




声明
本笔记不收费,若误被系统设置vip或收费,可跳转博客园查看。链接:https://www.cnblogs.com/puwei-524/p/18958139
目录
说明
- 笔记为B站刘二大人的《PyTorch深度学习实践》课程笔记以及对应的代码。这里也列出一些其他大佬关于此课程的博客供读者参考学习:错错莫-PyTorch深度学习实践的代码、陈同学爱吃方便面-PyTorch学习系列的作业代码等也都非常棒!
- 本人初学者,能力有限,有些表达会有问题,欢迎留言或私信交流。
- 后续的课程目前理解不够,笔记较乱,暂时停更。
线性回归模型(第2讲)
- 做模型的几个主要步骤:准备数据集、选择模型、训练、推理。
背景
假设学生每周花费x小时学习,在期末考试中可以取得成绩y,那么对此,如果每周花费4小时,最终可以取得什么成绩?

其中,前三行给结果的数据为用于训练阶段,第四行没给结果的数据一般用于测试阶段或推理阶段。
将数据集交给算法,经过训练后,再给新的输入,能够得到相应的预测的结果,就是机器学习的过程。
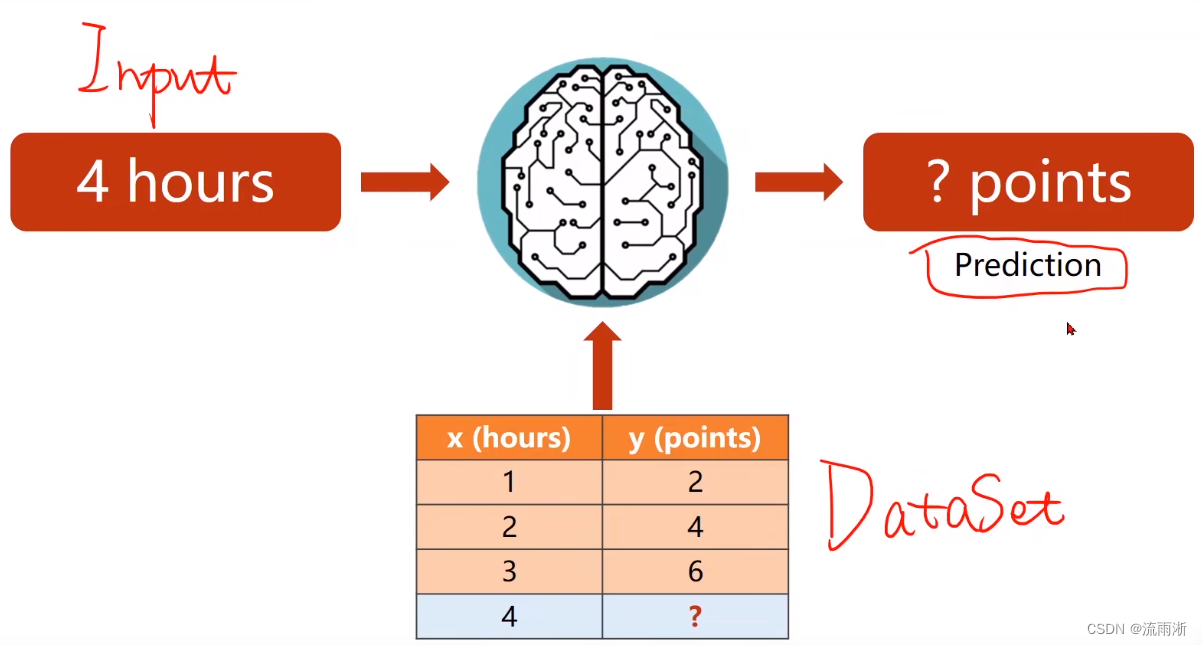
监督学习:训练时知道输入对应的输出,可以根据模型训练的值和对应值之间的差异对模型进行调整。测试集的数据不能偷看,用于判定模型是否有很好的泛化能力,用于评估模型的性能。
数据集:先分成两部分,一部分用于训练(训练集:能看到x和y),另一部分用于训练好之后测试(测试集:只能看到x)模型的性能。
过拟合:训练时在训练集误差很小,但把噪声也学进来了,这个是我们不想要的。 我们希望我们的模型有较好的泛化能力,即通过训练集的训练,对于没见过的图片也具有较好的识别的能力。对此,我们通常会将训练集分为两份,一份进行训练(训练集),另一份进行模型的评估(开发集)。
线性模型
选择模型:寻找
y
=
f
(
x
)
y = f(x)
y=f(x) 来满足所给数据。
线性模型:
y
^
=
x
∗
ω
+
b
\hat{y}=x*\omega+b
y^=x∗ω+b,简化的线性模型:
y
^
=
x
∗
ω
\hat{y}=x*\omega
y^=x∗ω。
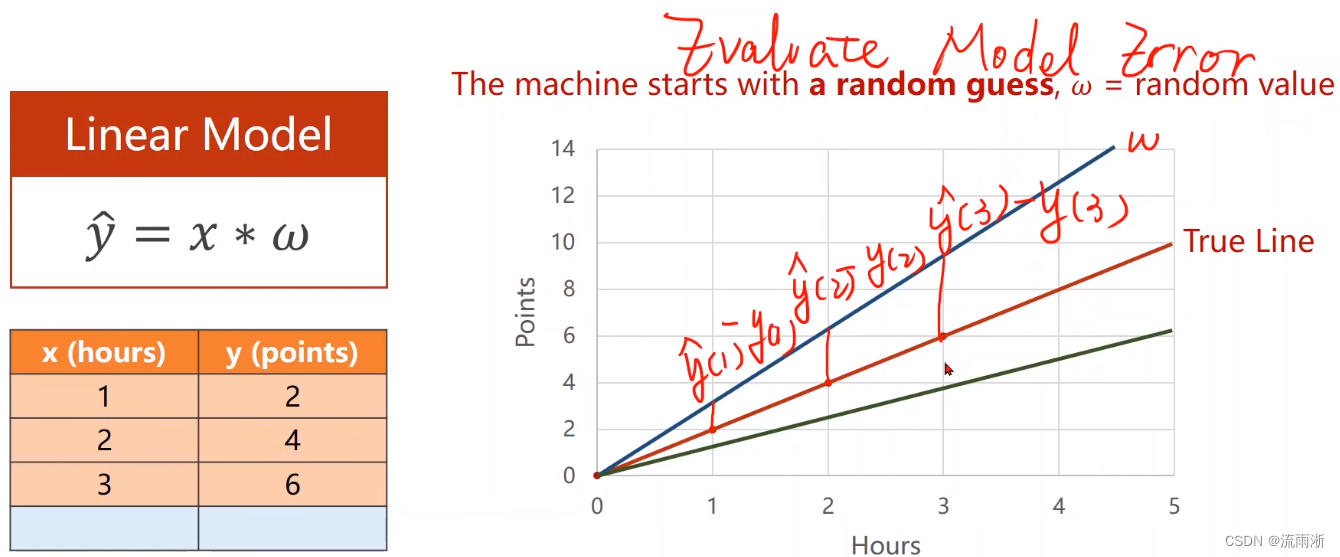
这里我们需要解决的是权重
ω
\omega
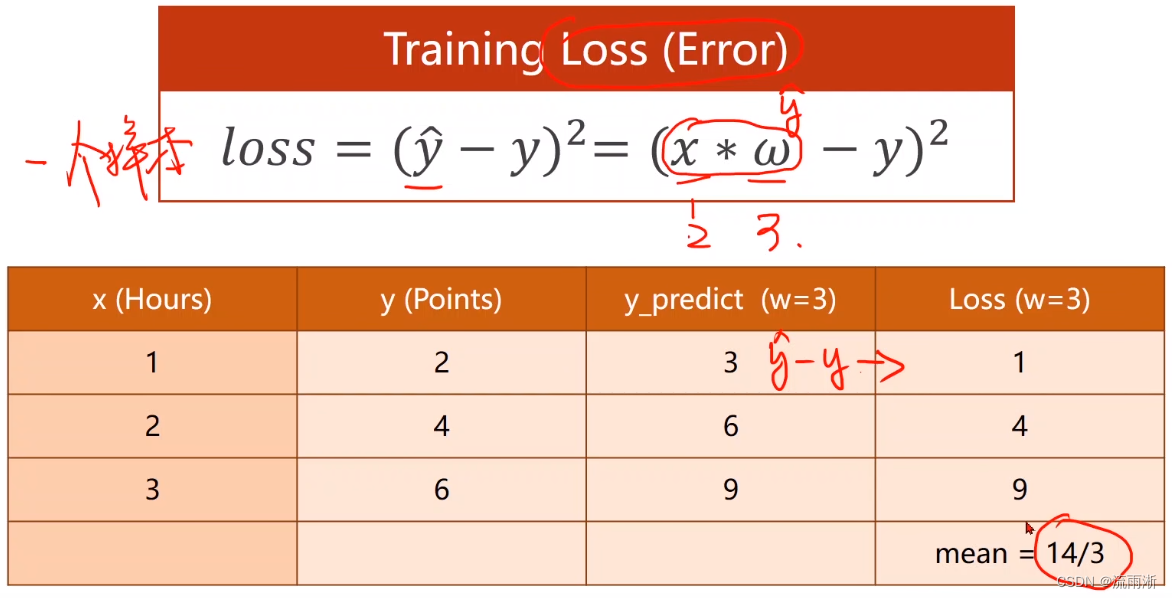
ω的问题,一般在开始会采用随机猜测,取一个随机数。当取得一个权重后,需要计算这个模型的取值与真实取值之间的误差。若采用的模型与真实值的误差为零,则选取的模型可以看作是数据真实的分布(理想情况下,一般很少会有误差为0)。计算误差的评估模型可以称为损失。
训练的目标任务:找一个最好的
ω
\omega
ω值,想法让平均损失降到最低。
损失函数(Loss Function) 是针对一个样本,代价函数(Cost Function,平均损失) 有时也被称为目标函数(Objective Function),是在整个训练集上评估模型性能的标准。

