







1前言
在这里主要介绍决策树中的ID3算法以及C4.5算法的原理,由于代码比较多,我将代码放在Github中了,ID3的代码点击此处,C4.5的代码点击此处。
2 决策树简介
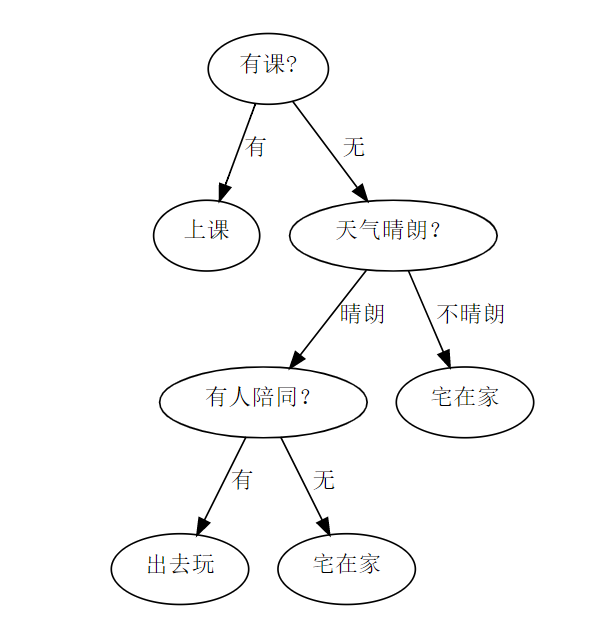
决策树顾名思义就是一个基于树形结构进行决策的过程。例如,我们要对明天是否出去玩?作一个决策,我们通常会作一系列判断,比如我们得先看“明天是否有课?”,如果是“没课”,则我们再看明天天气是否晴朗?,如果是“晴朗”,那么我们再进行判断明天是否有人一起出去玩?,最后如果是“有人陪同”,那么根据这一系列的判断,我们便得出最终结论,“出去玩!”,这个过程如下图所示。
3 如何构造决策树
由第一个例子可知,在构造好决策树的情况下,每条数据会不断的经过决策树的结点(即数据的属性)进行判断,然后该数据将会被归到不同的类别中去,不论有多少数据,决策树都可以把它们归到相应的类别中去,比如现在有100条数据,经过第一个例子后,有30条被归到了“上课”,有50条被归到了“出去玩”,有20条被归到了“宅在家”,也就是说决策树是根据属性将数据集进行分类的一个过程。既然决策树能够根据属性将数据集划分,那么反过来,根据属性划分数据集也就能够生成决策树!
下面有一个包含有5条样本的海洋生物的数据表,其中有两个属性用来判断该物种是否属于鱼类。接下来我们将用这个数据集来尝试建立决策树。
| 不浮出水面是否可以生存 | 是否有脚蹼 | 属于鱼类 | |
|---|---|---|---|
| 1 | 是 | 是 | 是 |
| 2 | 是 | 是 | 是 |
| 3 | 是 | 否 | 否 |
| 4 | 否 | 是 | 否 |
| 5 | 否 | 是 | 否 |
我们已经知道可以根据属性将数据集分类,然后依据属性和分类结果构造决策树。依据属性将数据集划分是很简单的事情,那么哪个属性在划分数据时起决定性作用呢?这将决定了我们使用属性进行判断的顺序,因此找到起决定性作用的属性,即选择最优划分属性,这就是决策树的精髓所在。一般而言,我们希望决策树的分支结点所包含的样品尽可能的属于同一个类别,即结点的纯度越来越高。所以可以根据划分之后数据集的“纯度”来决定最优划分属性。信息熵是度量样本集合纯度最常用的一种指标,因此我们可以用它来判断划分数据之前和之后数据集的纯度。
构造决策树的流程如下:
①检测数据集中每个子项是否属于同一分类,若不为则前往②,否则结束。
②寻找最优划分特征(属性),并依据特征划分数据集。
③对于每一个划分的数据集重复进行上述步骤 。
由流程可知,构建决策树需要用到递归,其停止的条件为(1)当前结点包含的样本全属于统一类别,无需划分;(2)当前属性已用完,或是所有样本在所有属性上取值相同,不能划分;(3)当前结点包含的样本集合为空,无法划分。
4 算法原理详解
4.1 ID3算法
ID3(Iterative Dichotomiser即迭代二分器)的简称,ID3算法是以信息增益为准则来选择划分属性的,再介绍信息增益之前,首先介绍下信息熵,信息熵的定义如下:假定当前集合
D
D
D中的样本共有
n
n
n个类别,的第
k
k
k个类别所占的比例为
p
k
(
k
=
1
,
2
,
.
.
.
