










算法演示和完整代码见文末,下一期将带来NLP的经典Word2Vec算法。若需转载请注明来源,谢谢。
-
简要介绍
-
部分理论
-
数据清单
-
工程复现
-
结果演示
-
优化展望
简要介绍
最近忙着上线推荐业务,以后再更新Word2Vec,根据业务的embedding数据,许多算法工程师为了加速模型训练会采用各种降维手段,在此将PCA部分理论融入自己的知识进行工程复现,内容涉及使用基本运算库实现数据标准化、PCA降维等。
部分理论
Name: Normalization
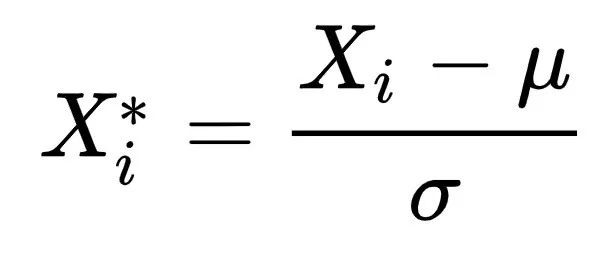
Model: Principal Component Analysis
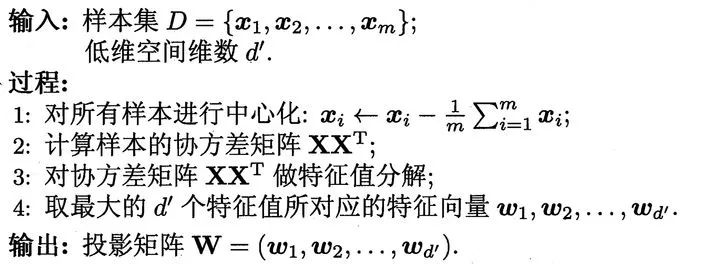
数据清单
在线手写数字图像数据集
dataset.zip:包含1797行,64列特征列(仅采用特征列),1列标签列
Fig.2 Partial images set display
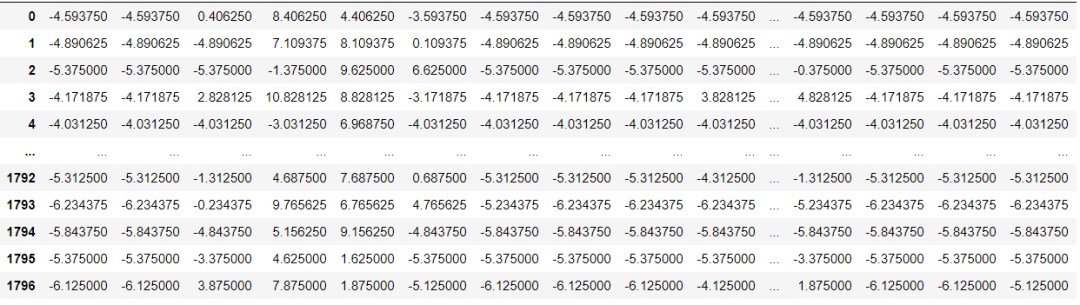 Fig.3 Partial feature set display
Fig.3 Partial feature set display
工程复现
配置基本需求库
""" Import the basic requirements package """
import time
import math
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits配置数据集导出函数
""" Dataset export function """
def read_csv():
X, y = load_digits(return_X_y=True)
print(X.shape) # Print feature set and label set length
return X配置数据标准化函数
""" Dataset Normalization function """
def normalization(X):
columns = 'col_' + pd.Series(np.arange(1, 1 + X.shape[1]).astype(str)).values
data = pd.DataFrame(X, columns=columns)
data = pd.DataFrame(data.apply(lambda x_row: (x_row - np.mean(x_row)) / math.sqrt(np.var(x_row)), axis=1).values, columns=columns)
return data.values配置协方差计算函数
""" Dataset Covariance function """
def covariance(X):
X_cov = np.cov(np.transpose(X))
return X_cov配置特征值、特征向量计算函数
""" Dataset Eig function """
def eig_values(X):
a, b= np.linalg.eig(X)
X_eig = pd.DataFrame()
X_eig['Lambda'] = a
X_eig['Beta_i'] = np.arange(X.shape[0])
X_eig['Beta'] = X_eig['Beta_i'].apply(lambda i: b[i])
X_eig.sort_values(by='Lambda', ascending=False)
return X_eig配置PCA算法函数
""" PCA model function """
# create model
def PCAVectorizer(decomposition=10):
pca_params = {
'decomposition': decomposition, # Set the base of the idf logarithm
}
return pca_params
# fit model
def fit_transform(pca_params, X):
X = normalization(X)
X_cov = covariance(X)
X_eig = eig_values(X_cov)
X_eig = np.vstack(X_eig.sort_values(by='Lambda', ascending=False)[ :pca_params['decomposition']]['Beta'].values)
pca_X = np.transpose(np.dot(X_eig, np.transpose(X)))
columns = 'col_' + pd.Series(np.arange(1, 1 + pca_params['decomposition']).astype(str)).values
submit = pd.DataFrame(pca_X, columns=columns)
print(submit.head(20))
return pca_X配置训练主进程
""" PCA model training host process """
if __name__ == '__main__':
sta_time = time.time()
X = read_csv()
model = PCAVectorizer(decomposition=6)
pca_X = fit_transform(model, X)
print("Time:", time.time() - sta_time)结果演示
Fig.4 Results of the algorithm
优化展望
在本次复现的结果中,可以观察到结果有两个以上可以优化的方向。
-
在本次降维中并没有降维效果评估指标,通常可以采用累计方差贡献率来评价降维效果。
-
PCA降维算法是线性降维算法,可以通过采用类似SVM中的非线性Kernel进行非线性降维或者采用如LLE非线性降维算法等进行非线性降维。
完整代码
结尾扫码关注精彩的公众号!后台回复"PCA"获取完整代码
参考链接
Digits
Cvcr
Kpca
LLe

扫描二维码获取更多算法前沿知识和精彩
筝自然语言处理和推荐算法

















 2993
2993

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