确定好目标函数后,可以根据数据集里面的所有数据,根据不同的权重计算平均损失是多少。
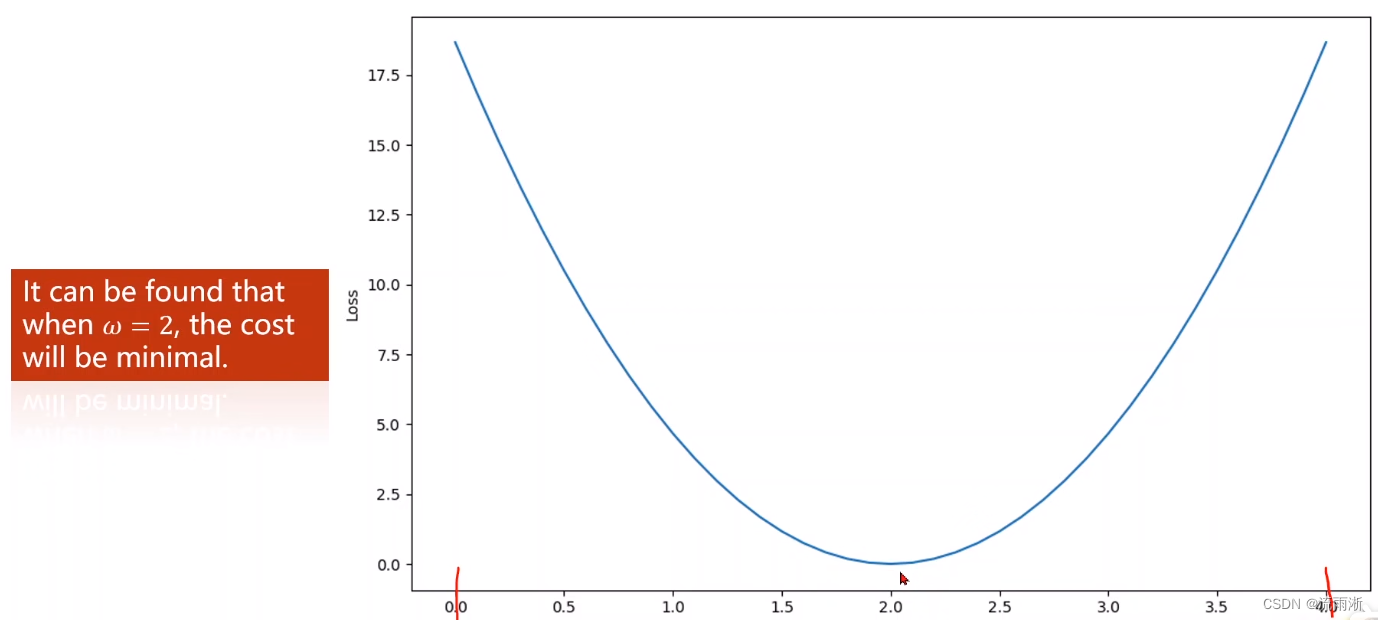
对比过后选取的
ω
\omega
ω值不一定是真实的最小值,采用穷举法,把所有的可能的值都例举出来,绘制曲线,可以观察出最有的权重
ω
\omega
ω应该取什么样的值。
线性回归代码
import numpy as np
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
# 模型:前馈
def forward(x):
return x * w
# 损失函数
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) * (y_pred - y)
w_list = [] #保存权重w
mse_list = [] #保存每个w的mse
for w in np.arange(0.0, 4.1, 0.1): #生成从0.0-4.0,间隔为0.1的序列
print("w=", w)
l_sum = 0
for x_val, y_val in zip(x_data, y_data): # zip函数将x_data和y_data各取一个元素组成元组
y_pred_val = forward(x_val)
loss_val = loss(x_val, y_val)
l_sum += loss_val
print('\t', x_val, y_val, y_pred_val, loss_val) #此处打印的是求和而不是均值
print('MSE=', l_sum / 3)
w_list.append(w)
mse_list.append(l_sum / 3)
plt.plot(w_list, mse_list)
plt.ylabel('Loss')
plt.xlabel('w')
plt.show()
结果如下:
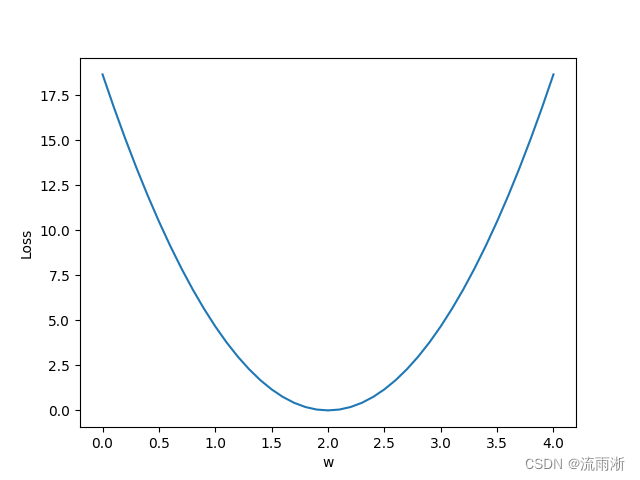
- 注意:在深度学习中图形的可视化很重要,如visdom。
- 定期打印存盘,减少跑代码过程中断点带来的数据丢失问题,避免跑代码时间白白浪费。
作业
- 采用线性模型 y ^ = x ∗ ω + b \hat{y}=x*\omega+b y^=x∗ω+b来绘制损失值图形。
import numpy as np
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
# 定义模型
def forward(x):
return x * w + b
# 定义损失函数
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
# 生成参数网格
w_list = np.arange(0.0, 4.1, 0.1)
b_list = np.arange(-2.0, 2.1, 0.1)
w, b = np.meshgrid(w_list, b_list) # w, b表示网格上的坐标
# 初始化损失矩阵
l_sum = 0
# 计算每个点的总损失
for x_val, y_val in zip(x_data, y_data):
y_pred_val = forward(x_val)
loss_val = loss(x_val, y_val)
l_sum += loss_val
print(f'x_val: {x_val}, y_val: {y_val}, y_pred_val: {y_pred_val}, loss_val: {loss_val}')
# 计算平均损失
l_avg = l_sum / 3
# 创建图形对象
fig = plt.figure()
# 创建 3D 轴对象
ax = fig.add_subplot(111, projection='3d')
# 绘制3D表面图
surface = ax.plot_surface(w, b, l_avg, cmap='viridis')
# 设置轴标签
ax.set_xlabel('w')
ax.set_ylabel('b')
ax.set_zlabel('Cost')
# 显示图形
plt.show()
结果如下图:
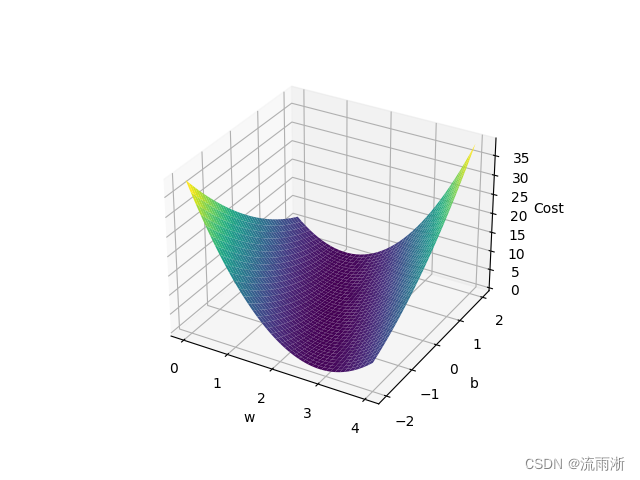
梯度下降算法(第3讲)
背景
在第2讲中,提到了做模型的主要步骤:准备数据集、选择模型、训练、推理。其中,数据集是给定的,选择的模型是线性模型,在训练的过程中采用的方法是穷举法,训练的目标任务就是找到一个最好的
ω
\omega
ω值,想法让平均损失降到最低。这种寻找一个最优值,使得目标函数最小的问题,我们称之为优化问题(Optimization Problem)。
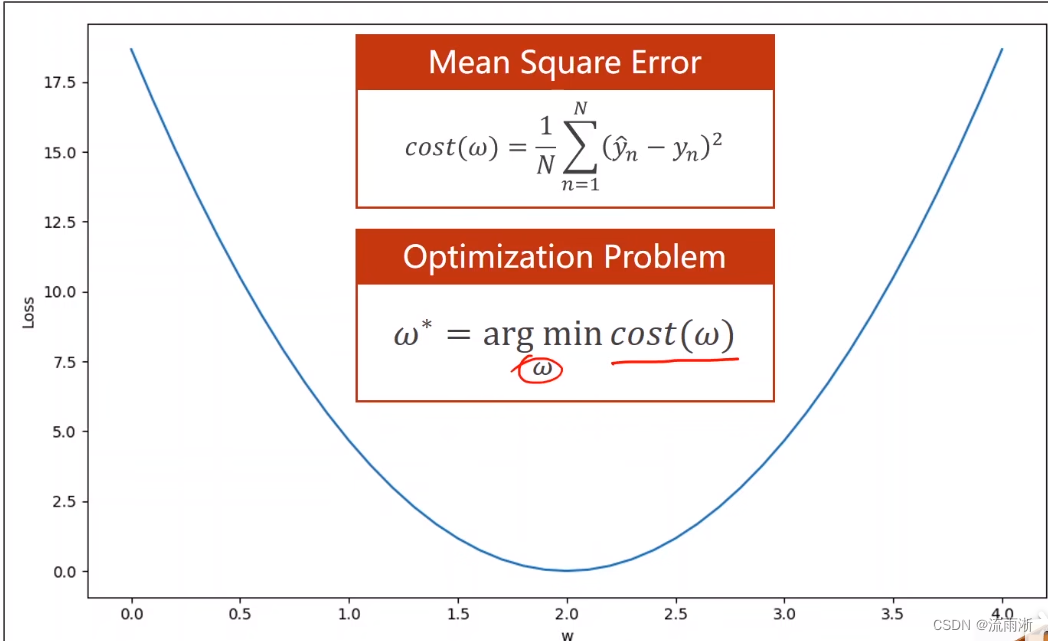
采用穷举法来解决这样一个优化问题,对于权重较少来搜索时搜索量还不明显。但是,当具有多个权重搜索多维的数据时,面对这个搜索量,这个程序就很难算出来了。这时就可以考虑分治法的思想,即将区域分为多个小区间,在不同的区间内找最优区间和最优点。但当权重数量过多或损失函数为非常不规则的曲线或曲面,那么在搜索的过程中会错过最优点。
原理
对于只含有一个权重的损失函数
c
o
s
t
=
f
(
ω
)
cost=f(\omega)
cost=f(ω),随机选择一个初始的
ω
\omega
ω值,通过对该点求梯度(一元函数就是求导),若不为零,说明有比该点更大的或者更小的值存在。梯度大于零,说明往
ω
\omega
ω轴正方向是变大的,如果要求
c
o
s
t
cost
cost最小值,就需要减小
ω
\omega
ω;同理,梯度小于零,说明往
ω
\omega
ω轴负方向是变大的,如果要求
c
o
s
t
cost
cost最小值,就需要增大
ω
\omega
ω。梯度的正方向是上升的,是使得函数最快上升的方向,相反,梯度的负方向是下降的,是使得函数最快下降的方向。因此将这种通过求梯度,并沿着梯度负方向使得函数值不断下降的方法成为梯度下降算法。
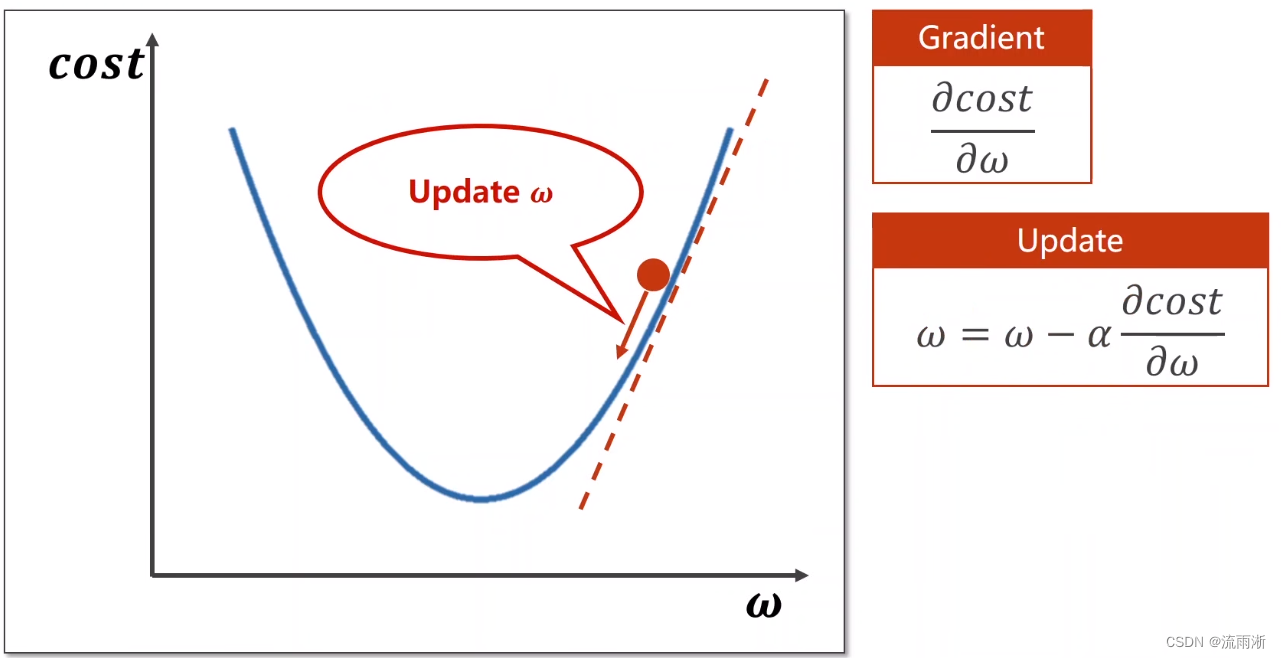
在梯度下降算法中,核心公式为梯度计算公式:
∂
c
o
s
t
∂
ω
\frac{\partial cost}{\partial\omega}
∂ω∂cost和
ω
\omega
ω更新公式:
ω
=
ω
−
α
∂
c
o
s
t
∂
ω
\omega=\omega-\alpha\frac{\partial cost}{\partial\omega}
ω=ω−α∂ω∂cost
其中,
α
\alpha
α是学习率,用来表示往前走多远,一般取值比较小;
对此算法,每次每次更新都是向梯度下降的方向走一步。属于典型的贪心算法,即每次只看眼前最好的选择。不一定能得到最优的结果,但是能得到局部区域最优解。如果函数(非凸函数) 的损失函数不规则,使用梯度下降算法可能无法到达真正的全局最优解,只能得到局部最优解。

在深度学习中使用梯度下降算法是由于深度神经网络中的损失函数中的局部最优解很少,很难陷入到局部最优解。但是,最大的问题是存在鞍点,没有局部最优解,如果在梯度优化时到达鞍点,则陷入到鞍点之中,无法继续更新。
采用第二讲中的损失函数:
1
N
∑
n
=
1
N
(
x
n
⋅
ω
−
y
n
)
2
\frac1N\sum_{n=1}^N(x_n\cdot\omega-y_n)^2
N1∑n=1N(xn⋅ω−yn)2 ,则梯度计算如下:

则更新函数就可以表示为:

梯度下降代码
import matplotlib.pyplot as plt
# 准备数据集
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
# 设置初始权重
w = 1.0
# 模型:前馈
def forward(x):
return x * w
# 定义cost函数计算MSE
def cost(xs, ys):
cost = 0
for x, y in zip(xs, ys):
y_pred = forward(x)
cost += (y_pred - y) ** 2
return cost / len(xs)
# 定义梯度函数
def gradient(xs, ys):
grad = 0
for x, y in zip(xs, ys):
grad += 2 * x * (x * w - y)
return grad / len(xs)
epoch_list = []
cost_list = []
print('predict (before training)', 4, forward(4))
for epoch in range(100):
cost_val = cost(x_data, y_data)
grad_val = gradient(x_data, y_data)
w -= 0.01 * grad_val # 设置学习率为0.01
print('epoch:', epoch, 'w=', w, 'loss=', cost_val)
epoch_list.append(epoch)
cost_list.append(cost_val)
print('predict (after training)', 4, forward(4))
plt.plot(epoch_list, cost_list)
plt.ylabel('cost')
plt.xlabel('epoch')
plt.show()
部分输出为:
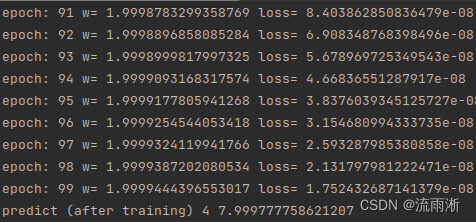
生成图像:
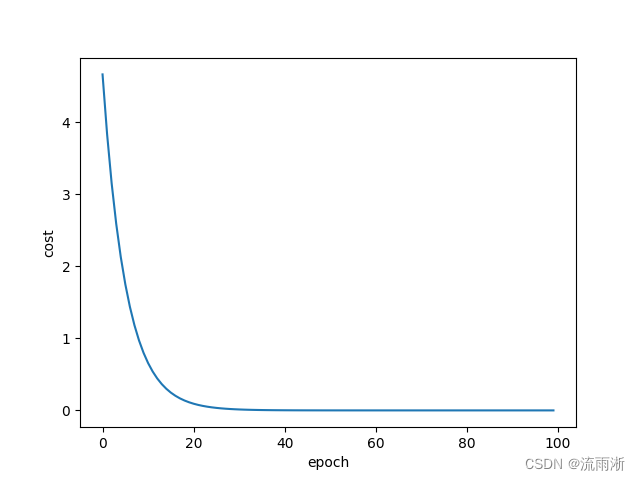
如果输出曲线抖动明显,可以通过指数加权求均值的方法进行平滑。有时候训练会发散,可以考虑降低学习率来尝试。
随机梯度下降
梯度下降的更新使用所有值的均值来计算。随机梯度下降则每次随机选择一个数据来计算更新。

