









在最新的Hadoop(2.7以上版本)中,我们在控制台已经找不到jobtracker和tasktracker模块了,这并不是说它们消失了,而是隐式的加入了YARN框架中去,具体的功能被整合和优化。然而,了解一下运行在其上的mapreduce方法的原理和特点,会对我们理解最新的Hadoop有很大帮助,同时也有助于我们理解这个高效的分布式并行框架。
大数据的存储和处理,就好比一个人的左右手,显得尤为重要。Hadoop比较适合解决大数据问题,很大程度上依赖其大数据存储系统,即HDFS和大数据处理系统,对于MapReduce,我们从几个问题来认识。
什么是MapReduce
Hadoop MapReduce是一个软件框架,基于该框架能够容易地编写应用程序,这些应用程序能够运行在由上千个商用机器组成的大集群上,并以一种可靠的,具有容错能力的方式并行地处理上TB级别的海量数据集。这个定义里面有着这些关键词,一是软件框架,二是并行处理,三是可靠且容错,四是大规模集群,五是海量数据集。因此,对于MapReduce,可以简洁地认为,它是一个软件框架,海量数据是它的“菜”,它在大规模集群上以一种可靠且容错的方式并行地“烹饪这道菜”。写到这里,作者由衷地感叹思想之伟大,分解之神奇,合并之巧妙。
比如期末考试完了,那考卷由不同的老师批改,完成后如果想知道全年级最高分,那么可以这么做:
- 1)各个老师根据自己批改过的所有试卷分数整理出来(map): =>(course,[score1,score2,...])
- 2)各个老师把最高分汇报给系主任(shuffle)
- 3)系主任统计最高分(reduce)=>(courese, highest_score)
当然,如果要多门课程混在一起,系主任工作量太大,于是副主任也上(相当于2个reduce),则老师在汇报最高分的时候,相同课程要汇报给同一个人(相同key传输给同一个reduce),例如数学英语汇报给主任,政治汇报给副主任。
MapReduce能做什么
MapReduce擅长处理大数据,它为什么具有这种能力呢?这可由MapReduce的设计思想发觉。MapReduce的思想就是“分而治之”。Mapper负责“分”,即把复杂的任务分解为若干个“简单的任务”来处理。“简单的任务”包含三层含义:一是数据或计算的规模相对原任务要大大缩小;二是就近计算原则,即任务会分配到存放着所需数据的节点上进行计算;三是这些小任务可以并行计算,彼此间几乎没有依赖关系。Reducer负责对map阶段的结果进行汇总。至于需要多少个Reducer,用户可以根据具体问题,通过在mapred-site.xml配置文件里设置参数mapred.reduce.tasks的值,缺省值为1。
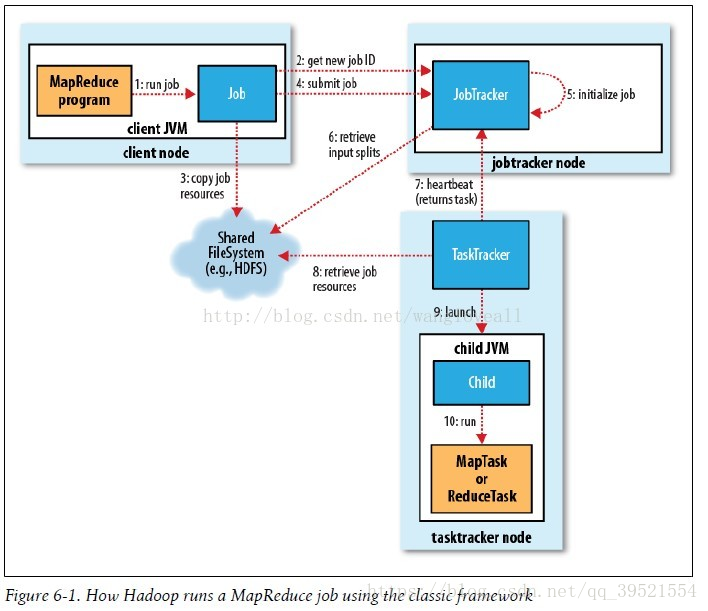
- 实体一:客户端,用来提交MapReduce作业。
- 实体二:jobtracker,用来协调作业的运行。
- 实体三:tasktracker,用来处理作业划分后的任务。
- 实体四:HDFS,用来在其它实体间共享作业文件。
通过审阅MapReduce工作流程图,可以看出MapReduce整个工作过程有序地包含如下工作环节。
- 环节一:作业的提交
- 环节二:作业的初始化
- 环节三:任务的分配
- 环节四:任务的执行
- 环节五:进程和状态的更新
- 环节六:作业的完成
关于每一个环节里具体做什么事情,可以参读《Hadoop权威指南》的第六章MapReduce工作机制的内容。对于用户来说,若是想使用MapReduce来处理大数据,就需要根据需求编写MapReduce应用程序。因而,如何利用MapReduce框架开发程序,是需要深入思考和不断实践的事情。
MapReduce有何特点
- MapReduce将复杂的、运行于大规模集群上的并行计算过程高度地抽象到了两个函数:Map和Reduce
- 编程容易,不需要掌握分布式并行编程细节,也可以很容易把自己的程序运行在分布式系统上,完成海量数据的计算
- MapReduce采用“分而治之”策略,一个存储在分布式文件系统中的大规模数据集,会被切分成许多独立的分片(split),这些分片可以被多个Map任务并行处理
