







摘要
预训练语言模型在各种自然语言理解(NLU)任务中取得了巨大成功,因为它能够通过对大规模语料库进行预训练来捕捉文本中的深层上下文信息。在本技术报告中,我们介绍了我们在中文语料库上预训练语言模型(名为NEZHA,中文理解的情境化神经表示)并在中文NLU任务上进行微调的实践。当前版本的NEZHA基于BERT [1],并结合了一系列经过验证的改进,包括作为有效位置编码方案的功能性相对位置编码、全词掩码策略、混合精度训练以及训练模型时使用的LAMB优化器。实验结果表明,NEZHA在多个具有代表性的中文任务上微调后取得了最先进的性能,这些任务包括命名实体识别(人民日报NER)、句子匹配(LCQMC)、中文情感分类(ChnSenti)和自然语言推理(XNLI)。
关键词 预训练语言模型 · NEZHA · 中文理解
1 引言
诸如ELMo [2]、BERT [1]、ERNIE-Baidu [3, 4]、ERNIE-Tsinghua [5]、XLNet [6]、RoBERTa [7]和MegatronLM等预训练语言模型通过利用大量训练文本,在建模上下文词表示方面取得了显著成功。作为自然语言处理(NLP)中的一项基础技术,预训练的语言模型可以轻松迁移到下游NLP任务中,并通过微调在许多任务上取得最先进的性能,包括情感分析、机器阅读理解、句子匹配、命名实体识别和自然语言推理。
现有的预训练语言模型大多是从英语语料库(如BooksCorpus和英文维基百科)中学习的。针对中文语言,也有一些尝试,包括谷歌的中文BERT [1]、ERNIE-Baidu [3, 4]和BERT-WWM [8]。所有这些模型都基于Transformer [9],并在两个无监督任务上进行训练:掩码语言模型(MLM)和下一句预测(NSP)。在MLM任务中,模型学习恢复训练句子中被掩码的词。在NSP任务中,模型尝试预测一个句子是否是另一个句子的下一句。中文模型之间的主要区别之一在于MLM任务中的词掩码策略。谷歌的BERT独立地掩码每个中文字符或WordPiece词元 [10]。ERNIE-Baidu通过将句子中的实体或短语作为一个整体进行掩码,使MLM任务更具挑战性,其中每个实体或短语可能包含多个字符或词元。BERT-WWM采用了类似的全词掩码(WWM)策略,强制要求属于一个中文词的所有词元应一起被掩码。此外,在最新发布的ERNIE-Baidu 2.0 [4]中,还引入了额外的预训练任务,如词元-文档关系预测和句子重排序。
在本技术报告中,我们介绍了预训练语言模型NEZHA(中文理解的情境化神经表示)的实践,该模型目前基于BERT并在中文文本上进行训练。具体而言,我们在模型中采用了一种称为功能性相对位置编码的技术。在原始Transformer以及BERT模型中,序列中每个词的位置编码是一个包含其绝对位置信息的向量。位置编码被添加到词嵌入中,作为Transformer的输入。确定位置编码的典型方法有两种:一种是功能性位置编码,其中位置编码由一些预定义的函数(例如[9]中的正弦函数)确定;另一种是参数化位置编码,它是模型参数的一部分,如[1]中所述。[11]提出了一种参数化相对位置编码,将相对位置信息融入Transformer的自注意力层中。随后,Transformer-XL [12]和XLNet [6]提出使用正弦编码矩阵和两个可训练的偏置项来表示相对位置。在本技术报告中,我们采用了一种功能性相对位置编码方案,通过预定义的函数对自注意力中的相对位置进行编码,而无需任何可训练参数。我们的实验研究表明,这是一种有效的预训练语言模型位置编码方案,并在实验中取得了稳定的性能提升。此外,我们在训练NEZHA时采用了三种在BERT预训练中被证明有效的技术,分别是全词掩码[8]、混合精度训练[13]和LAMB优化器[14]。
本技术报告的贡献在于,我们系统地研究了在大规模中文语料库上预训练语言模型的问题,在多个中文NLU任务上评估了模型,并分析了训练因素(包括位置编码方案、掩码策略、训练语料来源、训练序列长度)的有效性。我们将向社区发布NEZHA模型及其源代码。
2 NEZHA模型的预训练
本节详细介绍了我们的NEZHA模型。第2.1节介绍了BERT模型和位置编码方案的预备知识。第2.2节介绍了我们模型中采用的功能性相对位置编码。第2.3节、第2.4节和第2.5节分别介绍了我们预训练中使用的三种技术,即全词掩码、混合精度训练和LAMB优化器。
