






论文地址:https://arxiv.org/abs/2010.11929
TensorFlow代码:https://github.com/google-research/vision_transformer
Pytorch代码:https://github.com/lucidrains/vit-pytorch
————————————————
论文完整翻译:https://blog.csdn.net/qq_16137569/article/details/120689000
论文逐句讲解视频:https://www.bilibili.com/video/av892100567/?zw&vd_source=949ef635a39b058bf989a789466416d4 (这个很推荐,比看逐句翻译有用。沐神团队下朱毅博士讲解的)
对应以上视频的详细笔记:https://blog.csdn.net/cg129054036/article/details/121644780
————————————————
下面是我认为的本文需要重点阅读的部分:
摘要:原文摘要写的很简洁,只有4句话:
尽管 Transformer 已经成为自然语言处理任务事实上的一种标准,但是在计算机视觉上的应用还是非常有限。
在计算机视觉领域,注意力机制要么和卷积神经网络一起使用,要么在保持原有网络结构不变的情况下替换局部的卷积运算(例如 ResNet-50 中把其中每某一个残差块使用注意力机制替代)。
本文证明对卷积神经网络的依赖不是必要的,原始的 Transformer 可以直接应用在一系列小块图片上并在分类任务上可以取得很好的效果。
在大的数据集上预训练的模型迁移到中小型图片数据集上 (ImageNet, CIFAR-100, VTAB等),与目前最好的卷积神经网络相比,ViT 可以取得非常优秀的结果并且需要更少的训练资源。
总结:原文总结有两段;
第一段总结本文做的工作,图片处理成 patch 序列,然后使用 Transformer 去处理,取得了接近或超过卷积神经网络的结果,同时训练起来也更便宜。