优点:面对带有鞍点的损失函数,整个的cost函数可能陷入鞍点,无法继续更新,如果采用随机梯度下降算法,每次只拿出来一个数据进行更新,则随机噪声可能会在陷入鞍点是向前推动,向最优值前进。
随机梯度下降的更新函数:只需要求一个样本的均值求出来就可以了。
随机梯度下降代码
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = 1.0
def forward(x):
return x * w
# 计算损失函数,计算单一值,不需要累加求均值
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
# 定义梯度函数
def gradient(x, y):
return 2 * x * (x * w - y)
epoch_list = []
loss_list = []
print('Predict (before training)', 4, forward(4))
for epoch in range(100):
# 对每个样本求梯度更新(随机性在这里可以理解为正好随机到从前往后的数据顺序)
for x, y in zip(x_data, y_data):
grad = gradient(x, y)
w = w - 0.01 * grad
print("\tgrad:", x, y, grad)
l = loss(x, y)
print("progress:", epoch, "w=", w, "loss=", l)
epoch_list.append(epoch)
loss_list.append(l)
print('predict (after training)', 4, forward(4))
plt.plot(epoch_list, loss_list)
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()
小批梯度下降(Mini-Batch GD)
| \ | 梯度下降 | 随机梯度下降 |
|---|---|---|
| 性能 | 低 | 高 |
| 时间 | 低 | 高 |
梯度下降算法将所有的数据求梯度来计算,效率较高,随机梯度下降则需要每个数据单独计算,花费的时间更长。为了平衡二者之间的优缺点,取一种折中的方式:小批梯度下降。该方法将数据分为不同的小分组,组内采用梯度下降,组间采用随机梯度下降。
由于数据量较少,没有编写此法代码,但深度学习中更多的是用这种方法。
反向传播算法(第4讲)
背景
线性模型可以看作一个非常简单的神经网络,
x
x
x为输入,权重
ω
\omega
ω为训练的目标,
y
^
\hat{y}
y^为最终输出。对于这样一个简单的神经网络可以通过求损失函数,采用梯度下降算法来寻找最优的权重。
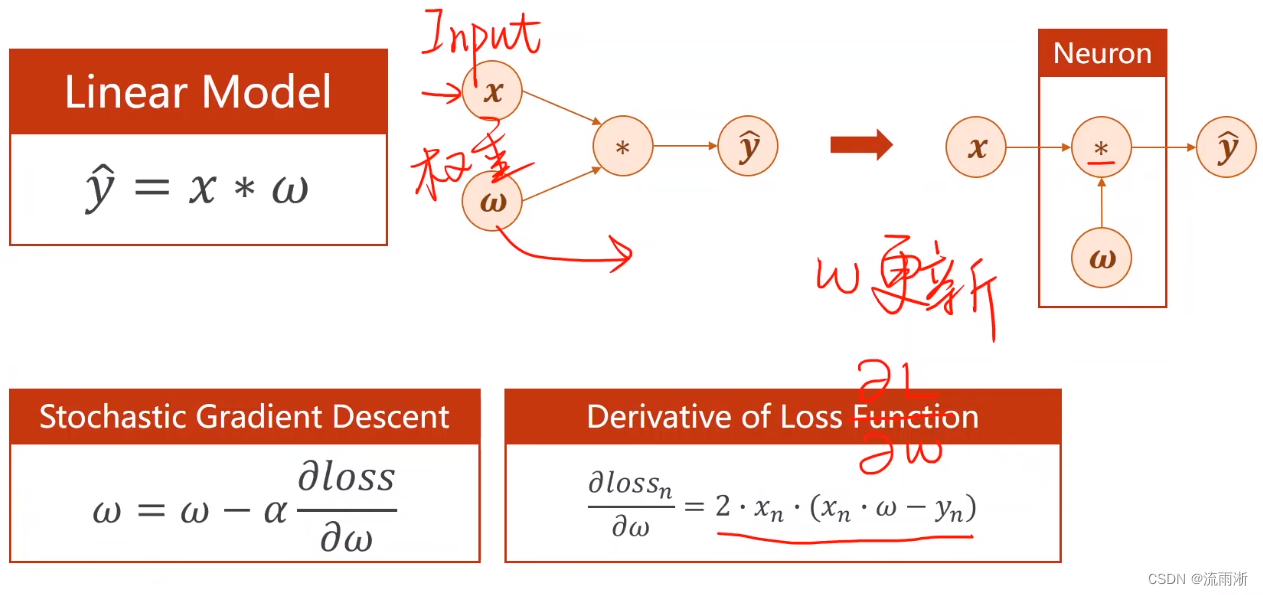
但对于一个比较复杂的模型,权重数量非常多,计算复杂,解析式会太过复杂。考虑把网络看成一个图,可以在图上传播梯度,最终根据链式法则把梯度求出来,这种算法我们称为反向传播算法。
原理
对于如图所示的一个两层的神经网络,需要注意输入维度与权重维度,经过运算后可以得到中间隐藏层的输出,隐藏层与偏置量相加得到,其中MN模块为矩阵乘法的运算,ADD为矩阵加法运算。第二层与第一层同。
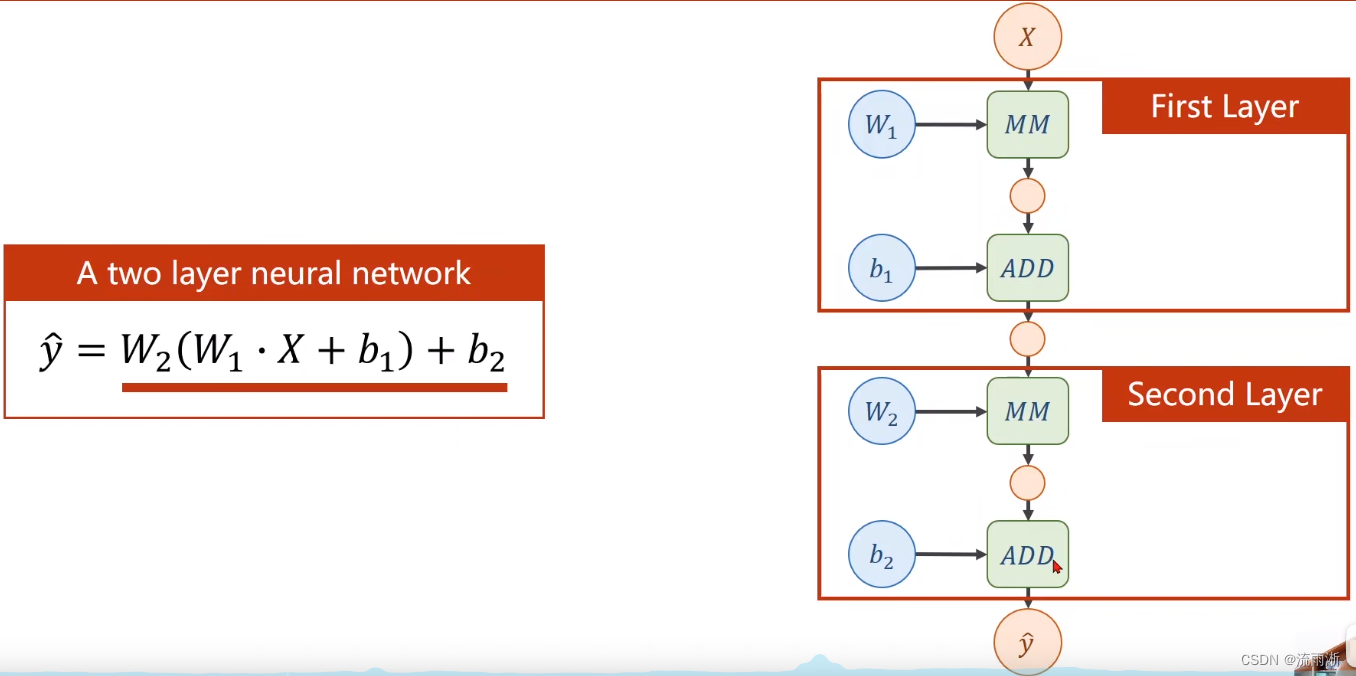
将上式展开,无论多少层都可以用一层来表示:
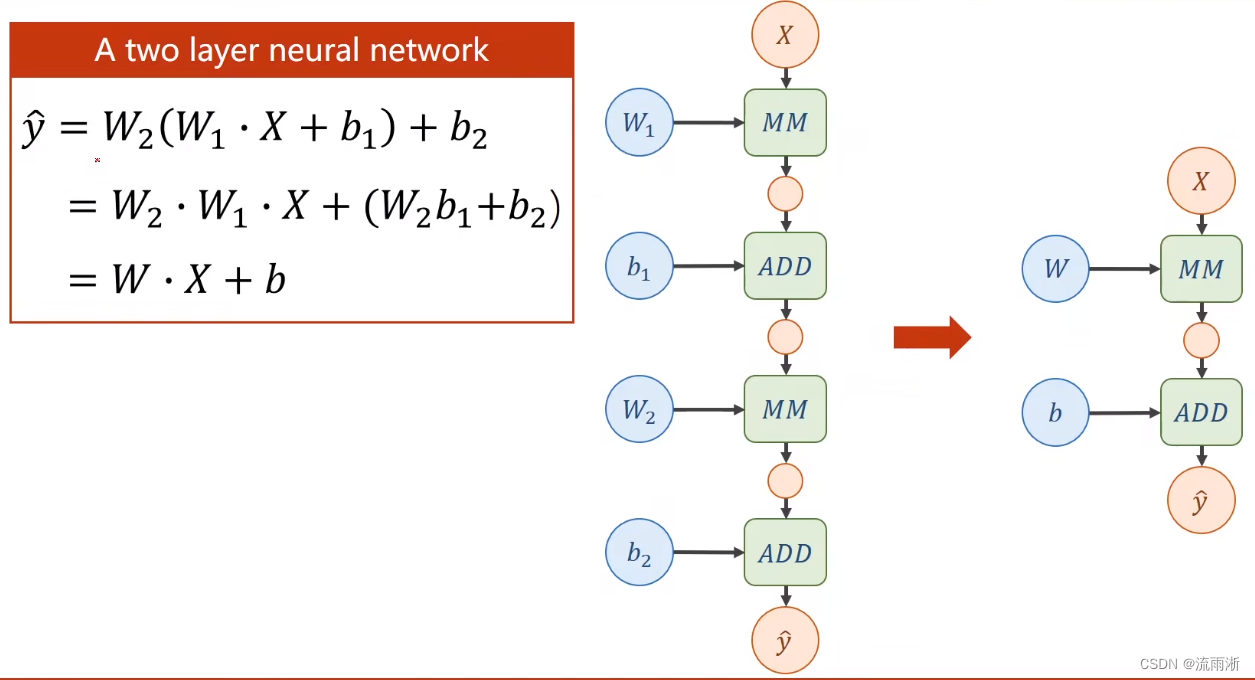
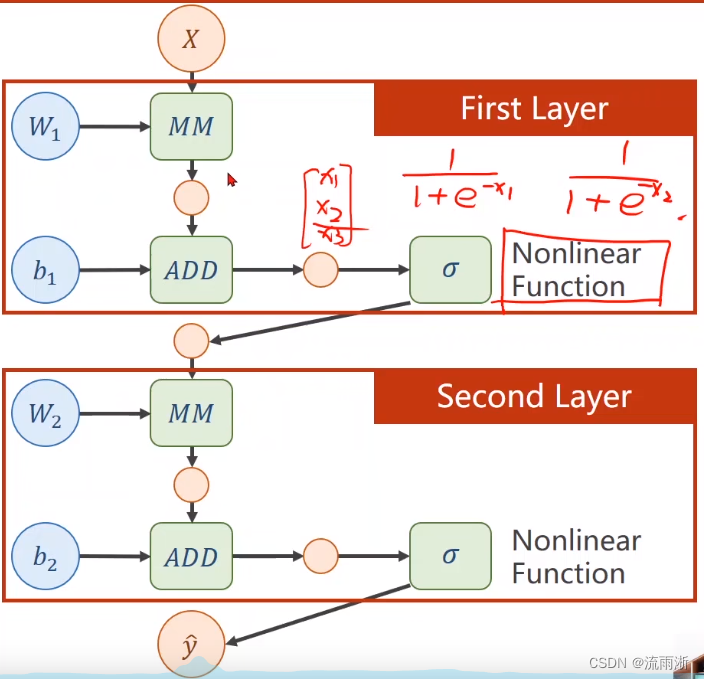
此时,增加的权重就完全没有意义,模型的复杂程度并没有提升。为此,考虑在每个层输出添加一个非线性的变化函数,对张量里的每个值,都应用一个非线性的函数,如此,所有层就没法展开化简为一层,才能成为一个真正的神经网络。
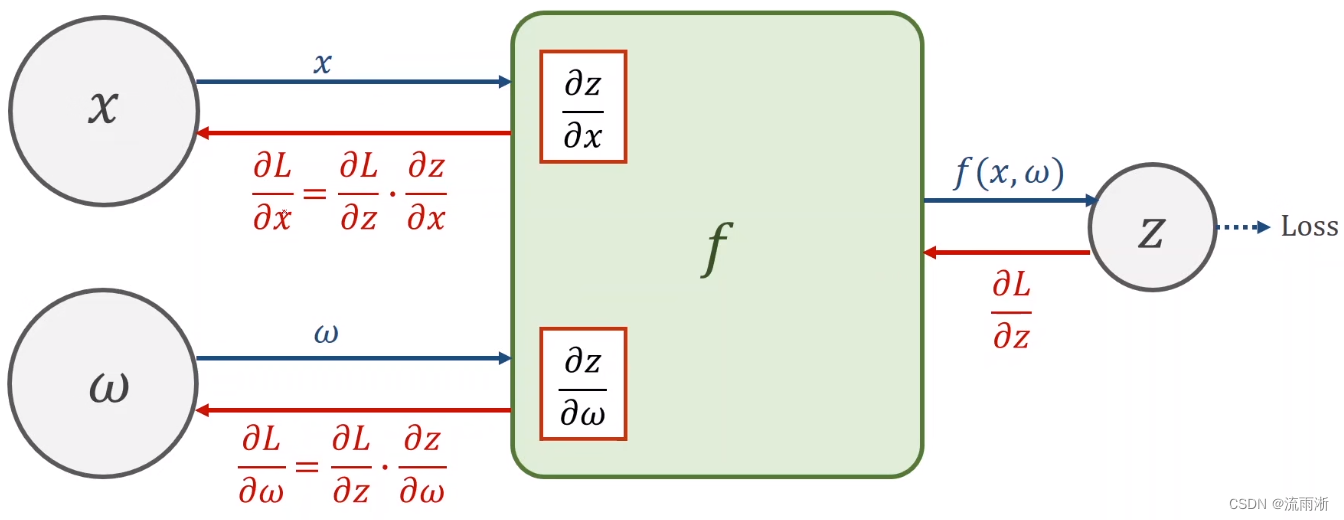
链式求导过程:1、创建计算图(前馈),沿着箭头的方向,即沿着边的方向,先计算最终的Loss;2、计算输出
z
z
z关于输出
x
x
x和
ω
\omega
ω的梯度(偏导数);3、给定来自后续节点的梯度;4、使用链式法则计算梯度
举例来说:
假设
f
=
x
⋅
ω
f=x\cdot\omega
f=x⋅ω,那么可以得出
z
z
z对
x
x
x的偏导和
z
z
z对
ω
\omega
ω的偏导,也可以求出
z
z
z,在视频中假设Loss对
z
z
z的偏导为5,可以反向计算出Loss对
x
x
x的偏导和Loss对
ω
\omega
ω的偏导。
完整的计算图:
前馈: 确定要训练的量,求偏导数,继续前馈求
y
^
\widehat{y}
y
,继续前馈做减法,求残差,求偏导,继续前馈做平方,求偏导。
反向传播: 求loss对r的偏导,loss对
y
^
\widehat{y}
y
的偏导,loss对
ω
\omega
ω的偏导。
得到了损失对权重的导数,后面就可以用梯度下降算法对权重进行更新。
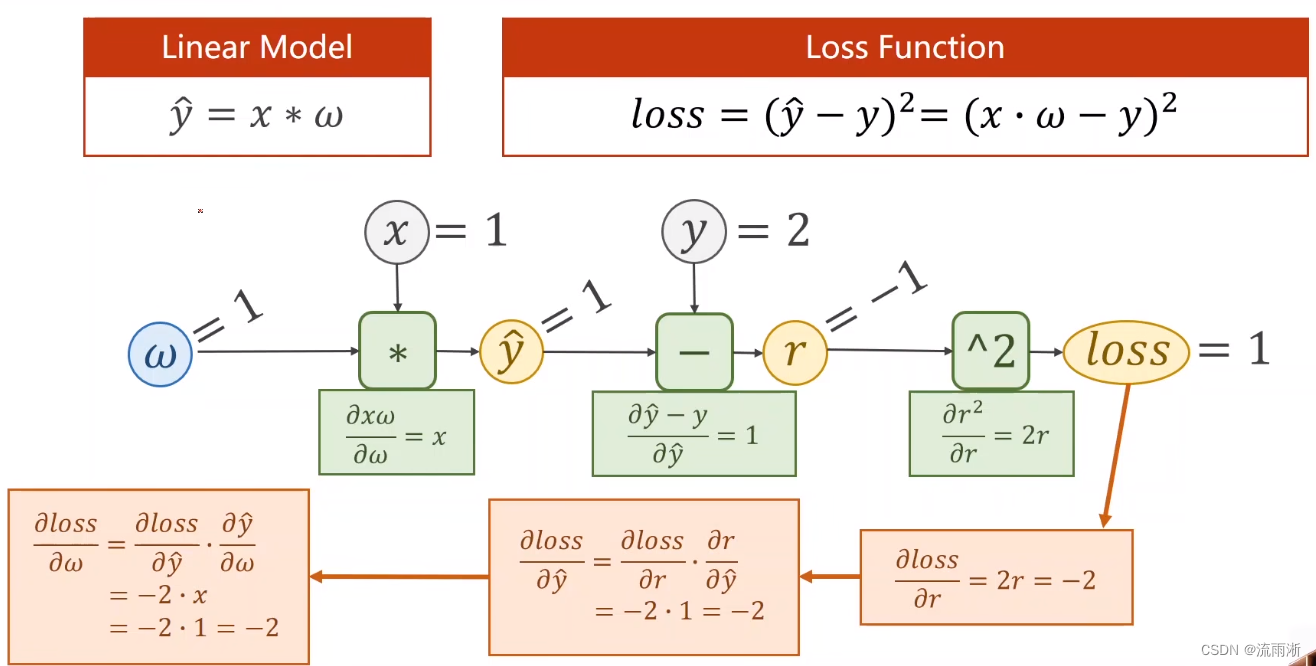
练习1
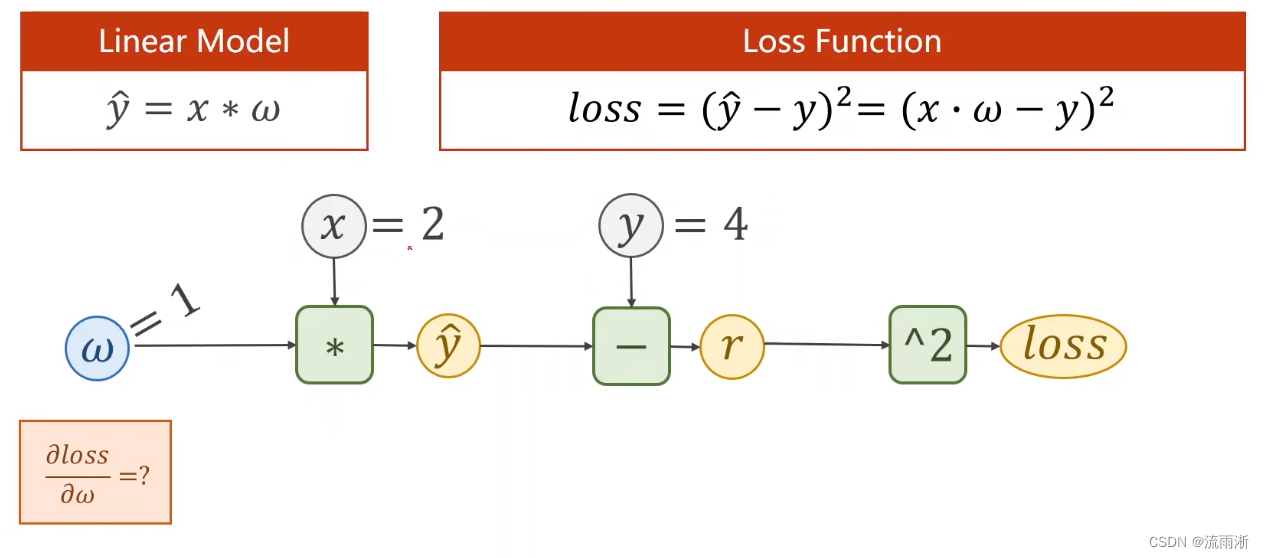
首先进行前馈:计算
y
^
\widehat{y}
y
对
ω
\omega
ω的导数,计算
y
^
\widehat{y}
y
值;做减法计算残差
r
r
r,求残差对
y
^
\widehat{y}
y
的导数;对残差进行平方求损失函数,计算损失函数的值,求损失函数loss对
r
r
r的偏导。
然后进行反向传播:计算损失函数对
y
^
\widehat{y}
y
的偏导,计算损失函数loss对
ω
\omega
ω的导数。
计算结果是
∂
l
o
s
s
∂
ω
=
−
8
\frac{\partial loss}{\partial\omega}=-8
∂ω∂loss=−8。
练习2
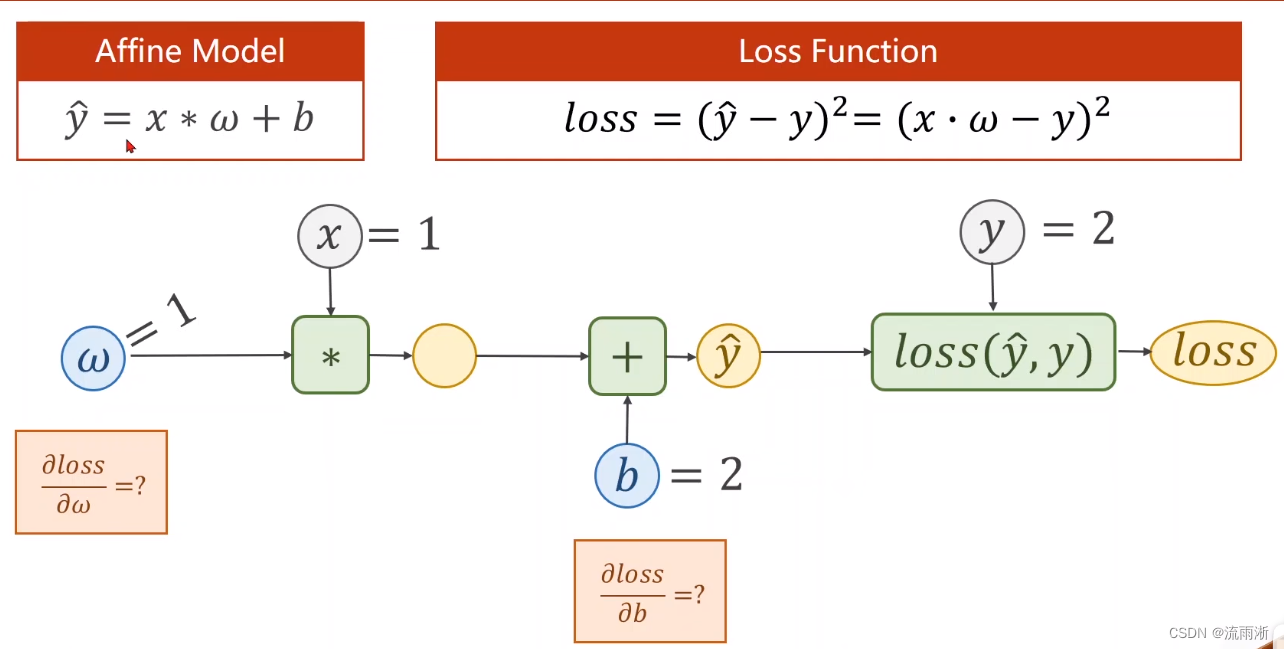
前馈:计算
y
^
\widehat{y}
y
的值,计算
y
^
\widehat{y}
y
对
ω
\omega
ω的偏导,计算
y
^
\widehat{y}
y
对b的偏导;计算损失函数
l
o
s
s
=
(
y
^
−
y
)
2
loss=(\hat{y}-y)^{2}
loss=(y^−y)2的值,计算loss对
y
^
\widehat{y}
y
的导数;
反向传播:计算loss对b的偏导,计算loss对
ω
\omega
ω的偏导。
计算结果是:
∂
l
o
s
s
∂
ω
=
2
\frac{\partial loss}{\partial\omega}=2
∂ω∂loss=2,
∂
l
o
s
s
∂
b
=
2
\frac{\partial loss}{\partial b}=2
∂b∂loss=2。
代码
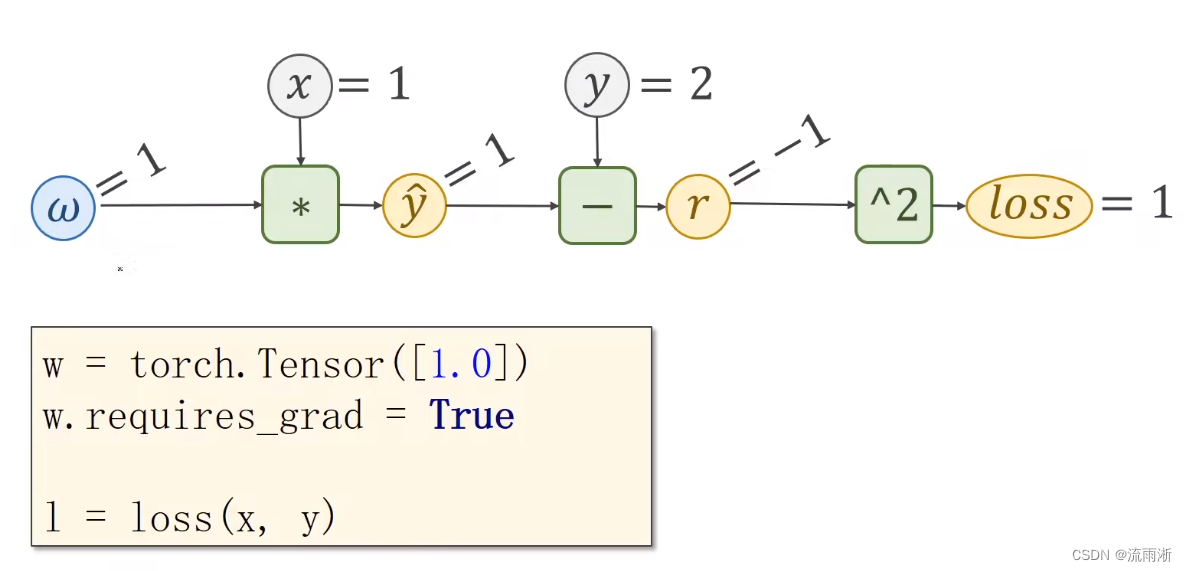
PyTorch中最基本的数据类型:Tensor。用来存数据,可以存标量、向量、矩阵、高维矩阵,Tensor是一个类(struct)。包含两个重要成员:data和grad ,data保存权重的值,grad保存损失函数对权重的导数。
import torch
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = torch.Tensor([1.0]) # w的初值为1.0
w.requires_grad = True # 需要计算梯度
# 模型
def forward(x):
return x * w # w是一个Tensor
# 损失函数
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
# 打印权重w为初值条件下的输出
print("predict (before training)", 4, forward(4).item())
for epoch in range(100):
for x, y in zip(x_data, y_data):
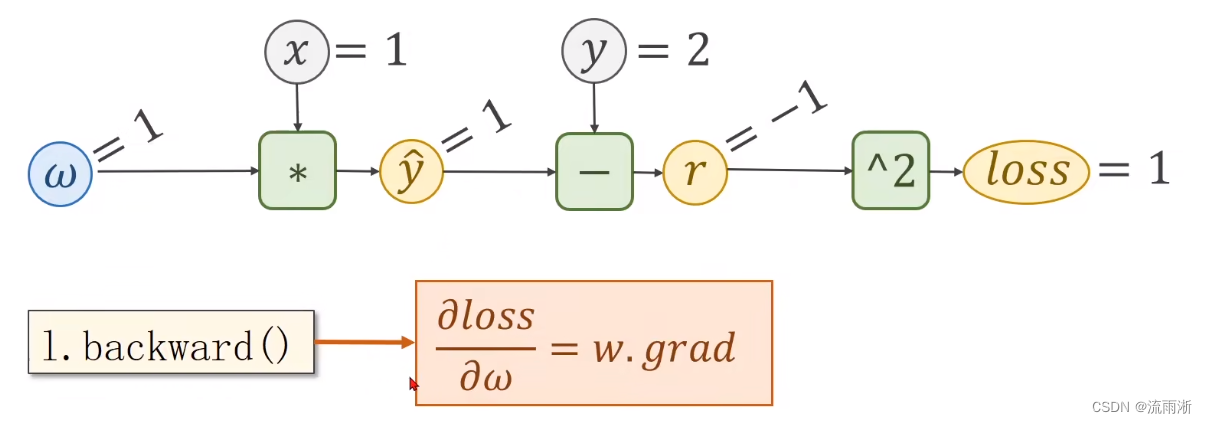
l = loss(x, y) # loss是一个张量,生成计算图
l.backward() # 只要计算backward,计算图就被释放了没有了,下次计算loss生成新的计算图
print('\tgrad:', x, y, w.grad.item())
w.data = w.data - 0.01 * w.grad.data
# 权重更新时,grad也是一个Tensor,不能直接拿grad直接进行计算,需要取到它的data,
# 取data计算不会建立计算图
w.grad.data.zero_() # 将梯度数据全部清零,若不清零会将上次的与本次的累加
print('progress:', epoch, l.item())
# 打印权重w为训练后的e输出值
print("predict (after training)", 4, forward(4).item())
PyTorch中的前馈
PyTorch中的反向传播
练习3

