







文章目录
4.1 Classical Search 经典搜索
- In previous chapter, we addressed a single category of problems, where the solution is a sequence of actions with following features:
上一章《经典搜索算法》,我们讨论了一个单一类别的问题,其解决方案是具有如下特点的一系列动作:
-observable, 可观测
-deterministic, 确定性
-known environments. 已知环境 - In this chapter, we will discuss the
local search algorithms, evaluating and modifying one or more current states rather than systematically exploring paths from an initial state.
本章我们将讨论:局部搜索算法,考虑对一个或多个状态进行评价和修改,而不是系统地探索从初始状态开始的路径。 - The search algorithms that we have seen so far are designed to explore search spaces systematically, they are called
Classic Search.
我们前面介绍过的搜索算法都系统地探索空间,称为经典搜索算法。 - This systematicity is achieved by keeping one or more paths in memory and by recording which alternatives have been explored at each point along the path.
这种系统性是通过将一条或多条路径保存在内存中,并在路径的每个点上记录已经探索过哪些备选方案来实现的。(record how to chose a node to be expanded) - When a goal is found, the path to that goal also constitutes a solution to the problem.
当找到目标时,到达此目标的路径就是这个问题的一个解。 - In many problems, however, the path to the goal is irrelevant to the solution.
然而在许多问题中,到达目标的路径与解是无关的。目标本身就是解,而不关心如何到达的。 - For example, in the 8-queens problem, what matters is the final configuration of queens, not the order in which they are added.
例如,在八皇后问题中,重要的是最终皇后在棋盘上的布局,而不是皇后加入的先后次序。 - The same general property holds for many important applications such as integrated-circuit design, factory-floor layout, job-shop scheduling, automatic programming, telecommunications network optimization, vehicle routing, and portfolio management.
许多重要的应用都具有这样的性质,例如集成电路设计、工厂场地布局、作业车间调度、自动程序设计,电信网络优化、车辆寻径和文件夹管理。
在集成电路设计时:只关心各种电子器件的布局,关注电容、电阻最终放在什么位置,至于先放哪个元器件、后放哪个元器件,并不是我们关心的。
4.2 Local Search Algorithms(局部搜索算法)
- In many optimization problems, the path to the goal does not matter; the goal state itself is the solution.
在许多优化问题中,到达目标的路径是无关紧要的;目标状态本身就是解决方案。 - In such cases, we can use a different class of algorithms that do not worry about paths at all. That is local search algorithm.
在此情况下,我们可以采用一种不同类型的搜索算法,这类算法不关心路径,它就
是局部搜索算法。 - Local search algorithms operate using a single current node (rather than multiple paths), and generally move only to neighbors of that node. 局部搜索算法从单个当前节点(而不是多条路径)出发,通常只移动到它的邻近状态。
- Typically, the paths followed by the search are not retained.
通常,不保留搜索路径。
Basic idea:
Basic idea: in the search process, always search towards the direction closest to the target.
基本思想:在搜索过程中,始终向着离目标最接近的方向搜索。
- The goal can be the maximum or the minimum.
目标可以是最大值,也可以是最小值 - Local search algorithms have two key advantages:局部搜索算法有如下两个主要优点:
-use very little memory; 使用很少的内存;
-can find reasonable solutions in large or infinite (continuous) state spaces. 在大的或无限(连续)状态空间中,能发现合理的解。
Methods of Local Search
- Hill-climbing search(爬山搜索)
- Local beam search(局部束搜索)
- Simulated annealing search(模拟煺火搜索)
- Genetic algorithms(遗传算法)
(1)Hill-climbing Search(爬山搜索)
- Hill-Climbing search algorithm is the most basic local search technique.
爬山搜索算法是最基本的局部搜索方法。 - It is an iterative algorithm: 爬山法是一种迭代算法:
starts with an arbitrary solution to a problem,
then incrementally change a single element of the solution,
if it’s a better solution, the change is made to the new solution,
repeating until no further improvements can be found.
