(en_core_web_sm中45个)和token.pos_
token.pos_
token.tag_ 提供了更详细和具体的词性标签,用于需要更精细区分的场景。
token.pos_ 提供了更广泛和简化的词性标签,用于需要大致分类的场景。UPOS
UPOS的详细label表:
https://universaldependencies.org/u/pos/
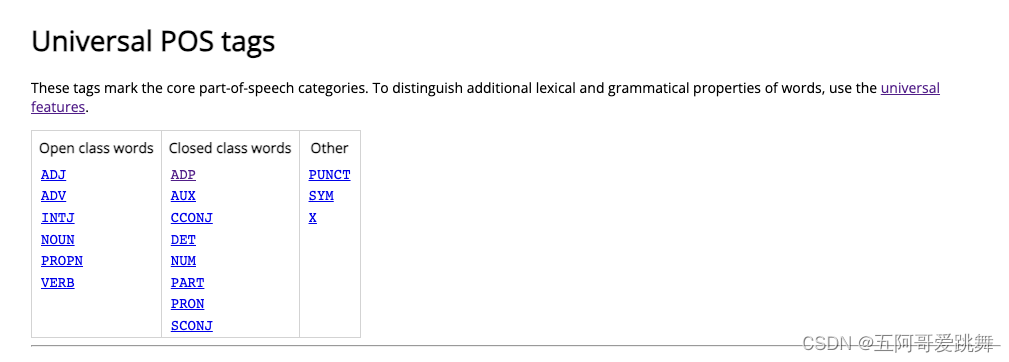
ADJ: adjective #形容词
ADP: adposition #介词
ADV: adverb #副词
AUX: auxiliary #助动词 has,is,will / was,got
CCONJ: coordinating conjunction # 并列连词
DET: determiner #限定词
INTJ: interjection #感叹词
NOUN: noun #名词
NUM: numeral #数词
PART: particle #' example: s / not 助词 (grammar)an adverb or a preposition that can combine with a verb to make a phrasal verb
#particle(语法)可以与动词结合构成动词短语的副词或介词
PRON: pronoun #代词
PROPN: proper noun #专有名词
PUNCT: punctuation #标点符号
SCONJ: subordinating conjunction #从属连词 that/if/while
SYM: symbol # 符号
VERB: verb #动词
X: other #其他
token.tag_
标签通常用在自然语言处理 (NLP) 和计算语言学领域,用于标识词在句子中的语法类别。
以下是每个token.tag_标签的含义:https://spacy.io/models/en#en_core_web_sm
$ - 货币符号
'' - 闭引号
,, - 闭逗号
-LRB- - 左圆括号 (left round bracket)
-RRB- - 右圆括号 (right round bracket)
. - 句号
: - 冒号
ADD - 电子邮件地址
AFX - 词缀
CC - 并列连词 (coordinating conjunction)
CD - 基数词 (cardinal digit)
DT - 限定词 (determiner)
EX - 存在词 (existential there)
FW - 外来词 (foreign word)
HYPH - 连字符 (hyphen)
IN - 介词或从属连词 (preposition or subordinating conjunction)
JJ - 形容词 (adjective)
JJR - 比较级形容词 (adjective, comparative)
JJS - 最高级形容词 (adjective, superlative)
LS - 列表项目标记 (list item marker)
MD - 情态动词 (modal verb)
NFP - 非打印字符 (non-final punctuation)
NN - 名词,单数或不可数 (noun, singular or mass)
NNP - 专有名词,单数 (proper noun, singular)
NNPS - 专有名词,复数 (proper noun, plural)
NNS - 名词,复数 (noun, plural)
PDT - 前置限定词 (predeterminer)
POS - 所有格标记 (possessive ending)
PRP - 人称代词 (personal pronoun)
PRP$ - 物主代词 (possessive pronoun)
RB - 副词 (adverb)
RBR - 比较级副词 (adverb, comparative)
RBS - 最高级副词 (adverb, superlative)
RP - 小品词 (particle)
SYM - 符号 (symbol)
TO - “to” (作为不定式标记)
UH - 感叹词 (interjection)
VB - 动词,原形 (verb, base form)
VBD - 动词,过去式 (verb, past tense)
VBG - 动词,动名词或现在分词 (verb, gerund or present participle)
VBN - 动词,过去分词 (verb, past participle)
VBP - 动词,非第三人称单数现在式 (verb, non-3rd person singular present)
VBZ - 动词,第三人称单数现在式 (verb, 3rd person singular present)
WDT - 疑问限定词 (wh-determiner)
WP - 疑问代词 (wh-pronoun)
WP$ - 物主疑问代词 (possessive wh-pronoun)
WRB - 疑问副词 (wh-adverb)
XX - 其他 (other)
_SP - 空格 (space)
`` - 开引号
4 taken.dep_ 句法依赖中token之间的依赖关系
en_core_web_sm中parser50个Token.dep_(20240521)
以下是每个token.dep_标签的含义
dep_类型https://spacy.io/models/en#en_core_web_sm
标准来源:https://universaldependencies.org/#language-
Universal Dependencies (UD) 通用依赖是一个为多种语言开发跨语言一致性树库注释的项目,目的是从语言类型学的角度促进多语言语法分析器的开发、跨语言学习和语法分析研究。
The annotation scheme is based on an evolution of (universal) Stanford dependencies (de Marneffe et al., 2006, 2008, 2014), Google universal part-of-speech tags (Petrov et al., 2012), and the Interset interlingua for morphosyntactic tagsets (Zeman, 2008).
