







局部最小值与鞍点
当使用梯度下降法时,通常会在遇到梯度为0的地方停下来,而局部最小值点(local minima)和鞍点(saddle point)的梯度都为0,统称critical point,但鞍点并非满足我们要求的点。
1.优化失败的原因
当参数的梯度为0时,导致参数无法正常更新,使得loss function无法下降。
- local minina
- saddle point
2.判断方法
loss function用泰勒展开,可近似等于:
L
(
θ
)
=
L
(
θ
′
)
+
(
θ
−
θ
′
)
T
g
+
1
2
(
θ
−
θ
′
)
T
H
(
θ
−
θ
′
)
L(\theta)=L(\theta^{'})+(\theta-\theta^{'})^{T}g+\frac{1}{2} (\theta-\theta^{'})^{T}H(\theta-\theta^{'})
L(θ)=L(θ′)+(θ−θ′)Tg+21(θ−θ′)TH(θ−θ′)
其中,
g
=
▽
L
(
θ
′
)
g=\triangledown L(\theta^{'})
g=▽L(θ′),
g
i
=
∂
L
(
θ
′
)
∂
θ
i
g_i=\frac{\partial L(\theta^{'})}{\partial \theta_i}
gi=∂θi∂L(θ′),
H
i
j
=
∂
2
∂
θ
i
∂
θ
j
H_{ij}=\frac{\partial ^2}{\partial \theta_i\partial \theta_j}
Hij=∂θi∂θj∂2
当梯度为0时,有:
L
(
θ
)
=
L
(
θ
′
)
+
1
2
(
θ
−
θ
′
)
T
H
(
θ
−
θ
′
)
L(\theta)=L(\theta^{'})+\frac{1}{2} (\theta-\theta^{'})^{T}H(\theta-\theta^{'})
L(θ)=L(θ′)+21(θ−θ′)TH(θ−θ′)
令
v
=
(
θ
−
θ
′
)
v=(\theta-\theta^{'})
v=(θ−θ′),有

即
- 当H为正定矩阵,所有特征值为正时,为local minima
- 当H所有特征值为负时,为local maxima
- 当H的特征值有正有负时,为saddle point
3.更新方向
令
u
=
(
θ
−
θ
′
)
u=(\theta-\theta^{'})