2.1 预备知识:BERT模型与位置编码
BERT(来自Transformer的双向编码器表示)是一种预训练语言模型,它由多个Transformer编码器堆叠而成。每个Transformer编码器由多头自注意力层和逐位置前馈网络组成。它在每个子层周围使用残差连接,随后进行层归一化。有关Transformer架构的更多细节,请参阅[9]。BERT的训练数据中的每个样本是一对句子。在每个样本中,12%的词元被掩码,1.5%的词元被随机替换为词汇表中的另一个词元。此外,在训练集中,每个样本(包含句子A和句子B)的构建方式如下:50%的情况下,B实际上是A的下一句;50%的情况下,B是从语料库中随机选择的句子,而不是A的下一句。在预训练阶段,BERT有两个任务:一个是掩码语言建模(MLM),旨在从其他词元中预测被掩码的词元;第二个预训练任务是下一句预测(NSP),它预测每个训练样本中的第二个句子是否是第一个句子的下一句。从某种意义上说,BERT可以被视为一种去噪自编码器,因为其训练目标之一是恢复添加了噪声的数据。
在Transformer中,每个注意力头操作一个由词元组成的序列 x = ( x 1 , x 2 , … , x n ) x = (x_1, x_2, \ldots, x_n) x=(x1,x2,…,xn),其中 x i ∈ R d x x_i \in \mathbb{R}^{d_x} xi∈Rdx,并输出一个相同长度的序列 z = ( z 1 , z 2 , … , z n ) z = (z_1, z_2, \ldots, z_n) z=(z1,z2,…,zn),其中 z i ∈ R d z z_i \in \mathbb{R}^{d_z} zi∈Rdz。每个注意力头有三个需要学习的参数矩阵 W K W^K WK、 W Q W^Q WQ和 W V ∈ R d x × d z W^V \in \mathbb{R}^{d_x \times d_z} WV∈Rdx×dz。输出 z i z_i zi的计算方式如下: z ~ i = ∑ j = 1 n α i j ( x j W V ) ( 1 ) . \tilde{z}_i = \sum_{j=1}^{n} \alpha_{ij}(x_j W^V)\qquad{(1)}. z~i=j=1∑nαij(xjWV)(1).
注意力分数 α i j \alpha_{ij} αij表示位置 i i i和位置 j j j之间的隐藏状态的相关性,通过softmax函数计算:
α i j = exp ( e i j ) ∑ k exp ( e i k ) ( 2 ) \alpha_{ij} = \frac{\exp(e_{ij})}{\sum_k \exp(e_{ik})}\qquad{(2)} αij=∑kexp(eik)exp(eij)(2)
其中
e
i
j
e_{ij}
eij是输入元素的线性变换之间的缩放点积:
e
i
j
=
(
x
i
W
Q
)
(
x
j
W
K
)
T
d
z
(
3
)
.
e_{ij}=\frac{(x_iW^Q)(x_jW^K)^T}{\sqrt{d_z}} \qquad{(3)}.
eij=dz(xiWQ)(xjWK)T(3).
由于Transformer(和BERT)中的多头注意力是排列不变的,因此对词序不敏感。因此,[9] 为每个位置引入了一个绝对位置编码,这是一个嵌入向量,直接添加到词元嵌入中。随后,[11] 提出了一种参数化的相对位置编码方案。在相对位置编码方案中,注意力分数的计算涉及两个位置之间相对距离的参数化嵌入。具体来说,它修改了公式D中输出
z
i
z_i
zi的计算以及公式3中
e
i
j
e_{ij}
eij的计算,如下所示:
z
i
=
∑
j
=
1
n
α
i
j
(
x
j
W
V
+
a
i
j
V
)
(
4
)
,
z_i=\sum_{j=1}^n\alpha_{ij}(x_jW^V+a_{ij}^V) \qquad{(4)},
zi=j=1∑nαij(xjWV+aijV)(4),
e
i
j
=
(
x
i
W
Q
)
(
x
j
W
K
+
a
i
j
K
)
T
d
z
(
5
)
.
e_{ij}=\frac{(x_{i}W^{Q})(x_{j}W^{K}+a_{ij}^{K})^{T}}{\sqrt{d_{z}}} \qquad{(5)}.
eij=dz(xiWQ)(xjWK+aijK)T(5).