,
n
)
p_{k}(k=1,2,...,n)
pk(k=1,2,...,n),则D的信息熵定义为
E
n
t
(
D
)
=
−
∑
k
=
1
∣
n
∣
p
k
log
2
p
k
Ent(D)=-\sum_{k=1}^{|n|}{p_{k}\log_{2}{p_{k}}}
Ent(D)=−k=1∑∣n∣pklog2pk
Ent(D)的值越小,则D的纯度越高。
信息增益(information gain)是基于信息熵的,其定义如下:假定离散属性
a
a
a有
m
m
m个可能的取值
{
a
1
,
a
2
,
…
,
a
m
}
\lbrace{a_{1},a_{2},\dots,a_{m}}\rbrace
{a1,a2,…,am},此时若采用属性
a
a
a来划分数据,则会产生
m
m
m个分支结点,其中第
i
{
i
ϵ
(
1
,
2
,
…
,
m
)
}
i\lbrace{i\epsilon(1,2,\dots,m)}\rbrace
i{iϵ(1,2,…,m)}个分支结点包含了
D
D
D中所有在属性
a
a
a上取值为
a
i
a_{i}
ai的样本,记该样本集合为
D
i
D_{i}
Di。我们可根据上式计算出
D
i
D_{i}
Di的信息熵,再考虑到不同分支结点所包含的样本数不同,给分支结点赋予权重
∣
D
i
∣
/
∣
D
∣
|D_{i}|/|D|
∣Di∣/∣D∣(其中
∣
D
i
∣
|D_{i}|
∣Di∣,
∣
D
∣
|D|
∣D∣分别表示
D
i
D_{i}
Di,
D
D
D中包含的样本的数量),即样本数越多的分支结点影响越大,于是可计算出用属性
a
a
a对样本
D
D
D进行划分所获得的信息增益
G
a
i
n
(
D
,
a
)
=
E
n
t
(
D
)
−
∑
i
=
1
m
∣
D
i
∣
∣
D
∣
E
n
t
(
D
i
)
Gain(D, a)=Ent(D)-\sum_{i=1}^{m}{{|D_{i}|\over|D|}Ent(D_{i})}
Gain(D,a)=Ent(D)−i=1∑m∣D∣∣Di∣Ent(Di) 一般而言,信息增益越大,则意味着使用属性
a
a
a来进行划分所获得的纯度提升越大。因此,我们可以用信息增益来进行决策树的划分属性选择。
由上表中的海洋数据集为例,该数据包含5个训练样本,用以学习一颗能判断该生物是否为鱼的决策树。再决策树开始时,根节点包含
D
D
D中所有样本,其中正例占
p
1
=
2
5
p_{1}={2\over5}
p1=52反例占
p
2
=
3
5
p_{2}={3\over5}
p2=53。于是根据公式(1)能计算出根节点的信息熵为
E
n
t
(
D
)
=
−
∑
k
=
1
2
p
k
log
2
p
k
=
−
(
2
5
log
2
2
5
+
3
5
log
2
3
5
)
=
0.971
Ent(D)=-\sum_{k=1}^{2}{p_{k}\log_{2}{p_{k}}}=-({2\over5}\log_{2}{2\over5}+{3\over5}\log_{2}{3\over5})=0.971
Ent(D)=−k=1∑2pklog2pk=−(52log252+53log253)=0.971 然后,我们要计算出当前属性集合
{
\lbrace
{不浮出水面是否可以生存,是否有脚蹼
}
\rbrace
}中每个属性的信息增益。以属性“不浮出水面是否可以生存”为例,它有2个可能的取值:
{
\lbrace
{是,否
}
\rbrace
}。若使用该属性对
D
D
D进行划分,则可以得到2个子集,分别记为
D
1
(
不
浮
出
水
面
是
否
可
以
生
存
=
是
)
D_{1}(不浮出水面是否可以生存=是)
D1(不浮出水面是否可以生存=是),
D
2
(
不
浮
出
水
面
是
否
可
以
生
存
=
否
)
D_{2}(不浮出水面是否可以生存=否)
D2(不浮出水面是否可以生存=否)。
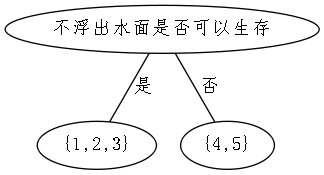
子集
D
1
D_{1}
D1包含编号
{
\lbrace
{ 1,2,3
}
\rbrace
}的3个样例,其中正例占
p
1
=
2
3
p_{1}={2\over3}
p1=32,反例占
p
2
=
1
3
p_{2}={1\over3}
p2=31,子集
D
2
D_{2}
D2包含编号
{
\lbrace
{ 4,5
}
\rbrace
}的2个样例,其中正例占
p
1
=
0
p_{1}={0}
p1=0,反例占
p
2
=
1
p_{2}={1}
p2=1,则根据公式(1)可以计算出用“不浮出水面是否可以生存”为属性划分之后所获得的3个分支结点的信息熵为
