







A Comprehensive Survey of AI-Generated Content (AIGC):A History of Generative AI from GAN to ChatGPT
一、AIGC简介
1、什么是AIGC
AIGC:生成式人工智能,AI-Generated Content。
AIGC的目标是使内容创建过程更加高效和易于访问,从而能够以更快的速度制作高质量的内容。
AIGC是通过从人类提供的指令中提取和理解意图信息,并根据其知识和意图信息生成内容来实现的。
AIGC的发展依赖于数据的增长、AI算法的发展以及GPU的发展
2、AI发展历程
1956,人工智能达特茅斯学院人工智能夏季研讨会上正式使用了人工智能(artificial
intelligence,AI)这一术语。这是人类历史上第一次人工智能研讨,标志着人工智能学科的诞生。
1957年-Frank Rosenblatt-感知机(Perceptron)的神经网络模型
1958年,David Cox提出了logistic regression线性判别器
1967年,Thomas等人提出K最近邻算法
1968年,爱德华·费根鲍姆(Edward Feigenbaum)提出首个专家系统DENDRAL(知识库、推理机)
1974年,哈佛大学沃伯斯(Paul Werbos)博士论文里,首次提出了通过误差的反向传播(BP)来训练人工神经网络,但在该时期未引起重视。
1980年,在美国的卡内基梅隆大学(CMU)召开了第一届机器学习国际研讨会,标志着机器学习研究已在全世界兴起。
1989年,LeCun (CNN之父) 结合反向传播算法与权值共享的卷积神经层发明了卷积神经网络(Convolutional Neural Network,CNN),并首次将卷积神经网络成功应用到美国邮局的手写字符识别系统中。
1995年,Cortes和Vapnik提出联结主义经典的支持向量机(Support Vector Machine),它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。
1997年,Sepp Hochreiter 和 Jürgen Schmidhuber提出了长短期记忆神经网络(LSTM)。
2011年,IBM Watson问答机器人参与Jeopardy回答测验比赛最终赢得了冠军。Waston是一个集自然语言处理、知识表示、自动推理及机器学习等技术实现的电脑问答(Q&A)系统。
2012年,Hinton和他的学生Alex Krizhevsky设计的AlexNet神经网络模型在ImageNet竞赛大获全胜,这是史上第一次有模型在 ImageNet 数据集表现如此出色,并引爆了神经网络的研究热情。 AlexNet是一个经典的CNN模型,在数据、算法及算力层面均有较大改进,创新地应用了Data Augmentation、ReLU、Dropout和LRN等方法,并使用GPU加速网络训练。
2012年,谷歌正式发布谷歌知识图谱Google Knowledge Graph),它是Google的一个从多种信息来源汇集的知识库,通过Knowledge Graph来在普通的字串搜索上叠一层相互之间的关系,协助使用者更快找到所需的资料的同时,也可以知识为基础的搜索更近一步,以提高Google搜索的质量。
2013年,Google的Tomas Mikolov 在《Efficient Estimation of Word Representation in Vector Space》提出经典的 Word2Vec模型用来学习单词分布式表示,因其简单高效引起了工业界和学术界极大的关注。
2014年,聊天程序“尤金·古斯特曼”(Eugene Goostman)在英国皇家学会举行的“2014图灵测试”大会上,首次“通过”了图灵测试。
2014年,Goodfellow及Bengio等人提出生成对抗网络(Generative Adversarial Network,GAN),被誉为近年来最酷炫的神经网络。
2015年,Microsoft Research的Kaiming He等人提出的残差网络(ResNet)在ImageNet大规模视觉识别竞赛中获得了图像分类和物体识别的优胜。
2015年,谷歌开源TensorFlow框架。它是一个基于数据流编程(dataflow programming)的符号数学系统,被广泛应用于各类机器学习(machine learning)算法的编程实现,其前身是谷歌的神经网络算法库DistBelief。
2015年,马斯克等人共同创建OpenAI。它是一个非营利的研究组织,使命是确保通用人工智能 (即一种高度自主且在大多数具有经济价值的工作上超越人类的系统)将为全人类带来福祉。其发布热门产品的如:OpenAI Gym,GPT等。
2016年,AlphaGo与围棋世界冠军、职业九段棋手李世石进行围棋人机大战,以4比1的总比分获胜。
2017年,中国香港的汉森机器人技术公司(Hanson Robotics)开发的类人机器人索菲亚,是历史上首个获得公民身份的一台机器人。索菲亚看起来就像人类女性,拥有橡胶皮肤,能够表现出超过62种自然的面部表情。其“大脑”中的算法能够理解语言、识别面部,并与人进行互动。
2018年,Google提出论文《Pre-training of Deep Bidirectional Transformers for Language Understanding》并发布Bert(Bidirectional Encoder Representation from Transformers)模型,成功在 11 项 NLP 任务中取得 state of the art 的结果。
2020年,OpenAI开发的文字生成 (text generation) 人工智能GPT-3,它具有1,750亿个参数的自然语言深度学习模型,比以前的版本GPT-2高100倍,该模型经过了将近0.5万亿个单词的预训练,可以在多个NLP任务(答题、翻译、写文章)基准上达到最先进的性能。