- MapReduce设计的一个理念就是“计算向数据靠拢”,而不是“数据向计算靠拢”,因为,移动数据需要大量的网络传输开销
- MapReduce框架采用了Master/Slave架构,包括一个Master和若干个Slave。Master上运行JobTracker,Slave上 运行TaskTracker
- Hadoop框架是用Java实现的,但是,MapReduce应用程序则不一定要用Java来写
MapReduce如何工作
MapReduce是如何来处理大数据呢?用户可以通过编MapReduce应用程序来实现对大数据的操作。既然是用MapReduce程序处理大数据,那么MapReduce程序怎样工作呢?这就是第三个问题,即MapReduce的工作机制。
MapReduce主要有以下4个部分组成:
1)Client
- •用户编写的MapReduce程序通过Client提交到JobTracker端
- •用户可通过Client提供的一些接口查看作业运行状态
2)JobTracker
- •JobTracker负责资源监控和作业调度
- •JobTracker 监控所有TaskTracker与Job的健康状况,一旦发现失败,就将相应的任务转移到其他节点
- •JobTracker 会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器(TaskScheduler),而调度器会在资源出现空闲时,选择合适的任务去使用这些资源
3)TaskTracker
- •TaskTracker 会周期性地通过“心跳”将本节点上资源的使用情况和任务的运行进度汇报给JobTracker,同时接收JobTracker 发送过来的命令并执行相应的操作(如启动新任务、杀死任务等)
- •TaskTracker 使用“slot”等量划分本节点上的资源量(CPU、内存等)。一个Task 获取到一个slot 后才有机会运行,而Hadoop调度器的作用就是将各个TaskTracker上的空闲slot分配给Task使用。slot 分为Map slot 和Reduce slot 两种,分别供MapTask 和Reduce Task 使用
4)Task
Task 分为Map Task 和Reduce Task 两种,均由TaskTracker 启动
其中最核心的就是mapper和reducer这两个实现了具体功能的类,如下表所示
| 函数 | 输入 | 输出 | 说明 |
| Map | <k1,v1> 如: <行号,”a b c”> | List(<k2,v2>) 如: <“a”,1> <“b”,1> <“c”,1> | 1.将小数据集进一步解析成一批<key,value>对,输入Map函数中进行处理 2.每一个输入的<k1,v1>会输出一批<k2,v2>。<k2,v2>是计算的中间结果 |
| Reduce | <k2,List(v2)> 如:<“a”,<1,1,1>> | <k3,v3> <“a”,3> | 输入的中间结果<k2,List(v2)>中的List(v2)表示是一批属于同一个k2的value |
- MapTask并行度决定机制
maptask的并行度决定map阶段的任务处理并发度,进而影响到整个job的处理速度,一个job的map阶段并行度由客户端在提交job时决定,而客户端对map阶段并行度的规划的基本逻辑为:将待处理数据执行逻辑切片(即按照一个特定切片大小,将待处理数据划分成逻辑上的多个split),然后每一个split分配一个mapTask并行实例处理.
- ReduceTask并行度决定机制
reducetask的并行度同样影响整个job的执行并发度和执行效率,但与maptask的并发数由切片数决定不同,Reducetask数量的决定是可以直接手动设置。//默认值是1,手动设置为4
job.setNumReduceTasks(4);
如果数据分布不均匀,就有可能在reduce阶段产生数据倾斜,有些情况下,需要计算全局汇总结果,就只能有1个reducetask,尽量不要运行太多的reduce task。对大多数job来说,最好reduce的个数最多和集群中的reduce持平.
