







struc2vec[2017]:struc2vec:Learning Node Representations from Structural Identity
原理:如果两个节点的所有邻居组成的两个序列相似,那么这两个节点就比较相似。

构建网络:
原本只有一个网络(只有一层),现在我们要构造多层网络(即以原始网络为副本创建k层网络)

层与层之间,只有U(k)节点连接U(k+1),k表示第k层。(即只有节点与自己的上下层节点有连接)
借用这篇文章的话。https://zhuanlan.zhihu.com/p/65539782


g()函数是比较两个序列相似度的函数,可以是Dynamic Time Warping(动态时间规整算法),用来计算两个可能长度不等的序列的相似
有了这个概念我们就可以计算网络边的权重。

同层两个节点u,v的权重为(1.12)所示。
不同层之间u与u的上下层w如(1.13)所示。
其中:

![]() 度量了节点u与k层中其他节点的相似度。
度量了节点u与k层中其他节点的相似度。
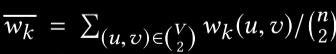
![]() 表示同层任意两个节点连边权重的平均值。
表示同层任意两个节点连边权重的平均值。
随机游走方法:
对于节点u,首先每一步有一个概率q在本层, 1-q跳出本层,如果在本层按照公式1.14采样下一个节点,如果跳出本层,按照公式1.15来选择上一层![]() 还是下一层
还是下一层![]() :
:
(概率q的取值:论文里没找到,可能是我没认真看)

其中:Zk(u)为规范化因子。
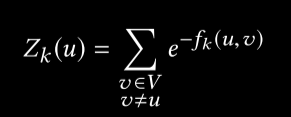
最后:随机游走后用skim-gram进行训练得到节点的向量表示(略)。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