2021年,OpenAI提出两个连接文本与图像的神经网络:DALL·E 和 CLIP。DALL·E 可以基于文本直接生成图像,CLIP 则能够完成图像与文本类别的匹配。
2022年11月30日,OpenAI推出ChatGPT,使用了Transformer神经网络架构,也是GPT-3.5架构,2023年一月末,ChatGPT的月活用户已突破1亿,成为史上增长最快的消费者应用。
3、AIGC发展历程
从ChatGPT的前世今生,到如今AI领域的竞争格局(截止至2023.03)
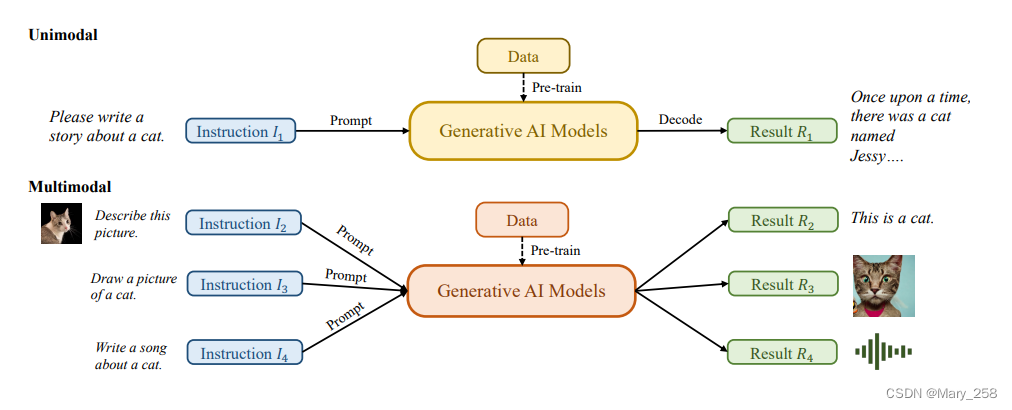
生成式AI模型(GAI)分为单模态模型和多模态模型:
单模态模型从与生成的内容模态相同的模态接收指令
多模态模型接受跨模态指令并产生不同模态的结果
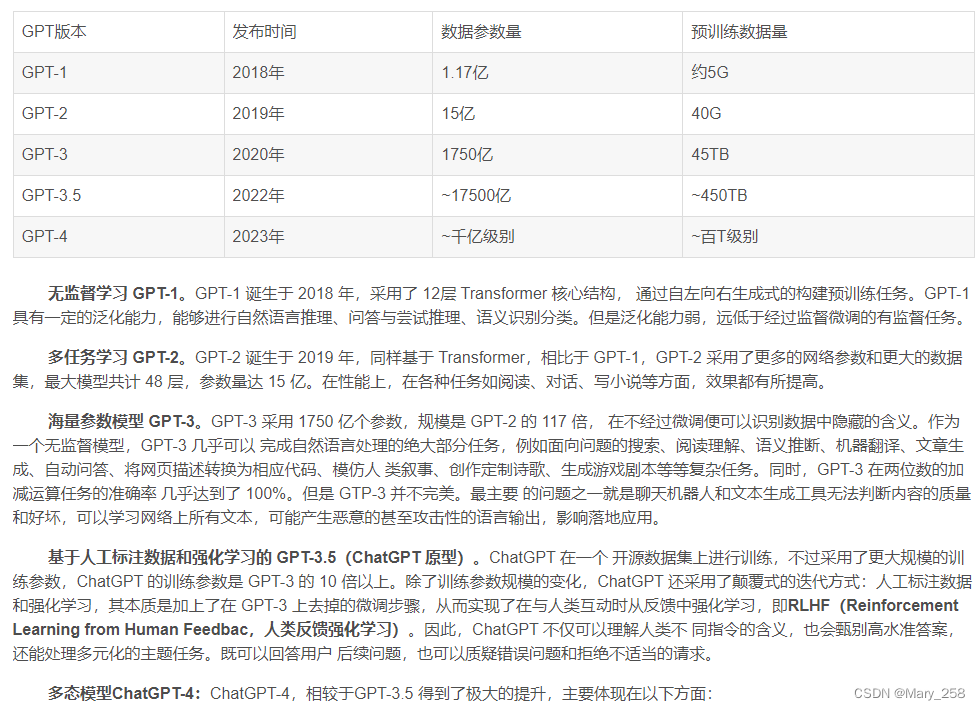
GPT-3的框架与GPT-2保持相同,但预训练数据大小从Web Text(38GB)到CommonCrawl【训练数据集](过滤后为570GB),以及基础模型大小从1.5亿增长到175亿。因此,GPT-3在各种方面都比GPT-2具有更好的泛化能力任务,例如人类意图提取。
ChatGPT利用来自人类反馈的强化学习(RLHF)[10-12]来确定对给定指令做出最恰当的响应,从而提高模型的可靠性和准确性随着时间的推移。这种方法使ChatGPT能够更好地理解长对话中的人类偏好。
同时,在计算机视觉中,稳定性提出了稳定扩散[13]stable diffusion, 2022年的人工智能在图像生成方面也取得了巨大成功。与现有方法不同,生成扩散模型可以通过控制探索和开发之间的权衡来帮助生成高分辨率图像,从而实现生成图像的多样性和与训练数据的相似性的和谐结合。
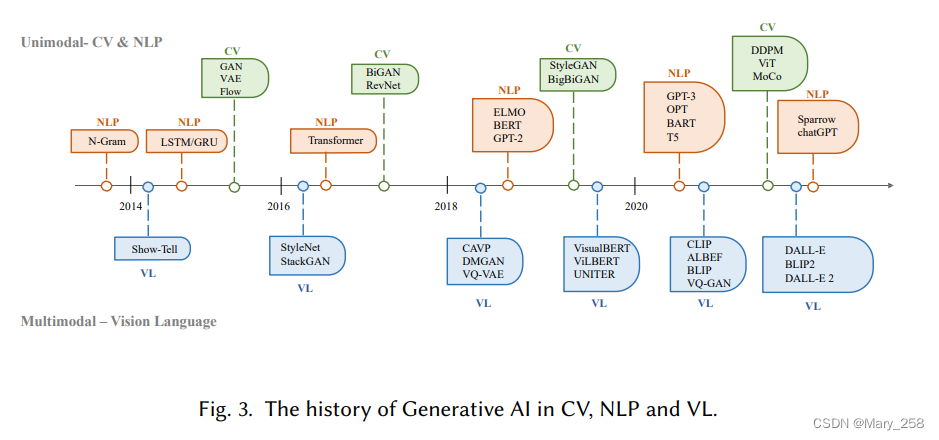
二、AI发展历史
20世纪50年代,隐马尔科夫模型HMM和高斯混合模型GMM生成了语言和时间序列之类的顺序数据。
NLP中,生成句子的传统方式是N-gram模型进行单词分别,然后搜索最佳序列。随着LSTM、GRU门控递归网络在训练过程中建模相对较长的依赖关系。
CV中,传统算法纹理合成和纹理映射到2014年生成对抗网络GANs的提出,再到变分自动编码器VAE和stable-diffusion的提出,图像生成过程也有了更细粒度的控制和高质量图像生成的能力。
Transformer的出现,使得NLP/CV出现了交叉点。NLP中,bert、GPT采用transformer作为其主要构建块,与LSTM和GRU相比更具优势。CV中,发展为ViT和swin transformer,多模态代表:CLIP
基于transformer模型的出现彻底改变了人工智能的生成,并带来了大规模训练的可能性。
ChatGPT、DALL-E-2、Codex
bert/transformer/强化学习
三、GAI模型训练中广泛使用的基本组件
3.1、AIGC的组件模型-Foundation Model
transformer
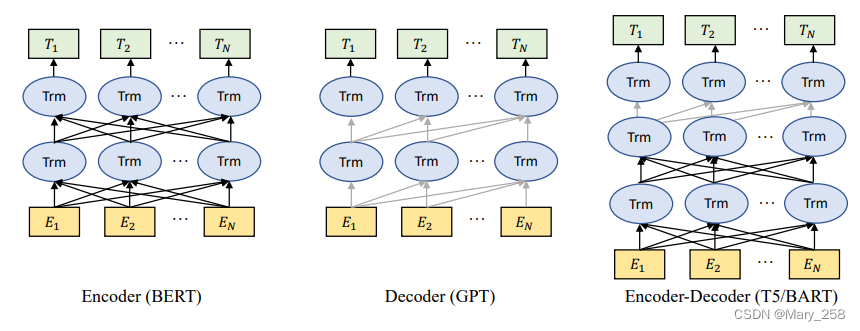
它最初是为了解决传统模型(如RNN)在处理可变长度序列和上下文感知方面的局限性而提出的。Transformer体系结构主要基于自关注机制,该机制允许模型关注输入序列中的不同部分。Transformer由一个编码器和一个解码器组成。编码器接收输入序列并生成隐藏表示,而解码器接收隐藏表示并生成输出序列。每一层编码器和解码器由多头注意力和前馈神经网络组成。多头注意力是Transformer的核心组成部分,它学习根据标记的相关性为其分配不同的权重。这种信息路由方法使模型能够更好地处理长期依赖关系,从而提高了在各种NLP任务中的性能。
transformer的另一个优点是其架构使其具有高度的并行性,并允许数据胜过电感偏差[40]。这种特性使transformer非常适合大规模的预训练,使基于transformer的模型能够适应不同的下游任务。
预训练语言模型-Pre-trained Language Models
自从引入Transformer体系结构以来,由于其并行性和学习能力,它已成为自然语言处理中的主导选择。通常,这些基于转换器的预训练语言模型根据其训练任务通常可分为两类:自回归语言建模autoregressive language modeling和掩蔽语言建模masked language modeling [41]。给定一个由几个标记组成的句子,masked language modeling 的目标,例如BERT[42]和RoBERTa[43],是指在给定上下文信息的情况下预测masked标记的概率。masked language modeling 最显著的例子是BERT[42],它包括masked language modeling 和下一句预测任务。RoBERTa[43]使用与BERT相同的架构,通过增加预训练数据量和纳入更具挑战性的预训练目标来提高其性能。XL Net[44]也基于BERT,它结合了置换运算来改变每次训练迭代的预测顺序,使模型能够跨tokens学习更多信息。而autoregressive language modeling,例如GPT-3[9]和OPT[45],是在给定先前token的情况下对下一个token的概率进行建模,因此是从左到右的语言建模。与masked language modeling不同,autoregressive language modeling自回归模型更适合于生成任务。
3.2、强化学习-Reinforcement Learning from Human Feedback