在上述两个公式中, a i j V , a i j K ∈ R d z a_{ij}^V, a_{ij}^K \in \mathbb{R}^{d_z} aijV,aijK∈Rdz是两个向量,编码了位置 i i i和 j j j之间的相对位置,并且它们在所有注意力头之间共享。Transformer-XL [12] 和 XLNet [6] 以不同的形式实现了相对位置编码。更多细节请参阅它们的论文。
2.2 功能性相对位置编码
在当前版本的NEZHA中,我们采用了功能性相对位置编码,其中输出和注意力分数的计算涉及它们相对位置的正弦函数。这一灵感来源于Transformer [9] 中采用的功能性绝对位置编码。具体来说,在我们的模型中, a i j V a_{ij}^V aijV和 a i j K a_{ij}^K aijK都由正弦函数生成,并在模型训练期间固定。在本技术报告的剩余部分中,为了清晰起见,我们用 a i j a_{ij} aij来表示 a i j V a_{ij}^V aijV和 a i j K a_{ij}^K aijK的公式。考虑 a i j a_{ij} aij的第 2 k 2k 2k维和第 2 k + 1 2k+1 2k+1维,分别有:
a i j [ 2 k ] = sin ( j − i 1000 0 2 k d z ) ( 6 ) , a_{ij}[2k]=\sin\left(\frac{j-i}{10000^{\frac{2k}{d_z}}}\right) \qquad{(6)}, aij[2k]=sin(10000dz2kj−i)(6), a i j [ 2 k + 1 ] = cos ( j − i 1000 0 2 k d z ) ( 7 ) . a_{ij}[2k+1]=\cos\left(\frac{j-i}{10000^{\frac{2k}{d_z}}}\right) \qquad{(7)}. aij[2k+1]=cos(10000dz2kj−i)(7).
也就是说,位置编码的每一维对应一个正弦函数,不同维度的正弦函数具有不同的波长。在上述公式中, d z d_z dz等于NEZHA模型每个注意力头的隐藏大小(即隐藏大小除以注意力头的数量)。波长从 2 π 2\pi 2π到 10000 ⋅ 2 π 10000 \cdot 2\pi 10000⋅2π形成一个几何级数。我们选择固定的正弦函数主要是因为它可能使模型能够外推到比训练期间遇到的序列长度更长的序列。
2.3 全词掩码(Whole Word Masking)
在原始的BERT中,每个词元或中文字符被随机掩码。在[8]中,全词掩码(WWM)策略被证明比随机掩码更有效。在WWM中,一旦一个中文字符被掩码,属于同一个中文词的其他字符也会一起被掩码。在NEZHA中实现WWM时,我们使用了分词工具Jieba2进行中文分词(即确定中文词的边界)。在WWM训练数据中,每个样本包含若干个被掩码的中文词,被掩码的中文字符总数大约占样本长度的12%,其中1.5%的字符被随机替换。
2.4 混合精度训练
在NEZHA模型的预训练中,我们采用了混合精度训练技术[13]。该技术可以将训练速度提高2-3倍,同时减少模型的空间消耗,从而可以使用更大的批量大小。
传统上,深度神经网络的训练使用FP32(即单精度浮点格式)来表示训练中涉及的所有变量(包括模型参数和梯度)。混合精度训练[13]在训练中采用混合精度。具体来说,它维护模型权重的一个单精度副本(称为主权重)。在每次训练迭代中,它将主权重舍入为FP16(即半精度浮点格式),并使用FP16格式存储的权重、激活值和梯度执行前向和反向传播。最后,它将梯度转换为FP32格式,并使用FP32梯度更新主权重。
