






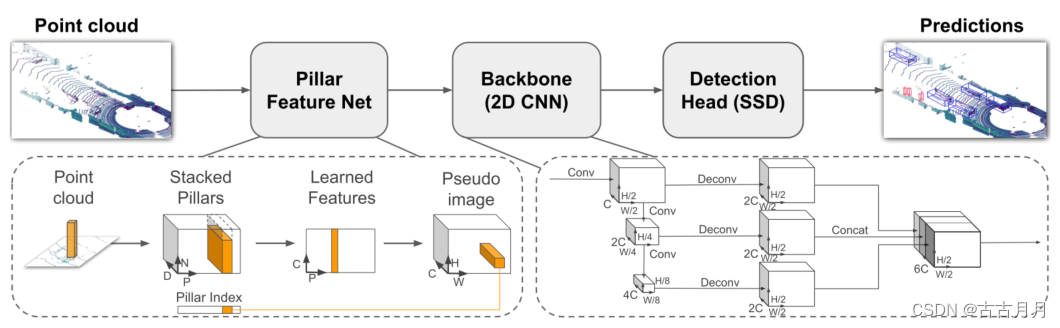
PointPillars:点云编码器,编码特征可以与任何标准的 2D 卷积检测架构一起使用。任务是目标检测。来自于CVPR2019。
论文地址:https://arxiv.org/pdf/1812.05784.pdf
代码地址:GitHub - nutonomy/second.pytorch: PointPillars for KITTI object detection
运行这个代码可不容易,下面是遇到的一些问题:
1.mmcv包,这个包要求torch>=1.7, 我的torch是1.4,“pip install mmcv”之后会由于版本问题,自动删除我的torch1.4和torchvision。解决:把cuda10卸载,重装cuda11(因为cuda10最高支持torch1.4),下载torch1.7和torchvision0.8
注意:虽然我用的是ubuntu18.04, 但是cudnn要安装linux而不是unbunt的.deb文件,.deb会出现很多不必要的问题,同样安装cuda的时候选的是runfile(local)而不是Ubuntu的deb
2.torchplus,这个包也是上面的问题,至少torch1.7
3.import问题,from secnd.XXX import XXX会报错,找不到second模块,解决1:可以用print(os.getcwd())来查看当前进程的路径是否是上面, 前面加一句:sys.path.append(".."),sys.path是一个list,包含了已经添加的环境变量路径,sys.path.append("..")可以用于跨文件导入
4. CUDA_arch为None的问题,会报错"ValueError: you must specify arch if use cuda",这个错是作者在command.py中写的,
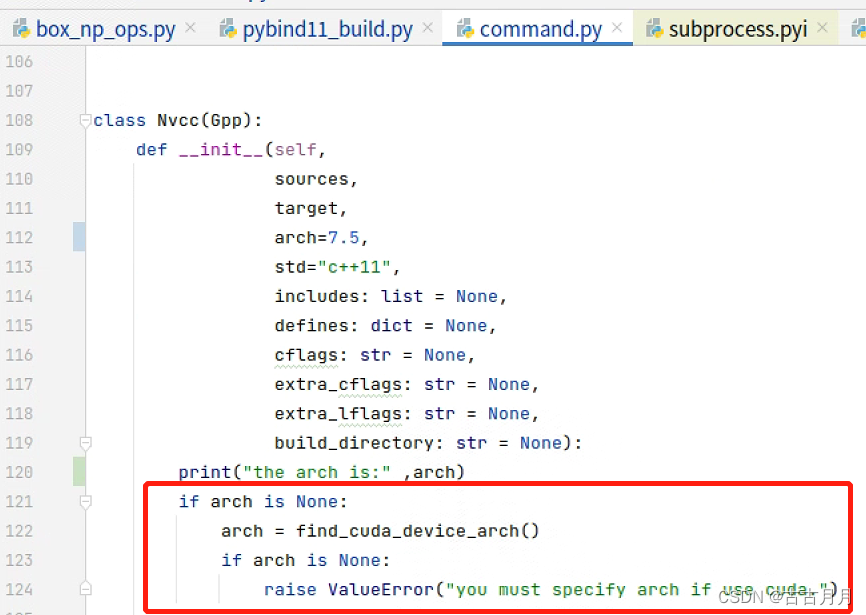
我在__init__()中把arch默认参数写上了7.5,还是不行,进入find_cuda_device_arch()函数去一点一点用print查看,发现while一旦执行,arch就会变成None,注释掉即可
注意:对于arch是什么,怎么查看:
cuda_arch是指CUDA Capability Major/Minor version number,代表显卡的算力,比如我的2080ti的arch是7.5,下面是查看arch的命令(假设你已经装了cuda)
cd /usr/local/cuda/samples/1_Utilities/deviceQuery
sudo make
./deviceQuery
5. cuda_runtime.h没有那个文件