第二段是未来展望:
一是和目标检测和分割结合起来,ICCV 2021 最佳论文 Swin Transformer 就证明了 Transformer 在检测和分割任务也能取得很好的效果;
另一个是自监督预训练,因为本文是有监督预训练,自监督和有监督预训练还存在着很大的差距,最近何恺明博士的新论文 MAE 就研究了这个问题;
最后是更大规模的 ViT,半年之后作者团队就提出了 ViT-G。
网络模型图:
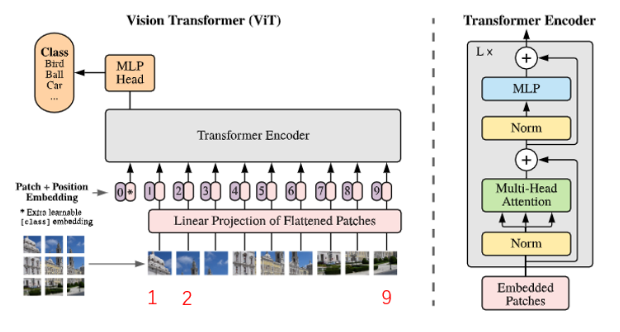
具体实现:假设图像大小是 224×224×3,划分成 16×16×3 的 patch, 则最终会有196个 patch。将每一个 patch 拉平,则每一个 patch 维度变为 768。线性投射层使用 E 表示,维度为 768 × 768 ( D ) D 是可调参数。则经过线性变换后输出为: X E = 196 × 768 × 768 × 768 = 196 × 768 ,输出为196个 token,每个 token 维度为768。因为还有一个 class token,位置编码维度为 1 × 768 ,和 patch embedding直接相加(sum),则最终输入维度为 197 × 768。
再和图联系起来,再走一遍流程:
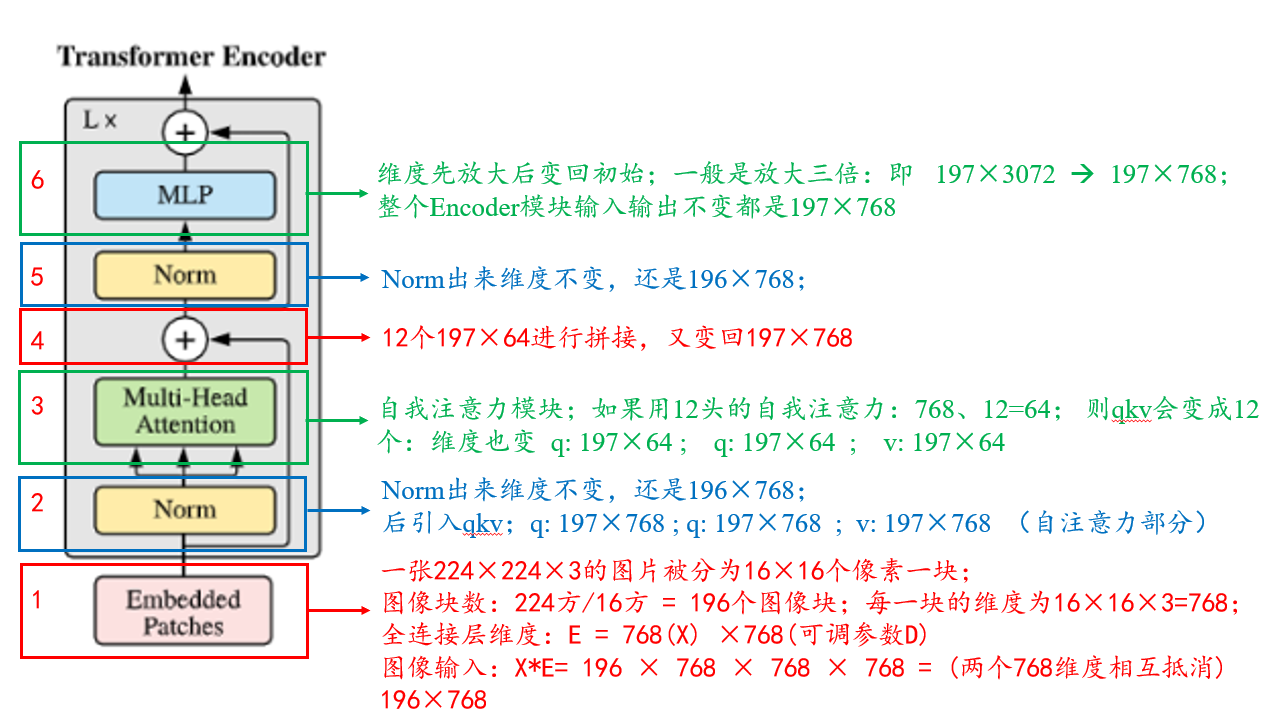
整个Encoder模块输入输出维度一致,都是197X 768
公式:
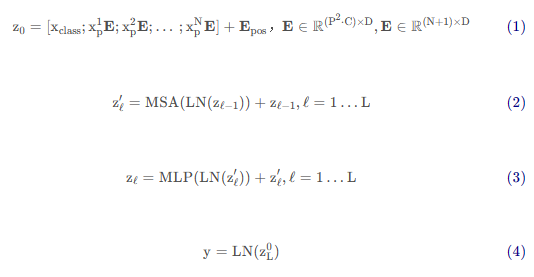
(1)z0:输入 x1p....xnp:图像块 E:全连接层 Epos:位置编码信息
(2.3)l = 1...L 循环
(2)MSA:多头自注意力 zl-1:残差连接 z'l:每个多头自注意力出来的结果
(1)MLP: z‘l: 残差连接 zl:每个transformer block 出来的结果
(4)y:输出 z0L:是输入的Xclass所对应的输出,也是最后被当作整体图像的一个特征进行分类任务