2.5 LAMB优化器
LAMB优化器[14]专为深度神经网络的大批量同步分布式训练设计。使用大批量训练是加速训练的有效方法。然而,如果没有仔细调整学习率的调度,当批量大小超过某个阈值时,性能可能会大幅下降。LAMB优化器采用了一种通用的自适应策略,同时通过理论分析提供了对收敛的洞察。该优化器通过使用非常大的批量大小(在[14]中超过30k)加速BERT的训练,而不会导致性能损失,甚至在许多任务中取得了最先进的性能。值得注意的是,BERT的训练时间从3天显著减少到76分钟。
3 实验
本节报告了在中文文本上预训练NEZHA模型并在中文NLU下游任务上微调的实验结果。需要注意的是,这些训练技术不仅限于中文,也可以轻松应用于其他语言。
3.1 实验设置
数据集
我们采用了三个中文语料库来预训练NEZHA模型:
- 中文维基百科:中文维基百科是一个包含1,067,552篇文章的中文百科全书。我们下载了最新的中文维基百科数据,并使用WikiExtractor4工具清理原始数据。清理后的语料库包含简体和繁体中文,大约有2.02亿个词元。
- 百度百科:我们从百度百科爬取了网页,百度百科是由百度拥有和制作的中文协作网络百科全书。截至2018年8月,百度百科拥有超过1540万篇文章。清理后的语料库包含47.34亿个词元。
- 中文新闻:我们从多个新闻网站(如新浪新闻)爬取了中文新闻语料库。清理后的语料库包含56亿个词元。
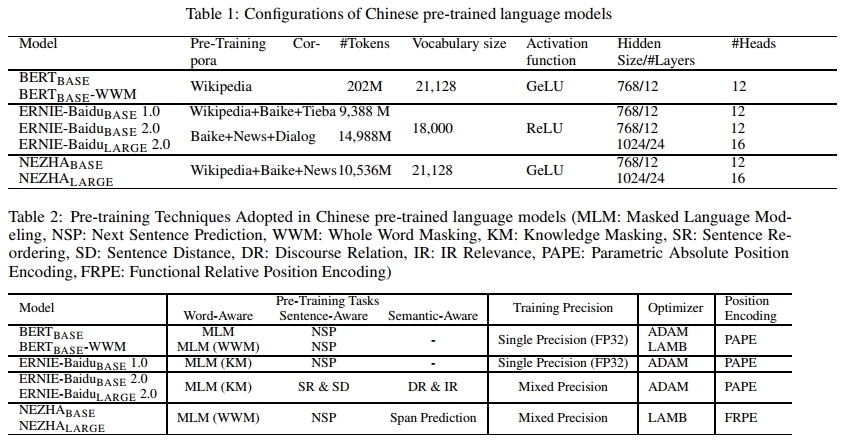
对于上述每个语料库,我们为NEZHA准备了两个版本的预训练数据。第一个版本的处理方式与[1]中相同,包含12%的掩码中文字符和1.5%的随机替换中文字符。我们使用BERT GitHub项目6提供的工具将文本数据转换为预训练样本。第二个版本基于全词掩码(WWM)策略。我们使用中文分词工具Jieba创建WWM预训练样本,以识别中文词的边界。在WWM样本中,每个样本包含若干个被掩码的中文词,被掩码的中文字符总数大约占样本长度的12%,其中1.5%的字符被随机替换。表1总结了几种预训练模型的数据集统计信息。
预训练细节
我们在华为云7上的10台服务器上训练NEZHA模型,每台服务器配备8个NVIDIA Tesla V100 GPU(32GB内存)。分布式训练算法采用Ring-AllReduce8,并使用Horovod[15]框架实现。我们从零开始训练每个模型,并在训练损失收敛时终止训练。对于NEZHABASE模型,我们将最大学习率设置为1.8e-4(1800个预热步骤,线性衰减)。每个GPU的批量大小为180,因此总批量大小为180 * 8 * 10 = 14400。对于NEZHALARGE模型,我们将最大学习率设置为1e-4(1800个预热步骤,多项式衰减)。每个GPU的批量大小为64,因此总批量大小为64 * 8 * 10 = 5120。此外,我们在预训练阶段采用了FP16混合精度训练[13]。
3.2 实验结果
在实验中,我们将NEZHA模型与当前最先进的中文预训练语言模型进行了比较,包括谷歌的中文BERT [1]、BERT-WWM [8] 和ERNIE-Baidu [3, 4]。它们的模型配置如表1所示。我们还在表2中总结了每种中文预训练语言模型采用的预训练技术。需要注意的是,ERNIE-Baidu有三个不同的版本,分别是ERNIE-BaiduBASE 1.0、ERNIE-BaiduBASE 2.0和ERNIE-BaiduLARGE 2.0。ERNIE-BaiduBASE和ERNIE-BaiduLARGE 2.0引入了许多不同的预训练任务,具体细节请参阅其论文。如表所示,我们模型的独特技术是功能性相对位置编码。我们通过在多种自然语言理解(NLU)任务上微调来测试预训练模型的性能,这些任务如下所列。每个任务微调的超参数如表3所示。