应该是前面重装cuda的时候没装完整,先检查cuda的环境变量配置是否好之后,直接pip install cudatoolkit即可
6. RuntimeError: ('compile faied with retcode', 1)
找到是在command.py的compile_func()函数中报的错:

了解了一下subprocess.run()方法,是多线程的实现 :
run()方法的返回值是subprocess.CompletedProcess类的实例,表示一个进程结束了。CompletedProcess类有下面这些属性:
(1)args :启动进程的参数,通常是个列表或字符串。
(2)returncode: 进程结束状态返回码。0表示成功状态。一个负值 -N 表示子进程被信号 N 中断 (仅 POSIX).
(3)stdout :从子进程捕获到的标准输出。是一个字节序列, 或一个字符串,如果 run()是设置了 encoding, errors 或者 text=True 来运行的,则为字符串。如果未有捕获, 则为 None。如果设置 stderr=subprocess.STDOUT 运行进程,标准输入和标准错误将被组合在这个属性中,并且 stderr 将为 None。
(4)stderr: 捕获到的子进程的标准错误。一个字节序列, 或者一个字符串, 如果 run()是设置了参数 encoding, errors 或者 text=True 运行的,则为字符串。 如果未有捕获, 则为 None。
(5)check_returncode():如果returncode非零,抛出CalledProcessError
直接输出shell及其运行路径cwd看看是什么:

然后进入对应的cwd路径,执行这个shell,然后解决shell报的错,发现是arch的参数不对,我改成了 -arch=compute_60就解决了:

然后再把代码中的shell改掉,发现arch是在pybind11_build.py中定义的,直接改: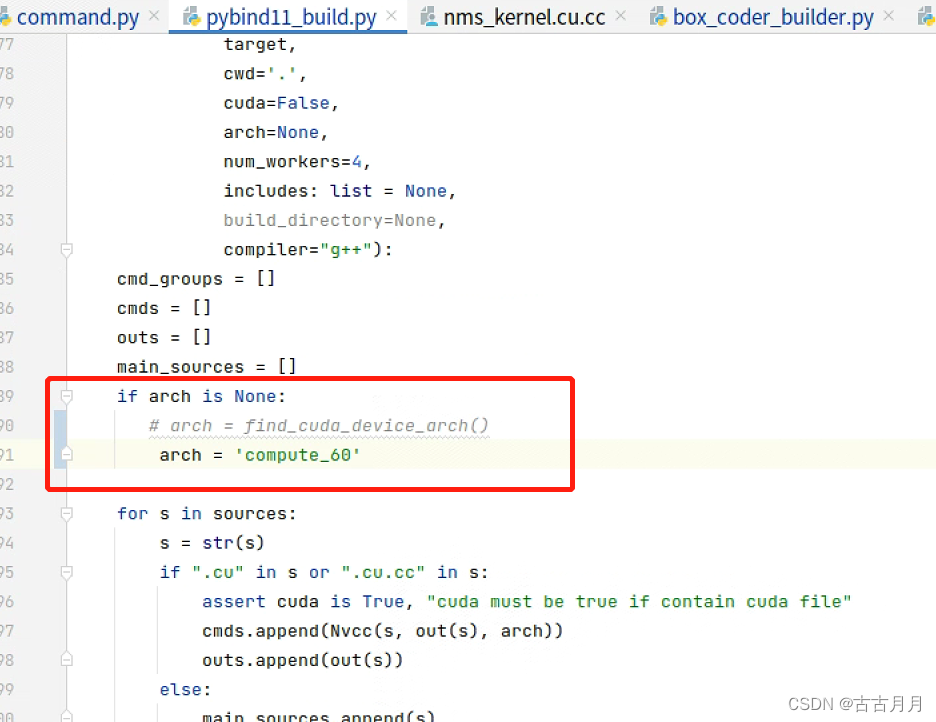
这样就ok了,又迎来了新的报错哦(微笑脸)
7.新的报错如下:
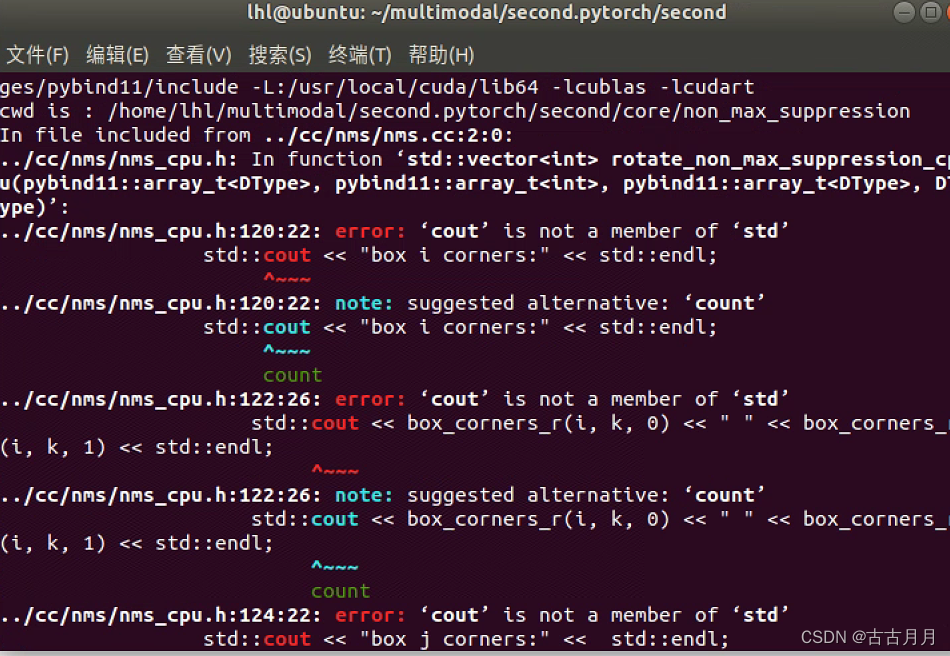
用上一步的方法,知道这个错误是在这个cwd下执行这个shell失败的:
打开nms_cpu.h文件查看他写的c++代码才发现,都没引入iostream,加上 #include<iostrream>就解决了。。。。让我们欢迎下一个报错(微笑脸)
8.No such file or directoory: "/usr/local/cuda/nvmm/lib64'
纳尼?我打开了新窗口ls发现明明有lib64!
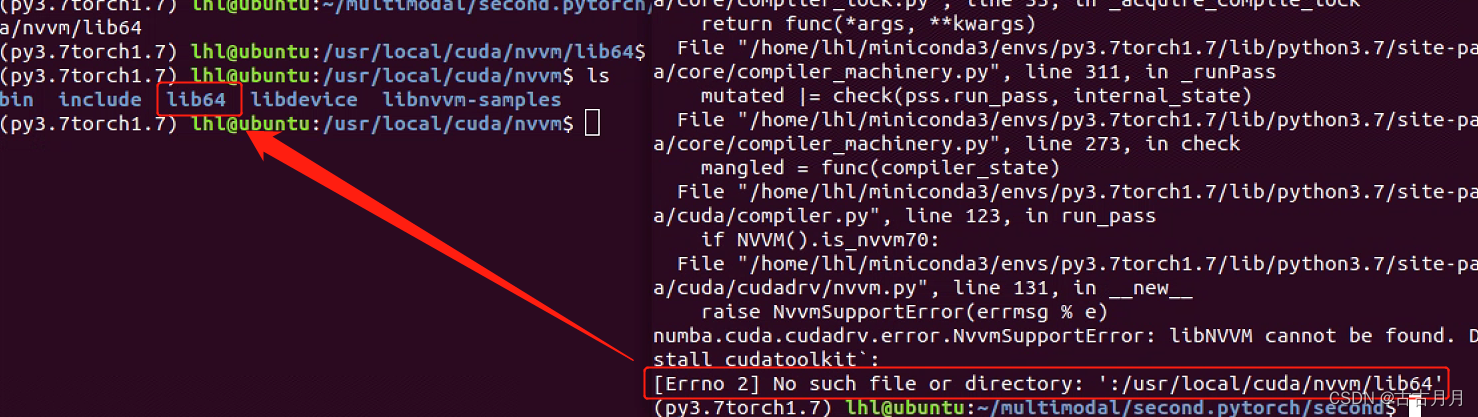
这时候我又检查了下cuda,发现nvcc -V查到的版本始终是9.1,而我昨天才刚装的11.0,才知道是cuda软连接没更新到cuda11.0,在local目录下会有一个cuda目录和一个cuda-XX.X目录,要把cuda目录整个删掉,再为cuda-11.0建立新的软连接。
sudo rm -rf /sur/local/cuda #删除cuda目录
sudo ln -s /usr/local/cuda-11.0 /usr/local/cuda #重新生成11.0的cuda这时候问题还真解决了,欢迎下一个error(微笑脸)
9.找不到 -lcublas 找不到 -lcudart
还是用前面的方法,把shell单独拿出来执行一下具体是什么错。















 1370
1370











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









