







作者及发刊详情
Y. Wang et al., “A 28nm 27.5TOPS/W Approximate-Computing-Based Transformer Processor with Asymptotic Sparsity Speculating and Out-of-Order Computing,” 2022 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 2022, pp. 1-3, doi: 10.1109/ISSCC42614.2022.9731686. keywords: {Out of order;Correlation;Computational modeling;Conferences;Transformers;Integrated circuit modeling;Artificial intelligence},
摘要
正文
文章术语
Q
×
K
T
Q×K^T
Q×KT:attention score
X
i
X_i
Xi:attention score的行向量
X
i
−
X
m
a
x
s
o
f
t
m
a
x
归一化的概率值
X_i-X_{max}softmax归一化的概率值
Xi−Xmaxsoftmax归一化的概率值:
P
P
P
WR-Tokens:attention score很小的值,表示弱相关的tokens
主要工作贡献
1)大精确小近似(A big-exact-small-approximate,BESA)处理元件(PE) 自适应近似计算弱关联Tokens,减少整个注意力模块的能耗
通过为WR-Tokens设计的自关断gate的近似乘法器,节省1.62倍的MAC计算功耗。
该乘法器计算小的值有较大误差,但很节能;计算大值精确,能满足attention的容错性
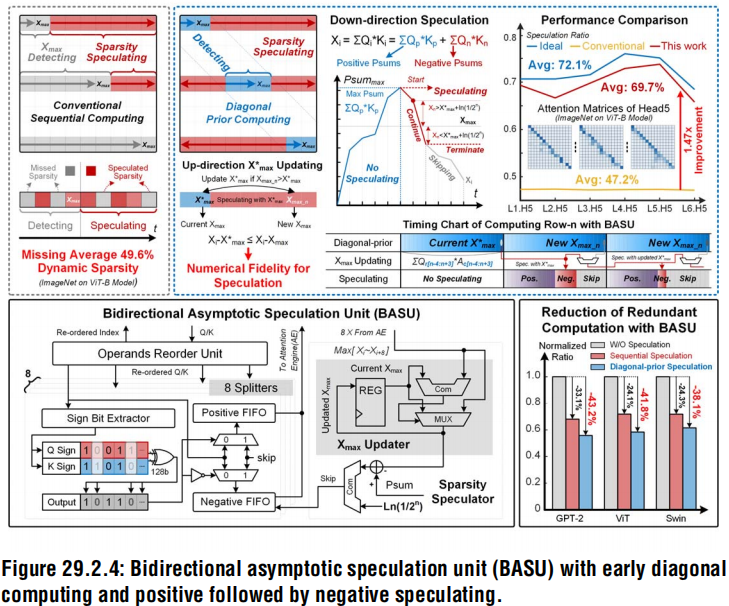
2)一个双向渐近推测单元(bidirectional asymptotic speculation unit,BASU)动态预测输出稀疏,实时移除Q×KT中的冗余注意力的相关计算
通过捕获稀疏性,跳过了46.7%的冗余计算。
BASU利用注意力的局部特性来快速找到变化的
X
m
a
x
X_{max}
Xmax,提高了利用稀疏性存在的能力
3)乱序的PE-line计算调度器(out-of-order PE-line computing scheduler,OPCS)融合两个乘法计算到一个乘法单元,提升P×V计算的资源利用率
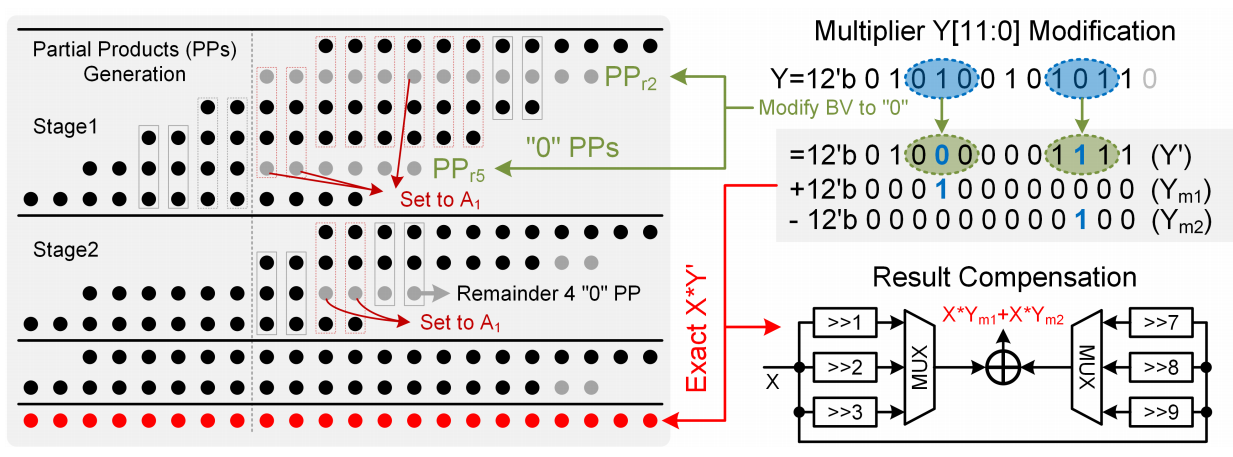
通过重排序操作数,将硬件利用率提高了1.81倍,即使2个操作合并为1乘法,省略了“0”的PPs计算