u=(θ−θ′),其中
u
u
u是
H
H
H的特征向量,
λ
\lambda
λ是
u
u
u的特征值
当
λ
<
0
\lambda<0
λ<0时,有:
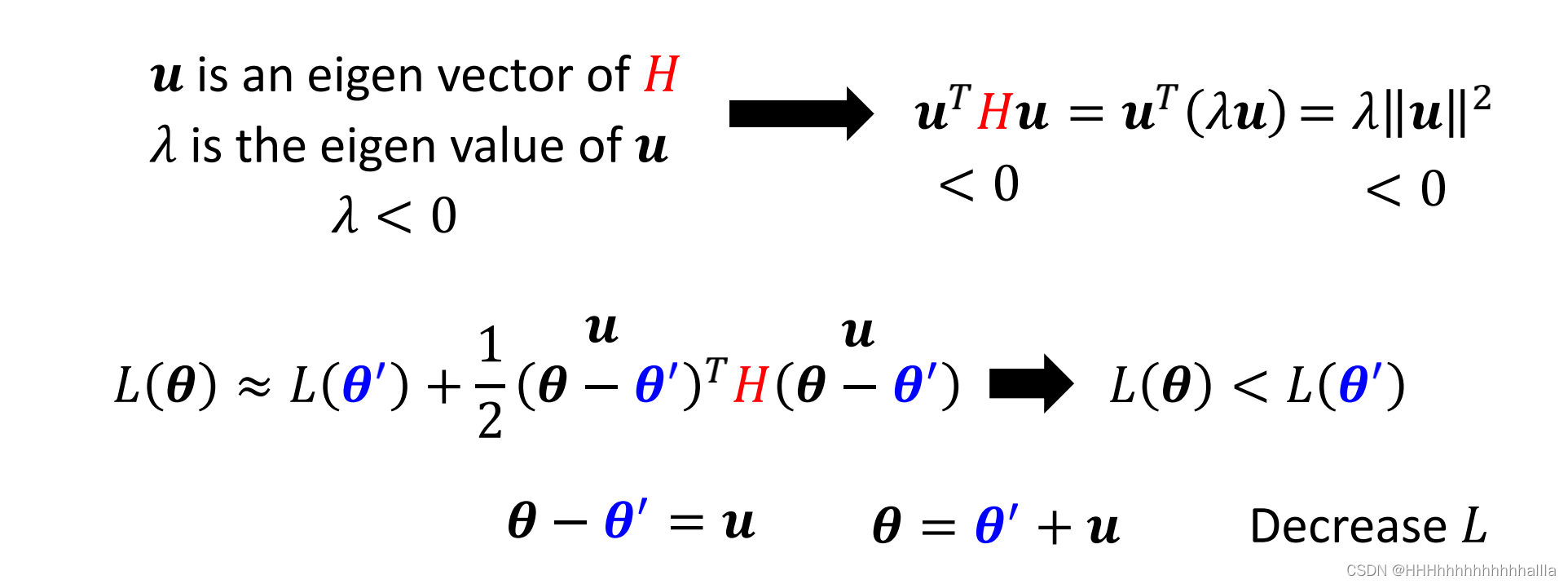
即沿着
u
u
u的方向,可使loss function继续减小。
批次与动量
Small Batch and Momentum可以帮助我们解决critical point(梯度为0的点)
1.批次(batch)
- 实际实践中,并不是一次性使用全部的数据集进行优化,而是将全部的数据集分成许多个 b a t c h batch batch,依次用这些 b a t c h batch batch进行参数更新,更新完所有 b a t c h batch batch称为一次 e p o c h epoch epoch,每一次 e p o c h epoch epoch都会将所有 b a t c h batch batch打乱,称为 s h u f f l e shuffle shuffle。
- small batch 对比big batch
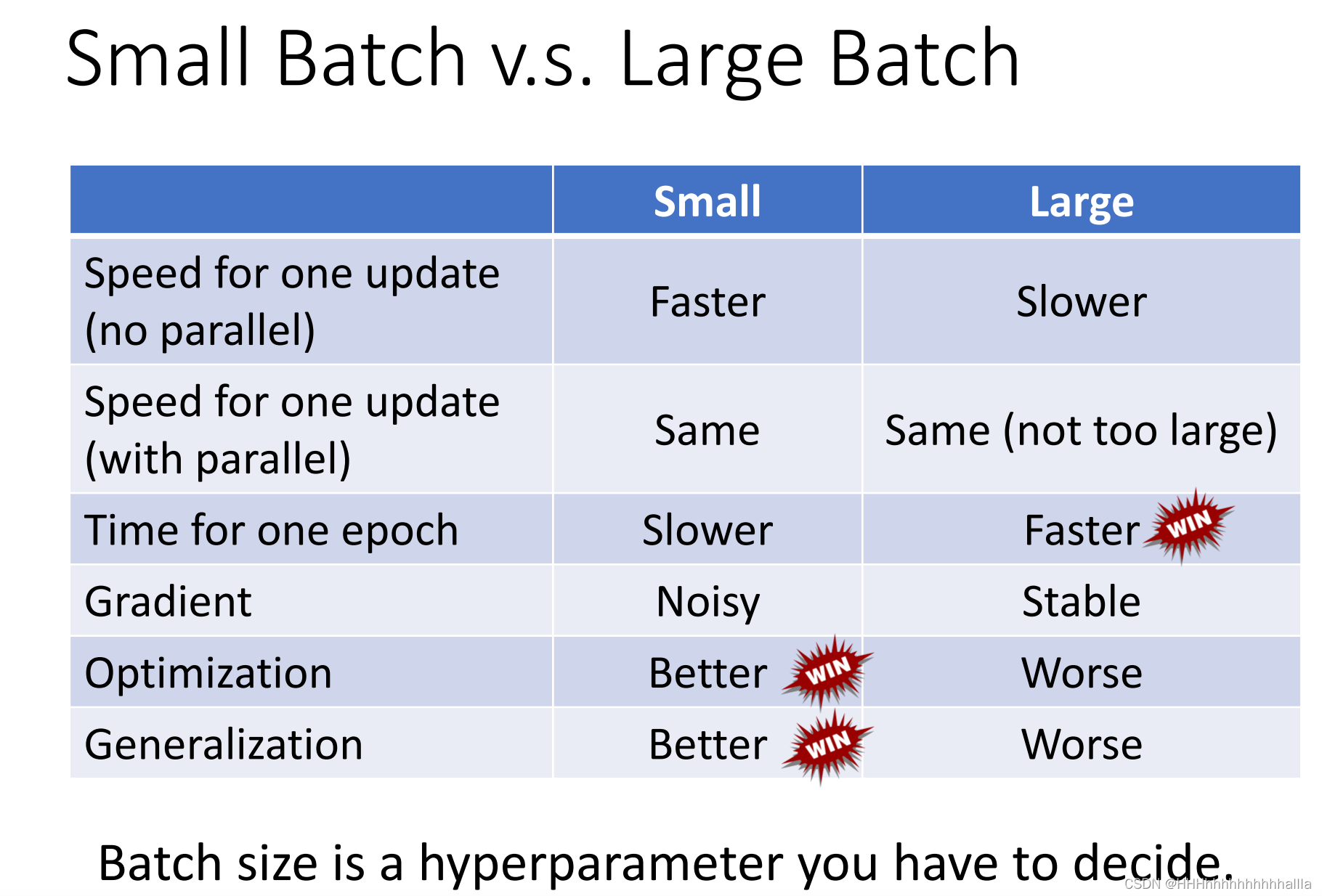