-
CMRC(中文机器阅读理解2018)[16]:一个机器阅读理解任务,针对给定问题从给定段落中返回答案片段。
-
XNLI(跨语言自然语言推理)[17]:XNLI的中文部分,是MultiNLI的一个版本,其开发集和测试集已被人工翻译成15种语言。XNLI是一个自然语言推理任务,目标是预测第二句话是否与第一句话矛盾、蕴含或中立。
-
LCQMC(大规模中文问题匹配语料库)[18]:一个句子对匹配任务。给定一对句子,任务是判断这两个句子在语义上是否等价。
-
PD-NER(人民日报命名实体识别)9:一个序列标注任务,从文本中识别命名实体。语料库来自中国新闻媒体《人民日报》。
-
ChnSenti(中文情感分类)10:一个二分类任务,预测给定句子的情感是正面还是负面。
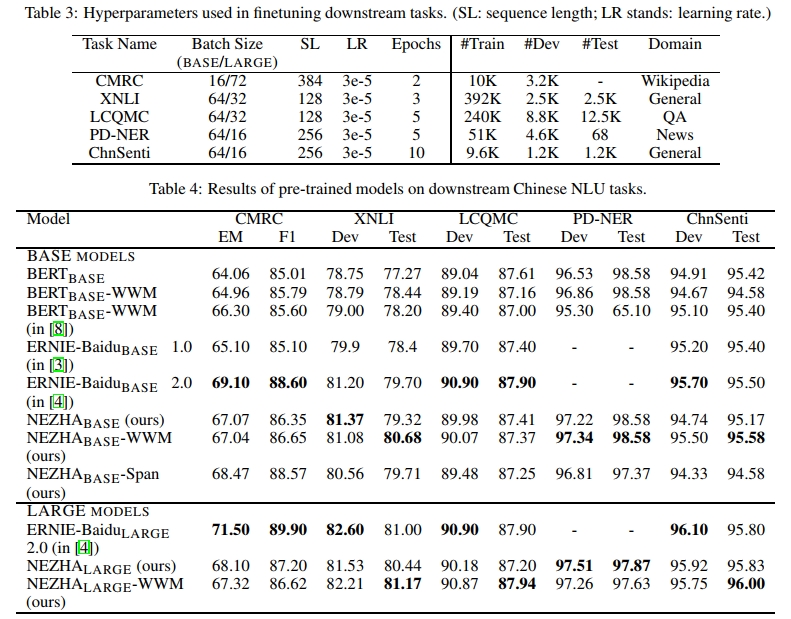
我们在表4中展示了不同预训练模型在上述任务上的比较结果。在BASE模型和LARGE模型组中,ERNIE-Baidu 2.0或NEZHA均取得了最佳性能。需要注意的是,部分结果直接复制自原始论文[8, 4]。由于实验设置或微调方法的可能差异,这种比较可能并不完全公平。我们注意到,在CMRC任务上,我们的实现与[8, 4]中报告的结果之间存在一致的差距。一旦ERNIE-Baidu 2.0中文模型发布,我们将在相同设置下对其进行评估并更新本报告。
3.3 消融研究
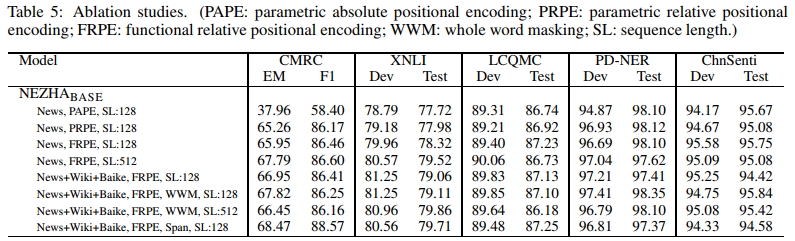
在本节中,我们研究了训练NEZHA时数据和不同技术的有效性,具体如下:
- 位置编码:我们工作中采用的功能性相对位置编码(FRPE)与现有研究中采用的参数化绝对位置编码(PAPE)和参数化相对位置编码(PRPE)的有效性比较。
- 掩码策略:全词掩码(WWM)对预训练模型性能的影响。
- 训练序列长度:使用更长序列进行训练的影响。
- 训练语料:训练数据来源的影响。
基于上述目标,我们比较了几种NEZHABASE模型变体的性能,如表5所示。结果表明,上述技术通常对下游任务有积极贡献,其中功能性相对位置编码相比其他位置编码方法表现出显著优势。例如,我们可以看到,当使用最多128个词元进行训练时,使用绝对位置编码的模型在CMRC任务上的表现显著差于使用相对位置编码的模型,而CMRC任务的输入段落可能更长。
4 结论
在本技术报告中,我们介绍了在中文语料库上训练大规模预训练语言模型NEZHA的实践。我们采用了一种有效的功能性相对位置编码方案,相比其他位置编码方法,这一方案带来了显著的性能提升。NEZHA模型的预训练还整合了多种技术,包括全词掩码策略、混合精度训练和LAMB优化器。实验表明,我们的模型在多个中文自然语言理解任务上能够达到最先进的性能。未来,我们计划继续改进NEZHA在中文及其他语言上的表现,并将其应用扩展到更多场景中。
论文名称:
NEZHA: NEURAL CONTEXTUALIZED REPRESENTATION FOR CHINESE LANGUAGE UNDERSTANDING
论文地址:
https://arxiv.org/pdf/1909.00204


















 862
862

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