强化学习(RLHF)已被应用于各种应用程序中的微调模型,如Sparrow、InstructGPT和ChatGPT[10,46]。
通常,RLHF的整个流程包括以下三个步骤:预训练、奖励学习和强化学习的微调。
3.3、算力computing
硬件hardware
分布式训练 Distributed training.
云计算 Cloud computing
四、生成AI的发展历程-GENERATIVE AI
4.1、单模态模型
在本节中,我们将介绍最先进的单峰生成模型。这些模型被设计为接受特定的原始数据模态作为输入,例如文本或图像,然后以与输入相同的模态生成预测。我们将讨论这些模型中使用的一些最有前途的方法和技术,包括生成语言模型,例如GPT3[9]、BART[34]、T5[56],以及生成视觉模型,例如GAN[29]、VAE[30]和归一化流[57]。
4.1.1 语言生成模型Generative Language Models GLM
GLM:对话系统、翻译、问答系统
预训练语言模型分为:masked language models(encoders), auto-regressive language model(decoders)和encoder-decoder language models
Decoder models 使用用于文本生成
encoder models主要用于分类任务
encoder-decoder language models可以利用上下文信息和自回归特性来提高各种任务的性能。
依据 Decoder models 的模型
One of the most prominent examples of autoregressive decoder-based language models is GPT, which is a transformer-based model that utilizes self-attention mechanisms to process all words in a sequence simultaneously.
- GPT:基于Transformer,利用自注意机制处理序列中的单词。GPT是在前一个单词的基础上进行下一个单词预测任务的训练,使其能够生成连贯的文本。
Subsequently, GPT-2 [62] and GPT-3 [9] maintains the autoregressive left-to-right training method, while scaling up model parameters and leveraging diverse datasets beyond basic web text, achieving state-of-the-art results on numerous datasets.
- GPT-2[62]和GPT-3[9]放大模型参数,并利用web text进行训练,并在众多数据集上表现较好。
- Gopher[39]使用类似GPT的结构,但将LayerNorm[63]替换为RSNorm,其中将residual connection(RS,剩余连接)添加到原始层结构以维护信息。除了增强归一化功能外,其他几项研究都集中在优化注意力机制上。
- BLOOM[64]与GPT-3共享相同的结构,但BLOOM使用全注意力网络,而不是使用稀疏注意力,这更适合于对长依赖关系进行建模。
- [65]提出了Megatron,它扩展了GPT-3、BERT和T5等常用架构,并以分布式训练为目标来处理大量数据。这种方法后来也被MT-NLG[66]和OPT[45]所采用。
除了在模型架构和预训练任务方面的进步外,在改进语言模型的微调过程方面也做出了重大努力。
- InstructGPT[10]利用预先训练的GPT-3,并使用RLHF进行微调,允许模型根据人类标记的排名反馈来学习偏好。
依据 Encoder-Decoder models 的模型
One of the main encoder-decoder methods is Text-to-Text Transfer Transformer (T5)
- T5能将输入和输出数据转换为标准化的文本格式。可用于机器翻译、问答系统、摘要生成等
- Switch Transformer[67]utilizes“switch/切换”(指简化的MoE路由算法)在T5上进行并行训练。与基本模型相比,该模型在相同的计算资源下成功地获得了更大的规模和更好的性能。
- ExT5[68],谷歌2021年提出,扩展T5模型的规模。ExT5继续在C4和ExMix上进行预训练,which is跨不同领域的107个监督NLP任务的组合。
- BART[34],混合了BERT的双向编码器和GPT的自回归解码器,使其能够利用编码器的双向建模能力,同时保留生成任务的自回归特性。
- HTLM[69]利用BART去噪目标对超文本语言进行建模,超文本语言包含有关文档级结构的宝贵信息。该模型在各种生成任务的零样本学习中也实现了最先进的性能。
- DQ-BART[70]将BART压缩为较小的模型,从而在各种下游任务上实现BART的原始性能。
T5演化出Switch Transformer、ExT5;
bert和GPT→bart
BART演化出HTLM、DQ-BART

InstructGPT[10]的体系结构。首先,使用人类贴标机收集演示数据并且用于微调GPT-3。然后从语言中抽取提示和相应的答案模型和人类标签将从最好到最差对答案进行排名。这些数据用于训练奖励模型。最后,通过训练的奖励模型,可以根据偏好对语言模型进行优化人类贴标机。
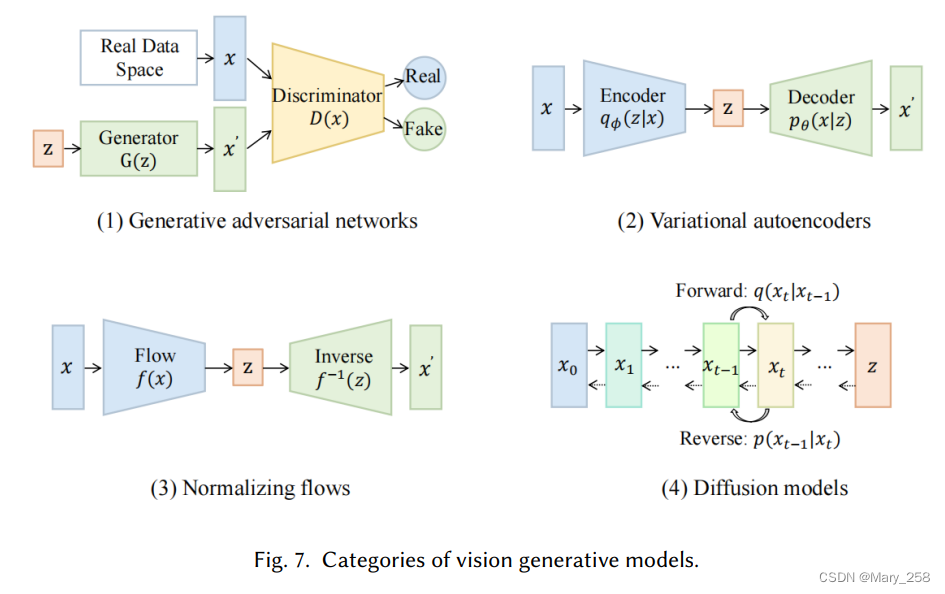
4.1.2 图像生成模型-Vision Generative Models
GAN
