






基于python3.6—spyder,用knn实现鸢尾花iris数据集分类
先说iris数据集
鸢尾花数据集:iris数据集包含150个样本,包含三种鸢尾花的五种特征,每种鸢尾花50朵,共150朵,所以iris数据集是一个150行5列的二维表。
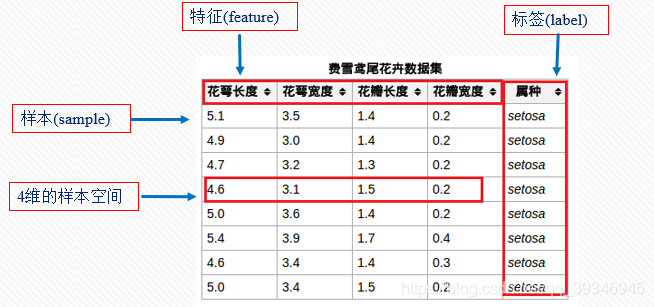
我下载的数据集是csv格式的,可以用excel打开,也可以用记事本打开,具体就长这样
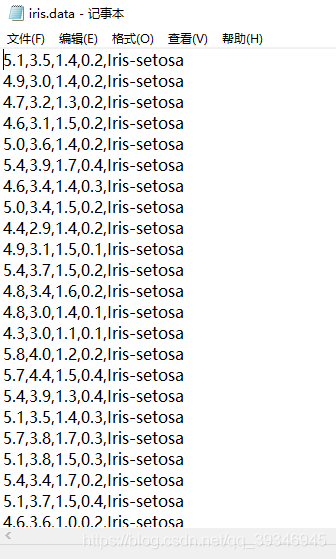
如果数据集不一样(比如每一列有抬头或者第一列多了个序号)则代码是不一样的(使用如下代码时可能会出错)
再说knn原理
当预测一个新的值x的时候,根据它距离最近的K个点是什么类别来判断x属于哪个类别。

KNN分类算法的步骤:
1.
计算待
分类点
与
已知类别
的点之间的距离
2.
按照
距离递增
次序排序
3.
选取与待分类点
距离最小
的
K
个点
4.
确定前
K
个点所在类别的出现
次数
5.
返回前
K
个点出现
次数最高的类别
作为该点的预测分类
(5.也可以加权平均)
•
在
训练
过程中,分类器获取训练数据并简单记忆
•
在
测试
过程中,
KNN
通过将每张测试图与所有训练图像做比较并给出
K
个最相似的训练样本的标签
•
KNN的主要决定因素:
K
值的选取;
点距离的计算
K值的选取
交叉验证:从选取一个较小的
K
值开始,
不断增加
K
的值
,然后计算验证集的
方差
,最终找到一个比较合适的
K
值。
k
较小,容易被噪声影响,发生过拟合。
k
较大,较远的训练实例也会对预测起作用,容易发生错误。
点距离的计算

终于轮到代码
数据集一定要和代码放在同一文件夹下并且命名为iris.csv
k=8;2/3是训练集,1/3是测试集
# -*- coding: utf-8 -*-
"""
Created on Thu Apr 22 09:36:17 2021
@author: QiMeng
"""
import random #定义的是包
import csv
#数据读取
with open("./iris.csv","r",encoding='utf-8') as file: #打开鸢尾花这个"Iris.csv"文件,“r”表示以读取的方式,“w”表示以写入的方式
reader = csv.DictReader(file) #DictReader表示以字典的形式读取这个文件
datas = [row for row in reader] #把这个文件每一行都存到data里
#数据分组 2/3是训练集,1/3是测试集
random.shuffle(datas) #先借用random包里的shuffle函数将数据全部打乱
n = len(datas)//3 #直接将数据分为三部分 /表示整除 /表示除结果可能是浮点型
test_set = datas[0:n] #0到n(不包括n个)是测试集
train_set = datas[n:] #从n开始daozuihou是训练集
#knn算法
#算距离(用的欧式距离)
def distance(d1,d2): #定义一个算d1-d2间距离的函数
res = 0 #定义一个和 需要一直相加的
for key in ("Sepal.Length","Sepal.Width","Petal.Length","Petal.Width"): #需要计算距离的列
res+= (float(d1[key])-float(d2[key]))**2 #计算欧氏距离
return res**0.5 #计算欧氏距离(最后的开方)
k=8
def knn(data):
#求所有距离
res = [
{"result":train["Species"],"distance":distance(data,train)}
#"Species"表示训练的结果应该是种类,distance(data,train) 表示用定义的distance函数计算出data与训练项之间的距离
for train in train_set #将训练集中所有的训练项循环一遍
]
#2距离排序(升序)
res = sorted(res,key=lambda item:item["distance"]) #以distance的大小作为排序
#3取前k个
res2=res[0:k] #在res中取0-k,(共k个数)
# print(res2)
#4加权平均 离的近的权重高,远的权重低
result={"versicolor":0,"setosa":0,"virginica":0} #三类的权重都是0
#算总距离
sum=0
for r in res2: #res2里的元素循环一边并且相加
sum+=r["distance"]
for r in res2:
result[r["result"]]+=1-r["distance"]/sum #因为距离近的权重反而高,所以要用1-权重(权重本身和1)
# print(result)
# print(data["Species"])
if result["versicolor"]>result["setosa"]:
if result["versicolor"]>result["virginica"]:
return "versicolor"
else:
return "virginica"
else:
return "setosa"
#测试阶段
correct = 0
for test in test_set: #将测试集中的测试项都取出来
result=test["Species"] #真实结果
result2=knn(test) #预测结果
if result==result2:
correct+=1
# print(correct)
# print(len(test_set
print("准确率:",format(100*correct/len(test_set))) #最后显示一下
运行一下

每一次的结果都不一样是因为我代码中最开始就将数据随机打乱在进行分组的
![]()














 4290
4290











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