开始时选择问题的一个任意解,然后递增地修改该解的一个元素,若得到一个更好的解,则将该修改作为新的解;重复直到无法找到进一步的改善。 - Hill-climbing Search is simply a loop that continually moves in the direction
of increasing value—that is, uphill.
爬山搜索是简单的循环过程,不断向值增加的方向持续移动—— 即,登高。 - It terminates when it reaches a “peak” where no neighbor has a higher value.
算法在到达一个“峰顶”时终止,邻接状态中没有比它值更高的。 - The algorithm does not maintain a search tree, so the data structure for the
current node need only record the state and the value of the objective function.
算法不维护搜索树,因此当前结点的数据结构只需要记录当前状态和目标函数值。 - Hill climbing does not consider the state that are not the neighbors of the current state. 爬山法不会考虑与当前状态不相邻的状态。
- It is sometimes called greedy local search, because it grabs the best neighbor state without thinking ahead about where to go next.
爬山法有时被称为贪婪局部搜索,因为它总是选择邻居中状态最好的一个,而不考虑一步该如何走。 - It turns out that greedy local search algorithms often perform quite well.
贪婪局部搜索算法往往很有效。 - It often makes rapid progress toward a solution, because it is usually quite easy
to improve a bad state.
爬山法很快朝着解(目标状态)的方向进展,因为它可以很容易地改善一个不良状态。
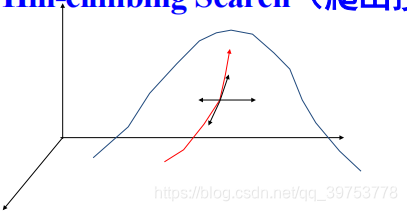
- If the peak is taken as the goal, h(n) to represent the height difference between the peak and the current position n, the algorithm is equivalent to always climbing towards the top of the mountain. Under the condition of single peak, it will be able to reach the peak.
如果把山顶作为目标,h(n)表示山顶与当前位置n之间的高度差,则该算法相当于总是登向山顶。在单峰的条件下,必能到达山顶。

- At each step the current node is replaced by the best neighbor; in this version, that means the neighbor with the highest VALUE, but if a heuristic cost estimate h is used, we would find the neighbor with the lowest h.
在每一步,当前结点都会被它的最佳相邻结点所代替;这里,最佳相邻结点是指VALUE 最高的相邻结点,但是若使用启发式代价评估函数h, 我们要找的就是h 最低的相邻结点。
Example: n-queens problems n皇后问题
- To illustrate hill climbing, we will use it to solve the n-queens problem.
为了举例说明爬山法,我们将用它解决n皇后问题。 - Put all n queens on an n × n board. Each time move a queen to reduce the number of conflicts, so that there are no two queens on the same row, column, or diagonal.
把n个皇后放在n x n的棋盘上。每次移动一个皇后来减少冲突数量,使得没有两个皇后在同一行、同一列、或同一对角线上。 - each state has 8 queens on the board, one per column.
每个状态都是在棋盘上放置8 个皇后,每列一个皇后。 - The heuristic cost function h is the number of pairs of queens that are attacking each other, either directly or indirectly.
启发式评估函数h 是形成相互攻击的皇后对的数量;不管是直接还是间接。 - The global minimum of this function is zero, which occurs only at perfect solutions. 该函数的全局最小值是0, 仅在找到解时才会是这个值。

- Hill-climbing algorithms typically choose one randomly among the set of best successors if there is more than one.
