







一.SRGAN原理
1.主要内容
(1)提出了SRGAN,一种用于图像超分辨率(SR)的生成对抗网络(GAN)。
(2)提出了一种感知损失函数,它包括对抗性损失和内容丢失。
(3)提出了广泛的平均意见得分(MOS)测试显示使用SRGAN在感知质量方面获得了巨大的显着提升。
2.GAN原理
它由两部分组成
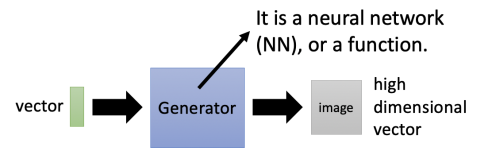
Generator生成器,它是一个深度神经网络,输入一个低维vector,输出高维vector(图片或文本或语音)
Discriminator判别器,它也是一个深度神经网络,输入一个高维vector(图片或文本或语音),输出一个标量。标量越大,代表输入图片(或文本语音)越真实。

generate生成新图片,从而可以骗过判别器。判别器也在不断迭代进化,努力识别越来越接近真实的假图片。通过二者对抗学习,最终生成器生成的假图片越来越像真实图片,而判别器越来越能区分和真实图片很接近的假图片。二者能力在迭代过程中,都可以得到大幅提升
3.SRGAN网络结构
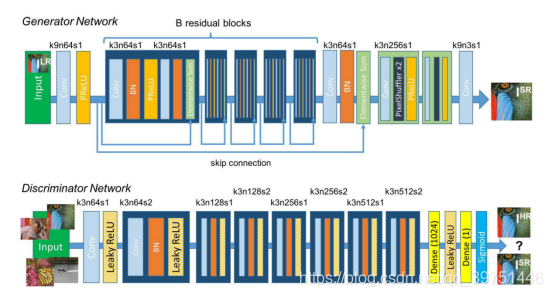
生成网络的构成如上图所示,生成网络的作用是输入一张低分辨率图片,生成高分辨率图片。:
SRGAN的生成网络由三个部``分组成。整体结构如以下程序
class SRResNet(nn.Module):
"""
SRResNet模型
"""
def __init__(self, large_kernel_size=9, small_kernel_size=3, n_channels=64, n_blocks=16, scaling_factor=4):
"""
:参数 large_kernel_size: 第一层卷积和最后一层卷积核大小
:参数 small_kernel_size: 中间层卷积核大小
:参数 n_channels: 中间层通道数
:参数 n_blocks: 残差模块数
:参数 scaling_factor: 放大比例
"""
super(SRResNet, self).__init__()
# 放大比例必须为 2、 4 或 8
scaling_factor = int(scaling_factor)
assert scaling_factor in {2, 4, 8}, "放大比例必须为 2、 4 或 8!"
# 第一个卷积块
self.conv_block1 = ConvolutionalBlock(in_channels=3, out_channels=n_channels, kernel_size=large_kernel_size,
batch_norm=False, activation='PReLu')
# 一系列残差模块, 每个残差模块包含一个跳连接
self.residual_blocks = nn.Sequential(
*[ResidualBlock(kernel_size=small_kernel_size, n_channels=n_channels) for i in range(n_blocks)])
# 第二个卷积块
self.conv_block2 = ConvolutionalBlock(in_channels=n_channels, out_channels=n_channels,
kernel_size=small_kernel_size,
batch_norm=True, activation=None)
# 放大通过子像素卷积模块实现, 每个模块放大两倍
n_subpixel_convolution_blocks = int(math.log2(scaling_factor))
self.subpixel_convolutional_blocks = nn.Sequential(
*[SubPixelConvolutionalBlock(kernel_size=small_kernel_size, n_channels=n_channels, scaling_factor=2) for i
in range(n_subpixel_convolution_blocks)])
# 最后一个卷积模块
self.conv_block3 = ConvolutionalBlock(in_channels=n_channels, out_channels=3, kernel_size=large_kernel_size,
batch_norm=False, activation='Tanh')
def forward(self, lr_imgs):
"""
前向传播.
:参数 lr_imgs: 低分辨率输入图像集, 张量表示,大小为 (N, 3, w, h)
:返回: 高分辨率输出图像集, 张量表示, 大小为 (N, 3, w * scaling factor, h * scaling factor)
"""
output = self.conv_block1(lr_imgs) # (16, 3, 24, 24)
residual = output # (16, 64, 24, 24)
output = self.residual_blocks(output) # (16, 64, 24, 24)
output = self.conv_block2(output) # (16, 64, 24, 24)
output = output + residual # (16, 64, 24, 24)
output = self.subpixel_convolutional_blocks(output) # (16, 64, 24 * 4, 24 * 4)
sr_imgs = self.conv_block3(output) # (16, 3, 24 * 4, 24 * 4)
return sr_imgs
1.低分辨率图像进入后会经过一个卷积+RELU函数。定义卷积块的函数如下:
class ConvolutionalBlock(nn.Module):
class ConvolutionalBlock(nn.Module):
"""
卷积模块,由卷积层, BN归一化层, 激活层构成.
"""
def __init__(self, in_channels, out_channels, kernel_size, stride=1, batch_norm=False, activation=None):
"""
:参数 in_channels: 输入通道数
:参数 out_channels: 输出通道数
:参数 kernel_size: 核大小
:参数 stride: 步长
:参数 batch_norm: 是否包含BN层
:参数 activation: 激活层类型; 如果没有则为None
"""
super(ConvolutionalBlock, self).__init__()
if activation is not None:
activation = activation.lower()
assert activation in {'prelu', 'leakyrelu', 'tanh'}
# 层列表
layers = list()