GANs consist of two parts, a generator生成器 and a discriminator鉴别器.生成器用于生成数据,鉴别器用于判别数据是否为真实数据。生成器和鉴别器的结构对GAN的训练稳定性和性能有很大影响。
Structure结构
LAPGAN[71]使用拉普拉斯金字塔框架[72]内的卷积网络级联,以从粗到细的方式生成高质量图像。
A.Radford等人[73]提出了DCGANs结构,这是一类具有架构约束的CNN,作为无监督学习的强大解决方案。
渐进式GAN[74]逐步扩展生成器和鉴别器,从低分辨率开始,添加层来建模更精细的细节,从而实现更快、更稳定的训练并生成高质量的图像。
由于传统的卷积GANs仅基于低分辨率特征图中的空间局部点来生成高分辨率细节,SAGAN[75]引入了注意力驱动、长程依赖性建模和频谱归一化,以改进训练动力学。
为了解决从复杂的数据集生成高分辨率和多样化的样本,BigGAN[76]被提出作为GANs的大规模TPU实现。
StyleGAN[77]通过分离高级属性和变体来改进GANs,从而在质量度量、插值和解纠缠方面实现直观的控制和更好的性能。[78,79]专注于反向映射——将数据投影回潜在空间,从而为辅助判别任务提供有用的特征表示。
为了解决模式崩溃问题并改进生成模型,D2GAN[80]和GMAN[81]方法都通过组合额外的鉴别器来扩展传统的GAN。
MGAN[82]和MAD-GAN[83]通过结合多个生成器和一个鉴别器来解决模式崩溃问题。CoGAN[84]由一对具有权重共享约束的GAN组成,允许从单独的边缘分布学习联合分布,而不需要训练集中的相应图像。
代表性变体
作为潜在矢量𝑧的生成器是高度非结构化的,InfoGAN[85]提出了另一种潜在的代码𝑐以提取实际数据空间的重要结构化特征。在CGAN[86-88]中,生成器和鉴别器以附加信息为条件,如类别标签或来自其他模态的数据,以生成以特定属性为条件的样本。f-GAN[89]允许使用任何f-散度作为训练生成模型的目标函数。f散度的选择为控制生成样本的质量和训练模型的难度之间的权衡提供了一个灵活的框架。
objective目标功能
生成模型的目标是匹配真实的数据分布。WGAN[90]和LS-GAN[91,92]旨在用真实数据密度上的Lipschitz正则性条件正则化损失函数,以便更好地推广和产生真实的新数据。[93]是一种权重归一化技术,用于稳定GANs中鉴别器的训练。Che等人[94]将目标正则化,这可以稳定GAN模型的训练。
UGAN[95]通过定义关于鉴别器的展开优化的生成器目标来稳定GANs的训练。[96]通过对真实/生成的数据对进行采样,使鉴别器具有相对性,以提高生成器生成的数据分布的稳定性和覆盖率。
VAE
根据变分贝叶斯推断[97],变分自动编码器(VAE)是一种生成模型,试图将数据反映到概率分布中,并学习接近其原始输入的重建。
复杂的先验知识
重写变分自动编码器的变分证据下界目标(ELBO)有助于改进变分边界[98]。由于真正的聚合后验是难以处理的,VampPrior[99]引入了以可学习伪输入为条件的后验先验的变分混合。[100-102]提出了围绕随机采样过程的跳跃连接,以捕捉数据分布的不同方面。
正则化自动编码器
[1103104]将正则化引入编码器的潜在空间,并导致平滑且具有代表性的潜在空间而不符合任意选择的先验。[105]提出了一种多尺度层次组织来对较大的图像进行建模。
Flow
归一化流是通过一系列可逆和可微映射从简单到复杂的分布变换。
耦合流和自回归流。
通过[57]中的耦合方法学习数据的非线性确定性变换,以使变换后的数据符合因子分解分布。
Dinh等人[106]提出了多尺度流,以在生成方向上逐渐将维度引入分布。耦合层的一个更灵活的概括是自回归流[107-109],它允许将并行密度估计作为通用逼近器。
卷积流和残差流。
郑等人[110]使用了1D卷积(ConvFlow)和Hoogeboom等人[111]为d×d卷积建模提供了更通用的解决方案。他们利用三角形结构来改善输入之间的相互作用,并有效地计算行列式。
RevNets[112]和iRevNets[113]是第一个基于残差连接构建可逆网络架构的网络,这缓解了梯度消失的问题。此外,残差连接可以被视为一阶常微分方程(ODE)[114]的离散化,以提高参数效率。
DIFFUSION
扩散生成扩散模型(GDM)CV最先进的结果。
工作原理:用多级噪声扰动逐渐破坏数据,然后学习反转这一过程以生成样本。
模型配方
扩散模型主要分为三类。
- DDPM[115]分别应用两个马尔可夫链来逐步破坏具有高斯噪声的数据,并通过学习马尔可夫转移核来逆转前向扩散过程。基于分数的生成模型(SGM)直接处理数据的对数密度梯度,也称为分数函数。
- NCSN[31]用多尺度增强噪声扰动数据,并通过以所有噪声水平为条件的神经网络联合估计所有此类噪声数据分布的得分函数。由于训练和推理步骤完全解耦,它享有灵活的采样。
- Score SDE[116]将前两个公式推广到连续设置中,其中噪声扰动和去噪过程是随机微分方程的解。证明了概率流ODE也可以用于逆向过程的建模。
加强培训
- 训练增强旨在通过引入来自另一个预训练模型或额外可训练超参数的先验知识来改进采样。受知识提取思想的启发,Salimans等人[117]提出将知识从预先训练的复杂教师模型逐步提取到更快的学生模型,这可以将采样步骤减半。
- TDPM[118]和ES-DDPM[119]通过截断扩散过程并提前停止来提高采样速度。为了从由非高斯分布初始化的反向过程中生成样本,引入另一个预训练的生成模型,如VAE或GAN来近似这种分布。
- Franzese等人[120]将训练步骤的数量公式化为变量,以实现最佳权衡。改进的DDPM[121]首先通过在损失函数中添加噪声标度项来引入噪声标度调谐。
- San Romans等人[122]引入了一种噪声预测网络,以实现噪声调度的逐步调整。这种噪声调度学习通过在训练和推理期间有效地引导噪声的随机游动来改进重构。
高效培训免费采样