总结:
1)更大的batch不一定会比小batch计算时间长很多,因为有gpu加速和并行运算(除非size非常非常大)
2)big batch的优化过程更加平滑,而small batch优化过程有许多noisy,但是在训练时,这种noisy反而使得优化结果表现得更好
2.动量(Momentum)
动量(Momentum)可以简单理解为运动过程中的惯性力。
一般情况下,都是往梯度的反方向更新:
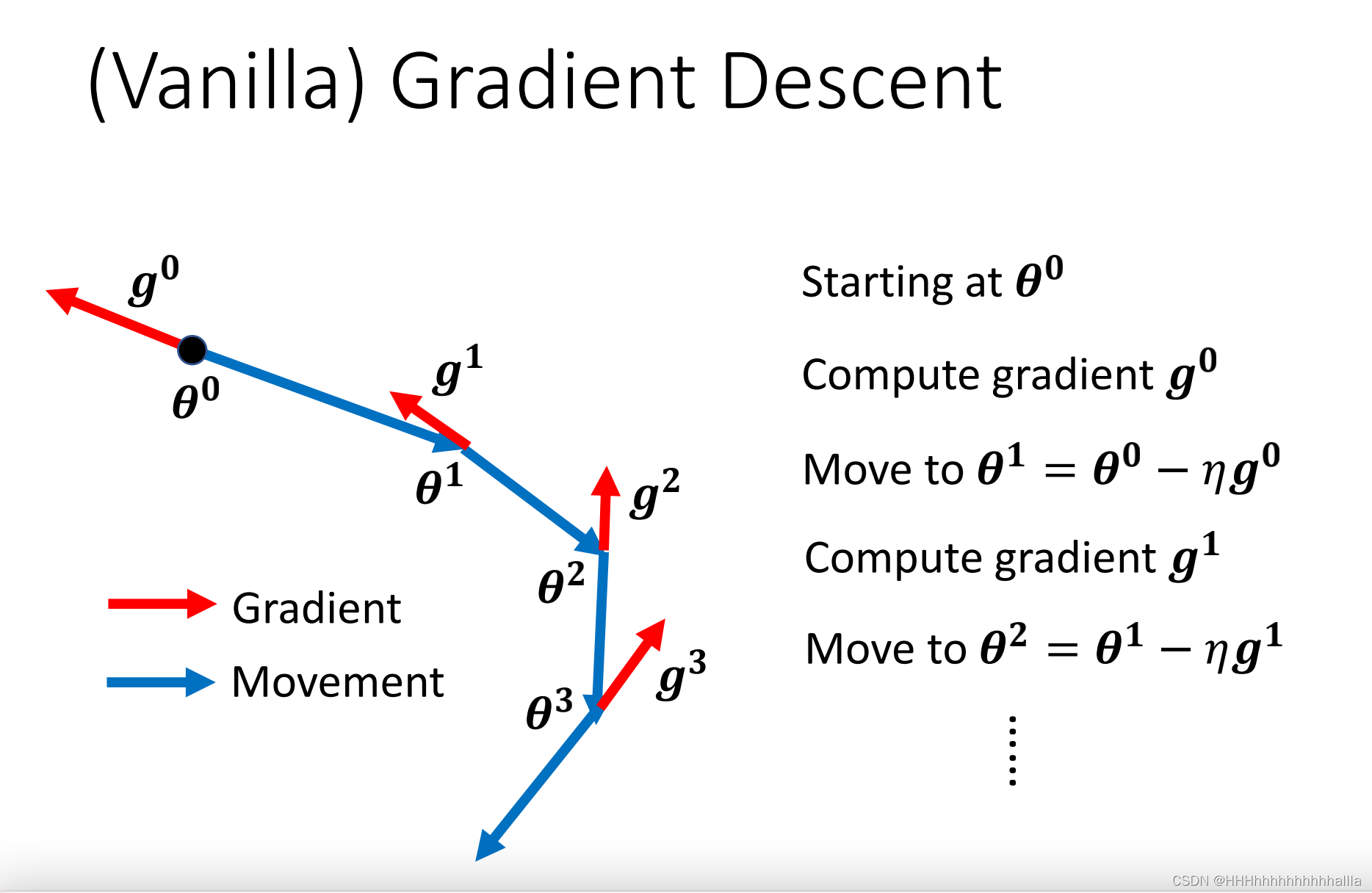
Gradient Descent + Momentum就是不仅考虑了梯度方向还考虑了上一步更新的方向,新的方向即为两个方向的合方向:
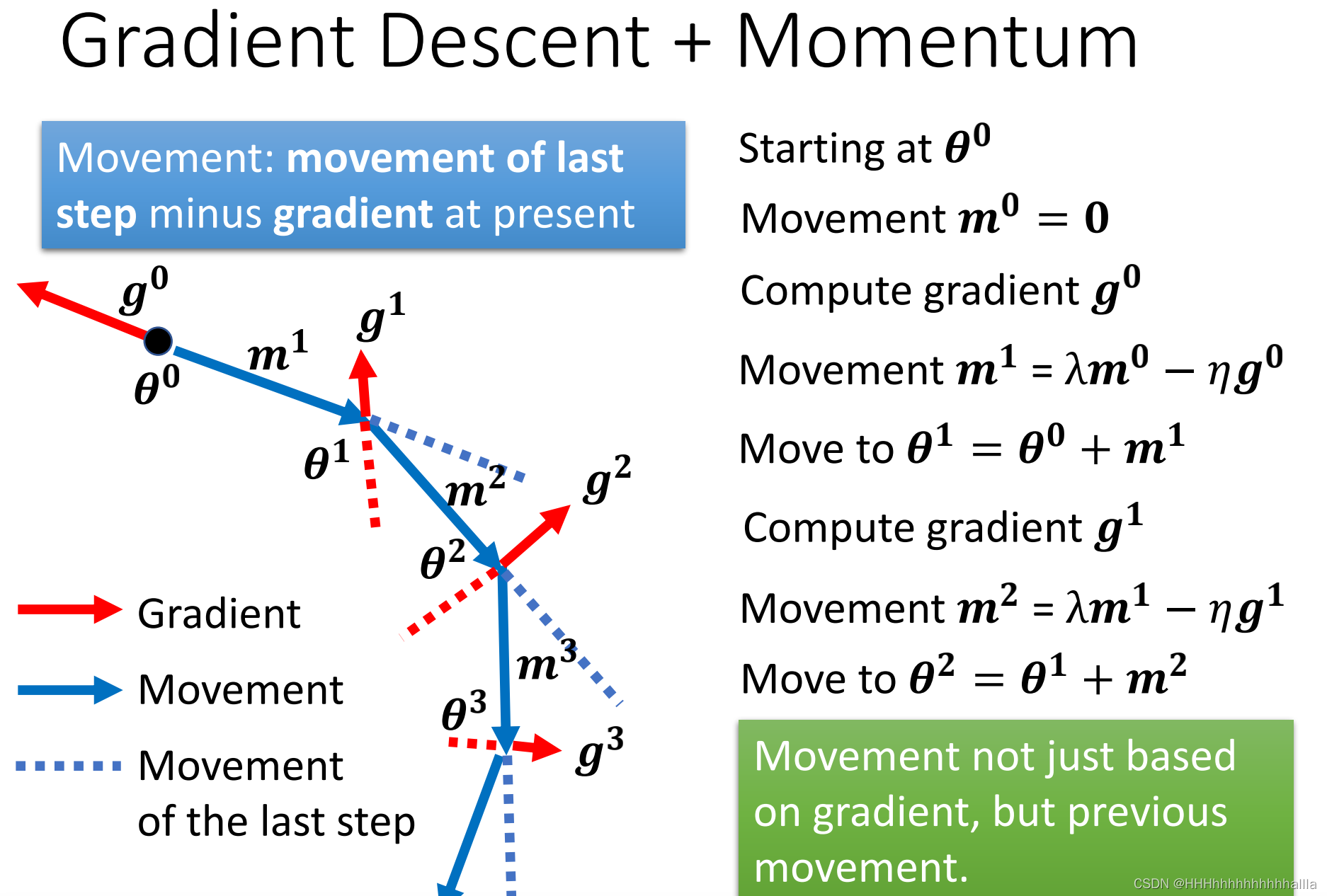
这样做的好处是:可以通过参数控制对计算出来的梯度的weight和上一步的weight。
动态调整学习率
有时候更新卡住并不是因为critical points,而是因为学习率设置的不合理,不同的参数应该设置不同的学习率
-
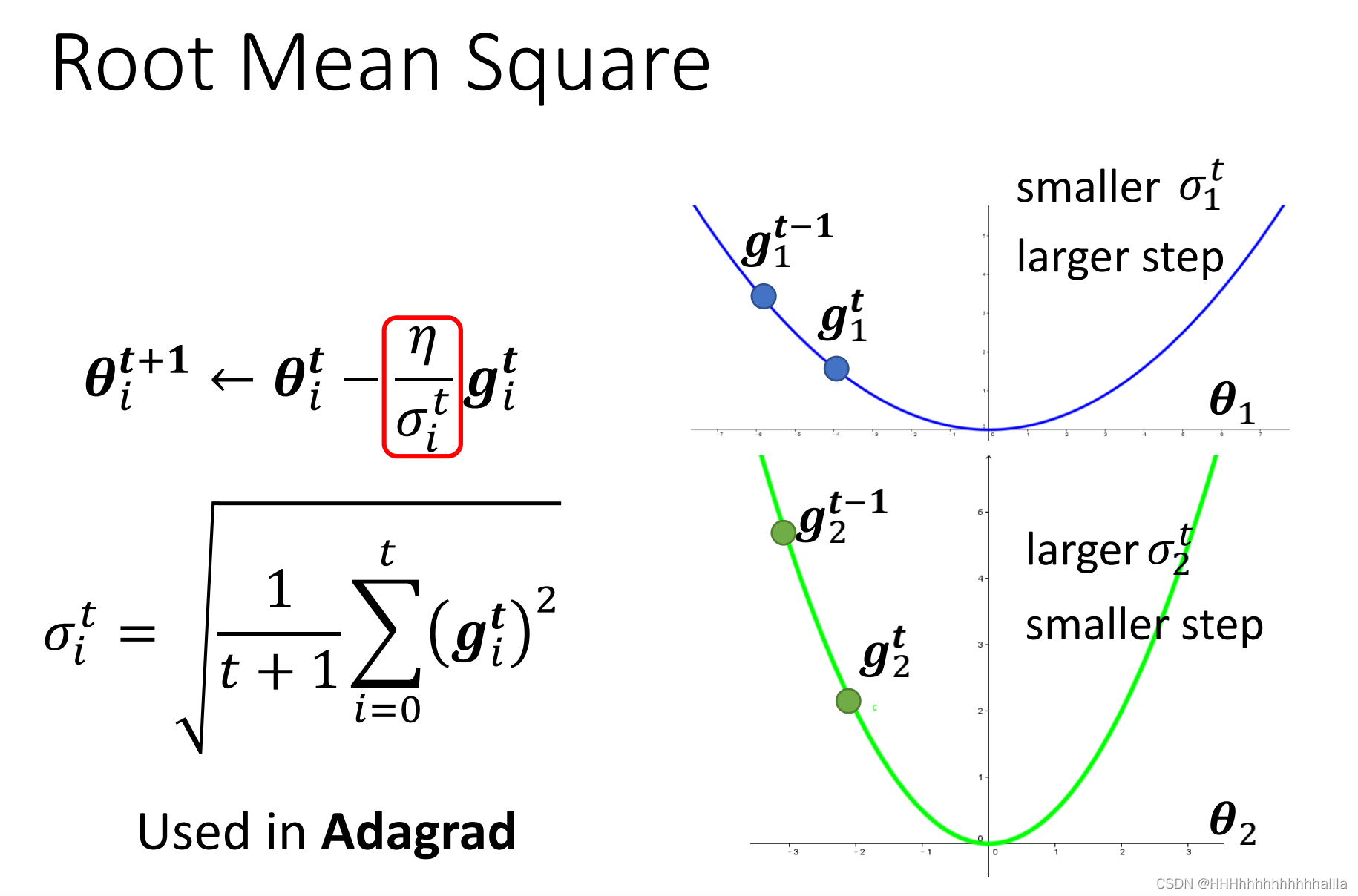
方法一:Root Mean Square
