








 超级会员免费看
超级会员免费看

什么是文本聚类?
文本聚类是将一个个文档由原有的自然语言文字信息转化成数学信息,以高维空间点的形式展现出来,通过计算那些点距离比较近来将那些点聚成一个簇,簇的中心叫做簇心。一个好的聚类要保证簇内点的距离尽量的近,但簇与簇之间的点要尽量的远。
文本聚类的难点是什么?
聚类是一种非监督学习,也就是说聚成几类,怎么聚,我们都不知道,只能一点点试出来。但是有时候机器认为这两堆点可以认为是两个簇,但人理解可能是一个簇,文本聚类就就难在了这里,机器与人的理解不太一样。一般能看到这个博的人都学过基本的聚类算法,拿k-means为例,簇心的选取是个非常随机的过程,导致k值相同的情况下聚类的结果每次都不一样,又不好取个平均,所以聚类的好坏很难被评价出来。
如何评价聚类的好坏?
http://blog.csdn.net/chixujohnny/article/details/51852633 中讲到完爆一切的S_Dbw评价指标,我目前还没试过,有兴趣的同学可以试试,总之早晚都要用的。
文本聚类过程
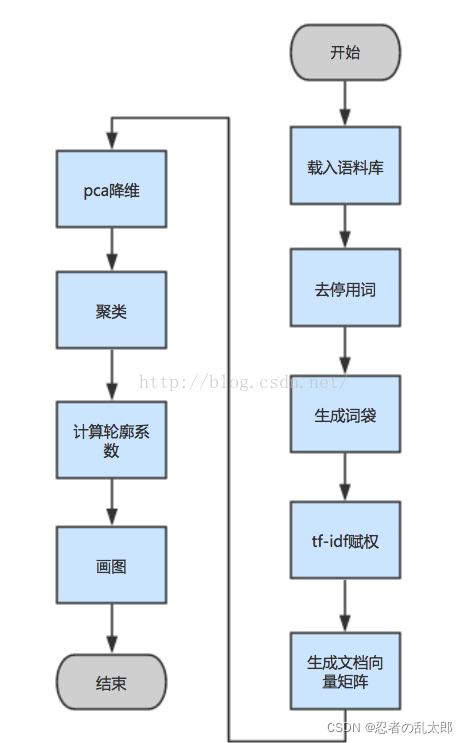
词赋权方法还有textrate,还没用,jieba自带的,肉眼看不错,可以试试。
上面的图说几个部分,一般生成
 订阅专栏 解锁全文
订阅专栏 解锁全文















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









