






 本文详细介绍了原子操作在多线程编程中的优势,如不占用中断、资源效率高,以及与Mutex等并发原语的对比。作者通过示例展示了如何在STM32WLE上使用原子操作,并分析了不同优化级别下的性能差异,讨论了乐观锁和悲观锁的原理及适用场景。
本文详细介绍了原子操作在多线程编程中的优势,如不占用中断、资源效率高,以及与Mutex等并发原语的对比。作者通过示例展示了如何在STM32WLE上使用原子操作,并分析了不同优化级别下的性能差异,讨论了乐观锁和悲观锁的原理及适用场景。
原子操作
1.概述
原子操作很好用,在两三个小线程要同步变量时,不占用中断,也不过度占用资源。如果使用Mutex等并发原语进行这些优化,虽然可以解决问题,但是这些并发原语的实现逻辑比较复杂,对性能还是有一定的影响的。atomic包提供的方法会提供内存屏障的功能,atomic不仅仅可以保证赋值的数据完整性,还能保证数据的可见性,一旦一个核更新了该地址的值,其它处理器总是能读取到它的最新值。
原子操作常用的三个操作有load,store,exchange。load方法会取出addr地址中的值;store方法会把一个值存入到指定的addr地址中;如果不需要比较旧值,只是比较粗暴地替换的话,就可以使用exchange方法,它替换后还可以返回旧值。
2.使用
● 最简单的使用途径
替换NODE_CRITICAL_SECTION_BEGIN与NODE_CRITICAL_SECTION_END之间的变量操作代码;全局变量,且在不同线程间同步才有意义
● 理解与使用
查看测试文件既可
● 测试代码在STM32WLE上验证通过;如下验证代码通过可证明原子操作的效果,不会使得变量在不同线程的操作下异常
static void ture_entry(void *parameter)
{
uint8_t arg = *(uint8_t *)parameter;
printf("ture_entry %d\r\n", arg);
int i;
for (i = 0; i < 1000000; i++)
{
rt_atomic_add(&count, 1);
}
osSemaphoreRelease(sem_t);
printf("ture_entry %d done\r\n", arg);
osThreadExit();
}
static void test_atomic_add(void)
{
size_t i;
sem_t = osSemaphoreNew(3, 0, &sem_attributes);
rt_atomic_store(&count, 0);
t1TaskHandle = osThreadNew(ture_entry, &arg1, &t1_attributes);
t2TaskHandle = osThreadNew(ture_entry, &arg2, &t2_attributes);
t3TaskHandle = osThreadNew(ture_entry, &arg3, &t3_attributes);
for (i = 0; i < 3; i++)
{
osSemaphoreAcquire(sem_t, osWaitForever);
