







Feature Selection

Class Distributions

熵(Entropy)
科学技术上用来描述、表征系统不确定程度的函数。
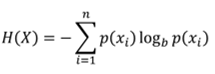




特征选择方法之信息增益(Information Gain)
设计分类系统的时候,一个很重要的环节便是特征选择,面对成千上万上百万的特征,如何选取有利于分类的特征呢?信息增益(Information Gain)法就是其中一种简单高效的做法。
几种常用的特征选择方法
特征选择主要有两个功能:1.减少特征数量、降维,使模型泛化能力更强,减少过拟合
2.增强对特征和特征值之间的理解
特征选择和降维
1、相同点和不同点:特征选择和降维有着些许的相似点,这两者达到的效果是一样的,就是试图去减少特征数据集中的属性(或者称为特征)的数目;但是两者所采用的方式方法却不同:降维的方法主要是通过属性间的关系,如组合不同的属性得新的属性,这样就改变了原来的特征空间;而特征选择的方法是从原始特征数据集中选择出子集,是一种包含的关系,没有更改原始的特征空间。
2、降维的主要方法:主成分分析(Principal Component Analysis) PCA
奇异值分解(Singular Value Decomposition) SVD
映射
特征选择的目标
提高预测的准确性
构造更快,消耗更低的预测模型
能够对模型有更好的理解和解释
特征选择的方法
1、Filter方法
其主要思想是:对每一维的特征“打分”,即给每一维的特征赋予权重,这样的权重就代表着该维特征的重要性,然后依据权重排序。主要的方法有:Chi-squared test(卡方检验)
information gain(信息增益)
correlation coefficient scores(相关系数)
2、Wrapper方法
其主要思想是:将子集的选择看作是一个搜索寻优问题,生成不同的组合,对组合进行评价,再与其他的组合进行比较。这样就将子集的选择看作是一个是一个优化问题,这里有很多的优化算法可以解决,尤其是一些启发式的优化算法,如GA,PSO,DE,ABC等主要方法有:recursive feature elimination algorithm(递归特征消除算法)
3、Embedded方法
其主要思想是:在模型既定的情况下学习出对提高模型准确性最好的属性。这句话并不是很好理解,其实是讲在确定模型的过程中,挑选出那些对模型的训练有重要意义的属性。主要方法:正则化,岭回归就是在基本线性回归的过程中加入了正则项。















 1098
1098











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