E
n
t
(
D
1
)
=
−
(
2
3
log
2
2
3
+
1
3
log
2
1
3
)
=
0.918
E
n
t
(
D
2
)
=
−
1
log
2
1
=
0
Ent(D_{1})=-({2\over3}\log_{2}{2\over3}+{1\over3}\log_{2}{1\over3})=0.918\\ Ent(D_{2})=-{1}\log_{2}{1}=0
Ent(D1)=−(32log232+31log231)=0.918Ent(D2)=−1log21=0 于是,根据公式(2)可计算出属性“不浮出水面是否可以生存”的信息增益为
G
a
i
n
(
D
,
不
浮
出
水
面
是
否
可
以
生
存
)
=
E
n
t
(
D
)
−
∑
i
=
1
3
∣
D
i
∣
∣
D
∣
E
n
t
(
D
i
)
=
0.971
−
(
3
5
×
0.918
+
2
5
×
0
)
=
0.4202
Gain(D, 不浮出水面是否可以生存)=Ent(D)-\sum_{i=1}^{3}{{|D_{i}|\over|D|}Ent(D_{i})} \\=0.971-({3\over5}\times0.918+{2\over5}\times0) \\=0.4202
Gain(D,不浮出水面是否可以生存)=Ent(D)−i=1∑3∣D∣∣Di∣Ent(Di)=0.971−(53×0.918+52×0)=0.4202 类似的,我们可以计算出其他属性的信息增益
G
a
i
n
(
D
,
是
否
有
脚
蹼
)
=
0.1710
Gain(D, 是否有脚蹼)=0.1710
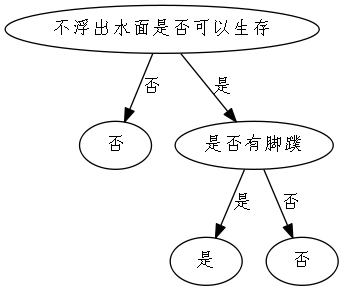
Gain(D,是否有脚蹼)=0.1710 显然,属性“不浮出水面是否可以生存”的信息增益最大,于是选择它为划分属性。下图给出了基于“不浮出水面是否可以生存”对根节点进行划分的结果,各分支结点所包含的样例显示再结点中。
4.2 C4.5算法
C4.5算法与ID3算法基本流程一样,不同的地方在于ID3算法使用的是信息增益准则来进行对数据的划分,而C4.5算法采用的是增益率(gain ration)来进行对数据的划分。信息增益准则对可取值数目较多的属性有所偏好,而增益率可以减少这种偏好带来的不利影响。增益率定义为
G
a
i
n
_
r
a
t
i
o
(
D
,
a
)
=
G
a
i
n
(
D
,
a
)
I
V
(
a
)
Gain\_ratio(D, a)={Gain(D, a)\over{IV(a)}}
Gain_ratio(D,a)=IV(a)Gain(D,a) 其中
I
V
(
a
)
=
−
∑
i
=
1
m
log
2
∣
D
i
∣
∣
D
∣
IV(a)=-\sum_{i=1}^{m}{\log_{2}{|D_{i}|\over{|D|}}}
IV(a)=−i=1∑mlog2∣D∣∣Di∣ 称为
a
a
a的属性固有值(instrinsic value)。属性
a
a
a的可能取值数目越多(即
m
m
m越大),则
I
V
(
a
)
IV(a)
IV(a)的值通常会越大。如我们的海洋生物数据,有
I
V
(
不
浮
出
水
面
是
否
可
以
生
存
)
=
0.971
(
m
=
2
)
IV(不浮出水面是否可以生存)=0.971(m=2)
IV(不浮出水面是否可以生存)=0.971(m=2),
I
V
(
是
否
有
脚
蹼
)
=
0.722
(
m
=
2
)
IV(是否有脚蹼)=0.722(m=2)
IV(是否有脚蹼)=0.722(m=2)。
需要注意的是,增益率准则对可取值数目较少的属性有所偏好,因此,C4.5算法并不是直接选择增益率最大的候选划分属性,而是使用了一个启发式思维:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。(PS:直接选择增益率最大也是可以的,不过另外一种方法能够减少算法的一些弊端)
5 总结
ID3算法采用信息增益来划分数据,它一般会优先选择有较多属性值的特征,因为属性值越多的特征会有较大的信息增益,而C4.5算法是采用的增益率来作为选择分支的准则,引入一个固有值来惩罚取值较多的特征。ID3和C4.5一般而言都是处理离散变量的数据,对于连续型变量的数据则采用CART( Classfication And Regression Tree即分类与回归树)算法。














 1727
1727











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