}
i = rt_atomic_load(&count);
if(i == 3000000) {
printf("test_atomic_add success\r\n");
} else {
printf("test_atomic_add failed\r\n");
}
}
测试日志成功生效
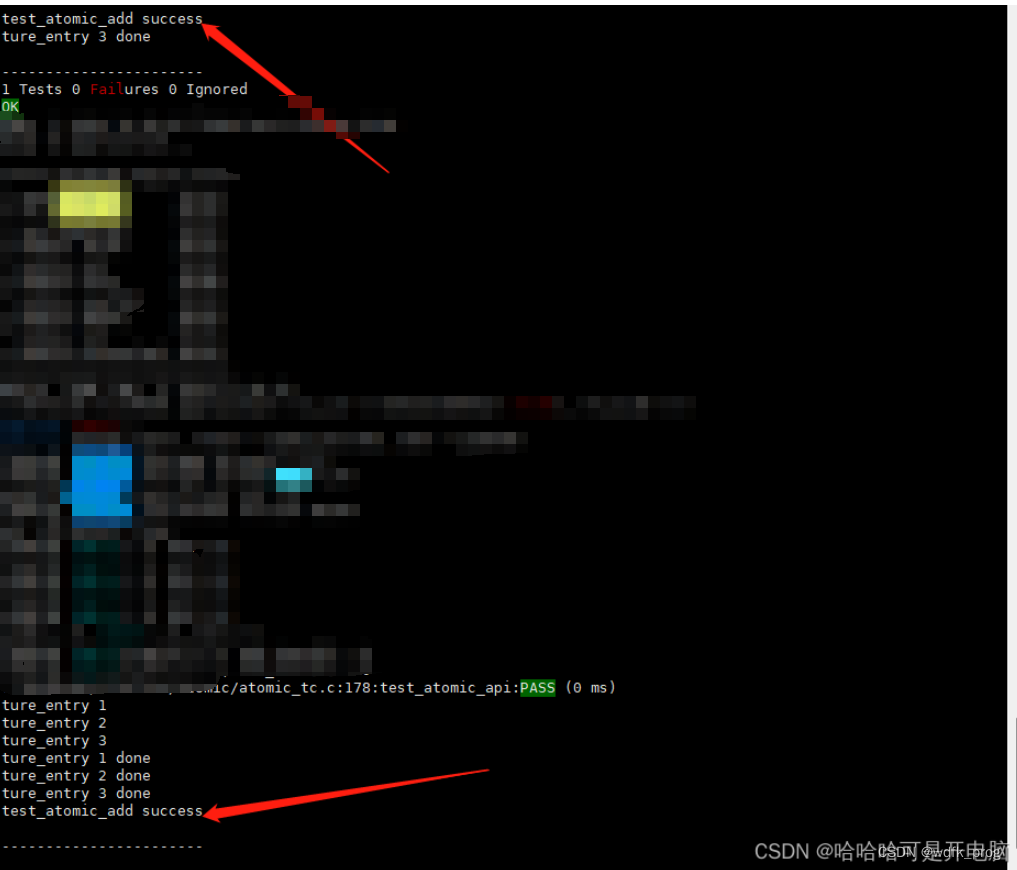
●修改测试代码如下,证明未经过原子操作与互斥操作;在线程间进行同步变量将会导致数据异常;
static void ture_entry(void *parameter)
{
uint8_t arg = *(uint8_t *)parameter;
printf("ture_entry %d\r\n", arg);
int i;
for (i = 0; i < 1000000; i++)
{
// rt_atomic_add(&count, 1);
__NOP(); //不添加会导致运行太快,另一个线程还未切换就结束
count++;
}
osSemaphoreRelease(sem_t);
printf("ture_entry %d done\r\n", arg);
osThreadExit(); //freertos线程结束必需调用该函数删除,否则调度异常
}
static void test_atomic_add(void)
{
size_t i;
sem_t = osSemaphoreNew(3, 0, &sem_attributes);
// rt_atomic_store(&count, 0);
count = 0;
t1TaskHandle = osThreadNew(ture_entry, &arg1, &t1_attributes);
t2TaskHandle = osThreadNew(ture_entry, &arg2, &t2_attributes);
t3TaskHandle = osThreadNew(ture_entry, &arg3, &t3_attributes);
for (i = 0; i < 3; i++)
{
osSemaphoreAcquire(sem_t, osWaitForever);
}
// i = rt_atomic_load(&count);
i = count;
if(i == 3000000) {
printf("test_atomic_add success\r\n");
} else {
printf("test_atomic_add failed\r\n");
}
}
测试日志打印;可以看到每次运行结果不同
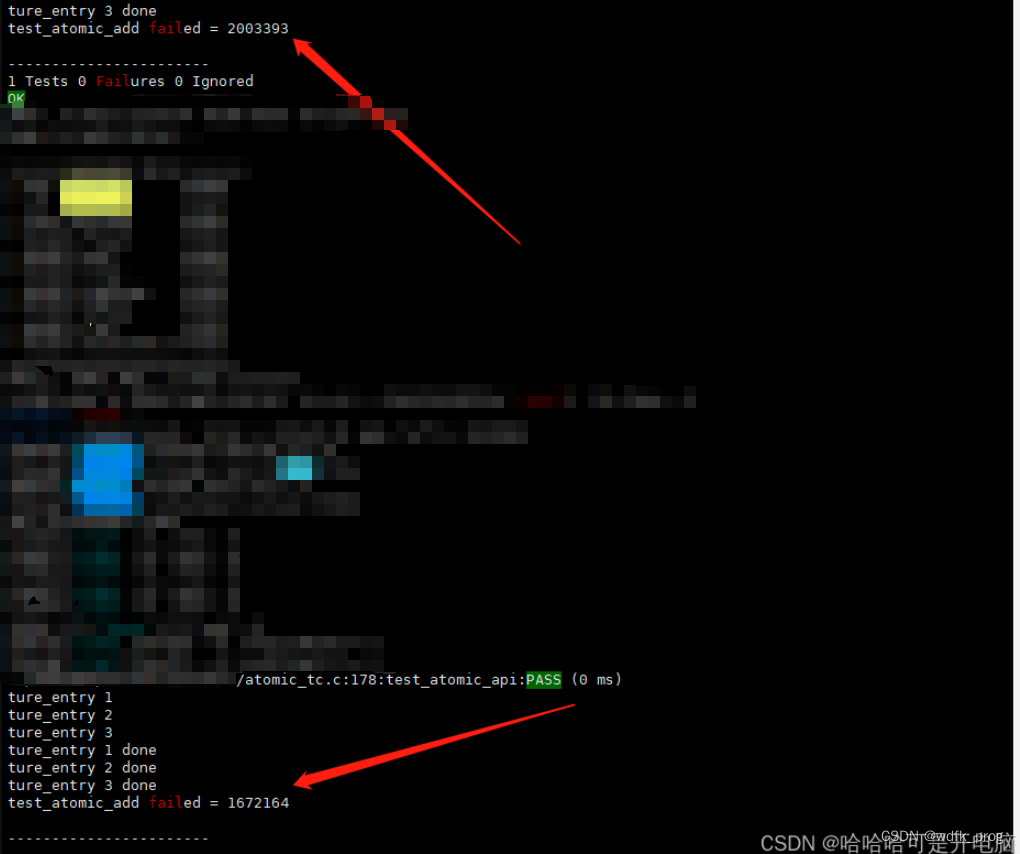
3.对比
将测试代码中test_atomic_add函数进行替换处理对比结果如下
1.使用STM32WLE 8MHZ主频 -OS优化
| ROM(与无处理对比) | FLASH(与无处理对比) | 耗时 | |
|---|---|---|---|
| 原子操作 | 0B | 增加20B | 09.905s |
| 互斥量 | 0B | 520B | 25ms |