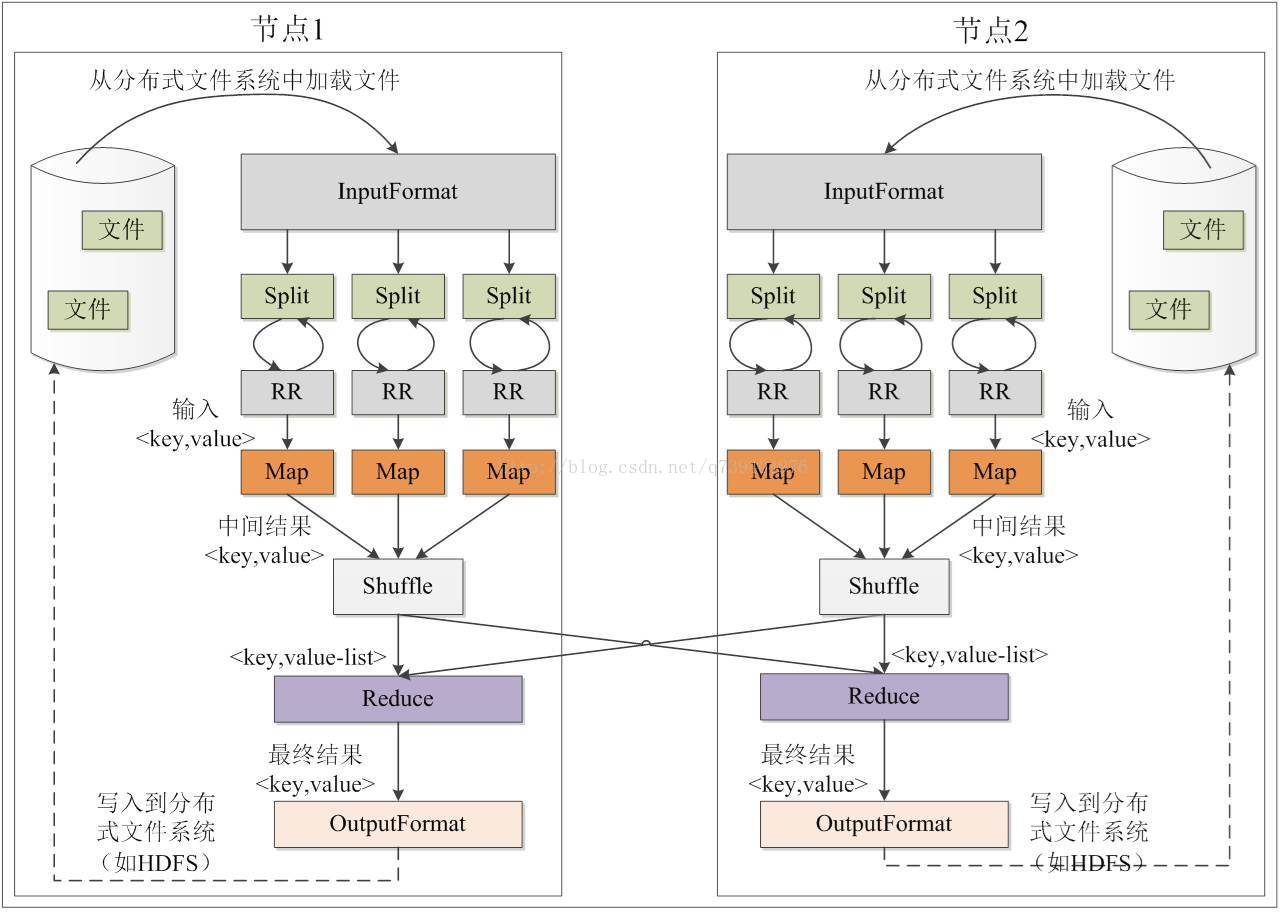
- Maperduce的shuffle机制
mapreduce中,map阶段处理的数据如何传递给reduce阶段,是mapreduce框架中最关键的一个流程,这个流程就叫shuffle。
具体来说:就是将maptask输出的处理结果数据,分发给reducetask,并在分发的过程中,对数据按key进行了分区和排序;
整体来看,分为3个操作:
- 分区partition
- Sort根据key排序
- Combiner进行局部value的合并
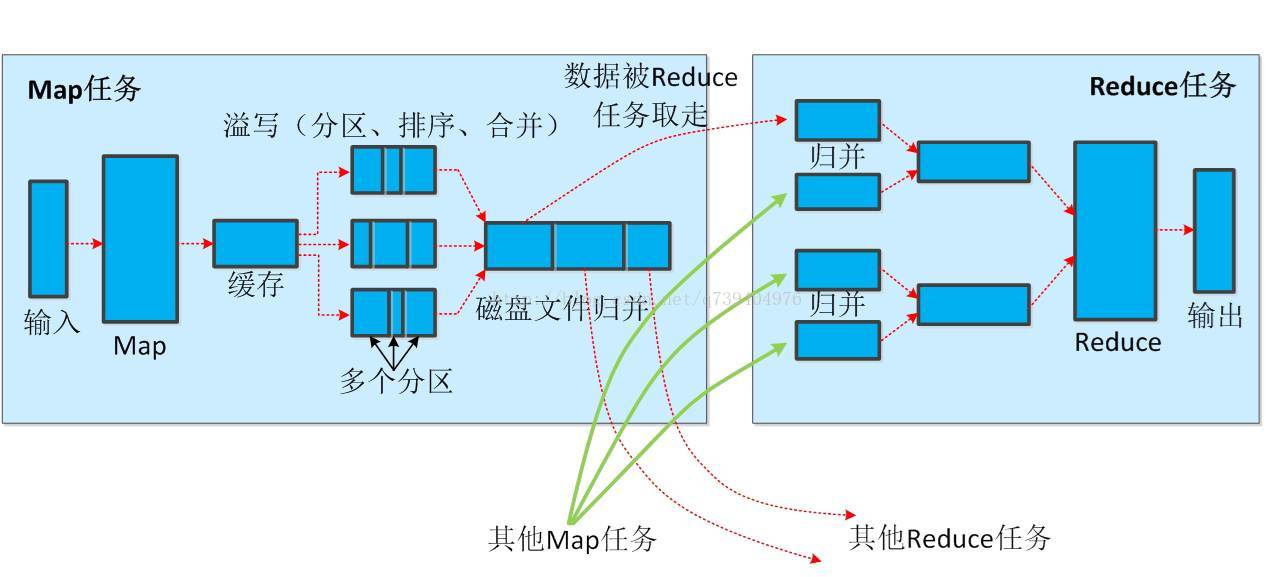