计算图如下:
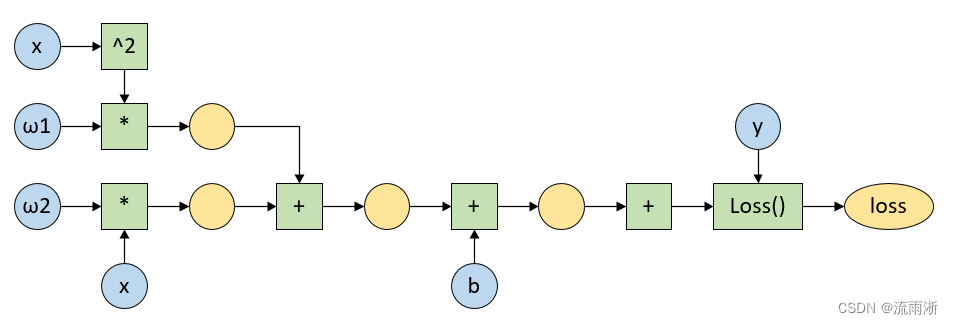
练习3代码
import torch
x_data = [1.0,2.0,3.0]
y_data = [2.0,4.0,6.0]
w1 = torch.Tensor([1.0])
w1.requires_grad = True
w2 = torch.Tensor([1.0])
w2.requires_grad = True
b = torch.Tensor([1.0])
b.requires_grad = True
def forward(x):
return w1 * x * x + w2 * x + b
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
print("Predict (befor training)", 4, forward(4).item())
for epoch in range(100):
for x, y in zip(x_data,y_data):
l = loss(x, y)
l.backward()
print('\tgrad:', x, y, w1.grad.item(), w2.grad.item(), b.grad.item())
w1.data = w1.data - 0.01 * w1.grad.data
w2.data = w2.data - 0.01 * w2.grad.data
b.data = b.data - 0.01 * b.grad.data
w1.grad.data.zero_()
w2.grad.data.zero_()
b.grad.data.zero_()
print('progress:', epoch, l.item())
print("Predict (after training)", 4, forward(4).item())
运行结果:
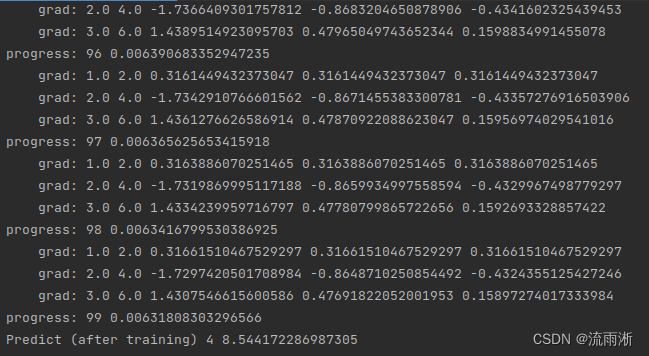
用PyTorch实现线性回归(第5讲)
采用PyTorch框架
1、准备数据集;
2、使用类来设计模型,模型继承自nn.Module;
3、构造损失函数和优化器,使用PyTorch API;
4、训练周期:前馈,反馈,更新;
准备数据
在PyTorch中,计算图采用mini-batch方式,mini-batch是一次性把所有的结果都求出来,因此x和y都是3x1的张量。