| 中断屏蔽 | 0B | 增加20B | 52ms |
●测试代码如下
static void ture_entry(void *parameter)
{
int i;
for (i = 0; i < 1000000; i++)
{
count++;
}
}
●在-OS优化时,查看汇编指令可以得出
static void ture_entry(void *parameter)
{
int i;
for (i = 0; i < 1000000; i++)
80176f0: 4a03 ldr r2, [pc, #12] ; (8017700 <ture_entry+0x10>)
80176f2: 6813 ldr r3, [r2, #0]
80176f4: f503 2374 add.w r3, r3, #999424 ; 0xf4000
80176f8: f503 7310 add.w r3, r3, #576 ; 0x240
80176fc: 6013 str r3, [r2, #0]
{
count++;
}
}
80176fe: 4770 bx lr
8017700: 20009670 .word 0x20009670
●编译器自动计算赋值为了1000000,并不具备可比性
80176f4: f503 2374 add.w r3, r3, #999424 ; 0xf4000
80176f8: f503 7310 add.w r3, r3, #576 ; 0x240
2.使用STM32WLE 8MHZ主频 -O0优化
| ROM(与无处理对比) | FLASH(与无处理对比) | 耗时 | |
|---|---|---|---|
| 原子操作 | 0B | 增加0B | 23.125s |
| 互斥量 | 0B | 960B | 7.567s |
| 中断屏蔽 | 0B | 增加10B | 7.143s |
| 未处理 | 0B | 增加10B | 7.725s |
●可以得出使用中断屏蔽处理最为省事,且耗时最短;但直接屏蔽中断风险最大
●互斥量需要创建再使用,且消耗FLASH最多;
●原子操作相比之下,耗时最旧;但需要注意这是操作了100W次的结果;实际上一次操作大约耗时23us;和其他方式的7us相比,并无多大差距;且用法最为方便
4.乐观锁与悲观锁
乐观锁:乐观锁在操作数据时非常乐观,认为别人不会同时修改数据。
因此乐观锁不会上锁,只是在执行更新的时候判断一下在此期间别人是否修改了数据:如果别人修改了数据则放弃操作,否则执行操作。
悲观锁:悲观锁在操作数据时比较悲观,认为别人会同时修改数据。
因此操作数据时直接把数据锁住,直到操作完成后才会释放锁;上锁期间其他人不能修改数据。
(1)CAS(Compare And Swap)
- CAS操作包括了3个操作数:
-
- 需要读写的内存位置(V)
-
- 进行比较的预期值(A)
-
- 拟写入的新值(B)
CAS操作逻辑如下:
如果内存位置V的值等于预期的A值,则将该位置更新为新值B,否则不进行任何操作。
许多CAS的操作是自旋的:如果操作不成功,会一直重试,直到操作成功为止。
这里引出一个新的问题,既然CAS包含了Compare和Swap两个操作,它又如何保证原子性呢?
