







摘要
对比学习在多模态表示学习领域取得了显著成功。在本文中,我们提出了一种对比语言-音频预训练的流程,通过将音频数据与自然语言描述结合,开发音频表示。为实现这一目标,我们首先发布了LAION-Audio-630K,这是一个来自不同数据源的633,526对音频-文本对的大型数据集。其次,我们通过考虑不同的音频编码器和文本编码器,构建了一个对比语言-音频预训练模型。我们将特征融合机制和关键词到字幕增强方法融入模型设计中,以进一步使模型能够处理变长的音频输入并增强其性能。第三,我们进行了全面的实验,评估模型在三个任务上的表现:文本到音频检索、零-shot音频分类和有监督音频分类。结果表明,在文本到音频检索任务中,我们的模型表现优异。在音频分类任务中,模型在零-shot设置中达到了最先进的性能,并能够获得与非零-shot设置下模型结果相当的性能。LAION-Audio-630K和所提出的模型均已向公众开放。
关键词— 对比学习,表示学习,文本到音频检索,音频分类,音频数据集
1. 引言
音频是世界上最常见的信息类型之一,和文本、图像数据并列。然而,不同的音频任务通常需要精细注释的数据,这由于劳动密集的收集过程限制了可用音频数据的数量。因此,在不需要大量监督的情况下,设计有效的音频表示以适应许多音频任务仍然是一个挑战。对比学习范式是一个成功的解决方案,用于在从互联网收集的大规模噪声数据上训练模型。最近提出的对比语言-图像预训练(CLIP)[1]通过将文本和图像投射到共享的潜在空间中,学习它们之间的对应关系。训练过程中,将真实的图像-文本对作为正样本,其他则作为负样本。与在单模态数据上训练相比,CLIP不受数据注释的约束,表现出极大的鲁棒性,并在ImageNet数据集的零-shot设置下取得了高准确度[2]。此外,CLIP在下游任务中也取得了巨大的成功,例如文本到图像检索和文本引导字幕生成。与视觉任务类似,音频和自然语言也包含重叠的信息。例如,在音频事件分类任务中,事件的一些文本描述可以映射到相应的音频。这些文本描述共享类似的意义,可以与相关音频一起学习,从而形成跨模态信息的音频表示。此外,训练这样的模型只需要简单配对的音频和文本数据,这些数据很容易收集。
近年来,几项研究[3–9]提出了对比语言-音频预训练模型的原型,用于文本到音频检索任务。[6]使用预训练的音频神经网络(PANN)[10]作为音频编码器,BERT[11]作为文本编码器,并通过几个损失函数评估文本到音频检索的性能。[5]进一步将HTSAT[12]和RoBERTa[13]集成到编码器列表中,以进一步增强性能。随后,[4]研究了学习到的表示在下游音频分类任务中的有效性。其他一些研究,如AudioClip [3]和WaveCLIP [9],则更侧重于对比图像-音频(或图像-音频-语言)预训练模型。这些模型展示了对比学习在音频领域的巨大潜力。
然而,当前的研究并未完全展示语言-音频对比学习的潜力。首先,上述模型在相对较小的数据集上进行训练,表明需要进行大规模的数据收集和增强。其次,现有的工作缺乏对音频/文本编码器选择和超参数设置的全面调查,而这些对于确定基本的对比语言-音频架构至关重要。第三,模型难以处理变长音频输入,尤其是在基于变换器的音频编码器中。应该有解决方案来处理变长音频输入。最后,大多数语言-音频模型的研究仅专注于文本到音频检索,而没有评估其在下游任务中的音频表示。作为一个表示模型,我们期望更多地发现其在下游任务中的泛化能力。
在本文中,我们通过以下方面改进了数据集、模型设计和实验设置:
- 我们发布了LAION-Audio-630K,这是目前最大的公开音频字幕数据集,包含633,526对音频-文本对。为了促进学习过程,我们采用关键词到字幕模型,将AudioSet [14]的标签增强为相应的字幕。这个数据集也可以为其他音频任务做出贡献。
- 我们构建了一个对比语言-音频预训练的流程,选择了两个音频编码器和三个文本编码器进行测试。我们采用特征融合机制以增强性能,并使我们的模型能够处理变长输入。
- 我们对模型进行了全面的实验,包括文本到音频检索任务,以及零-shot和有监督音频分类下游任务。我们证明了数据集的扩展、关键词到字幕增强和特征融合可以从不同角度提高模型的性能。它在文本到音频检索和音频分类任务中达到了最先进的(SOTA)水平,甚至与有监督模型的性能相当。
