









很多场景下,会看到AUPRC与平均查准率的混用,即一般情况下,默认二者相同,即AUPRC = average precision
但实际上,二者是不同的, average precision只是AUPRC值的近似。注意python (sklean)和R都采用了这个方式
计算AUPRC
# Compute Precision-Recall and plot curve
precision, recall, thresholds = precision_recall_curve(y_test, clf.predict_proba(X_test)[:,1])
area = auc(recall, precision)
print "Area Under PR Curve(AP): %0.2f" % area #should be same as AP?
print 'AP', average_precision_score(y_test, y_pred, average='weighted')
print 'AP', average_precision_score(y_test, y_pred, average='macro')
print 'AP', average_precision_score(y_test, y_pred, average='micro')
print 'AP', average_precision_score(y_test, y_pred, average='samples')二者实际输出
Area Under PR Curve(AP): 0.65
AP 0.676101781304
AP 0.676101781304
AP 0.676101781304
AP 0.676101781304
小结,实际还是默认二者相等,但自己要知道它们是不等价的。
进一步思考
这里的讨论比较详细,笔者参考了这里,https://stats.stackexchange.com/questions/157012/area-under-precision-recall-curve-auc-of-pr-curve-and-average-precision-ap
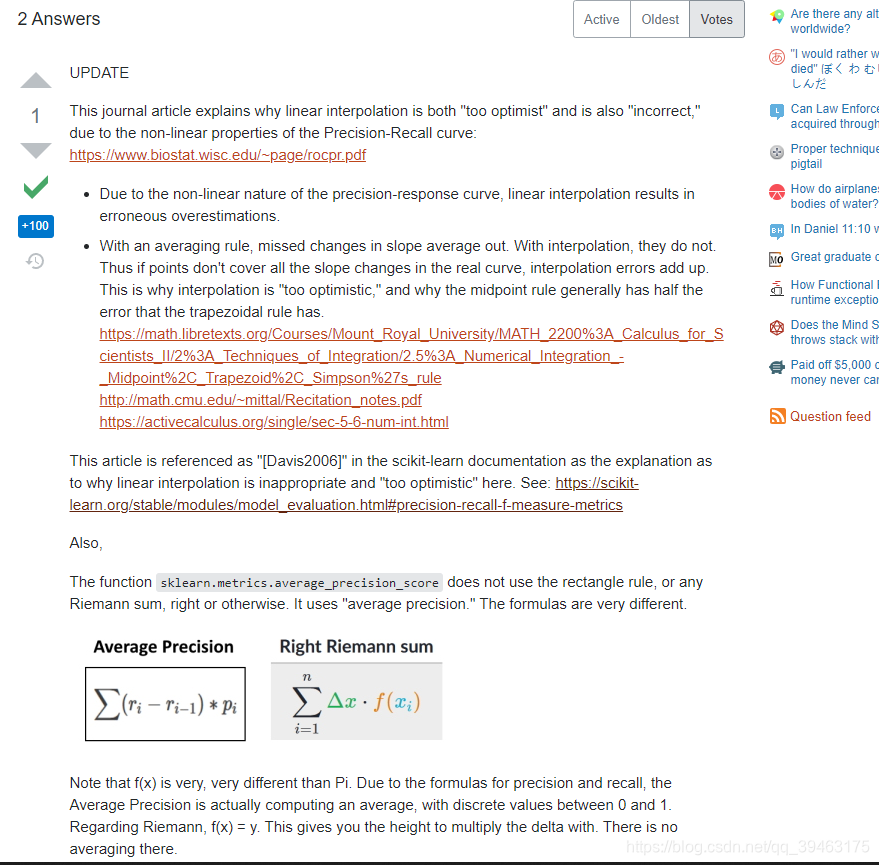
笔者认为第2个讨论更适合,具体个人见简如下:
上述代码的求AUPRC属于Riemann sum原则,即黎曼和。笔者后续又重新看了黎曼和的定义,发现Riemann sum用于连续的曲线,所以会导致过估计。
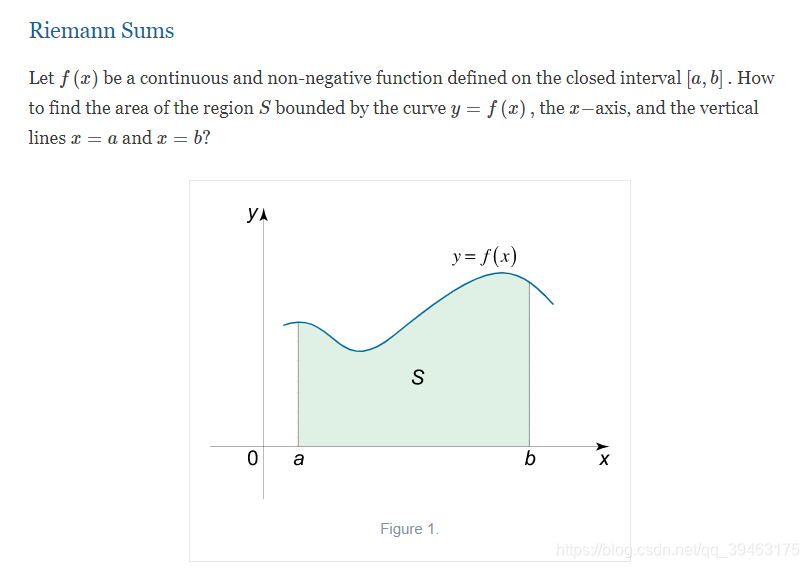
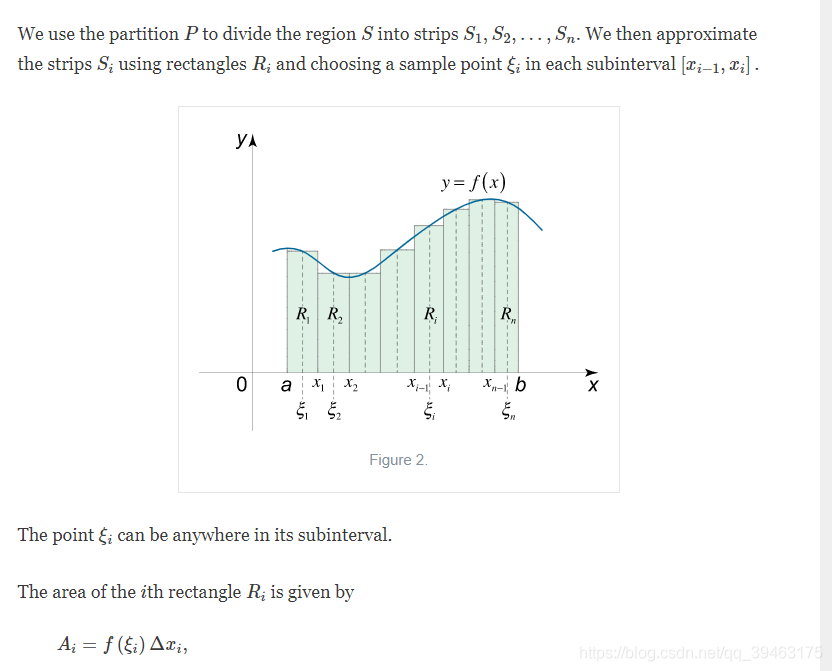
试想一下,真正的AUPRC会是连续的曲线吗,在回顾Precicion和Recall会发现,它们都是离散的点。笔者认为,只要当类别数为无穷时,AUPRC才可能逼近连续的曲线,才适合用Riemann sum或者插值做。
在现实的应用中,类别数是很有限的,因此,真正的AUPRC是分段的函数(non-linear nature ),故不能用Riemann sum. 用平均查准率比较适合。
- Due to the non-linear nature of the precision-response curve, linear interpolation results in erroneous overestimations.
- With an averaging rule, missed changes in slope average out. With interpolation, they do not. Thus if points don't cover all the slope changes in the real curve, interpolation errors add up. This is why interpolation is "too optimistic," and why the midpoint rule generally has half the error that the trapezoidal rule has.

















 4772
4772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