如果有多个最佳后继,爬山算法通常会从一组最佳后继中随机选择一个。
Weaknesses of Hill-Climbing 爬山法的弱点
It often gets stuck for the three reasons: 它在如下三种情况下经常被困:
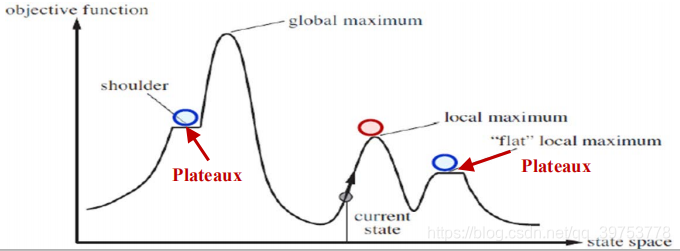
- Local maxima 局部最大值
higher than its neighbors but lower than global maximum. 高于相邻节点但低于全局最大值。
A local maximum is a peak that is higher than each of its neighboring states but lower than the global maximum.
局部极大值是一个比它的每个邻接结点都高的峰顶,但是比全局最大值要小。
Hill-climbing algorithms that reach the vicinity of a local maximum will be drawn upward toward the peak but will then be stuck with nowhere else to go.
爬山法算法到达局部极大值附近就会被拉向峰顶,然后就卡在局部极大值处无处可走。
- Plateaux 高原
can be a flat local maximum, or a shoulder. 可能是一个平坦的局部最大值,或山肩。
- Ridges 山岭
result in a sequence of local maxima that is very difficult to navigate.
结果是一系列局部最大值,非常难爬行。

Example of local maxima
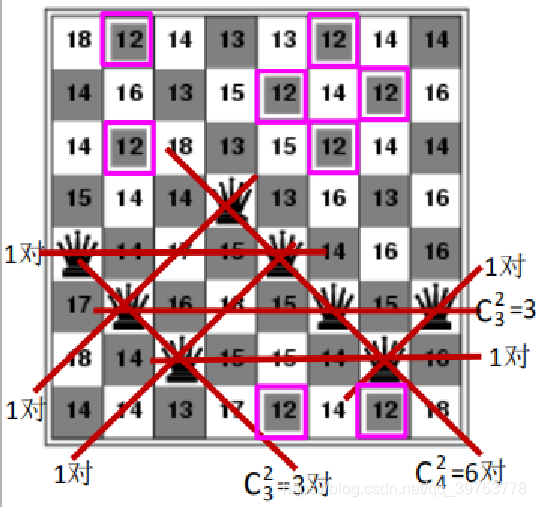
- h = number of pairs of queens that are attacking each other, either directly or indirectly ,
h = 17 - It shows the values of all its successors, with the best successors having h=12.
- Hill-climbing algorithms typically choose one randomly among the set of best successors if there is more than one. 如果有多个后继同是最小值,爬山法会在最佳后继集合中随机选择一个进行扩展。
(a) Its heuristic cost estimate h=17. It shows the value of h for each possible successor obtained by moving a queen within its column. The best moves are marked.
当前状态的启发式代价评估h =17, 方格中显示的数字表示将这一列中的皇后移到该方格而得到的后继的h 值。最佳移动在图中做了标记.
(1) Choose one randomly among the set of best successors and place the queen in the same
column to this cell.
在当前状态中,从若干个最佳后继中随机挑选一个,将该列的皇后移到此位置,
(2) Recalculate the value of h in each cell. 再重新计算各个方格里的h值,
(3) goto step (1) until the optimal solution is obtained or can not find a neighbor with lower value than the current node .
转到步骤(1),直到得到最优解或无法找到比的当前状态h值更小的相邻状态。
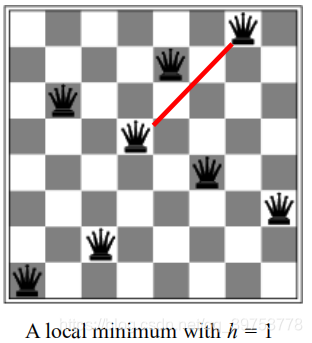
(b) A local minimum in the 8-queens state space; the state has h=1 but every successor has a higher cost.
八皇后问题状态空间中的一个局部极小值:该状态的 h=l, 但是它的每个后继的 h 值都会比它.