设计模型
在PyTorch中不再考虑人工求导数,重点目标变成构造计算图,将计算图成功构造出,梯度就自动计算出了。将一个权重和一个偏置量构成的
y
^
=
ω
∗
x
+
b
\hat{y}=\omega*x+b
y^=ω∗x+b称为一个线性单元。
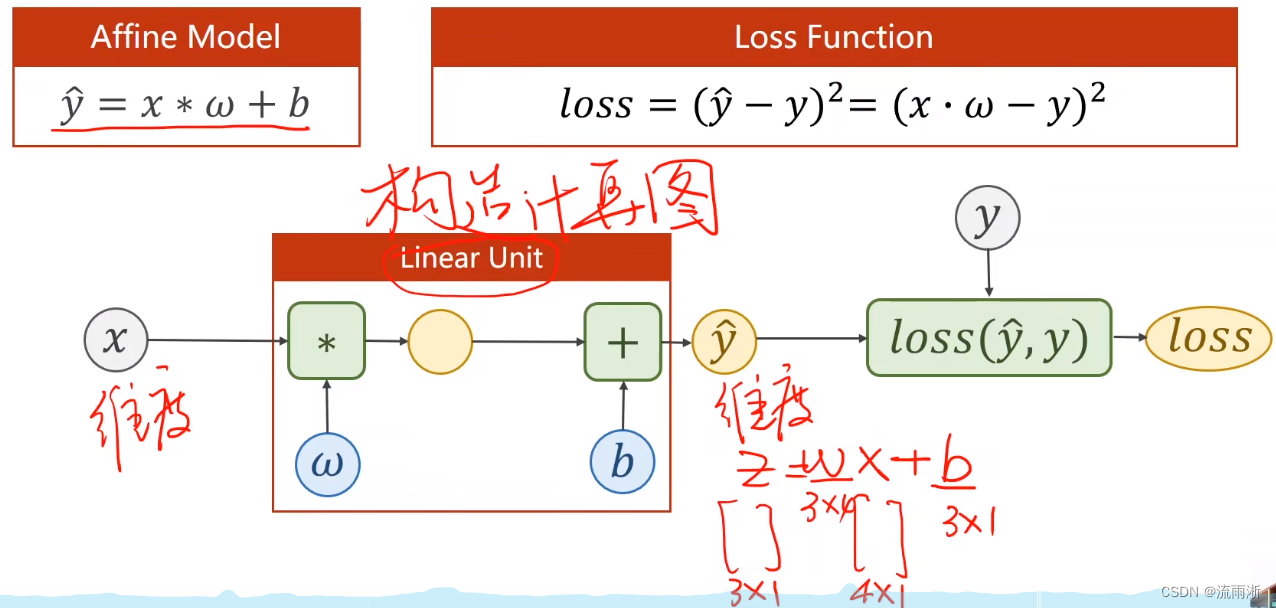
如果要确定权重
ω
\omega
ω和
b
b
b的维度,则需要知道
x
x
x的维度和输出
y
^
\hat{y}
y^的维度。
总体就是构造一个计算图,从 x x x输入开始,经过权重和偏置参与的计算,最终通过损失函数计算出loss,随后就可以在loss处调用backward进行反向传播。
需要注意的是:loss最终必须是一个标量,而上面算出来的是3x1的矩阵,这时候就需要将矩阵中的所有loss进行求和,并选择是否求均值。loss为向量是无法进行backward的。
首先,我们需要将模型定义为一个类,我们的模型类需要继承自nn.Module,这是对于所有神经网络模块的基础类。
类里面至少需要实现两个函数:init(构造函数),初始化对象时默认调用的函数;forward函数,执行前馈的时候所要执行的计算。这里面没有写反向的如何算,原因是用Module构造出来的对象会根据这里面的计算图自动实现backward的过程。

super(LinearModel, self).__init__()
上面的super调用父类的构造,这里调用父类的init。
self.linear = torch.nn.Linear(1, 1)
这里torch.nn.Linear是PyTorch里的一个类,类的后面加括号是构造一个对象,这个对象包含了权重和偏置这两个Tensor,将来可以直接利用Linear来完成权重*输入+偏置这个计算。Linear也是继承自Module的,所以能够自动进行反向传播。所以这里的self.linear也是一个对象,对象的类型是torch下nn里面的Linear这个类。
视频中讲完上面的之后又详细讲了一些关于文档和维度的内容,建议看视频。

y_pred = self.linear(x)
在对象self.linear后面加括号,实现一个可调用的对象。这里面实现了对
y
^
=
ω
∗
x
+
b
\hat{y}=\omega*x+b
y^=ω∗x+b的计算,并且有x为3x1的矩阵计算出
y
^
\hat{y}
y^为一个3x1的矩阵。
视频中又讲解了一些关于python的内容,这里略过。
model = LinearModel()
这里进行实例化。
构建损失和优化器
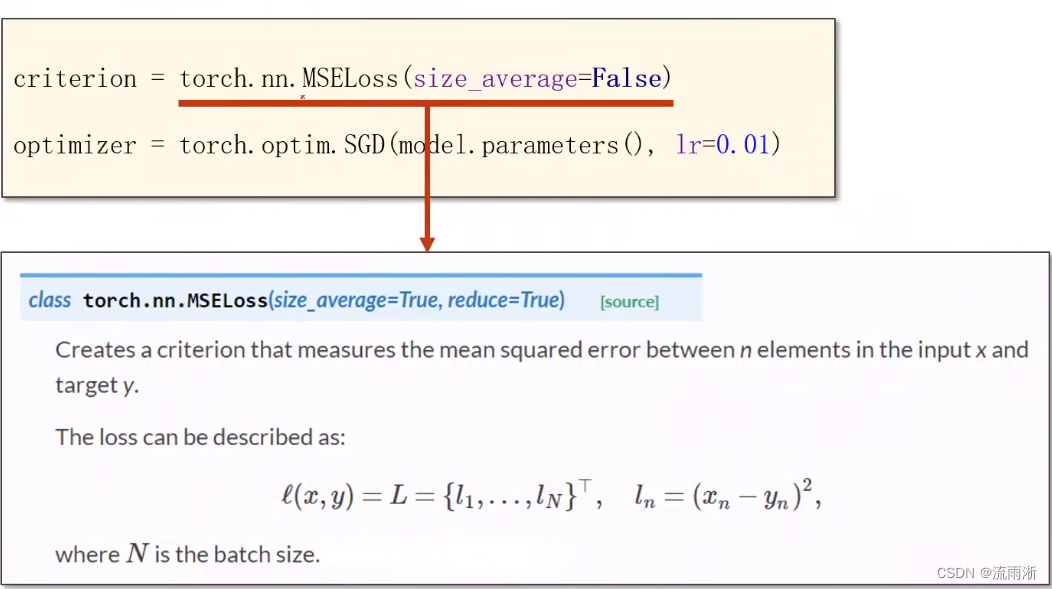
在PyTorch中有现成类进行mse运算,这个类也是继承自nn.Module。参数有两个,如上图所示,第一个size_average为是否求平均,第二个reduce为是否设置为降维,也就是前面提到的对于loss矩阵里面的每个loss累加求和,最后得到一个标量,形式上是降维了,这里默认为降维。

优化器不是Module,不会构建计算图,SGD是一个类,这里是做实例化。第一个参数是权重,第二个参数是学习率。
训练过程
for epoch in range(1000):
y_pred = model(x_data) # 计算y_hat
loss = criterion(y_pred, y_data) # 计算损失函数
print(epoch, loss.item())
optimizer.zero_grad() # 通过backward的梯度计算会被累加,需要归零
loss.backward() # 进行反向传播
optimizer.step() # 进行更新
测试模块
# Output weight and bias
print('w = ', model.linear.weight.item()) # weight是一个矩阵,打印时只显示数值,后面需要添加item()
print('b = ', model.linear.bias.item())
# Test Model
x_test = torch.tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ', y_test.data)
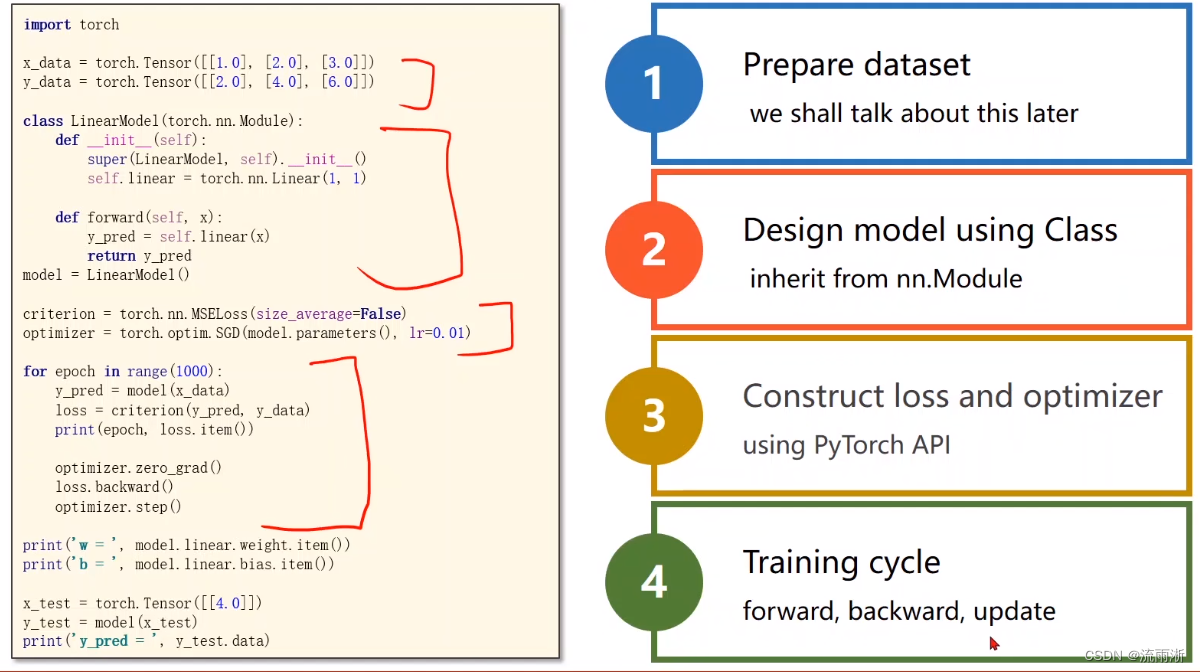
代码
import torch
x_data = torch.tensor([[1.0], [2.0], [3.0]])
y_data = torch.tensor([[2.0], [4.0], [6.0]])
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
y_pred = self.linear(x)
return y_pred
model = LinearModel()
criterion = torch.nn.MSELoss(size_average=False)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
for epoch in range(1000):
y_pred = model(x_data) # 计算y_hat
loss = criterion(y_pred, y_data) # 计算损失函数
print(epoch, loss.item())
optimizer.zero_grad() # 通过backward的梯度计算会被累加,需要归零
loss.backward() # 进行反向传播
optimizer.step() # 进行更新
# Output weight and bias
print('w = ', model.linear.weight.item()) # weight是一个矩阵,打印时只显示数值,后面需要添加item()
print('b = ', model.linear.bias.item())
# Test Model
x_test = torch.tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ', y_test.data)
总体结构
线性回归中不同的优化器