每次优化的学习率(步长)与时间(次数)相关,即一开始离local minima距离远,学习率大;随着时间增加,离local minima的距离变小,减小学习率
-
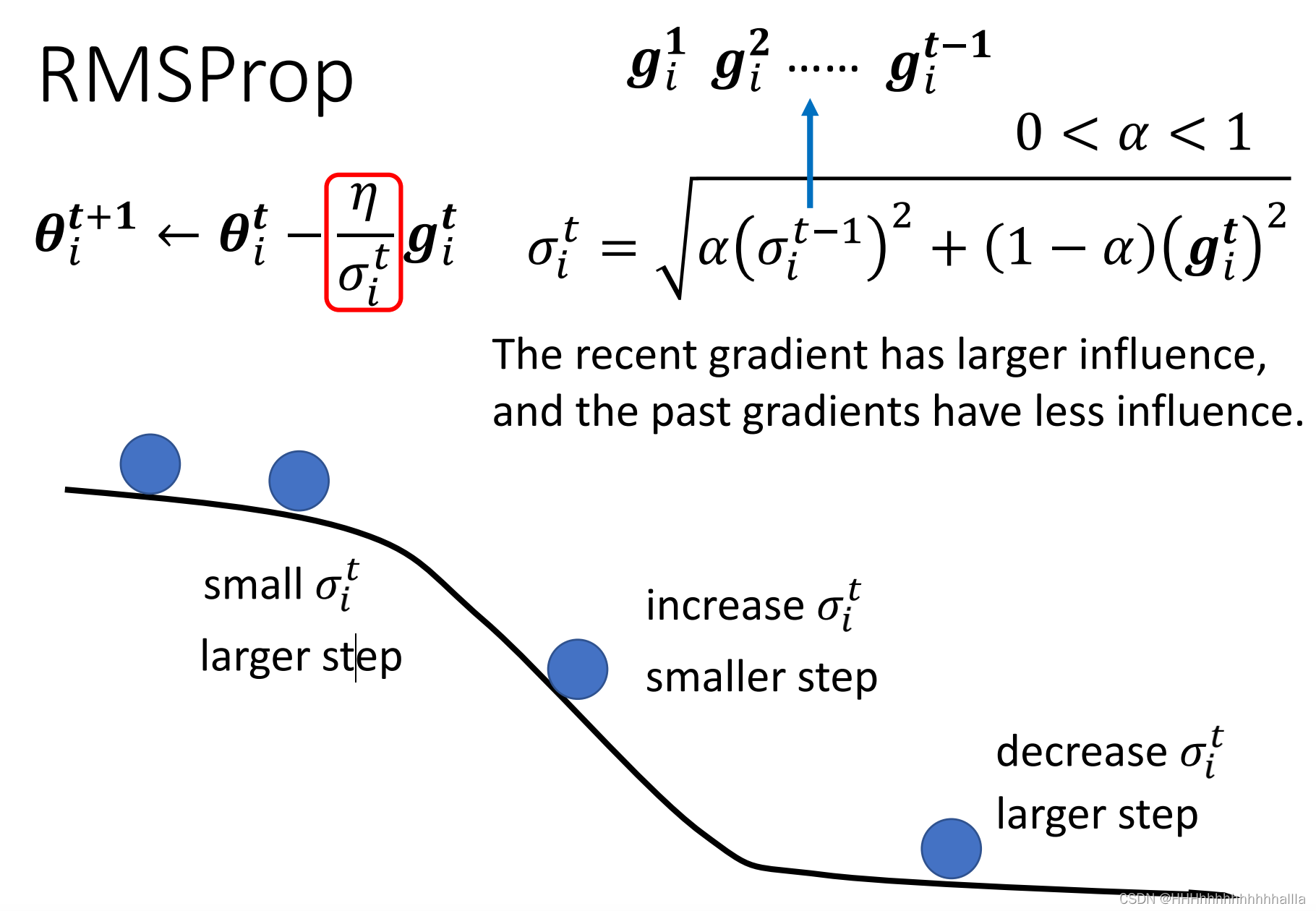
方法二:RMSProp
不仅有方法一的优点,还增加了对历史梯度和当前梯度weight,对数据会更敏感
-
方法三:Learning Rate Scheduling
-
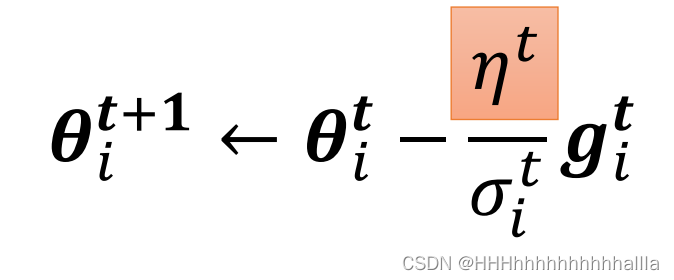
-
Learning Rate Decay:在训练开始之后,逐步接近目标, η t \eta^t ηt随 t t t减小
-
Warm Up:在训练开始,数据量较少,计算较差, η t \eta^t ηt一开始较小,随着数据增加,可信度变高, η t \eta^t ηt增大,又随着靠近目标点, η t \eta^t ηt减小
总结

损失函数的影响
机器学习的问题大致可以分为:分类与回归,主要的不同在输出部分,其二者的本质是一样,不过分类是对回归的结果再离散化。
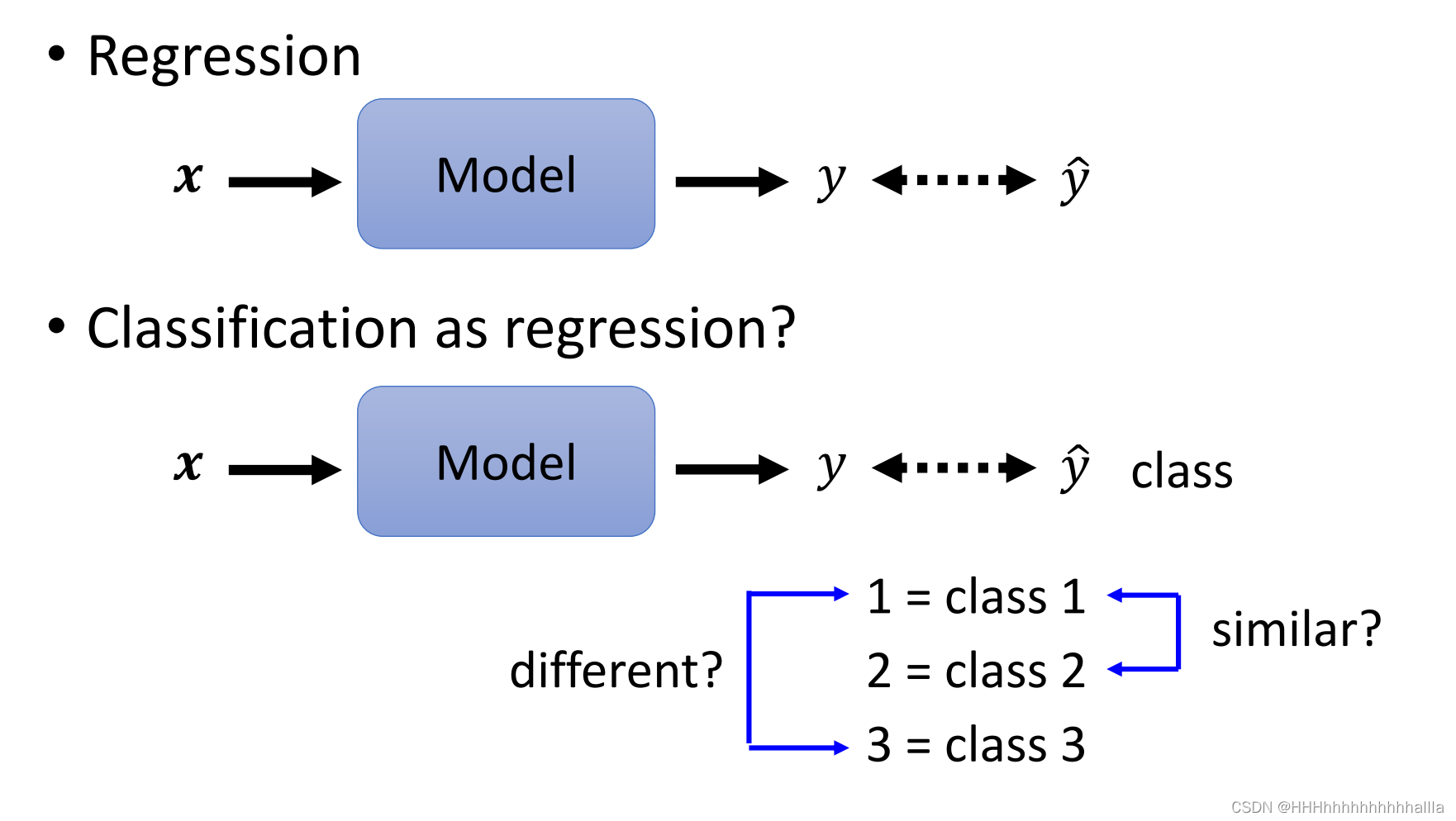