实验:
评估了ResNet、Vision Transformer(ViT)和混合结构的表达学习能力。为了理解每个模型的数据需求,在不同大小的数据集上进行了预训练。
将ViT和SOTA进行对比。
3. 进行了一个自监督的小实验,表明了自监督ViT在未来是具有潜力的。
数据集:(都很大,只做分类)
ILSVRC-2012 ImageNet(1000类别,1300万张图像);
ImageNet-21k(2.1万类别,1.4亿万张图像);
JFT(1.8万类别,30.3亿张图像)数据集。
模型变体:
基于BERT配置VIT,各种大小的VIT(base,large,huge),patch的大小P也是可调的,P越大,序列长度越小。P越小,长度越长,计算开销越大。

与SOTA比:
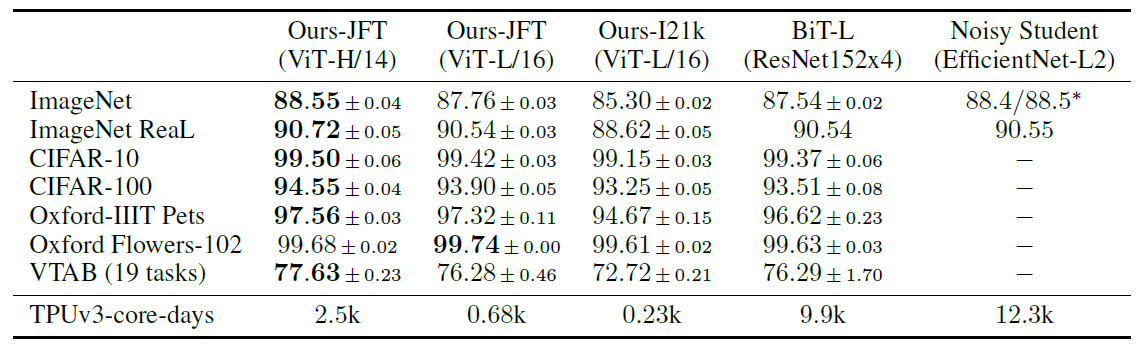
BiT-L Noisy和Student属于卷积神经网络。
其他消融:
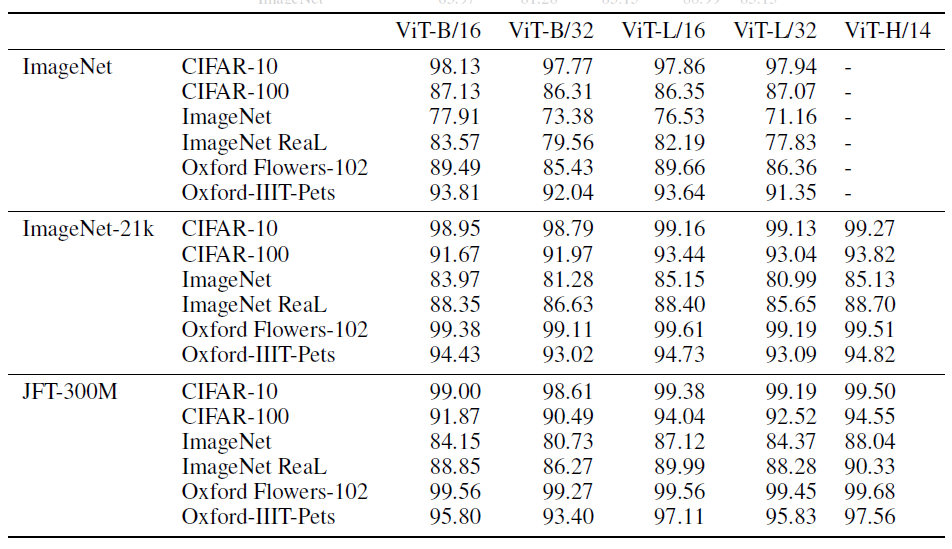
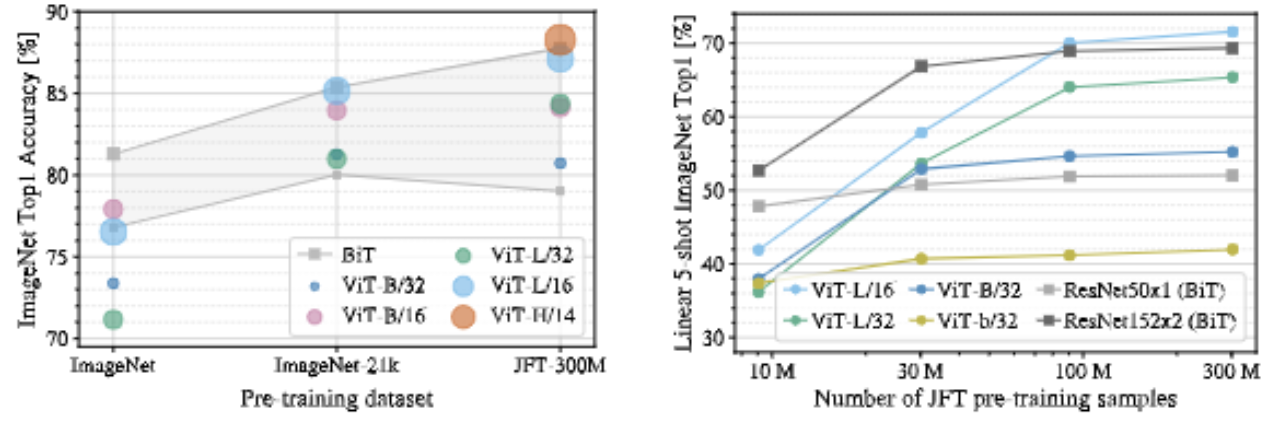
该图证明了transformer在中小型数据集上效果并不如卷积神经网络,因为transformer没有用先验知识,归纳偏置等,故需要更多的数据去学习。
模型编码方式作者消融了:1D、2D、相关编码。发现结果差别不大,给出的理由是被切割后得到的各个patch之间的关系非常更容易找到,只要略给提示即可。
模型命名方式:
VIT-L/16: 使用Large模型;patch size使用16×16;
transformer的序列长度跟patchr size成反比。patchr size越小,切的块越多,所以patchr size越小,模型计算量更大。















 3057
3057











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









