







 本文详细介绍了Sequential模型的两种添加层方法,包括通过add()函数和直接添加。同时,讲解了模型编译、训练及评估的过程。重点讨论了Dense层的参数及其作用,如激活函数、输入维度等。此外,还阐述了Flatten层在处理多维数据时的作用。文章适合对深度学习感兴趣的读者,特别是初学者。
本文详细介绍了Sequential模型的两种添加层方法,包括通过add()函数和直接添加。同时,讲解了模型编译、训练及评估的过程。重点讨论了Dense层的参数及其作用,如激活函数、输入维度等。此外,还阐述了Flatten层在处理多维数据时的作用。文章适合对深度学习感兴趣的读者,特别是初学者。
Sequential模型
顺序模型
核心操作是添加layers,有两种方法
第一种:通过add()添加
model = Sequential()
model.add(tf.keras.layers.Dense(10,input_shape(1,),activation='relu'))#10表示输出数据的维度,后面表示输入的形状,激活函数为relu
model.add(tf.keras.layers.Dense(28,input_shape(1,)))
第二种;直接添加
model = Sequential(tf.keras.layers.Dense(10,input_shape(1,),activation='relu'),tf.keras.layers.Dense(28,input_shape(1,)))
选择优化器(如rmsprop或adagrad)并指定损失函数(如categorical_crossentropy)来指定反向传播的计算方法
model.compile(loss='binary_crossentropy',
optimizer='rmsprop')
调用fit函数将数据提供给模型。这里还可以指定批次大小(batch size)、迭代次数、验证数据集等等。
model.fit(x_train, y_train, batch_size=32, epochs=10,validation_data=(x_val, y_val))
使用evaluate方法来评估模型。
score = model.evaluate(x_test,y_test,batch_size = 32)
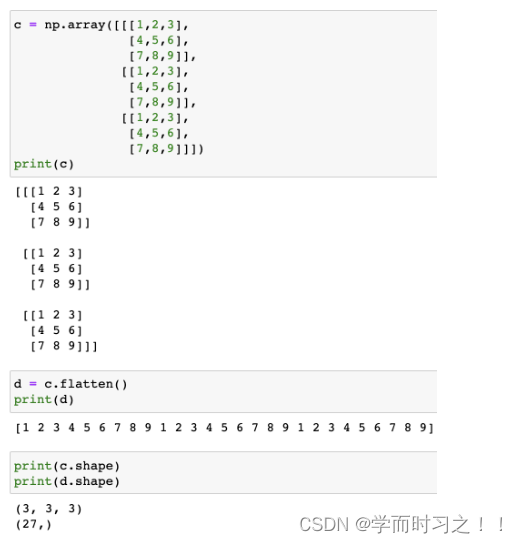
Flatten层(展平层)
用来对数组进行展平操作的
假设有一张灰度图片,这个图片只有3x3个像素点,分别是从1到9,我们对其进行flatten操作。首先它会把每1行进行分开,然后用第2行接在第1行后面,形成一个新的数组1,2,3,4,5,6,最后再把第3行的7,8,9接在新生成的数组后面形成最终的数组。
例如:如果是彩色图片的话,它会有3个颜色通道,进行fltten时的步骤也是一样的。
Dense层
keras.layers.Dense(units, activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)
参数
units :代表该层的输出维度或神经元个数, units解释为神经元个数为了方便计算参数量,解释为输出维度为了方便计算维度
activation=None:激活函数.但是默认 liner (详见API的activation)
use_bias=True:布尔值,该层是否使用偏置向量b
kernel_initializer:初始化w权重 (详见API的initializers)
bias_initializer:初始化b权重 (详见API的initializers)
kernel_regularizer:施加在权重w上的正则项 (详见API的regularizer)
bias_regularizer:施加在偏置向量b上的正则项 (详见API的regularizer)
activity_regularizer:施加在输出上的正则项 (详见API的regularizer)
kernel_constraint:施加在权重w上的约束项 (详见API的constraints)
bias_constraint:施加在偏置b上的约束项 (详见API的constraints)
# 作为 Sequential 模型的第一层,需要指定输入维度。可以为 input_shape=(16,) 或者 input_dim=16,这两者是等价的。
model = Sequential()
model.add(Dense(32, input_shape=(16,))) #其输出数组的尺寸为 (*, 32),模型以尺寸(*, 16) 的数组作为输入
# 在第一层之后,就不再需要指定输入的尺寸了:
model.add(Dense(32))
input_shape是指输入张量的shape
input_dim是指的张量的维度
比如,一个一阶的张量[1,2,3]的shape是(3,),input_dim = 1(因为是一阶)
一个二阶的张量[[1,2,3],[4,5,6]]的shape是(2,3),input_dim = 2(因为是二阶)
一个三阶的张量[[[1],[2],[3]],[[4],[5],[6]]]的shape是(2,3,1),input_dim = 3(因为是三阶)
参考
https://blog.csdn.net/mogoweb/article/details/82152174
https://blog.csdn.net/fisherming/article/details/114827976

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