答案是:CAS是由CPU支持的原子操作,其原子性是在硬件层面进行保证的。下面以Java中的自增操作(i++)为例,看一下悲观锁和CAS分别是如何保证线程安全的。
我们知道,在Java中自增操作不是原子操作,它实际上包含三个独立的操作:
- 读取i值;
- 加1;
- 将新值写回i
因此,如果并发执行自增操作,可能导致计算结果的不准确。
在下面的代码示例中:value1没有进行任何线程安全方面的保护,value2使用了乐观锁(CAS),value3使用了悲观锁(synchronized)。
运行程序,使用1000个线程同时对value1、value2和value3进行自增操作,可以发现:value2和value3的值总是等于1000,而value1的值常常小于1000。
乐观锁和悲观锁优缺点和适用场景
乐观锁和悲观锁并没有优劣之分,它们有各自适合的场景;下面从两个方面进行说明。
●功能限制 与悲观锁相比,乐观锁适用的场景受到了更多的限制,无论是CAS还是版本号机制。
例如,CAS只能保证单个变量操作的原子性,当涉及到多个变量时,CAS是无能为力的,而synchronized则可以通过对整个代码块加锁来处理。
再比如版本号机制,如果query的时候是针对表1,而update的时候是针对表2,也很难通过简单的版本号来实现乐观锁。
●竞争激烈程度 如果悲观锁和乐观锁都可以使用,那么选择就要考虑竞争的激烈程度:
当竞争不激烈 (出现并发冲突的概率小)时,乐观锁更有优势,因为悲观锁会锁住代码块或数据,其他线程无法同时访问,影响并发,而且加锁和释放锁都需要消耗额外的资源。
当竞争激烈(出现并发冲突的概率大)时,悲观锁更有优势,因为乐观锁在执行更新时频繁失败,需要不断重试,浪费CPU资源。
下面是CAS一些不那么完美的地方:
1.ABA问题 假设有两个线程——线程1和线程2,两个线程按照顺序进行以下操作:
●(1)线程1读取内存中数据为A;
●(2)线程2将该数据修改为B;
●(3)线程2将该数据修改为A;
●(4)线程1对数据进行CAS操作
在第(4)步中,由于内存中数据仍然为A,因此CAS操作成功,但实际上该数据已经被线程2修改过了。这就是ABA问题。
在AtomicInteger的例子中,ABA似乎没有什么危害。
但是在某些场景下,ABA却会带来隐患,例如栈顶问题:一个栈的栈顶经过两次(或多次)变化又恢复了原值,但是栈可能已发生了变化。
对于ABA问题,比较有效的方案是引入版本号,内存中的值每发生一次变化,版本号都+1;
在进行CAS操作时,不仅比较内存中的值,也会比较版本号,只有当二者都没有变化时,CAS才能执行成功。
Java中的AtomicStampedReference类便是使用版本号来解决ABA问题的。
2.高竞争下的开销问题 在并发冲突概率大的高竞争环境下,如果CAS一直失败,会一直重试,CPU开销较大。
针对这个问题的一个思路是引入退出机制,如重试次数超过一定阈值后失败退出。
当然,更重要的是避免在高竞争环境下使用乐观锁。
3.功能限制 CAS的功能是比较受限的,例如CAS只能保证单个变量(或者说单个内存值)操作的原子性,这意味着:
(1)原子性不一定能保证线程安全,例如在Java中需要与volatile配合来保证线程安全;
(2)当涉及到多个变量(内存值)时,CAS也无能为力。
除此之外,CAS的实现需要硬件层面处理器的支持,在Java中普通用户无法直接使用,只能借助atomic包下的原子类使用,灵活性受到限制。
5.参考
https://club.rt-thread.org/ask/article/8137bfed7f581142.html
https://www.rt-thread.org/document/site/#/rt-thread-version/rt-thread-standard/programming-manual/atomic/atomic
https://club.rt-thread.org/ask/question/762672a6d3cc365f.html
https://www.freertos.org/FreeRTOS_Support_Forum_Archive/September_2013/freertos_Concerns_about_the_atomicity_of_vTaskSuspendAll_d165e9c3j.html
https://github.com/RT-Thread/rt-thread/issues/8449
6.后记
-
最底层ARM提供的原子操作指令可以保证当前读写操作不会因为其他线程同时访问导致异常.如果执行指令的时候发现已经被标记为独占访问了,并不会对指令的执行产生影响。而如果执行这条指令的时候发现没有设置独占标记,则不会更新内存,所以需要while进行阻塞查询进而实现写入成功
-
ldrex和strex指令
LDREX和STREX指令,是将单纯的更新内存的原子操作分成了两个独立的步骤。 -
LDREX Rx, [Ry]
LDREX用来读取内存中的值,并标记对该段内存的独占访问。上面的指令意味着,读取寄存器Ry指向的4字节内存值,将其保存到Rx寄存器中,同时标记对Ry指向内存区域的独占访问。如果执行LDREX指令的时候发现已经被标记为独占访问了,并不会对指令的执行产生影响。 -
STREX Rx, Ry, [Rz]
STREX在更新内存数值时,会检查该段内存是否已经被标记为独占访问,并以此来决定是否更新内存中的值。如果执行这条指令的时候发现已经被标记为独占访问了,则将寄存器Ry中的值更新到寄存器Rz指向的内存,并将寄存器Rx设置成0。指令执行成功后,会将独占访问标记位清除。而如果执行这条指令的时候发现没有设置独占标记,则不会更新内存,且将寄存器Rx的值设置成1。一旦某条STREX指令执行成功后,以后再对同一段内存尝试使用STREX指令更新的时候,会发现独占标记已经被清空了,就不能再更新了,从而实现独占访问的机制。















 5537
5537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