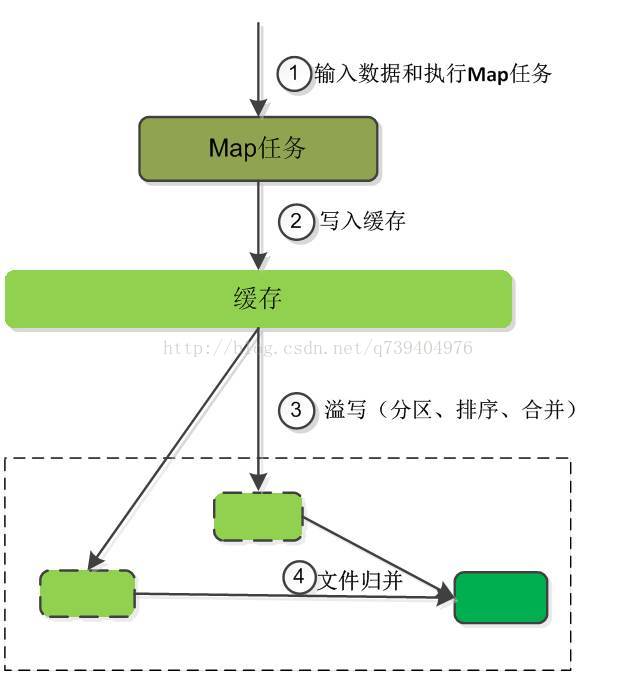
- •Reduce任务通过RPC向JobTracker询问Map任务是否已经完成,若完成,则领取数据
- •Reduce领取数据先放入缓存,来自不同Map机器,先归并,再合并,写入磁盘
- •多个溢写文件归并成一个或多个大文件,文件中的键值对是排序的
- •当数据很少时,不需要溢写到磁盘,直接在缓存中归并,然后输出给Reduce















 1547
1547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