Now hill climbing gets stuck in local maxima.
此时,爬山法陷入了局部最大值,无法找到全局的最优解。
Problem of Hill-Climbing
- It is very difficult for greedy algorithms to deal with the situation of falling into local maxima.
贪婪算法很难处理陷入局部极大值的情况。 - In each case, the algorithm reaches a point at which no progress is being made.
在这种情况下,爬山法都会到达无法再取得进展的地点。 - Starting from a randomly generated 8-queens state, steepest-ascent hill climbing gets stuck 86% of the time, solving only 14% of problem instances.
从随机生成的八皇后问题开始,最陡上升的爬山法86%的情况下会被卡住,只有14%的问题实例能求得解。 - The hill-climbing algorithms described so far are incomplete—they often fail to find a goal when one exists because they can get stuck on local maxima.
到现在为止我们描述的爬山法是不完备的—— 它们经常会在目标存在的情况下因为被局部极大值卡住而找不到目标。
Variants of Hill-Climbing 爬山法的变型
Stochastic hill-climbing 随机爬山法
- It chooses at random among uphill moves; the probability of selection can vary with the steepness of uphill move.
在向上移动的过程中,随机地选择下一步, 被选中的概率可能随向上移动的陡峭程度的不同而变化。 - This usually converges more slowly than steepest ascent.
与最陡上升算法相比,收敛速度通常较慢。 - still incomplete—they may get stuck on local maxima.
仍然不完备,还会被局部极大值卡住。
Random-restart hill-climbing 随机重启爬山法
- It adopts the well-known adage, “If at first you don’t succeed, try, try again.”
- It conducts a series of hill-climbing searches from randomly generated initial states, until a goal is found.
随机生成一个初始状态,开始搜索,执行一系列这样的爬山搜索,直到找到目标为止。 - It is complete with probability approaching 1, because it will eventually generate a goal state as the initial state.
它十分完备,概率逼近1,因为最终它将生成一个目标状态作为初始状态。 - If each hill-climbing search has a probability p of success, then the expected number of restarts required is 1/p.
如果每次爬山搜索成功的概率为p,则重启需要的期望值是1/p。 - For 8-queens, then, random-restart hill climbing is very effective indeed. Even for three million queens, the approach can find solutions in under a minute.
对于八皇后问题,随机重启爬山法实际上是有效的。即使有300 万个皇后,这个方法找到解的时间不超过1分钟。 - The success of hill climbing depends very much on the shape of the state-space landscape: if there are few local maxima and plateaux, random-restart hill climbing will find a good solution very quickly.
爬山法成功与否严重依赖于状态空间地形图的形状:如果在图中几乎没有局部极大值和高原,随机重启爬山法会很快找到好的解。随机重启爬山法依然不完备!
(2)Simulated Annealing Search 模拟退火
- A hill-climbing algorithm that never makes “downhill” moves toward states with lower value (or higher cost) is guaranteed to be incomplete, because it can get stuck on a local maximum.
爬山法搜索从来不“下山”, 即不会向值比当前结点低的(或代价高的)方向搜索,它肯定是不完备的,理由是可能卡在局部极大值上。 - In contrast, a purely random walk—that is, moving to a successor chosen uniformly at random from the set of successors—is complete but extremely inefficient.
与之相反,纯粹的随机行走是完备的,但是效率极低。随机行走就是从后继集合中完全等概率的随机选取后继。 - Therefore, it seems reasonable to try to combine hill climbing with a random walk in some way that yields both efficiency and completeness. Simulated annealing is such an algorithm.
因此,把爬山法和随机行走以某种方式结合,同时得到效率和完备性的想法是合理的。模拟退火就是这样的算法。
Annealing 退火
- In metallurgy, annealing is the process used to temper or harden metals and glass by heating them to a high temperature and then gradually cooling them, thus allowing the material to reach a low energy crystalline state.
