







机器学习之误差
1.误差来源
- Error(误差)= Variance(方差)+ Bias(偏差)
- Error反映的是整个模型的准确度,Bias反映的是模型在样本上的输出与真实值之间的误差,即模型本身的精准度,Variance反映的是模型每一次输出结果与模型输出期望之间的误差,即模型的稳定性
2.误差估测
f(x;D)为训练集D中的x对模型f的输出, y D y _{D} yD为模型在数据集中的标记,y为x的真实标记
-
期望:
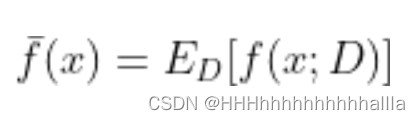
-
方差:
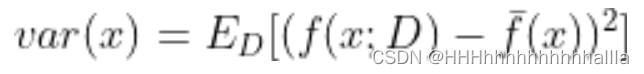
-
偏差:

3.误差与模型
3.1 误差与模型关系
简单模型方差小,偏差大
复杂模型方差大,偏差小
3.2 常见问题
欠拟合:偏差较大造成的误差
过拟合:方差较大造成的误差(在训练集上得到很小的错误,但在测试集上得到大的错误)
3.3 解决方案
欠拟合:1)更换训练集,使用更合适的训练集;2)重新设计模型,将更多特征考虑进去或者更高次函数
过拟合:使用更多的训练数据
4.模型选择
4.1 目的
在方差与偏差中作权衡,选择出一个模型可以很好的平衡偏差与方差产生的错误,使得总错误最小。
4.2 方法
- 交叉验证:将训练集分为两部分,一部分作为训练集,一部分作为验证集。用训练集训练模型,然后再验证集上比较,选出最好的模型后(比如模型3),再用全部的训练集训练最好的模型(模型3),然后再用public的测试集进行测试,此时一般得到的错误都是大一些的。
- N-折交叉验证:就是将训练集分成k份,每次取其中一份作为验证集,另外 k-1 份作训练集。这样进行 k 次训练得到 k 个模型。这 k 个模型对各自的验证集进行预测,得到 k 个评估值,选出最好的模型后(比如模型3),再用全部的训练集训练最好的模型(模型3),然后再用public的测试集进行测试。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









