






Introduction
本文是谷歌发表的文章,针对nlp里的机器翻译问题,提出了一种被称为”Transformer”的网络结构,基于注意力机制。文章提出,以往nlp里大量使用RNN结构和encoder-decoder结构,RNN及其衍生网络的缺点就是慢,问题在于前后隐藏状态的依赖性,无法实现并行,而文章提出的”Transformer”完全摒弃了递归结构,依赖注意力机制,挖掘输入和输出之间的关系,这样做最大的好处是能够并行计算了。
Attention mechanisms
注意机制已成为各种任务中引人注目的序列建模和转导模型的组成部分,允许其中中建模依赖关系,而不考虑它们的距离 输出序列。然而,在除少数情况外的所有情况下,这种注意机制都与一个递归网络一起使用。
Background

传统的编码器解码器一般使用RNN,这也是在机器翻译中最经典的模型,但正如我们都知道的,RNN难以处理长序列的句子,无法实现并行,并且面临对齐问题。
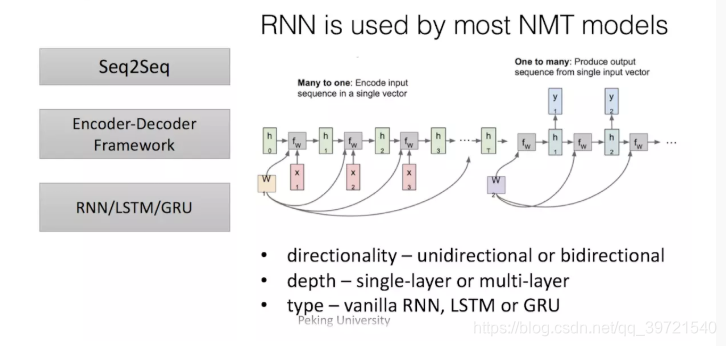
之后这类模型的发展大多从三个方面着手:
input的方向性 - 单向或双向
深度 - 单层或多层
类型– RNN,LSTM或GRU

但是依旧收到一些潜在问题的制约,神经网络需要能够将源语句的所有必要信息压缩成固定长度的向量。这可能使得神经网络难以应付长时间的句子,特别是那些比训练语料库中的句子更长的句子;每个时间步的输出需要依赖于前面时间步的输出,这使得模型没有办法并行,效率低;仍然面临对齐问题。
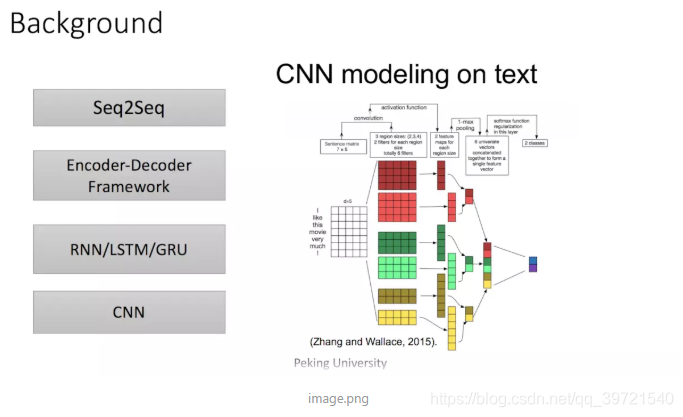
再然后CNN由计算机视觉也被引入到deep NLP中,CNN不能直接用于处理变长的序列样本但可以实现并行计算。完全基于CNN的Seq2Seq模型虽然可以并行实现,但非常占内存,很多的trick,大数据量上参数调整并不容易。

以上这些缺点的话就是由于无论输入如何变化,encoder给出的都是一个固定维数的向量,存在信息损失;在生成文本时,生成每个词所用到的语义向量都是一样的,这显然有些过于简单。为了解决上面提到的问题,一种可行的方案是引入attentionmechanism。
Attention
-
Attention与NLP开山之作:Neural machine translation by jointly learning to align and translate https://arxiv.org/pdf/1409.0473.pdf

这篇论文首先将注意力机制运用在NLP上,提出了soft Attention Model,并将其应用到了机器翻译上面。其实,所谓Soft,意思是在求注意力分配概率分布的时候,对于输入句子X中任意一个单词都给出个概率,是个概率分布。加入注意力机制的模型表现确实更好,但也存在一定问题,例如:attention mechanism通常和RNN结合使用,我们都知道RNN依赖t-1的历史信息来计算t时刻的信息,因此不能并行实现,计算效率比较低,特别是训练样本量非常大的时候。 -
Encoder:CNN+Attention

基于CNN的Seq2Seq+attention的优点:基于CNN的Seq2Seq模型具有基于RNN的Seq2Seq模型捕捉long distance dependency的能力,此外,最大的优点是可以并行化实现,效率比基于RNN的Seq2Seq模型高。缺点:计算量与观测序列X和输出序列Y的长度成正比。
Transformer

注意力机制(Attention)简单来说就是给定一个查找(query)和一个键值表(key-value pairs),将query映射到正确的输入的过程。此处的query、key、value和最终的输出都是向量。输出往往是一个加权求和的形式,而权重则由query、key和value决定。

有两种常用的注意力函数,一种是加法注意力(additive attention),另外一种是点乘注意力(dot-productattention),论文所采用的就是点乘注意力,这种注意力机制对于加法注意力而言,更快,同时更节省空间。
输入q、k、v,分别代表query、key-valuepair。这里的 key,value, 和 query需要解释一下,这里把attention抽象为对 value() 的每个 token进行加权,而加权的weight就是 attentionweight,而 attention weight 就是根据 query和 key 计算得到,其意义为:为了用 value求出 query的结果, 根据 query和 key 来决定注意力应该放在value的哪部分。以前的 attention是用 LSTM 做 encoder,也就是用它来生成key 和 value,然后由 decoder来生成 query。
具体到 Bahdanau 的论文 Neural machine translation by jointly learning to align and translate,key 和 value是一样的,都是文中的h ,而 query是文中的 s。
为什么要乘以√1dk?是因为如果d_k太大,点乘的值太大,如果不做scaling,结果就没有加法注意力好。另外,点乘的结果过大,这使得经过softmax之后的梯度很小,不利于反向传播的进行,所以我们通过对点乘的结果进行尺度化。



Transformer会在三个不同的方面使用multi-headattention:
1.encoder-decoder attention:使用multi-head attention,输入为encoder的输出和decoder的self-attention输出,其中encoder的self-attention作为 key and value,decoder的self-attention作为query
encoder self-attention:使用 multi-head attention,输入的Q、K、V都是一样的(input embedding and positional embedding)
3.decoder self-attention:在decoder的self-attention层中,deocder 都能够访问当前位置前面的位置

https://zhuanlan.zhihu.com/p/46990010 这篇确实不错!















 99
99











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