- 分类的loss function
L = 1 N ∑ n e n L= \frac{1}{N}\sum_{n}e_n L=N1n∑en
若采用MSE(Mean Square Error): L = ∑ i ( y i ^ − y ′ i ) 2 L= \sum_{i}( \hat{y_i}-{y^{'}}_i)^2 L=i∑(yi^−y′i)2
若采用交叉墒(Cross-entropyr): L = − ∑ i ( y i ^ ln y ′ i ) L= -\sum_{i}( \hat{y_i}\ln{y^{'}}_i) L=−i∑(yi^lny′i)
注:不同的loss function对优化的难易程度影响不一样
Batch Normalization
Batch Normalization(批量准化), 和普通的数据标准化类似, 是将分散的数据统一的一种做法,也是优化神经网络的一种方法,具有统一规格的数据, 能让机器学习更容易学习到数据之中的规律
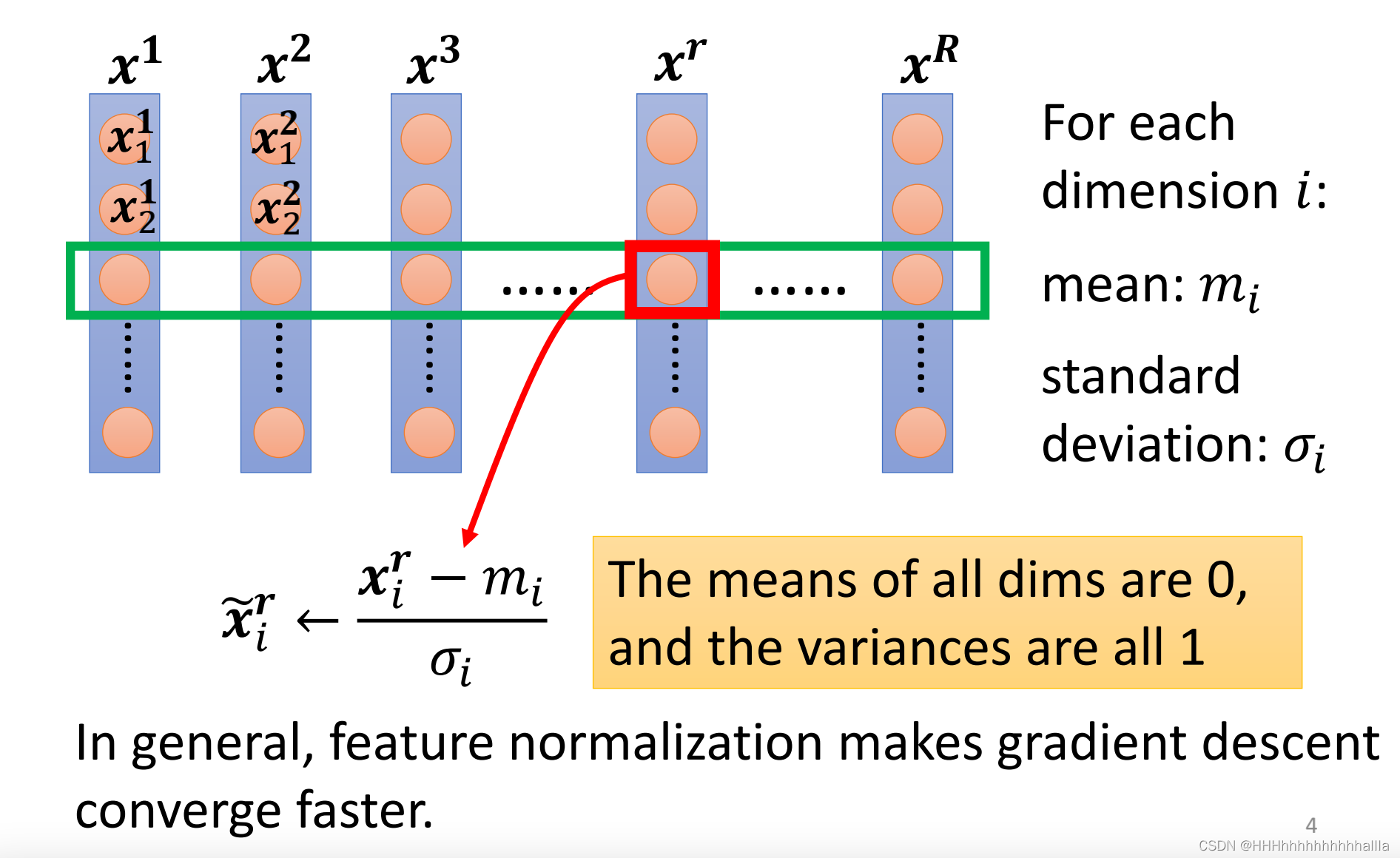
1.Feature Scaling