我们将LAION-Audio-630K和所提出的模型公开发布。
2. LAION-AUDIO-630K 和训练数据集
2.1. LAION-Audio-630K
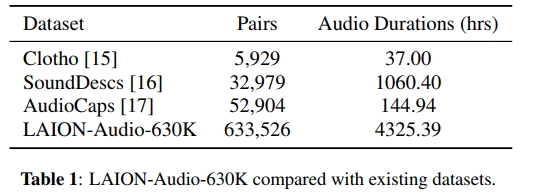
我们收集了LAION-Audio-630K,这是一个大型的音频-文本数据集,包含633,526对数据,总时长为4,325.39小时。数据集包括人类活动、自然声音和音效的音频,来源于8个公开可用的网络数据源3。我们通过下载音频及其相关文本描述来收集这些数据集。根据我们目前的了解,LAION-Audio-630K是目前公开可用的最大的音频-文本数据集,规模远大于之前的音频-文本数据集,如表1所示。
2.2. 训练数据集
为了测试模型在不同大小和类型数据集上的性能扩展,我们在本文中使用了三种不同大小的训练集设置,数据集的大小从小到大。这些设置包括三个数据集:
- AudioCaps+Clotho (AC+CL) [15, 17] 包含大约55K个音频-文本对的训练样本。
- LAION-Audio-630K (LA.) 包含大约630K个音频-文本对。
- Audioset [14] 包含190万个音频样本,但每个样本只有标签可用。
在处理这些数据集时,我们排除了评估集中所有重复的数据。更多关于训练数据集的细节可以在在线附录中找到。
2.3. 数据集格式和预处理
本研究中使用的所有音频文件都被预处理为单声道,采样率为48kHz,格式为FLAC。对于仅提供标签或标签的数据集,我们使用模板“标签-1, 标签-2, …, 标签-n的声音”或关键词到字幕模型(详细见第3.5节)将标签扩展为字幕。因此,我们可以利用更多的数据来训练对比语言-音频预训练模型。将所有数据集结合起来,我们将带有文本字幕的音频样本总数增加到250万。
3. 模型架构
3.1. 对比语言-音频预训练
图1展示了我们提出的对比语言-音频编码器模型的整体架构。与CLIP [1]类似,我们有两个编码器分别处理音频数据 X i a X _ { i } ^ { a } Xia和文本数据 X i t X _ { i } ^ { t } Xit的输入,其中 ( X i a , X i t ) ( X _ { i } ^ { a } , X _ { i } ^ { t } ) (Xia,Xit)是由i索引的音频-文本对。音频嵌入 E i a \boldsymbol { E _ { i } ^ { a } } Eia和文本嵌入 E i t { E } _ { i } ^ { t } Eit分别通过音频编码器 f a u d i o ( ⋅ ) f _ { a u d i o } ( \cdot ) faudio(⋅)和文本编码器 f t e x t ( ⋅ ) f _ { t e x t } ( \cdot ) ftext(⋅)获得,并通过投影层得到:
E i a = M L P a u d i o ( f a u d i o ( X i a ) ) ( 1 ) E i t = M L P t e x t ( f t e x t ( X i t ) ) ( 2 ) \begin{array} { l l l } { { E _ { i } ^ { a } = M L P _ { a u d i o } \big ( f _ { a u d i o } ( X _ { i } ^ { a } ) \big ) } } & { { \qquad \qquad } } & { { ( 1 ) } } \\ { { E _ { i } ^ { t } = M L P _ { t e x t } \big ( f _ { t e x t } ( X _ { i } ^ { t } ) \big ) } } & { { \qquad \qquad } } & { { ( 2 ) } } \end{array} Eia=MLPaudio(faudio(Xia))Eit=MLPtext(ftext
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1393
1393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