# 1个卷积层
layers.append(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride,
padding=kernel_size // 2))
# 1个BN归一化层
if batch_norm is True:
layers.append(nn.BatchNorm2d(num_features=out_channels))
# 1个激活层
if activation == 'prelu':
layers.append(nn.PReLU())
elif activation == 'leakyrelu':
layers.append(nn.LeakyReLU(0.2))
elif activation == 'tanh':
layers.append(nn.Tanh())
# 合并层
self.conv_block = nn.Sequential(*layers)
2、然后经过B个残差网络结构,每个残差结构都包含两个卷积+标准化+RELU,还有一个残差边。定义残差块的结构如下:
class ResidualBlock(nn.Module):
"""
残差模块, 包含两个卷积模块和一个跳连.
"""
def __init__(self, kernel_size=3, n_channels=64):
"""
:参数 kernel_size: 核大小
:参数 n_channels: 输入和输出通道数(由于是ResNet网络,需要做跳连,因此输入和输出通道数是一致的)
"""
super(ResidualBlock, self).__init__()
# 第一个卷积块
self.conv_block1 = ConvolutionalBlock(in_channels=n_channels, out_channels=n_channels, kernel_size=kernel_size,
batch_norm=True, activation='PReLu')
# 第二个卷积块
self.conv_block2 = ConvolutionalBlock(in_channels=n_channels, out_channels=n_channels, kernel_size=kernel_size,
batch_norm=True, activation=None)
def forward(self, input):
"""
前向传播.
:参数 input: 输入图像集,张量表示,大小为 (N, n_channels, w, h)
:返回: 输出图像集,张量表示,大小为 (N, n_channels, w, h)
"""
residual = input # (N, n_channels, w, h)
output = self.conv_block1(input) # (N, n_channels, w, h)
output = self.conv_block2(output) # (N, n_channels, w, h)
output = output + residual # (N, n_channels, w, h)
3、然后进入上采样部分,在经过两次上采样后,原图的高宽变为原来的4倍,实现分辨率的提升。上采样采用pixelshuffle的方式,及步长为1/r
判别网络的构成如上图所示:
class Discriminator(nn.Module):
"""
SRGAN判别器
"""
def __init__(self, kernel_size=3, n_channels=64, n_blocks=8, fc_size=1024):
"""
参数 kernel_size: 所有卷积层的核大小
参数 n_channels: 初始卷积层输出通道数, 后面每隔一个卷积层通道数翻倍
参数 n_blocks: 卷积块数量
参数 fc_size: 全连接层连接数
"""
super(Discriminator, self).__init__()
in_channels = 3
# 卷积系列,参照论文SRGAN进行设计
conv_blocks = list()
for i in range(n_blocks):
out_channels = (n_channels if i == 0 else in_channels * 2) if i % 2 == 0 else in_channels
conv_blocks.append(
ConvolutionalBlock(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=1 if i % 2 == 0 else 2, batch_norm=i != 0, activation='LeakyReLu'))
in_channels = out_channels
self.conv_blocks = nn.Sequential(*conv_blocks)
# 固定输出大小
self.adaptive_pool = nn.AdaptiveAvgPool2d((6, 6))
self.fc1 = nn.Linear(out_channels * 6 * 6, fc_size)
self.leaky_relu = nn.LeakyReLU(0.2)
self.fc2 = nn.Linear(1024, 1)
# 最后不需要添加sigmoid层,因为PyTorch的nn.BCEWithLogitsLoss()已经包含了这个步骤
def forward(self, imgs):
"""
前向传播.·
参数 imgs: 用于作判别的原始高清图或超分重建图,张量表示,大小为(N, 3, w * scaling factor, h * scaling factor)
返回: 一个评分值, 用于判断一副图像是否是高清图, 张量表示,大小为 (N)
"""
batch_size = imgs.size(0)
output = self.conv_blocks(imgs)
output = self.adaptive_pool(output)
output = self.fc1(output.view(batch_size, -1))
output = self.leaky_relu(output)
logit = self.fc2(output)
return logit
SRGAN的判别网络由不断重复的 卷积+LeakyRELU和标准化 组成。
对于判断网络来讲,它的目的是判断输入图片的真假,它的输入是图片,输出是判断结果。
判断结果处于0-1之间,利用接近1代表判断为真图片,接近0代表判断为假图片。
判断网络的构建和普通卷积网络差距不大,都是不断的卷积对图片进行下采用,在多次卷积后,最终接一次全连接判断结果。
4.训练思路:
判别器的训练
在训练判别器的时候我们希望判别器可以判断输入图片的真伪,因此我们的输入就是真图片、假图片和它们对应的标签。
因此判别器的训练步骤如下:
1、随机选取batch_size个真实高分辨率图片。
2、利用resize后的低分辨率图片,传入到Generator中生成batch_size个虚假高分辨率图片。
3、真实图片的label为1,虚假图片的label为0,将真实图片和虚假图片当作训练集传入到Discriminator中进行训练。