与额外的训练不同,训练自由采样直接减少了离散化时间步长的数量,同时最小化了离散化误差。
- 在相同的训练目标下,DDIM[123]将DDPM推广到一类非马尔可夫扩散过程,并引入了跳跃步加速。这可以提供更短的生成马尔可夫链。
- AnalyticDPM[124]通过估计最优模型逆方差和KL方差的分析形式及其得分函数,提供了更有效的推理。还有一些工作[1252126]通过动态规划直接计算出最佳采样轨迹。
噪声分布
噪声扰动的分布是扩散模型的重要组成部分,其中大多数是高斯扰动。同时,用更多的自由度来拟合这样的分布可以提高性能。
- Nachmani等人[127]证明了伽玛分布可以改善图像和语音的生成,高斯分布的混合也优于单一分布。
- 冷扩散[128]提出了一个更普遍的结论,即噪声可以设置为任何分布,因为扩散模型的生成行为并不强烈依赖于噪声分布的选择。
- 除了噪声扰动之外,CCDF[129]表明,没有必要从高斯分布进行初始化,并且它可以通过简单的前向扩散来减少采样步骤,但更好的噪声初始化。
混合建模
混合建模旨在将扩散模型与另一类生成模型相结合,充分发挥它们的优势,提供更强的表现力或更高的采样速度。
- DiffuseVAE[130]通过用VAE生成的模糊图像重建调节扩散采样过程,将标准VAE合并到DDPM管道中。
- LSGM[131]在VAE的潜在空间中训练SGM,这将SGM概括为非连续数据,并使SGM能够在小空间中更平滑地学习。
- 去噪扩散GANs[132]将条件GANs引入DDPM管道,以更具表现力的多模式分布参数化去噪过程,从而提供大的去噪步骤。
- DiffFlow[133]将流函数集成到基于SDE的扩散模型的轨迹中,这使得前向步骤也是可训练的。介绍的噪声扰动的随机性赋予归一化流更强的表达能力,而可训练的正向过程显著减少了扩散轨迹的长度。因此DiffFlow能够以更好的采样效率学习边界更清晰的分布
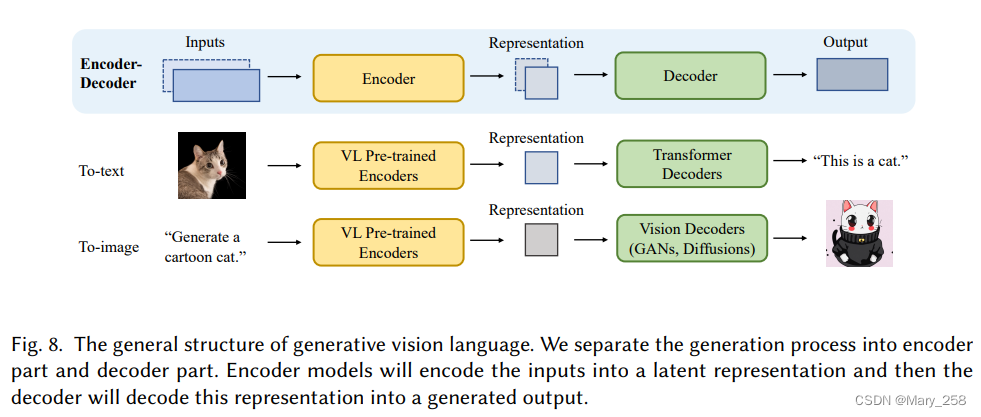
4.2 多单模态模型-Multimodal Models
在本节中,我们将介绍视觉语言生成、文本音频生成、文本图生成和文本代码生成中最先进的多模式模型。由于大多数多模式生成模型总是与现实世界的应用程序高度相关,因此本节将主要从下游任务的角度进行介绍。
4.2.1 视觉语言生成 Vision Language Generation
The encoder-decoder architecture在多模式生成中,特别是在VLG中,常被用作基础架构。编码器encoder负责学习输入数据的上下文化表示,而解码器decoder用于生成反映表示中跨模态交互、结构和连贯性的原始模态。在下文中,我们对最先进的视觉语言编码器进行了全面的调查,然后介绍了解码器组件。
Vision Language Encoders.
如何从多个模态中学习上下文化表示
一种常见的方法是使用融合函数组合特定于模态的编码器,然后利用多个预训练任务来对齐表示空间[371134135]。通常地这些编码器模型可以分为两类,级联编码器和交叉对准编码器[7]。
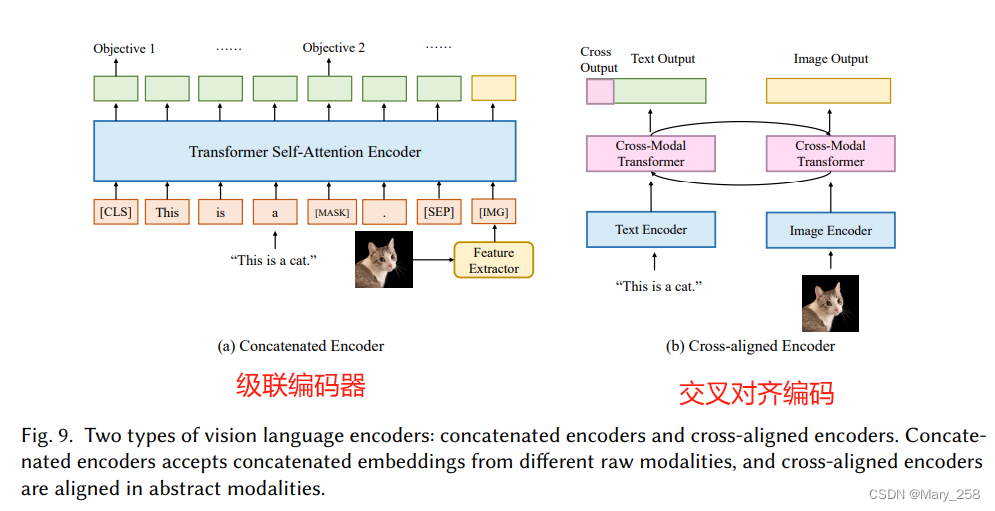
级联编码器
这个问题的直接解决方案是将来自单个编码器的嵌入连接起来。
-
VisualBERT[134],它利用BERT作为文本编码器,CNN作为图像编码器。来自图像编码器的嵌入将直接合并到BERT输入嵌入中,允许模型隐式学习对齐的联合表示空间。VisualBERT还利用了多任务预训练范式作为BERT,使用了两个基于视觉的语言模型目标:带图像的掩蔽语言建模和句子图像预测。此外,VisualBERT还纳入了一些特定于模态的预三角测量目标。
-
VL-BERT[136],它与VisualBERT共享相似的体系结构。与VisualBERT不同,VL-BERT使用Faster R-CNN[137]作为感兴趣区域(ROI)提取器,并利用提取的ROI信息作为图像区域嵌入。VL-BERT还包括一个额外的预训练任务,即带有语言线索的掩蔽ROI分类,以更好地整合视觉信息。
-
UNITER[138]基于与VisualBERT相同的架构提出,但具有不同的培训目标。UNITER使用掩蔽语言建模、掩蔽区域建模、图像-文本匹配预测和单词区域对齐预测作为其预训练任务。通过这种方式,UNITER可以学习信息丰富的上下文嵌入。
上述为级联编码器基于相同的BERT架构,并使用类似BERT的任务进行预训练的例子。然而,这些模型总是涉及非常复杂的预训练过程、数据收集和损失设计。 -
为了解决这个问题,[135]提出了SimVLM,通过将PrefixLM设置为训练目标,并直接使用ViT作为文本编码器和图像编码器,简化了视觉语言模型的预训练过程。与以前简化架构的方法相比,SimVLM在多个视觉语言任务上实现了最先进的性能。
交叉对齐编码器
除了将embedding连接为编码器的输入外,学习上下文化表示的另一种方法是观察模态之间的成对交互[7]。与级联编码器不同,交叉对准编码器使用双塔结构,其中每个模态一个塔,然后使用交叉模态编码器学习联合表示空间。
- LXMERT[139]使用Transformers提取图像特征和文本特征,然后添加多模式交叉注意力模块进行协调学习。由此产生的输出嵌入将是视觉嵌入、语言嵌入和多模式嵌入。该模型还通过几个多模式任务进行了预训练。
- ViLBERT[140]利用跨转换器模块来对齐两种模态。给定视觉和语言嵌入,一个特定模态的键和值将被输入到另一个模态的注意力模块中,以生成合并了这两种信息的集中注意力嵌入。通常,这些模型都利用跨层将信息融合到联合表示空间中。然而,在这种情况下使用转换器架构由于其大量的参数而将是低效的。
- 为了简化训练过程和计算,CLIP[37]使用点积作为交叉层,这比变压器编码器更高效,实现了高效的大规模下游训练。此外,CLIP是在大量的成对数据上训练的,这些数据已经被证明优于许多其他模型。