注释方案基于(通用)斯坦福依赖关系(de Marneffe 等人,2006 年、2008 年、2014 年)、谷歌通用语音部分标签(Petrov 等人,2012 年)和形态句法标签集 Interset interlingua(泽曼,2008 年)的演变。
这些依赖关系标签(dependency relations)是用来描述句子中单词之间的语法和语义关系的。它们是依存句法分析的结果,广泛应用于自然语言处理(NLP)任务中。以下是这些依赖关系标签的含义,以及依据的主要参考文献:
常见依赖关系标签及其含义
ROOT: 根节点,通常是句子的主要谓语动词。
acl: 形容词性从句修饰词(adjectival clause),如"book that you read"中的"that you read"修饰"book"。
acomp: 表语形容词(adjectival complement),如"He is happy"中的"happy"。
advcl: 副词性从句修饰词(adverbial clause),如"I saw the movie because she recommended it"中的"because she recommended it"。
advmod: 副词修饰词(adverbial modifier),如"He runs quickly"中的"quickly"。
agent: 动作的施动者(agent),通常在被动句中,如"The ball was kicked by the boy"中的"by the boy"。
amod: 形容词修饰词(adjectival modifier),如"red apple"中的"red"。
appos: 同位语(appositional modifier),如"My friend, John"中的"John"。
attr: 属性(attribute),如"He is a teacher"中的"teacher"。
aux: 助动词(auxiliary),如"He is running"中的"is"。
auxpass: 被动助动词(passive auxiliary),如"The ball was kicked"中的"was"。
case: 标记名词短语的语法关系(case marker),如"to the store"中的"to"。
cc: 并列连词(coordinating conjunction),如"and", "or"。
ccomp: 补语从句(clausal complement),如"He says that he is happy"中的"that he is happy"。
compound: 复合词(compound),如"apple pie"中的"apple"。
conj: 并列连接(conjunct),如"apples and oranges"中的"oranges"。
csubj: 从句主语(clausal subject),如"What he said makes sense"中的"What he said"。
csubjpass: 被动从句主语(clausal passive subject),如"That he lied was suspected"中的"That he lied"。
dative: 与格(dative),如"He gave her a book"中的"her"。
dep: 一般依赖关系(unclassified dependent),用于无法归类的关系。
det: 限定词(determiner),如"the", "a", "an"。
dobj: 直接宾语(direct object),如"I read the book"中的"the book"。
expl: 形式主语(expletive),如"It is raining"中的"It"。
intj: 感叹词(interjection),如"Oh!", "Wow!"。
mark: 标记(marker),如"because", "if"。
meta: 元语(meta language),如文章中的引号或括号内的信息。
neg: 否定词(negation modifier),如"not", "never"。
nmod: 名词修饰词(noun modifier),如"the book on the table"中的"on the table"。
npadvmod: 名词短语副词修饰词(noun phrase as adverbial modifier),如"last week"中的"last week"。
nsubj: 名词主语(nominal subject),如"He runs"中的"He"。
nsubjpass: 被动名词主语(passive nominal subject),如"The ball was kicked by him"中的"The ball"。
nummod: 数量修饰词(number modifier),如"three apples"中的"three"。
oprd: 宾语补语(object predicate),如"She called him a hero"中的"a hero"。
parataxis: 并列结构(parataxis),如"I came, I saw, I conquered"。
pcomp: 介词补语(prepositional complement),如"He talked about leaving"中的"leaving"。
pobj: 介词宾语(object of a preposition),如"in the room"中的"the room"。
poss: 所有格(possessive),如"John's book"中的"John's"。
preconj: 前置连词(preconjunct),如"both", "neither"。
predet: 前置限定词(predeterminer),如"all the kids"中的"all"。
prep: 介词(prepositional modifier),如"on the table"中的"on"。
prt: 小品词(particle),如"look up"中的"up"。
punct: 标点符号(punctuation),如",", ".", "!"。
quantmod: 数量词修饰词(quantifier modifier),如"many people"中的"many"。
relcl: 关系从句修饰词(relative clause modifier),如"The book that I read"中的"that I read"。
xcomp: 补语从句(open clausal complement),如"He wants to eat"中的"to eat"。
spacy加载trf模型报错
解决方案:
pip install spacy_transformers
import spacy_transformers
主要重启一下环境,如果jupyter notebook中仍然报错的话。
https://stackoverflow.com/questions/69406767/cant-load-spacy-en-core-web-trf
spacy指代消解报错
coref_chains = doc._.coref_clusters
上述代码报错如下,
AttributeError: [E046] Can’t retrieve unregistered extension attribute ‘coref_clusters’. Did you forget to call the set_extension method?
这个错误是因为spaCy默认模型不包括指代消解功能。我们需要使用特定的库来扩展spaCy以支持指代消解。一个常用的选择是neuralcoref,它是一个为spaCy设计的神经网络指代消解扩展。
pip install spacy
pip install neuralcoref
解决失败,考虑是包版本不兼容的问题,因此重新创建环境安装neuralcoref。
conda create -n coreference python==3.8
conda activate coreference
git clone https://github.com/huggingface/neuralcoref.git
cd neuralcoref
pip install -r requirements.txt
pip uninstall neuralcoref

















 937
937

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