这里给出官方的tutorial例子的网址:https://pytorch.org/tutorials/beginner/pytorch_with_examples.html
逻辑斯蒂回归(第6讲)
背景
逻辑斯蒂回归,名字带回归,但是一个分类问题。MNIST数据集:手写数字数据集,训练集有60000个样本,测试集有10000个样本,数字分为10个分类。 在分类问题中,需要对每种分类求它的概率,输出的也是每种类型的概率。对于每种输出概率,也有对其对应的分布。
torchvision是在PyTorch中的一个工具包,里面基本上包含了大部分比较流行的数据集。

torchvision还提供CIFAR-10数据集,是一对32x32的小图片,分为10个分类,训练集提供5万个样本,测试集提供一万个样本。数据集并不大。
对于前面几讲提到的回归问题,即学习时间和获得成绩的关系,将它转变为一个分类问题,可以将输出分类为考试通过或者不通过,就从一个回归问题变成了一个二分类问题。

原理
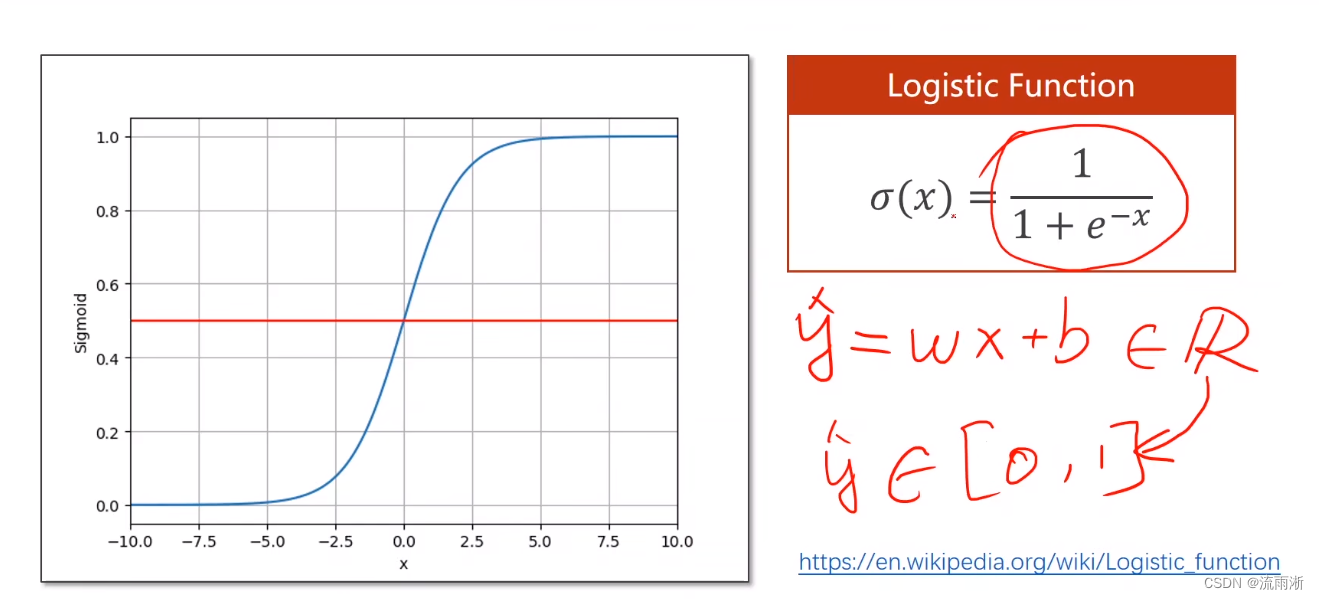
对于逻辑斯蒂函数,当x趋于正无穷,y趋近于1,当x趋近于0,y趋近于0,5,当x趋近于负无穷,y趋近于0。即对于任何输入,逻辑斯蒂函数的输出在0-1之间。 并且超过一定阈值之后,变化非常缓慢,导数逐渐趋于0。这种函数称为饱和函数。导数函数形状类似于正态分布。
sigmoid函数:函数值有极限,如图中所示,极限都在-1到+1之间;单调的增函数;满足饱和函数;最常用的就是逻辑斯蒂函数,所以一般直接称逻辑斯蒂函数为sigmoid函数。
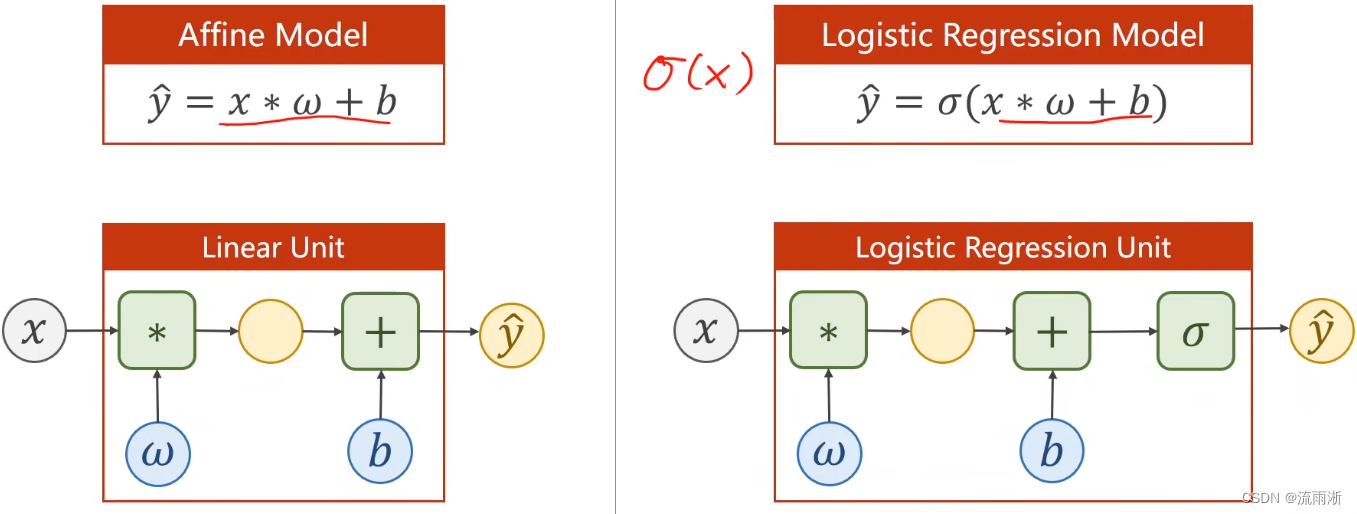
相比于仿射模型,逻辑斯蒂回归模型具有如图所示的变化:
损失函数的变化:

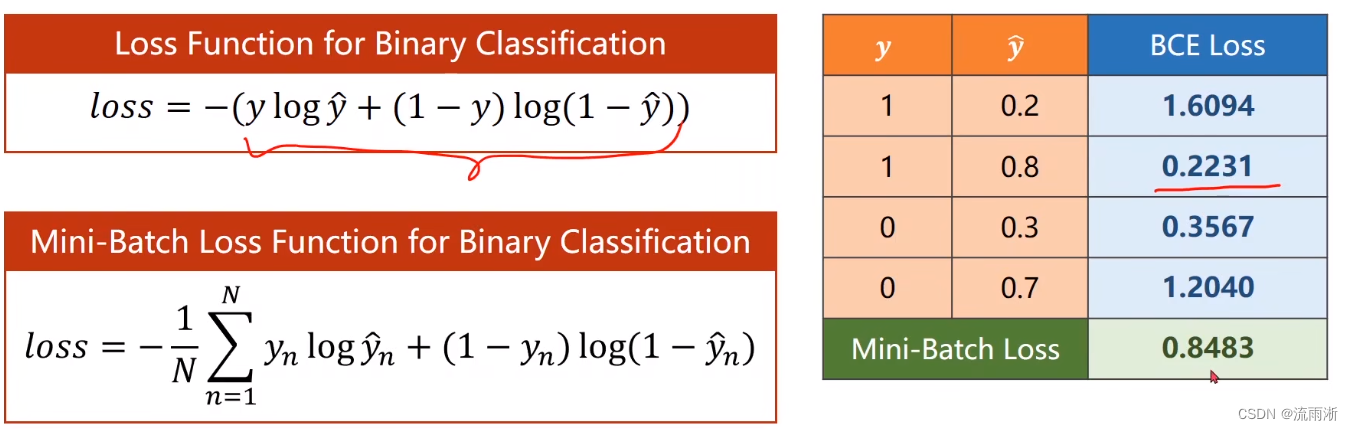
从上图表中可以看出,
y
^
\hat{y}
y^越接近
y
y
y,损失越小。
代码差异
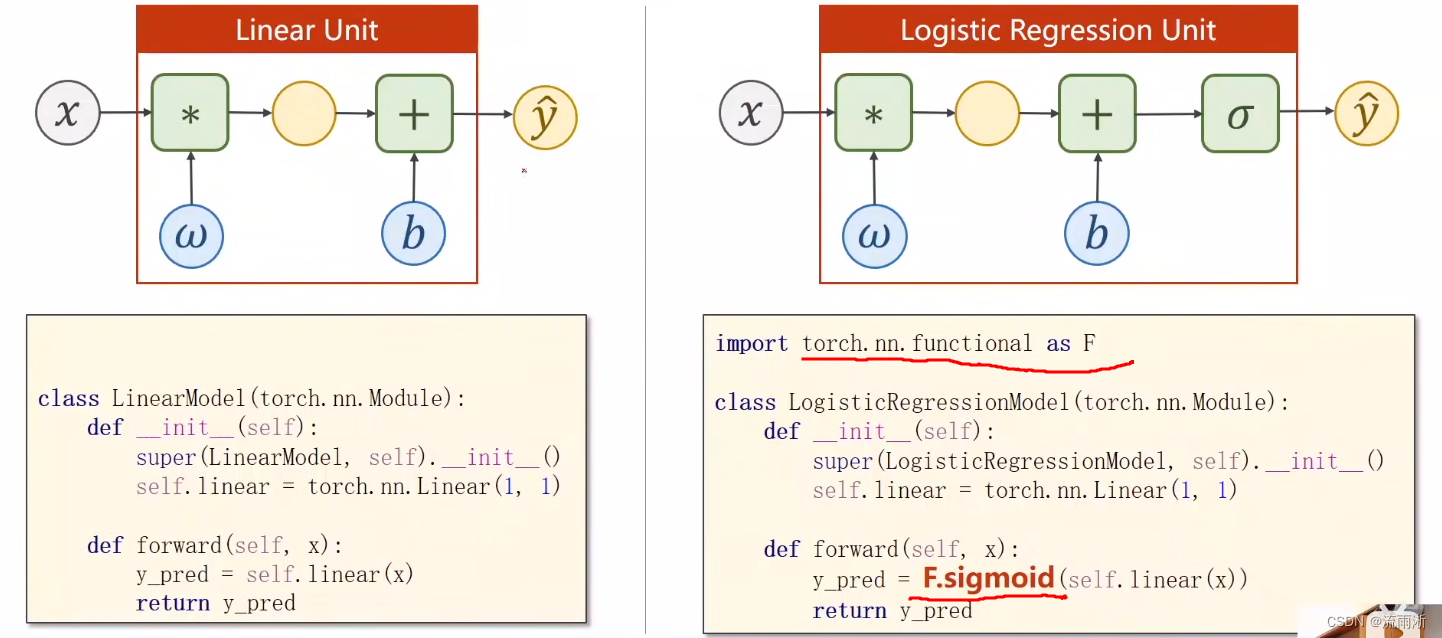
sigmoid函数定义在torch.nn.functional下面,这里就是将原本的结果再做一次变换。