Vision Language Decoders.
视觉语言解码器。给定来自某个模态的表示,视觉语言解码器的主要目的是将其转换为任务指定的某个原始模态。在本节中,我们将主要关注文本和图像解码器。to text和to image
To-text decoder
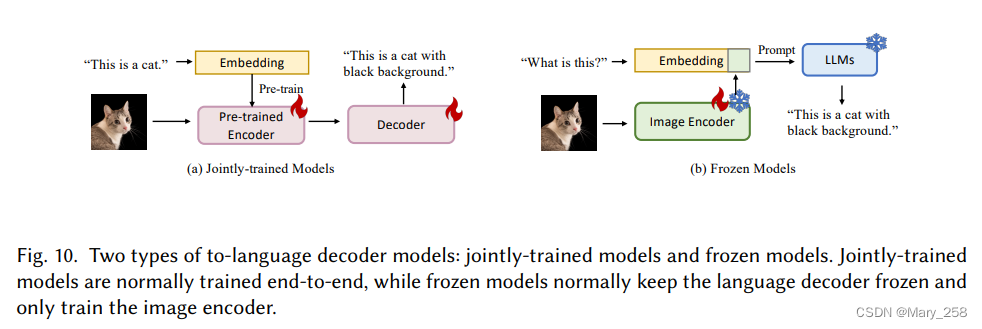
To-text decoder获取上下文化的表示,并将该表示解码为句子。
随着大型语言模型的出现和被证明的有效性,许多体系结构现在都在选择性地冻结语言解码器组件。因此,To-text decoder可以大致分为两种类型: jointly-trained models and frozen models联合训练模型和冻结模型。
jointly-trained models联合训练模型。联合训练解码器是指在解码表示时需要进行完整的跨模态训练的解码器。文本到文本生成的挑战通常在于在预训练期间调整这两种模式。因此,该模型需要更强的编码器而不是解码器。
许多模型优先构建一个强大的编码器,然后将其与相对轻量级的解码器模型相结合。
VLP[138]和ALBEF[141]利用简单的变换器解码器来解码信息。
BLIP[142]在预训练期间将编码器和解码器组合在一起,允许多模式空间对齐以实现理解和生成目标。BLIP由三个部分组成,一个用于提取图像和文本特征的单峰编码器,一个接受图像和文本特性作为输入的基于图像的文本编码器,以及一个接受图片特性并输出文本的基于图片的文本解码器。除了对齐的编码器和解码器结构外,作者还设计了几个相应的预训练任务,以帮助模型更好地学习多模式依赖性。
Frozen decoder
另一种有效执行文本生成任务的方法是to freeze the large language model and train an image encoder only,冻结语言模型,只训练图像编码器。由于NLP中prompting和上下文学习的成功,人们越来越关注这种性质的方法。
Frozen[143]首次将上下文学习引入视觉语言任务。它冻结语言模型,只训练图像编码器。生成的图像表示将被嵌入到语言模型的input embedding中。该方法在各种零样本和少样本视觉语言任务中实现了最先进的性能。
后来,Alayrac等人提出了Flamingo[144],进一步探索了上下文学习中的多模式。Flamingo涉及一个冻结的视觉编码器和一个冻结语言编码器来获得视觉语言表示,并利用门控交叉注意力密集层 gated cross-attention-dense layer将图像表示转化为文本表示。
最近,[145]提出了一种使用冻结语言模型实现VL对话的方法,使该模型能够生成交织的多模式数据。该方法还冻结输入编码器,并训练文本到图像和图像到文本的线性映射,以进一步编码和解码生成的嵌入。然而,为什么这种基于提示的方法在多模式生成中有效仍然是一个问题。也有人提出了一些作品来回答这个问题。
Merullo等人提出了一种方法[146],该方法在冻结图像编码器和文本编码器之间注入线性投影。在训练过程中,只调整线性投影。实验结果表明,具有相似大小的冻结语言模型在将视觉信息转换为语言方面通常表现得同样好,但经过语言监督预训练的图像编码器(如CLIP文本编码器)可以对额外信息进行编码,从而在视觉语言任务中表现得明显更好。
To-image decoder
给定指令,生成与该指令相对应的图像。类似地,图像生成中常用的模型也遵循编码器-解码器架构,其中编码器更专注于学习语言信息,而解码器更专注于利用学习的信息来限制图像合成。一般来说,最近的工作可以分为两类,基于GAN的方法和基于扩散的方法。
GAN based decoder
基于GAN的解码器。给定文本编码器φ(t),基于GAN的方法将鉴别器D和生成器G相结合,其中生成器G接受由φ(t)。
StackGAN[148]是该领域的一个著名模型。StackGAN体系结构由两个阶段组成:调整阶段和细化阶段。在调整阶段,模型将文本描述作为输入,并生成低分辨率图像。然后将该图像输入到细化阶段,在那里进一步细化以生成与文本描述匹配的高分辨率图像。AttnGAN[149]是另一个基于StackGAN架构的文本到图像合成模型。Attngan为StackGAN架构添加了一个注意力机制,以进一步提高生成图像的质量。
然而,这些模型在教学过程中主要使用相对简单的文本编码器,这可能会导致一定的信息损失。
StyleCLIP[150]是一种最新的文本到图像合成模型,它使用对比学习来对齐文本和图像特征。它基于StyleGAN[77]架构,代表了对以前的文本到图像合成模型(如StackGAN)的重大进步。StyleCLIP还遵循编码器-解码器结构,该结构使用文本编码器对指令进行编码,并使用图像解码器合成新图像。StyleCLIP的关键创新之一是使用对比学习来对齐文本和图像特征。通过训练模型以最大化文本和图像特征之间的相似性,同时最小化不同文本和图像对之间的相似度,StyleCLIP能够学习文本和图像特性之间更有效的映射,从而实现更高质量的图像合成。
Diffusion-based decoders
生成图像建模最近在使用扩散模型方面取得了巨大成功。这些模型也已应用于文本到图像的生成。
- GLIDE[151]将烧蚀扩散模型(ADM)引入文本到图像生成中。与以前的基于扩散的方法相比,GLIDE使用了具有3.5B参数的更大模型和更大的成对数据集,在许多基准上获得了更好的结果。
- Imagen[152]将冻结的T5语言模型与超分辨率扩散模型相结合。冻结编码器将对文本指令进行编码并生成嵌入,然后第一扩散模型将相应地生成低分辨率图像。第二扩散模型接受具有文本嵌入的该图像,并输出高分辨率图像。
- DALL-E-2[5]将CLIP编码器与扩散解码器相结合,用于图像生成和编辑任务。与Imagen相比,DALL-E-2利用先验网络在文本嵌入和图像嵌入之间进行翻译。
