







双指针算法:大致有下面两类
类似归并排序
类似快速排序:

核心思想:

示例: adc def ghi 将这个字符串, 以空格分开,并每个字符串占一行
#include <iostream>
#include <string>
using namespace std;
int main()
{
string a;
getline(cin,a);
cout<< a << a.size() << endl;
for(int i =0 ; i < a.size() ; i ++)
{
int j = i; // 必须这样
while( j < a.size() && a[j] != ' ') j ++;
for(int k = i; k < j; k ++) cout << a[k] ;
cout << endl;
i = j; // 跳出空格
}
return 0;
}
给定一个长度为 n 的整数序列,请找出最长的不包含重复的数的连续区间,输出它的长度。
输入格式
第一行包含整数 n。
第二行包含 n 个整数(均在 0∼105 范围内),表示整数序列。
输出格式
共一行,包含一个整数,表示最长的不包含重复的数的连续区间的长度。
数据范围
1≤n≤105
输入样例:
5
1 2 2 3 5
输出样例:
3
思路: 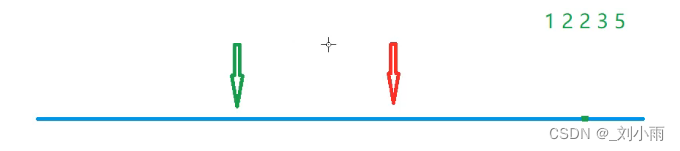
用双指针, 移动右边指针, 然后求左边指针在左边的最左的位置。(左边指针只能往右移动)
左指针: 往左最远能到什么地方
朴素做法O(n^2)
for(int i =0; i < n; i ++)
for(int j =0; j <= i; j ++)
if(check(j, i))
re = max(res, i- j + 1);
优化之后O(n)
for(int i =0; i < n; i ++)
while(j <= i && check(j, i)) j ++;
re = max(re, i - j + 1);
思路:
- 向后移动快指针
- 开始统计移动快指针指向的数据,是否出现重复,如果有重复,开始移动慢指针,直到没有重复的数据,并统计最长长度。
- 依次计算,直到快指针移动到结尾。
code:
#include <iostream>
using namespace std;
const int N = 1e6 + 10;
int n;
int a[N], s[N]; // a表示原数组, s表示数组出现次数
int main()
{
cin >> n;
for(int i = 0; i <n ;i ++) cin >> a[i];
int re = 0;
for(int i = 0, j = 0; i < n; i ++)
{
s[a[i]] ++; // 从前面统计a[i] 出现的次数
while(s[a[i]] > 1) // 如果出现数据次数> 1, 开始移动j, 并统计最长次数
{
s[a[j]] --;
j ++;
}
re = max(re, i - j + 1);
}
cout << re << endl;
return 0;
}
















 590
590











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