在冶金中,退火是通过将金属和玻璃加热到高温,然后逐渐冷却,使材料达到低能结晶状态,从而使金属和玻璃回火或硬化的过程。 - To explain simulated annealing, we switch our point of view from hill climbing to gradient descent (i.e., minimizing cost) and imagine the task of getting a ping-pong ball into the deepest crevice in a bumpy surface.
为了更好地理解模拟退火,我们把注意力从爬山法转向梯度下降(即,减小代价),想象在髙低不平的平面上有个乒乓球掉到最深的裂缝中。 - If we just let the ball roll, it will come to rest at a local minimum.
如果只允许乒乓球滚动,那么它会停留在局部极小点。 - If we shake the surface, we can bounce the ball out of the local minimum.
如果晃动平面,我们可以使乒乓球弹出局部极小点。 - The trick is to shake just hard enough to bounce the ball out of local minima but not hard enough to dislodge it from the global minimum.
窍门是晃动幅度要足够大让乒乓球能从局部极小点弹出来,但又不能太大把它从全局最小点弹出来。 - The simulated-annealing solution is to start by shaking hard (i.e., at a high temperature) and then gradually reduce the intensity of the shaking (i.e., lower the temperature).
模拟退火的解决方法就是开始使劲摇晃(也就是先高温加热)然后慢慢降低摇晃的强度(也就是逐渐降温)。
Basic Idea of Simulated Annealing Search
- escape local maxima by allowing some “bad” moves but gradually decrease their frequency.
避免局部极大值,允许一些“坏”的移动,但逐渐减少他们的频率。 - Break through Local Optima with probability and move towards Global Optimum
以概率突破局部最优,走向全局最优。
- The innermost loop of the simulated-annealing algorithm is quite similar to hill climbing.
模拟退火算法的内层循环与爬山法类似。 - Instead of picking the best move, however, it picks a random move.
只是它没有选择最佳移动,选择的是随机移动。 - If the move improves the situation, it is always accepted.
如果该移动使情况改善,该移动则被接受。 - Otherwise, the algorithm accepts the move with some probability less than 1.
否则,算法以某个小于1 的概率接受该移动。 - The probability decreases exponentially with the “badness” of the move—the amount ΔE by which the evaluation is worsened.
随着移动导致状态“变坏”, 概率会成指数级下降一一评估值ΔE 变坏。 - The probability also decreases as the “temperature” T goes down: “bad” moves are more likely to be allowed at the start when T is high, and they become more unlikely as T ecreases.
这个概率也随“温度”T的 降低而下降:开始T高的时候可能允许“坏的”移动,当T降低时则不可能允许“坏的”移动。 - If the schedule lowers T slowly enough, the algorithm will find a global optimum with probability approaching 1.
如果调度让温度T下降得足够慢,算法找到全局最优解的概率接近于1。 - Simulated annealing was first used extensively to solve VLSI (very large scale integration) layout problems in the early 1980s. It has been applied widely to factory scheduling and other large-scale optimization tasks.
模拟退火在20 世纪80 年代早期广泛用于求解VLSI (大规模集成电路)布局问题。现在它
已经广泛地应用于工厂调度和其他大型最优化任务。 - Simulated annealing is a probabilistic method to approach the global optimal
solution, which was published in 1953.
模拟退火是一种逼近全局最优解的概率方法,发表于1953年。
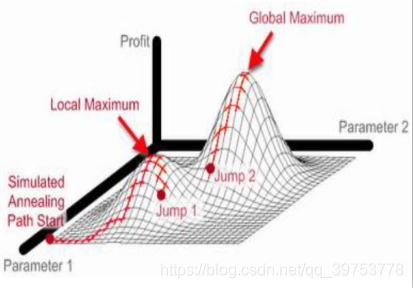
- The simulated annealing algorithm, a version of stochastic hill climbing where some downhill moves are allowed. Downhill moves are accepted readily early in the annealing schedule and then less often as time goes on.