除了在模型设计方面的进步之外,这些基于扩散的模型与以前的生成方法之间的另一个主要区别是,这些基于传播的模型通常在具有更多参数的更大数据集上进行训练,这使它们能够比其他模型学习更好的表示。
除了前面提到的方法之外,还有使用VAE作为解码器的工作。例如,Ramesh等人提出了DALL-E[33],这是一种零样本图像生成器,在推理过程中使用dVAE作为图像编码器和解码器,BPE作为文本编码器和预先训练的CLIP。
4.2.2 文本音频生成 Text Audio Generation
文本音频生成;合成任务,如语音合成;识别任务,如自动语音识别。
它们指的是将书面文本转换为口语或将人类语音准确地转录为机器可读文本的过程。然而,文本音频生成是一项独特的任务,涉及使用多模式模型创建新颖的音频或文本。虽然相关,但文本音频生成、合成和识别任务的目标和实现目标所使用的技术不同。在这项工作中,我们专注于文本音频生成,而不是合成或识别任务。
Text-Audio Generation。
AdaSpeech[153]被提出通过利用两个声学编码器和mel声谱图解码器中的条件层归一化,使用有限的语音数据来高效地定制具有高质量的新语音。由于先前的研究在风格转换方面存在局限性,Lombard[154]利用频谱整形和动态范围压缩[155]在存在噪声的情况下生成高清晰度语音。跨语言生成是另一项有影响力的跨语言传递声音的工作。[156]可以用多种语言产生高质量的语音,并通过使用音素输入表示和对抗性损失项来区分说话者身份和语音内容,在不同语言之间传递语音。
Text-Music Generation
- [157]提出了一种用于音频和歌词的深度跨模态相关学习架构,其中使用跨模态规范相关分析来计算音频和歌词之间的时间结构的相似性。为了更好地学习社交媒体内容
- JTAV[158]使用跨模态融合和注意力池技术融合文本、声学和视觉信息。
- [159]结合了与音乐更相关的多种类型的信息,如播放列表、曲目交互和流派元数据,并将其潜在表示与独特的音乐片段建模相一致。
此外,还有一些工作专注于在音频作为输入的情况下生成文本信息,如描述和字幕。 - [160]被提出通过结合音频内容分析和自然语言处理来生成音乐播放列表的描述,以利用每个曲目的信息。
- MusCaps[161]是一种音乐音频字幕模型,通过多模式编码器处理音频文本输入并利用音频数据预训练来获得有效的音乐特征表示,从而生成音乐音频内容的描述。
- 对于音乐和语言预训练,Manco等人[162]提出了一种多模式架构,该架构使用弱对齐文本作为唯一的监督信号来学习通用音乐音频表示。
- CLAP[163]是另一种从自然语言监督中学习音频概念的方法,它利用两个编码器和对比学习将音频和文本描述带入联合多模式空间。
4.2.3 知识图谱Text Graph Generation
知识图谱(Knowledge Graph,KG)是语言处理系统中以图结构形式反映语义内部状态之间关系的结构意义表示。越来越多的作品从文本中提取KG来帮助文本生成,文本生成将复杂的想法融入多个句子中。语义解析也可以被公式化为文本到图生成的问题。它旨在将自然语言文本转换为一种逻辑形式,主要是抽象意义表示(AMR)[164],这是一种广泛覆盖的句子级语义表示。与文本到KG的生成相比,它强调提供机器可解释的表示,而不是构建语义网络。相反,KG-to-text生成的目的是在已经构建的KG的基础上生成流畅、逻辑连贯的文本。除了NLP领域之外,文本图生成还可以推动计算机辅助药物设计的边界向前发展。有一些新兴的作品将高度结构化的分子图与语言描述联系起来,有助于人类理解深刻的分子知识和新颖的分子探索。下面,我们将简要概述这四个主题中的一些代表作。
文本生成知识图谱Text To Knowledge Graph Generation
李等人[165]将文本到KG的构建视为知识图完成(KGC)的过程,其中缺失的项逐渐被推理所覆盖。采用双线性模型和另一个基于DNN的模型来嵌入项并计算任意元组的分数以进行加法运算。
KG-BERT[166]利用预先训练的语言模型的力量,在KGC过程中捕获更多的上下文信息。其思想是将三元组表示为文本序列,并通过微调的BERT模型将图完成建模为序列分类问题。Malaviya等人[167]提出了一种结合图卷积网络(GCN)的方法,用于提取更多的结构和语义上下文。它还通过引入图扩充和渐进掩蔽策略来解决图的稀疏性和可扩展性问题。或者,另一系列工作[168-170]直接查询预先训练的语言模型,以获得语义知识网络。具体来说,语言模型被反复提示预测完形填空中的掩蔽项,以获得关系知识。CycleGT[171]是一种无监督的方法,允许文本KG双向翻译。采用无监督循环训练策略来提供自我监督,这使得整个训练过程可以使用非并行的文本和图形数据。利用类似的策略,DualTKB[172]进一步证明,即使在弱监督的情况下,模型性能也可以得到很大改善。Lu等人[173]提出了一种统一的文本到图框架,该框架包含了大多数信息提取任务。同时,使用预定义的模式可能会将其泛化限制为节点和边的不同文本形式。Grapher[174]通过在两个独立的阶段生成节点和边,有效地执行端到端文本到KG的构建。具体而言,首先使用实体提取任务对预先训练的语言模型进行微调,以生成节点。随后,引入焦点损失和稀疏邻接矩阵来解决边缘构建过程中的偏斜边缘分布问题。
知识图谱生成文本Knowledge Graph To Text Generation