生成器的训练
在训练生成器的时候我们希望生成器可以生成极为真实的假图片。因此我们在训练生成器需要知道判别器认为什么图片是真图片。
因此生成器的训练步骤如下:
1、将低分辨率图像传入生成模型,得到虚假高分辨率图像,将虚假高分辨率图像获得判别结果与1进行对比得到loss。(与1对比的意思是,让生成器根据判别器判别的结果进行训练)。
2、将真实高分辨率图像和虚假高分辨率图像传入VGG网络,获得两个图像的特征,通过这两个图像的特征进行比较获得loss
具体代码如下:
sr_imgs = generator(lr_imgs) # (N, 3, 96, 96), 范围在 [-1, 1]
sr_imgs = convert_image(
sr_imgs, source='[-1, 1]',
target='imagenet-norm') # (N, 3, 96, 96), imagenet-normed
# 计算 VGG 特征图
sr_imgs_in_vgg_space = truncated_vgg19(sr_imgs) # batchsize X 512 X 6 X 6
hr_imgs_in_vgg_space = truncated_vgg19(hr_imgs).detach() # batchsize X 512 X 6 X 6
# 计算内容损失
content_loss = content_loss_criterion(sr_imgs_in_vgg_space,hr_imgs_in_vgg_space)
# 计算生成损失
sr_discriminated = discriminator(sr_imgs) # (batch X 1)
adversarial_loss = adversarial_loss_criterion(
sr_discriminated, torch.ones_like(sr_discriminated)) # 生成器希望生成的图像能够完全迷惑判别器,因此它的预期所有图片真值为1
# 计算总的感知损失
perceptual_loss = content_loss + beta * adversarial_loss
# 后向传播.
optimizer_g.zero_grad()
perceptual_loss.backward()
# 更新生成器参数
optimizer_g.step()
#记录损失值
losses_c.update(content_loss.item(), lr_imgs.size(0))
losses_a.update(adversarial_loss.item(), lr_imgs.size(0))

losses_c = AverageMeter() # 内容损失
losses_a = AverageMeter() # 生成损失
losses_d = AverageMeter() # 判别损失
5.损失函数
感知损失: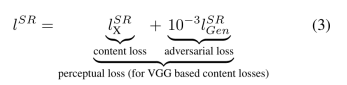
我们将感知损失表示为内容损失(lXSR)和对抗性损失成分的加权和:
、
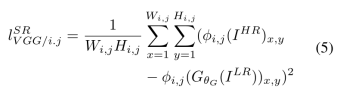
我们根据Simonyan和Zisserman [49]中描述的预训练的19层VGG网络的ReLU激活层来定义VGG损耗。 用φi; j表示在VGG19网络内的第i个最大化层之前通过第j个卷积(激活之后)获得的特征映射,我们考虑给出。 然后,我们将VGG损失定义为重建图像GθG(ILR)的特征表示与参考图像IHR之间的欧氏距离:
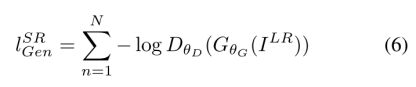


















 1087
1087











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