模拟退火算法,允许下山的随机爬山法。在退火初期下山移动容易被采纳,随时间推移下山的次数越来越少。

(3)Local Beam Search 局部束搜索
- Keeping just one node in memory might seem to be an extreme reaction to the problem of memory limitations.
虽然内存有限,但在内存中只保存一个结点又有些极端。(爬山法只记录当前状态及其目标函数值) - The local beam search algorithm keeps track of k states rather than just one.
局部束搜索算法记录k 个状态而不是只记录一个。 - It starts with k randomly generated states
它从k个随机生成的状态开始。 - At each step, all the successors of all k states are generated.
在每一步,生成所有k个状态的所有后继状态。 - If any one is a goal state, stop; else select the k best successors from the complete list and repeat.
如果其中有一个是目标状态,则算法停止;否则从整个后继列表中选择k个最佳后继,重复这个过程。
Example: Travelling Salesperson Problem (TSP) 旅行推销员问题
- Given the distance between a series of cities and each pair of cities, find the shortest loop to visit each city only once and return to the original city
给定一系列城市和每对城市之间的距离,求解访问每一座城市仅一次并回到起始城市的最短回路。 - The problem is to find a Hamilton loop with the least weight in a undirected completed graph with weight.
该问题实质是在一个带权无向完全图中,找一个权值最小的Hamilton回路
哈密顿回路图,与欧拉回路图正好互相呼应,欧拉回路要求通过每条边一次且仅仅一次,而哈密顿回路图则要求通过每个顶点一次且仅仅一次。
迄今没有一个能简单判定 哈密顿图 的充要条件。从算法设计理论来说,还没有有效的方法可求得该问题的精确解。好在有(nearest neighbor algorithm)最近邻居算法,(best-edge algorithm)最佳边算法都能给出比较不错的结果。
- Suppose that the weights of the horizontal and vertical line segments are equal and less than the diagonal weight. 假设水平和竖直线段的权值相等,均小于对角线的权值。
- Keeps track of k states rather than just 1. Start with k randomly generated states.
k=2in this example. 保持k个状态而不仅仅为1。从k个随机生成的状态开始。本例中k=2。
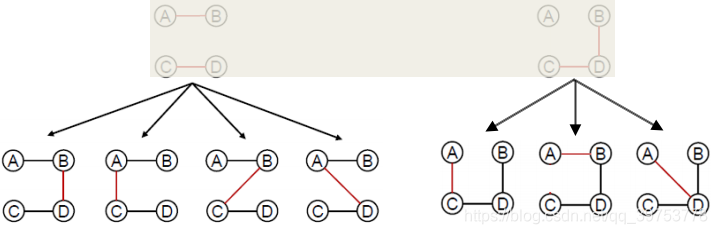
- Generate all successors of all the k states. None of these is a goal state so we continue.
生成所有k个状态的全部后继节点。这些后继节点中没有目标状态,故继续下一步。
Select the best k successors from the complete list. Repeat the process until goal found.
从完成表中选择最佳k个后继节点。重复上述过程,直到找到目标。
(4)Genetic Algorithms 遗传算法(GA)
- The elements of genetic algorithms was introduced in 1960s.Became popular
through the work of John Holland in early 1970s, and particularly his book
Adaptation in Natural and Artificial Systems(1975).
遗传算法的一些要素是1960年代提出的。通过约翰·霍兰在1970年代早期的工作,尤其是他的《神经元与人工系统的适应性》(1975年)一书,使得遗传算法流行起来。 - It is a search heuristic that mimics the process of natural selection.
它是一种模仿自然选择过程的搜索启发式算法。 - In this algorithm, successor states are generated by combining two parent states rather than by modifying a single state. It is dealing with sexual reproduction rather than asexual reproduction.