如果特征大小差的比较远的话,loss function会很扁平,数值更大的feature的参数会对结果的影响更大,这样在训练过程中,不同的方向需要设定不同的学习率,这样子会不太方便,所以我们通常会去做feature scaling,即:对每一维特征,我们对每一个数据减去这维特征的均值,再除以这位特征的标准差,得到缩放后的新的特征值,此时它的均值为0,方差为1。一般经过feature scaling之后,收敛速度会变快。
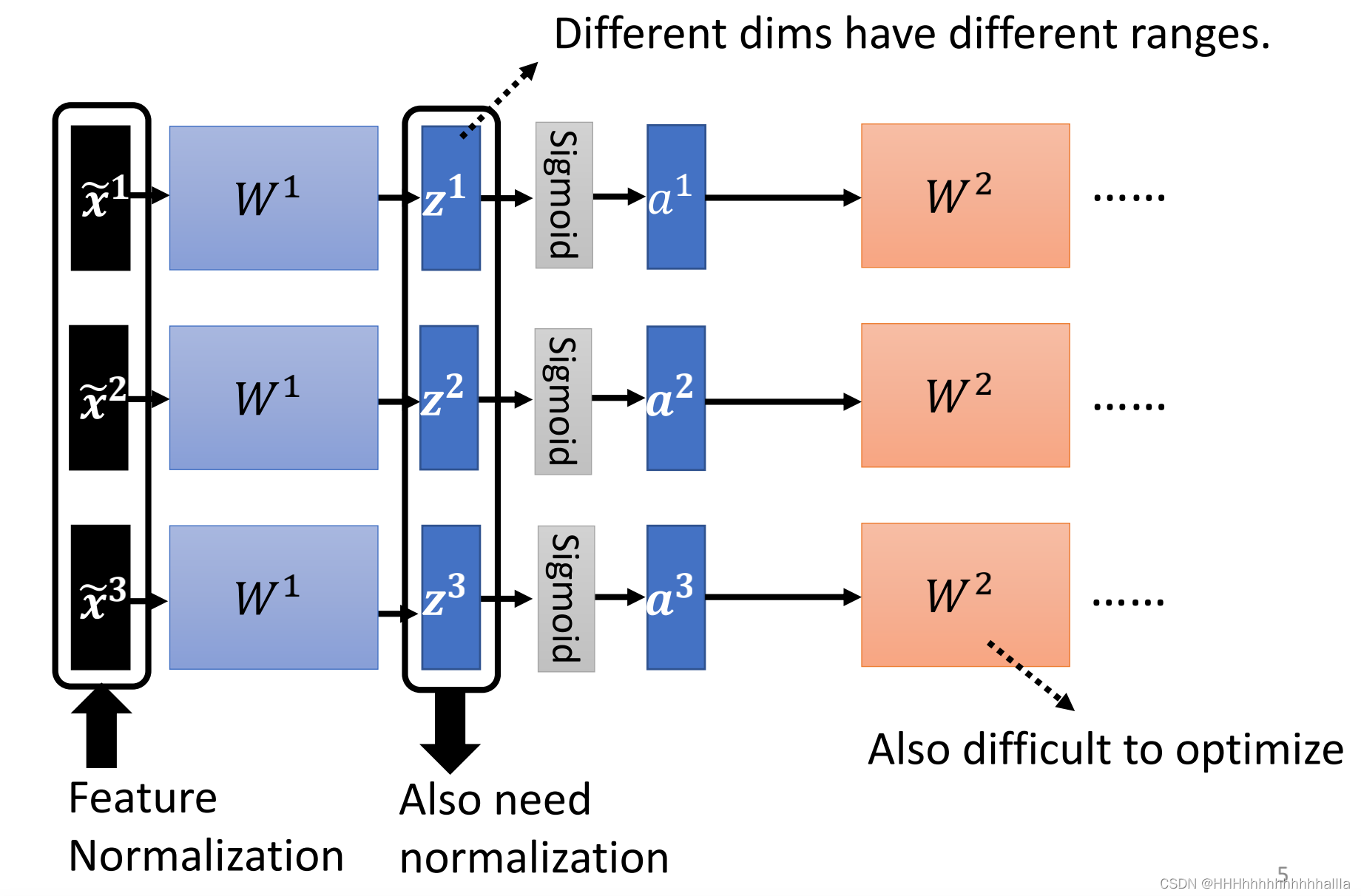
2.Batch Normalization
在机器学习中,我们不仅只对输入层进行Normalization,而是对每一层的输入进行Normalization,这就包括了input layer和所有的hidden layer。
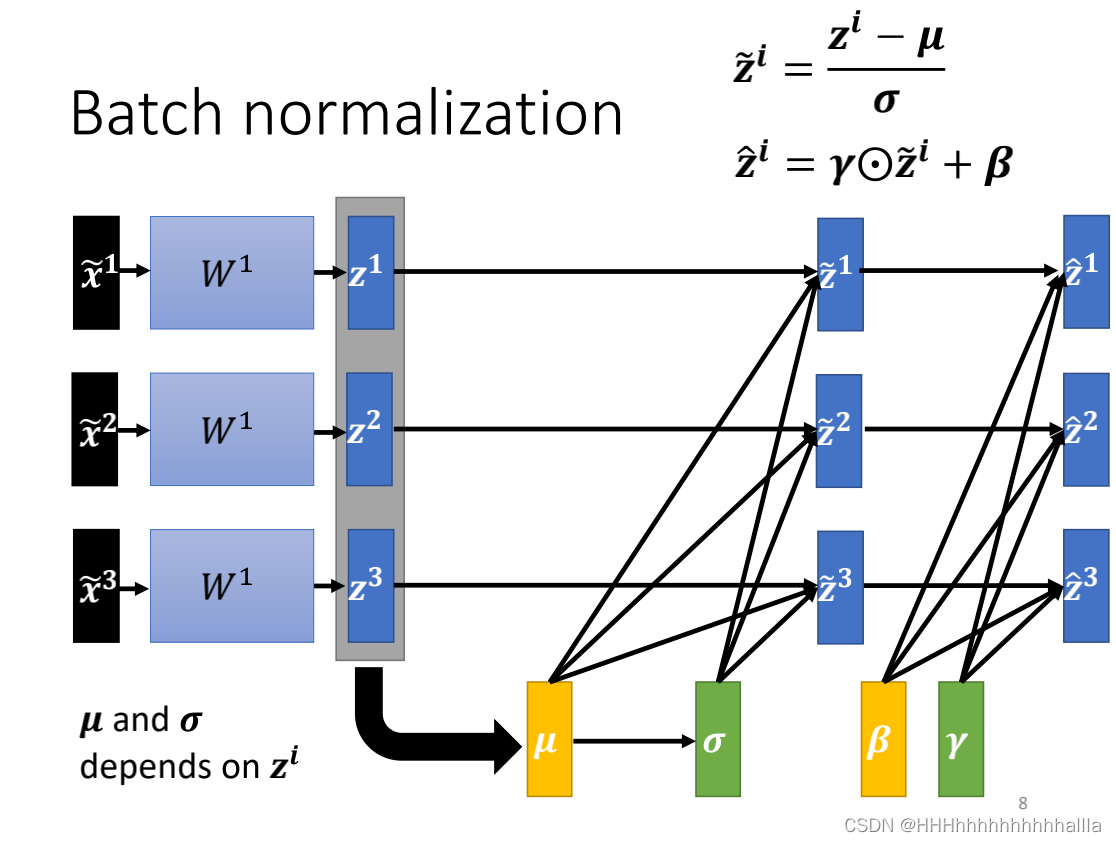
- 具体做法:
对每一层的输入参数计算均值 μ \mu μ和标准差 σ \sigma σ,然后对每一个参数进行如下计算:
z ~ i = z i − μ σ \widetilde{z}^i= \frac{z^i-\mu}{\sigma} z i=σzi−μ