之前用的是MSE损失函数,现在用的是BCE损失函数,即交叉熵。
代码
import torch
# 定义输入数据和标签数据
x_data = torch.tensor([[1.0], [2.0], [3.0]])
y_data = torch.tensor([[0.0], [0.0], [1.0]]) # 确保标签数据是浮点类型
# 定义逻辑回归模型
class LogisticRegressionModel(torch.nn.Module):
def __init__(self):
super(LogisticRegressionModel, self).__init__()
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
y_pred = torch.sigmoid(self.linear(x)) # 使用 torch.sigmoid
return y_pred
# 实例化模型
model = LogisticRegressionModel()
# 定义损失函数和优化器
criterion = torch.nn.BCELoss(reduction='sum') # 使用 reduction='sum'
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 训练模型
for epoch in range(1000):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 输出权重和偏置
print('w = ', model.linear.weight.item())
print('b = ', model.linear.bias.item())
# 测试模型
x_test = torch.tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ', y_test.data)
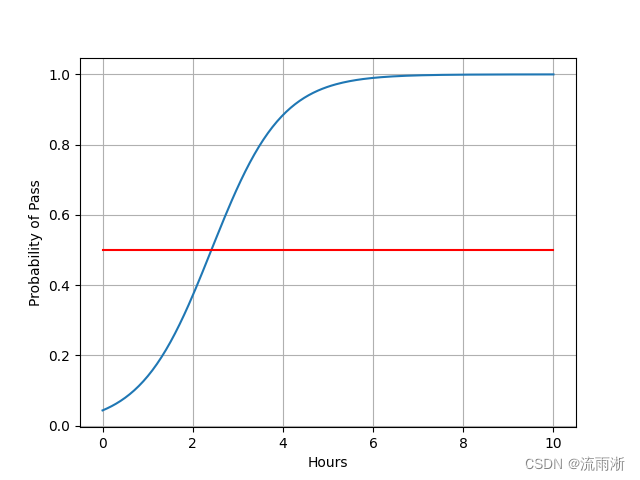
x = np.linspace(0, 10, 200)
x_t = torch.Tensor(x).view((200, 1))
y_t = model(x_t)
y = y_t.data.numpy()
plt.plot(x, y)
plt.plot([0, 10], [0.5, 0.5], c='r')
plt.xlabel('Hours')
plt.ylabel('Probability of Pass')
plt.grid()
plt.show()
注意
在实际运行中,原视频中的部分代码有错误,更改部分如下:
1、y_data的数据类型是LongTensor,而BCELoss期望输出是FloatTensor,需要将 y_data 转换为浮点类型。
2、激活函数使用 torch.sigmoid,因为 F.sigmoid 在较新版本的 PyTorch 中已被弃用。
3、更新 BCELoss 损失函数的参数 reduction=‘sum’,替代过时的 size_average=False。
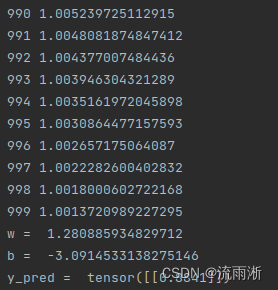
运行结果
处理多维特征的输入(第7讲)
原理
之前介绍的模型都是基于单维度的输入,输入x是一个实数。这一讲介绍面对多维输入,即输入x有很多个不同的特征,并预测其对应的分类。
对于一个糖尿病数据集,每一行对应一个sample(样本),叫做一个record(记录),机器学习中每一列对应一个feature(特征),数据库中每一列叫做一个字段。
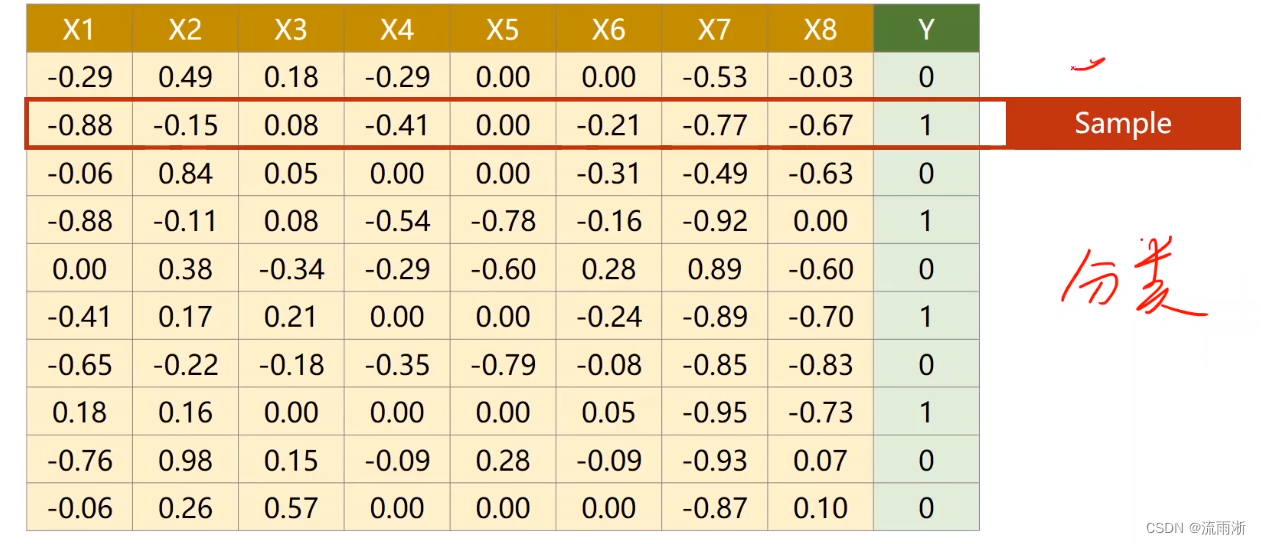
由于现在是多维输入确定一个输出,那么对应的模型和计算也会有变动,如下图中所示,x和y的右上序列代表不同的行的样本,每行样本是多维输入,右下序列代表每行的不同列的数据。由于输入维度的增加,对应的权重也相应增加。
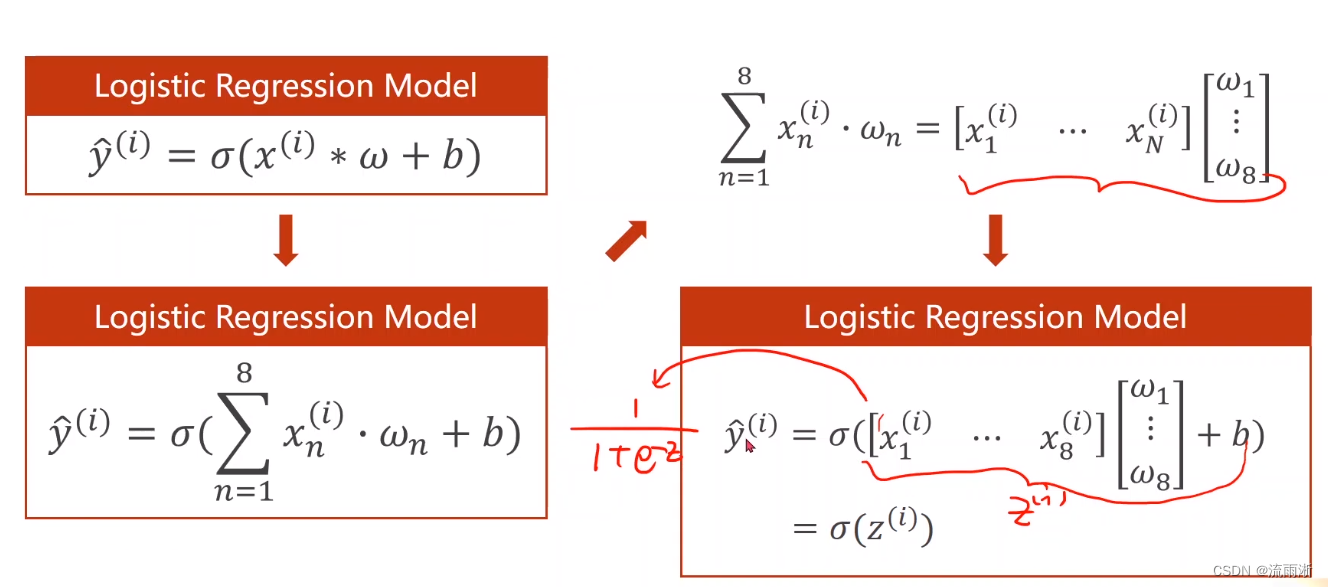
将所有的方程式合并为一个矩阵,可以计算为:
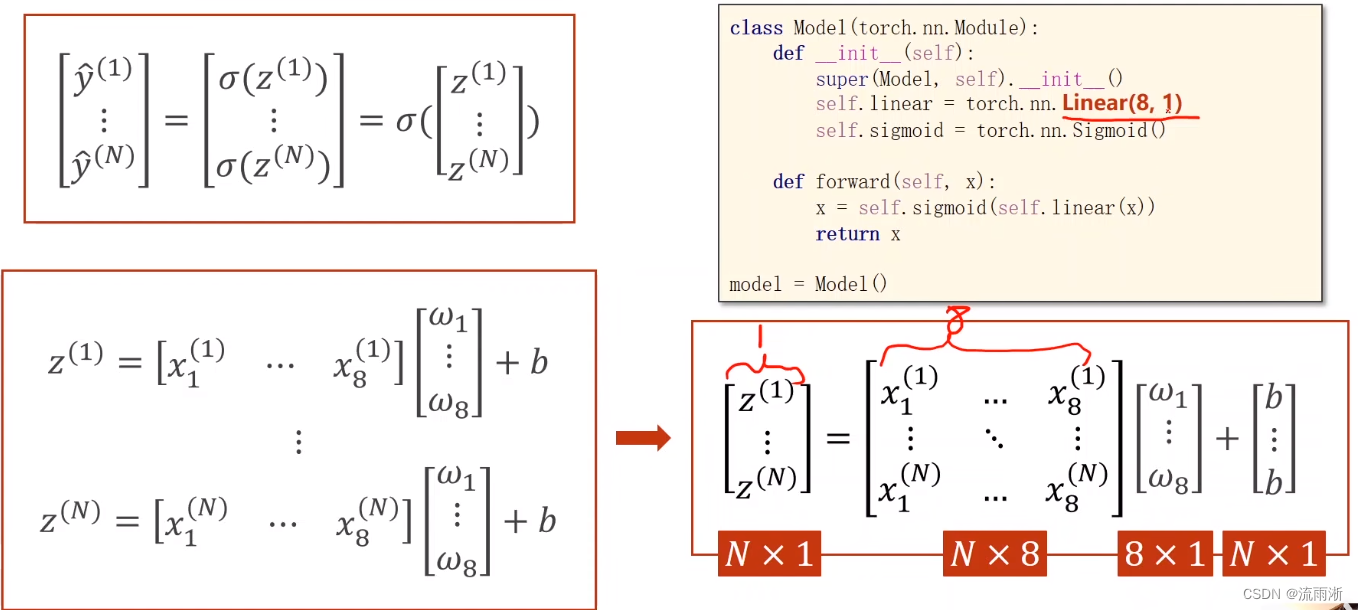
在这里,输入维度是8维,输出维度是1维,将之前的代码中Linear(1,1)改为(8,1)就好。这是通过单层直接实现得到1维的输出。
也可以通过多层最终得到1维的输出,比如先将维度从8维降到2维,再从2维降到1维:
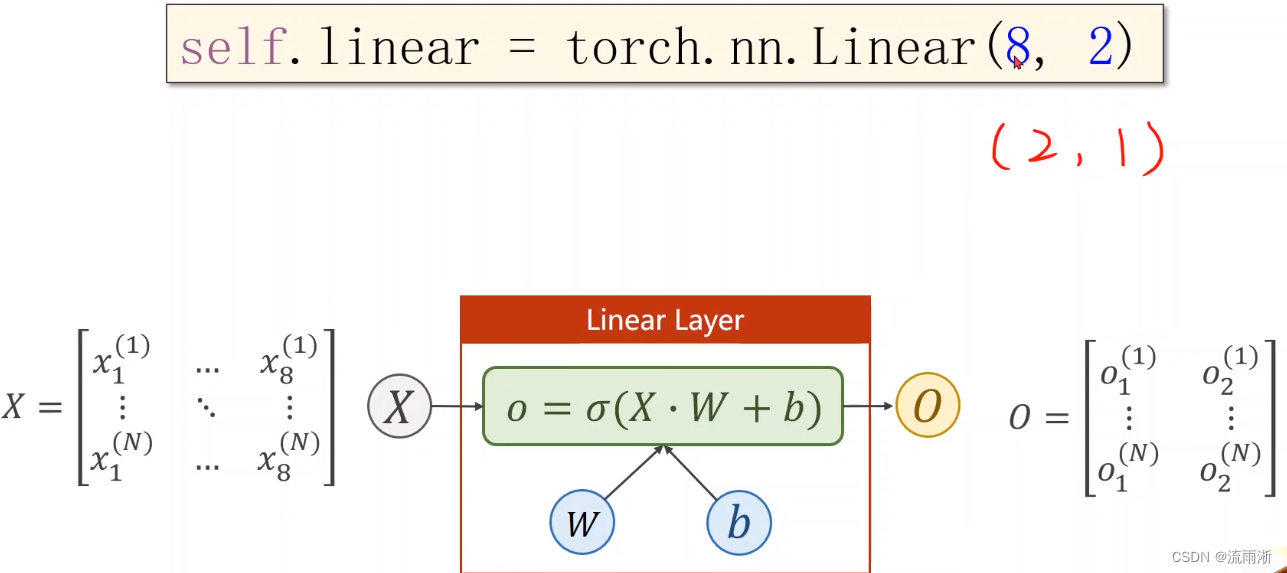
可以变换多次,可以先变高再变低,最终目的是得到1维的输出。如下是一个多层神经网络模型示例:

代码
import numpy as np
import torch
import matplotlib.pyplot as plt
xy = np.loadtxt('diabetes.csv', delimiter=',', dtype=np.float32)
x_data = torch.from_numpy(xy[:, :-1]) # 前面的:是指所有行,第二个:-1是指-1列不要
y_data = torch.from_numpy(xy[:, [-1]]) # 这里是所有行,且只要-1列
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6) # 输入数据x的特征是8维,x有8个特征
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
# 将其看作是网络的一层,而不是简单的函数使用,Sigmoid是nn下面的,不是之前的Function下面的
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x)) # y_hat
return x
model = Model()
# construct loss and optimizer
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
epoch_list = []
loss_list = []
for epoch in range(100):
# Forward
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
epoch_list.append(epoch)
loss_list.append(loss.item())
# Backward
optimizer.zero_grad()
loss.backward()
# Update
optimizer.step()
plt.plot(epoch_list, loss_list)
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()
仿真结果:
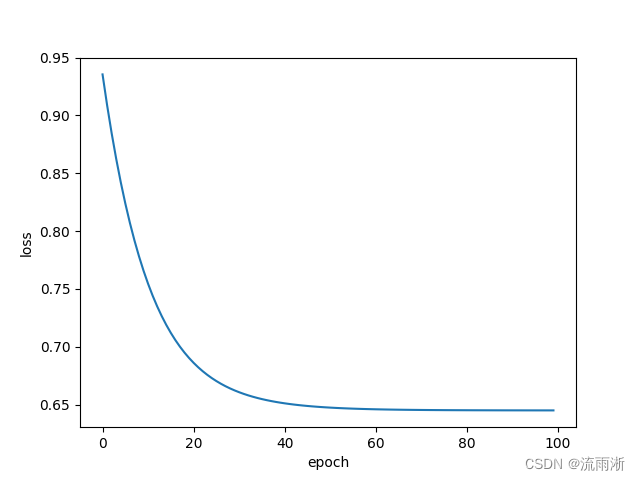
加载数据集(第8讲)
原理
数据集(dataset)和DataLoader是帮助我们加载数据的两个重要工具类,构造的数据集需要支持索引(用下标的方式将数据取出),DataLoader支持以mini-batch的形式将数据取出,以便训练时快速使用。
随机梯度下降可以帮助我们解决鞍点问题,mini-batch可以用以提升计算速度。
在使用mini-batch后,需要将代码写成两个循环嵌套的形式。
Epoch:所有训练样本都进行了一次前向传播和一次反向传播。
Batch-Size:每次训练时所用的样本数量。
Iteration:分了多少个Batch。

shuffle:将数据集打乱顺序。
Loader:将打乱顺序后的数据集进行分组。
在这里插入图片描述
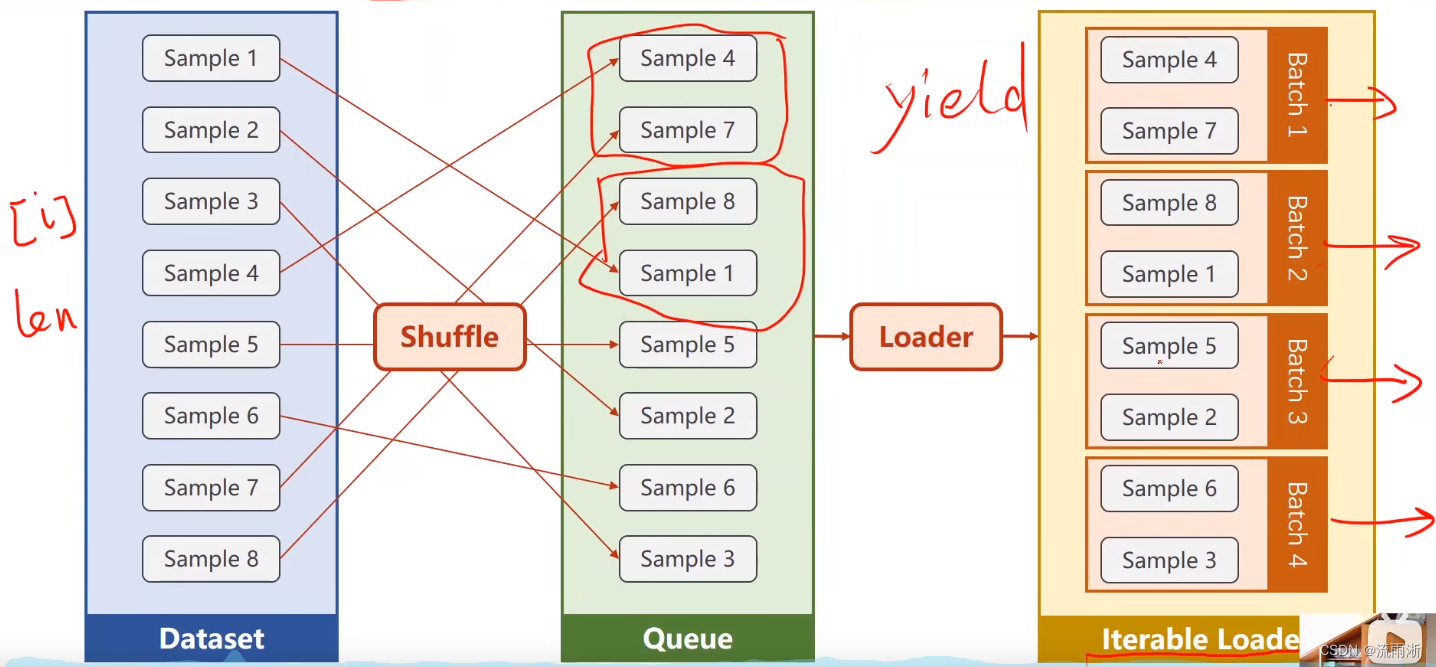
代码
import torch
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.data import Dataset # 抽象类,可以继承这个类来自定义一个
from torch.utils.data import DataLoader # 用来帮助加载数据:Shuffle, Loader
class DiabetesDataset(Dataset): # 这个类继承自Dataset
def __init__(self, filepath):
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)
self.len = xy.shape[0] # 返回(行数,列数)
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
def __getitem__(self, index): # 一个魔法函数,用以支持下标操作
return self.x_data[index], self.y_data[index]
def __len__(self): # 这个魔法函数返回数据集的长度
return self.len
dataset = DiabetesDataset('diabetes.csv')
train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=2) # num_workers:线程数
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
epoch_list = []
loss_list = []
loss_item = 0
if __name__ == '__main__':
for epoch in range(100):
for i, data in enumerate(train_loader, 0):
# 1.Prepare data
inputs, labels = data
# 2.Forward
y_pred = model(inputs)
loss = criterion(y_pred, labels)
print(epoch, i, loss.item())
loss_item += loss.item()
# 3.Backward
optimizer.zero_grad()
loss.backward()
# 4.Update
optimizer.step()
epoch_list.append(epoch)
loss_list.append(loss_item/24)
loss_item = 0
plt.plot(epoch_list, loss_list)
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()
仿真结果: 每次的图都不相同,不一样是正常的。
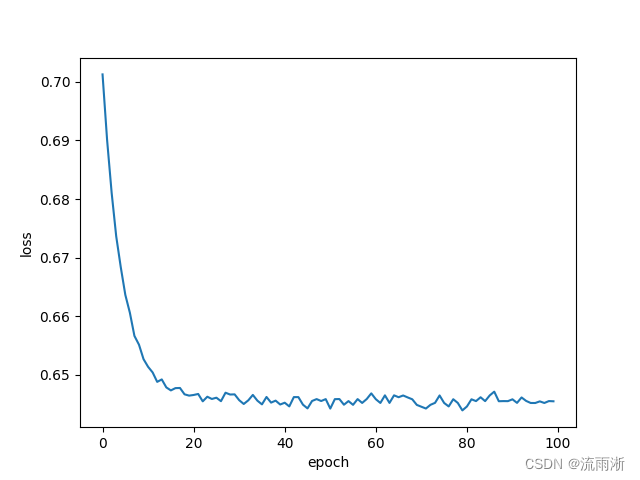
多分类问题(第9讲)
原理
第一种方式是将原来只有一个的输出增加到有十个输出,但是这里每个输出的概率都是独立的,并不满足一个分布的特性,即
P
≥
0
P\geq0
P≥0,且
∑
P
=
1
\sum P=1
∑P=1。所以我们在处理多分类问题中,最终输出层采用Softmax层。
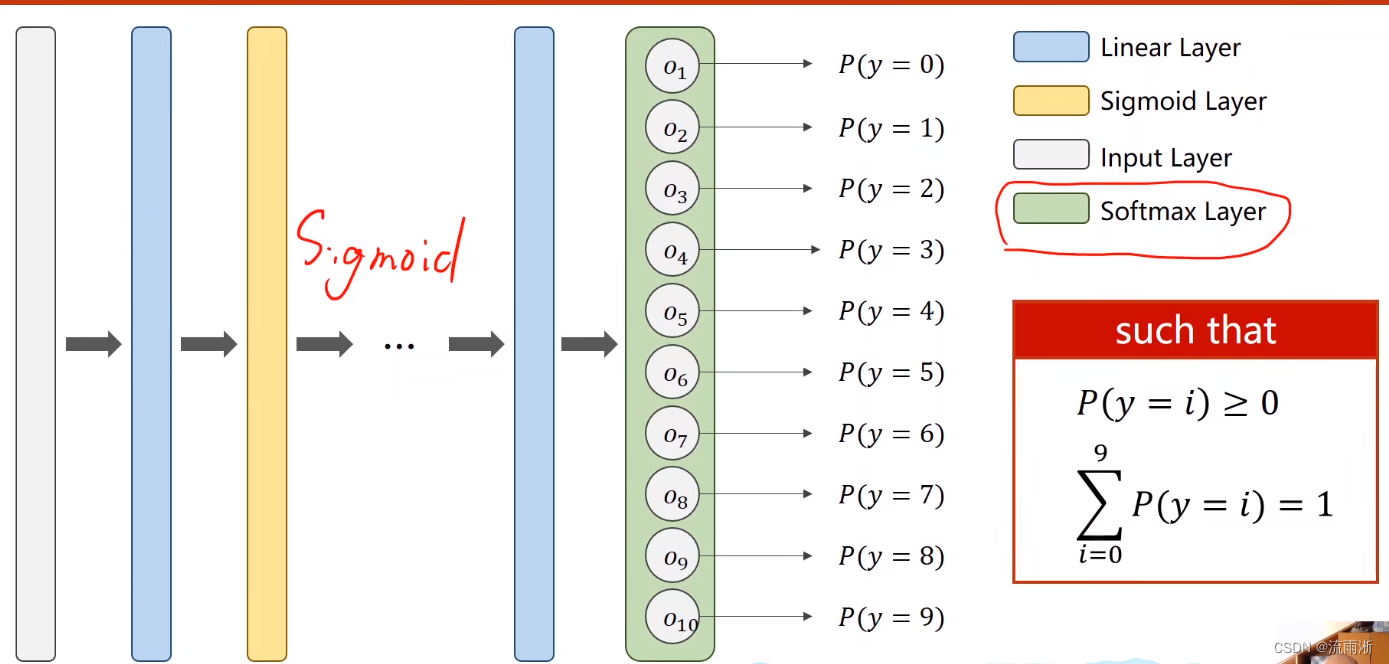
在最后一层线性层,Softmax函数为:
P
(
y
=
i
)
=
e
Z
i
∑
j
=
0
K
−
1
e
Z
j
,
i
∈
{
0
,
.
.
.
,
K
−
1
}
P(y=i)=\frac{e^{Z_i}}{\sum_{j=0}^{K-1}e^{Z_j}},i\in\{0,...,K-1\}
P(y=i)=∑j=0K−1eZjeZi,i∈{0,...,K−1},采用交叉熵损失函数计算损失。
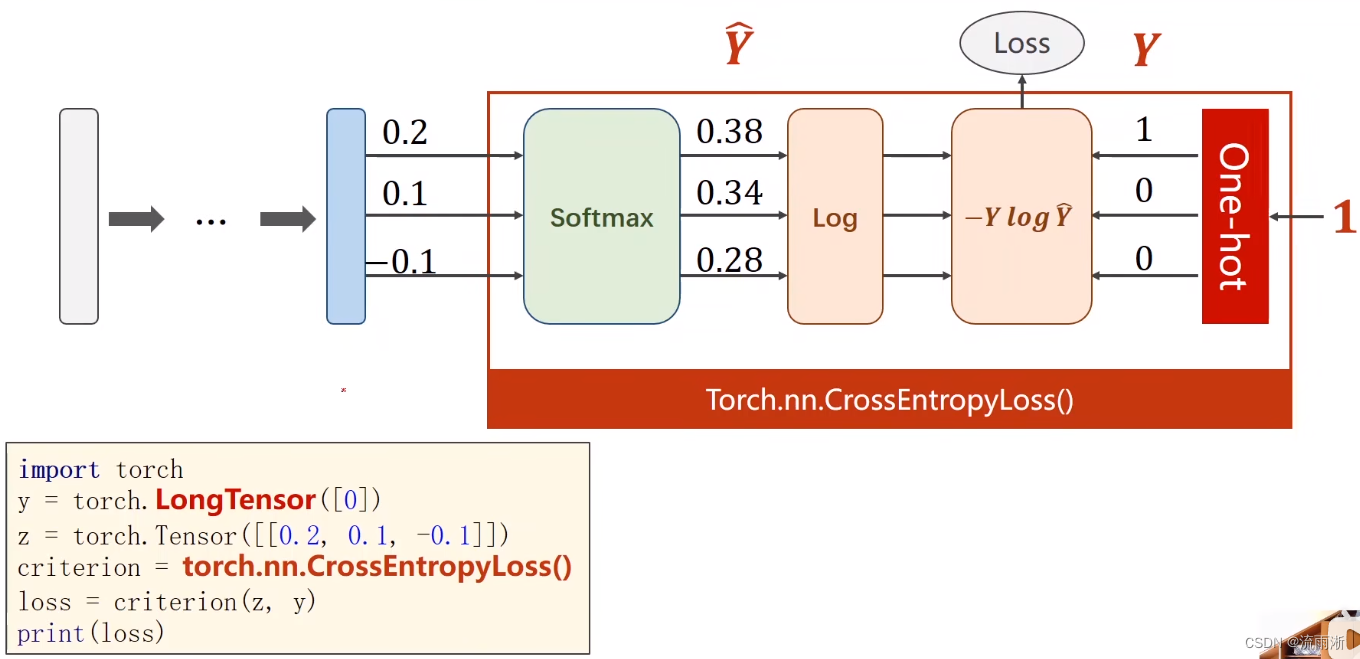
模型:输入的是图像,激活层改用ReLU,最后的输出层不做激活,由交叉熵损失算softmax。
代码
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import torch.nn.functional as F
import torch.optim as optim
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) # 归一化,均值和方差
train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 784) # -1表示自动计算总元素数量,确保总元素数量保持不变,784表示转换为784列的矩阵
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x)
model = Net()
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
epoch_list = []
accuracy_list = []
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, targets = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
def ceshi():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
print('accuracy on test set: %d %% ' % accuracy)
accuracy_list.append(accuracy)
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
ceshi()
epoch_list.append(epoch)
plt.plot(epoch_list, accuracy_list)
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.show()
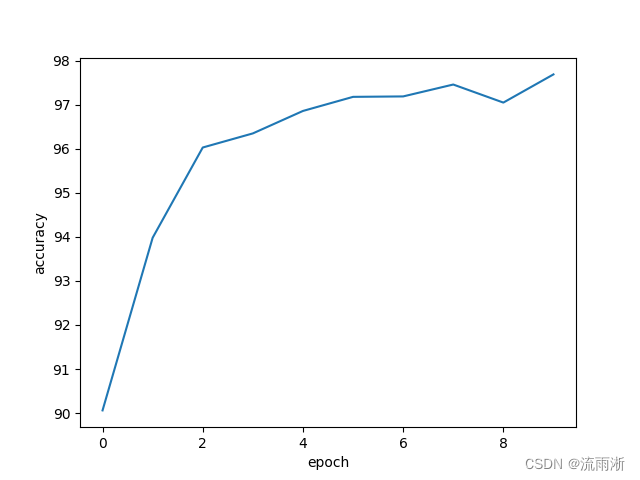
结果图如下:


















 6091
6091

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