在该算法中, 后继节点是由两个父辈状态的组合而不是修改单一状态生成的。其处理过程是有性繁殖,而不是无性繁殖。 - Genetic algorithms belong to the larger class of evolutionary algorithms. 遗传算法属于进化算法这个大分类。
- The algorithms generate solutions to optimization problems using techniques inspired by natural evolution, such as inheritance, mutation, selection, and crossover.
该算法采用自然进化所派生的技法来生成优化问题的解,例如:遗传、变异、选择、以及杂交。 - It begin with a set of k randomly generated states, called the population. 该算法开始时具有一组k个随机生成的状态,称其为种群。
- Each state, or individual, is represented as a string over a finite alphabet, most commonly, a string of 0s and 1s.
每个状态,或称为个体,表示为有限字母表上的一个字符串,通常是0和1的字符串。 - Each state is rated by the objective function, or (in GA terminology) the fitness function.
每个状态都由它的目标函数或(用遗传算法术语)适应度函数给出评估值。 - A fitness function should return higher values for better states.
对于好的状态,适应度函数应返回较高的值。
遗传算法—基本概念
- 种群(Population):指初始给定的多个解的集合。
- 个体(Individual):指种群中的单个元素,通常由一个用于描述其基本遗传结构的数据结构来表示。
- 染色体(Chromosome):指对个体进行编码后所得到的编码串。染色体中的每一位称为基因,染色体上由若干个基因构成的一个有效信息段称为基因组。例如:11011为一个染色体,每一位上的0或1表示基因。
- 适应度(Fitness)函数:一种用来对种群中各个个体的环境适应性进行度量的函
数。其函数值是遗传算法实现优胜劣汰的主要依据。 - 遗传操作(Genetic Operator):指作用于种群而产生新的种群的操作。标准的遗传操作包括以下三种基本形式:
选择(Selection)
交叉(Crossover)
变异(Mutation)
Example: 8-queens problem 8皇后问题
An 8-queens state must specify the positions of 8 queens, each in a column of 8
squares, the state could be represented as 8 digits, each in the range from 1to 8.
某8皇后状态需要指明8个皇后的位置,每个位于8个方格的一列,其状态可用8个数字表示,每个位于1到8之间。
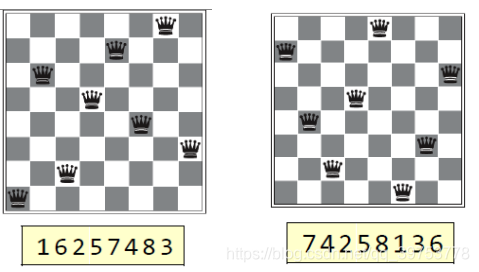
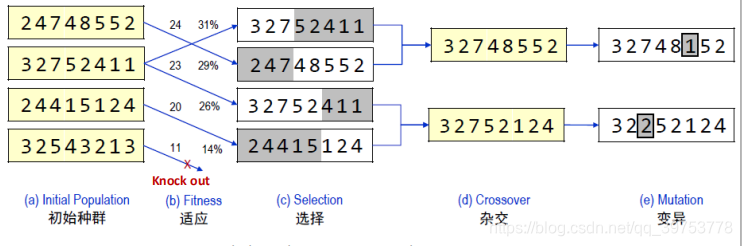
Fig. 1 Digit strings representing 8-queens states.
(a) the initial population, (b) ranked by the fitness function,
© resulting in pairs for mating, (d) reproduce child, (e) subject to mutation.
数字串表示8皇后的状态(a)为初始种群,(b)通过适应函数进行分级,©导致交配对产生,(d)繁殖后代,(e)取决于突变。
- For the 8-queens problem, we use the number of nonattacking pairs of queens to define the fitness, which has a value of 28 for a solution. 在八皇后问题中,我们用不相互攻击的皇后对的数目来表示适应度. 最优解的适应度是28。
- The values of the four states are 24, 23, 20, and 11. 这四个状态的适应度分别是24、23、20 和11.