在这个基础上,可以对 z ~ i \widetilde{z}^i z i继续做一些变换:

其中 λ \lambda λ和 β \beta β都是参数
- 所遇问题:训练完神经网络,到了测试的时候,会出现一个问题, z ~ i \widetilde{z}^i z i是通过一个batch的均值 μ \mu μ和标准差 σ \sigma σ 算出来的,但是测试的时候是没有batch的,那么这两个参数怎么来呢?
- 解决方法:把过去训练时每个batch算出来的 均值
μ
\mu
μ和标准差
σ
\sigma
σ都保存下来,然后对这些 均值
μ
\mu
μ和标准差
σ
\sigma
σ做加权平均,给最后几次训练的 均值
μ
\mu
μ和标准差
σ
\sigma
σ更大的权重,因为此时的参数更接近于完成的模型。
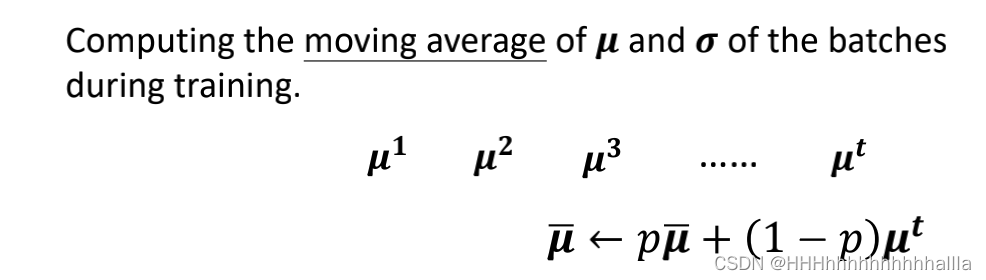
- 优点:解决了Internal Covariate Shift问题,即中间层数据分布发生改变的问题















 260
260











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