GTR-LSTM[176]是一个序列到序列的编码器-解码器框架,它从线性化的KG三元组生成文本。它可以处理以千克为单位的周期,以获取全球信息。同时,它的线性化图性质仍然可能导致相当大的结构信息损失,尤其是对于大型图。为了解决这个问题,Song等人[177]使用图状态LSTM对图语义进行编码,该LSTM能够在一系列状态转换期间在节点之间传播信息。事实证明,它能够对节点之间的非局部交互进行建模,同时由于高度并行化而高效。赵等人[175]提出了双重编码模型DULENC,以弥合输入图和输出文本之间的结构差异。具体而言,它利用基于GCN的图编码器来提取结构信息,同时还采用神经规划器来创建图的顺序内容计划,以生成线性输出文本。或者,Koncel Kedziorski等人[178]使用从图注意力网络(GAT)[179]扩展而来的基于转换器的架构对用于文本生成的图结构进行编码。其思想是通过自注意机制遍历KG的局部邻域来计算KG的节点表示。相反,Ribeiro等人[180]专注于联合利用局部和全局节点编码策略来从图上下文中捕获互补信息。HetGT[181]改编自transformer,旨在独立建模图中的不同关系,通过简单地混合它们来避免信息丢失。首先将输入图转换为异构Levi图,然后基于每个部分的异构性将其拆分为子图,用于未来的信息聚合。
语义分析Semantic Parsing
早期的工作[182183]将语义解析表述为序列到序列的生成问题。然而,AMR本质上是一个结构化对象。序列到序列问题设置只能捕获较浅的单词序列信息,同时可能忽略丰富的语法和语义信息。Lyu等人[184]通过将AMR表示为根标记的有向无环图(DAG),将语义解析建模为图预测问题。这需要图中的节点和句子中的单词之间的对齐。提出了一种神经解析器,将对齐作为联合概率模型中的潜在变量,用于AMR解析过程中的节点对齐和边缘预测。Chen等人[185]通过神经序列到动作的RNN模型构建具有动作集的语义图。在解码过程中,通过整合结构和语义约束来加强解析过程。张等人[186]通过一个无对齐器的基于注意力的模型来解决AMR解析中的可重入性问题,该模型将问题公式化为序列到图的转导。利用指针生成器网络,证明了在有限的标记AMR数据下可以有效地训练模型。Fancellu等人[187]提出了一种图感知序列模型来构建AMR图预测的线性化图。在没有潜在变量的情况下,它通过一种新颖的图感知字符串重写策略,确保每个形式良好的字符串只与一个派生字符串配对。
文本分子生成Text Molecule Generation
Text2Mol[189]是一个基于语言描述的跨模态信息检索系统,用于检索分子图。基于BERT的文本编码器和MLP-GCN组合的分子编码器被用于在语义空间中创建多模式嵌入,该语义空间通过与配对数据的对比学习来对齐。MolT5[190]没有从现有分子中检索,而是提出了一种用于文本条件下的从头分子生成和分子字幕的自监督学习框架。它通过预训练和微调策略解决了跨模态数据对的稀缺性。具体来说,它以去噪为目标,在未配对的文本和分子串上预训练模型,然后用有限的配对数据进行微调。然而,受其线性化图性质的限制,基于字符串的分子表示不是唯一的,可能会导致结构信息丢失。为了解决这个问题,MoMu[188]引入了一种基于图的多模态框架,该框架通过对比学习联合训练两个独立的编码器,用于与弱配对的跨模态数据进行语义空间对齐。除了从头生成分子图之外,它还可以适用于各种下游任务。
4.2.4 Text Code Generation
文本代码生成旨在从自然语言描述中自动生成有效的程序代码或提供编码辅助。LLM最近在从自然语言(NL)描述生成编程语言(PL)代码方面显示出巨大的潜力。早期的工作直接将文本代码生成公式化为纯语言生成任务。然而,NL和PL是具有固有不同模态的数据类型,在语义空间对齐期间,额外的策略对于捕获NL和PL之间的相互依赖性至关重要。与NL数据相比,PL数据还封装了丰富的结构信息和不同的语法,这使得从PL上下文中理解语义信息更具挑战性。此外,文本代码模型也被期望是多语言的,因为它们可以提供更好的泛化能力。在下文中,我们主要介绍以NL描述为条件的代码生成模型。我们还回顾了其他基于语言的编码辅助模型。
Text-conditioned Programming Code Generation
文本条件编程代码生成。CodeBERT[191]是一个基于双峰Transformer的预训练文本代码模型,可以捕捉NL和PL之间的语义连接。它采用混合目标函数,利用二项式NL-PL配对数据进行模型训练,利用单峰PL代码数据分别学习更好的生成器,以在语义空间中对齐NL和PL。为了更好地泛化,该模型在六个多语言PL上进行了进一步的预训练。CuBERT[192]与CodeBERT共享相似的模型架构,同时不需要在函数的自然语言描述与其主体之间执行语句分离以进行语句对表示。CodeT5[193]提出了一种预训练的编码器-解码器Trans-former模型,该模型可以更好地从代码中捕获上下文化的语义信息。具体来说,它引入了新的标识符感知预训练任务,通过区分标识符和代码令牌来保存关键的令牌类型信息,并在屏蔽时恢复它们。PLBART[194]在统一的框架下,将双峰文本代码模型从生成任务扩展到更广泛的判别任务类别,如克隆和易受攻击代码检测。另一系列工作[195196]引入了程序图[197]的概念,以明确地对PL代码的底层结构进行建模,从而帮助生成。程序图被构造为抽象语法树(AST),以封装来自程序特定语义和语法的知识。
Interactive Programming System
交互式编程系统。文本代码生成受到编程代码生成的棘手搜索空间和由于NL的固有模糊性而导致的用户意图的不适当指定的共同挑战。CODEGEN[198]提出了一种多回合程序合成方法,该方法将以单个复杂NL规范为条件的程序合成分解为由一系列用户意图控制的渐进生成。它以自回归变换器的形式构建,学习给定先前令牌的下一个令牌的条件分布,并在PL和NL数据上进行训练。TDUIF[199]通过形式化用户意图并提供更易于理解的用户反馈,扩展了交互式编程框架。它进一步实现了可扩展的自动算法评估,不需要高保真度的用户交互建模来实现用户在环。
AIGC落地场景应用
Chatbot
艺术
音乐
代码
教育














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