- In this particular variant of the genetic algorithm, the probability of being chosen for reproducing is directly proportional to the fitness score, and the percentages are shown next to the raw scores.在这个特定的遗传算法实现中,被选择进行繁殖的概率直接与个体的适应度成正比,其百分比标在旁边。
- In ©, two pairs are selected at random for reproduction, in accordance with the probabilities in (b). 在图1 © 中,按照(b) 中的概率随机地选择两对进行繁殖。
- Notice that one individual is selected twice and one not at all.4 For each pair to be mated, a crossover point is chosen randomly from the positions in the string.
请注意其中一个个体被选中两次, 而有一个个体一次也没被选中,对于要配对的每对个体,在字符串中随机选择一个位置作为杂交点。 - In Figure 1, the crossover points are after the third digit in the first pair and after the fifth digit in the second pair.
图1 中的杂交点在第一对的第三位数字之后和第二对的第五位数字之后。 - In (d), the offspring themselves are created by crossing over the parent strings at the crossover point.
在图1 (d) 中,父串在杂交点上进行杂交而创造出后代。 - For example, the first child of the first pair gets the first three digits from the first parent and
the remaining digits from the second parent, whereas the second child gets the first three
digits from the second parent and the rest from the first parent. The 8-queens states involved
in this reproduction step are shown in Figure 2.
例如,第一对的第一个后代从第一个父串那里得到了前三位数字、从第二个父串那里得到了后五位数字,而第二个后代从第二个父串那里得到了前三位数字从第一个父串那里得到了后五位数字. - Finally, in (e), each location is subject to random mutation with a small independent probability.
最后,在图1 (e) 中每个位置都会按照某个小的独立概率随机变异。 - One digit was mutated in the first, third, and fourth offspring.
在第1、第3和第4 个后代中都有一个数字发生了变异。 - In the 8-queens problem, this corresponds to choosing a queen at random and moving it to a random square in its column.
在八皇后问题中,这相当于随机地选取一个皇后并把它随机地放到该列的某一个方格里。

Fig. 2 Those three 8-queens states correspond to the first two parents in “Selection” and their
offspring in “Crossover”.
The shaded columns are lost in the crossover step and the unshaded columns are retained.
这三个8皇后的状态分别对应于“选择”中的两个父辈和“杂交”中它们的后代。
阴影的若干列在杂交步骤中被丢掉,而无阴影的若干列则被保留下来。
The Genetic Algorithm

Applications of Genetic Algorithms 遗传算法的应用
Vivid Interpretation —形象解释
- Hill climbing algorithm: a kangaroo jumps higher than it is now. It found the highest peak not far away, but not really the highest peak, perhaps just the secondary peak.
爬山算法:一只袋鼠不断跳向比现在高的地方。它找到了不远处的最高山峰,但不一定真的是最高峰,也许只是次高峰。 - Simulated annealing: the kangaroo is drunk and jumps randomly for a long time, during which time it may go high or low. However, it gradually sobered up and jumped to the highest peak.
模拟退火:袋鼠喝醉了,它随机地跳了很长时间,这期间它可能走向高处,也可能走向低处。但是,它渐渐清醒了,并跳向最高山峰。 - Genetic algorithm: n kangaroos were randomly put into the mountain. Kangaroos do not know that their task is to find the highest peak. But every few years, some kangaroos are shot at the low peaks. As a result, the kangaroo at the low peak died, while the kangaroo at the mountain peak multiplied. Many years later, the kangaroos would unconsciously gather at the high peaks.
遗传算法:在山中随机投放N只袋鼠。袋鼠不知道自己的任务是寻找最高山峰。但每过几年,就在低山峰射杀一些袋鼠。于是,低山峰的袋鼠不断死去,而高山峰的袋鼠繁衍生息。许多年后,袋鼠就会不自觉地聚拢到高山峰处。

















 955
955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