实验评估
实验验证平台:流片后芯片
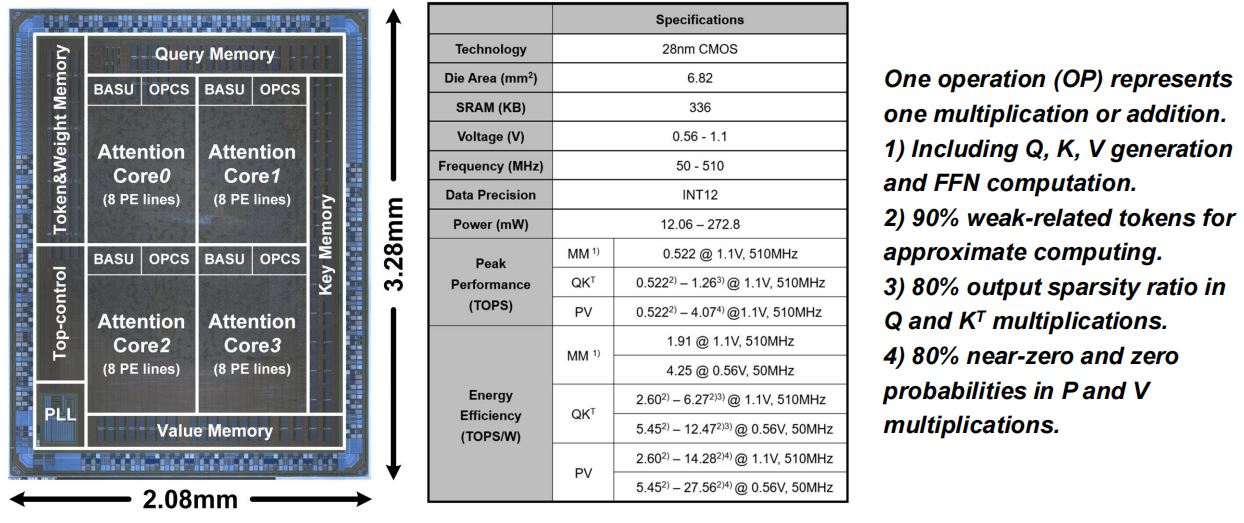
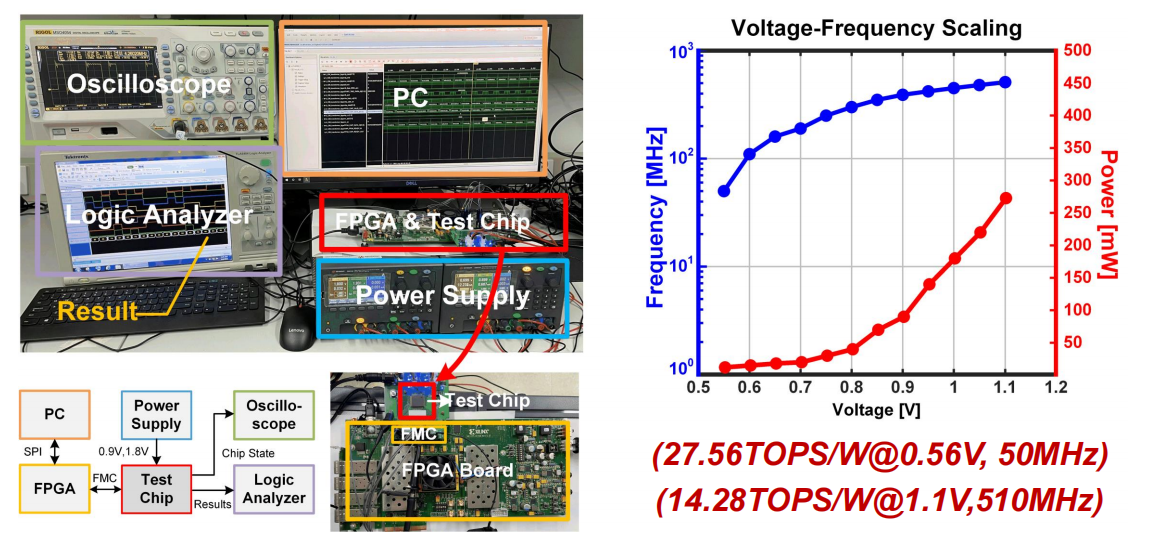
选用模型: GPT-2、ViT、Swin-transformer
三个模型均未优化
训练数据集:
推理精度
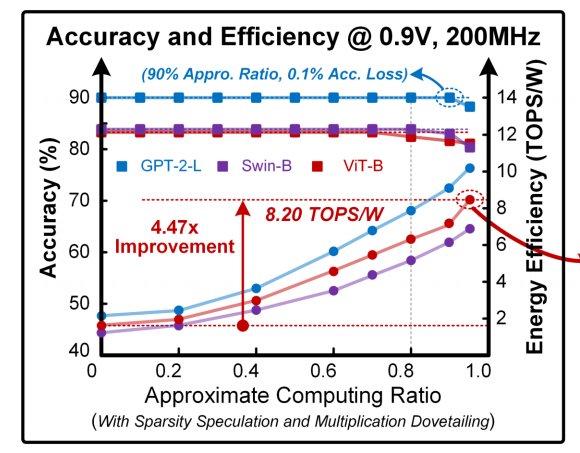
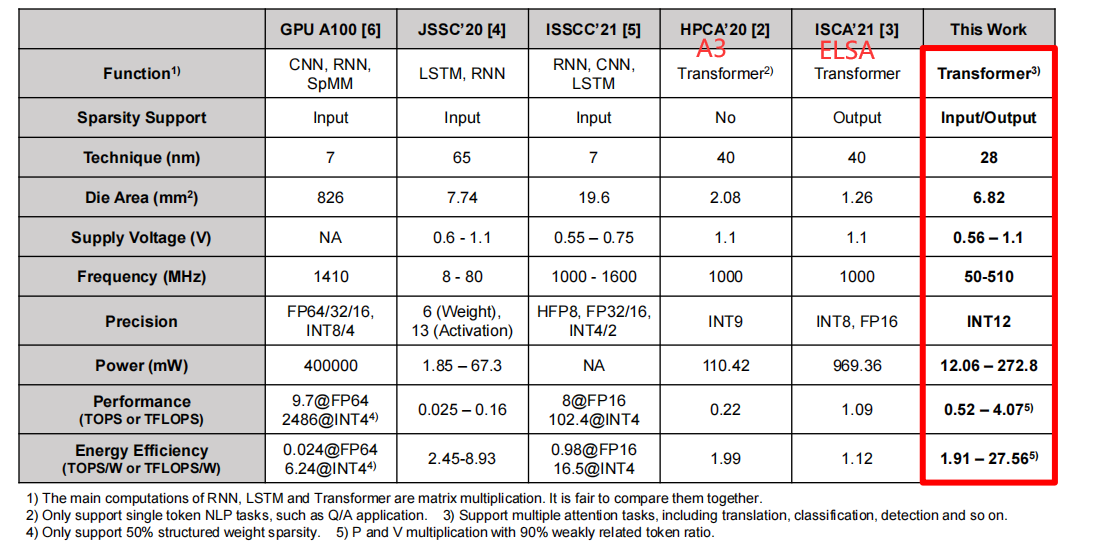
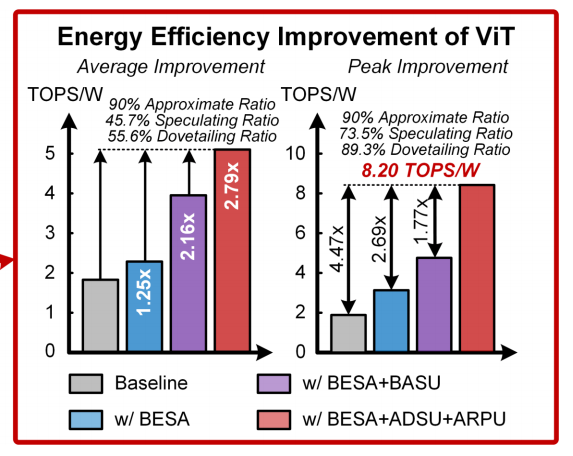
PPA表现
边缘端设备高能效计算的三个挑战
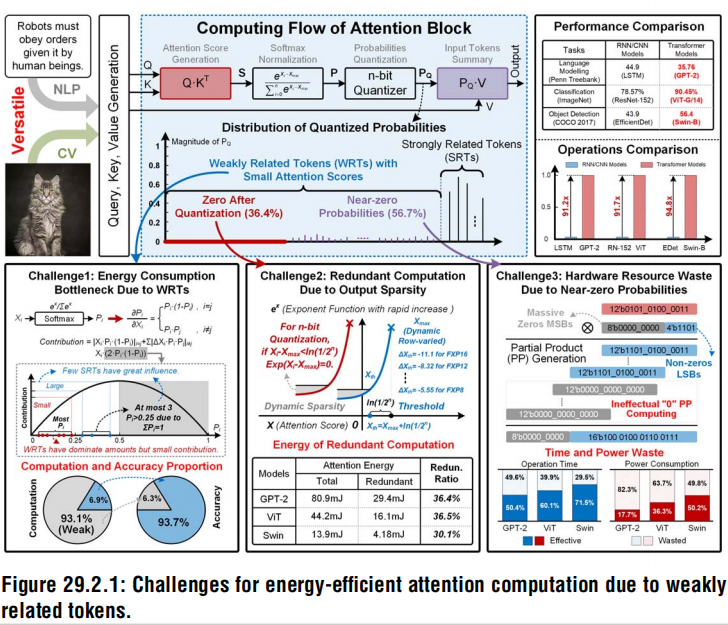
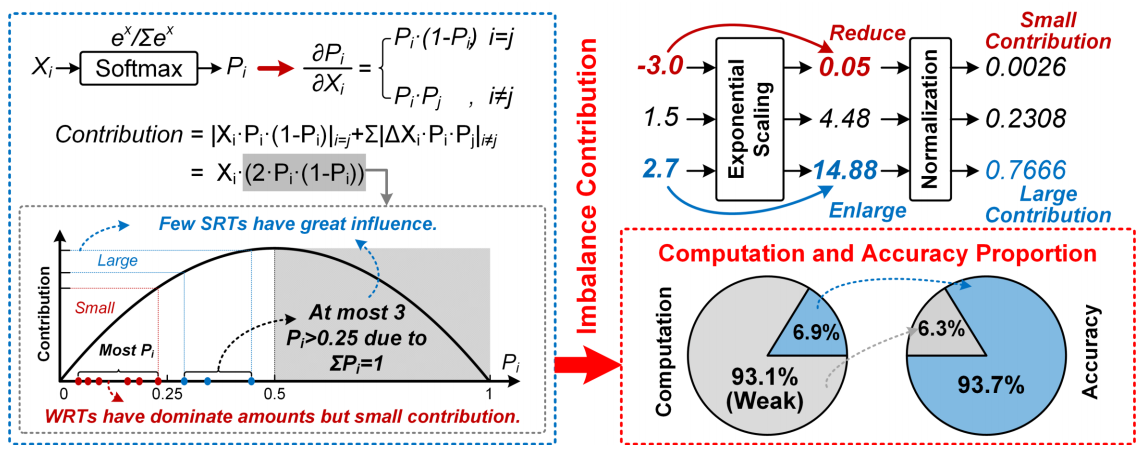
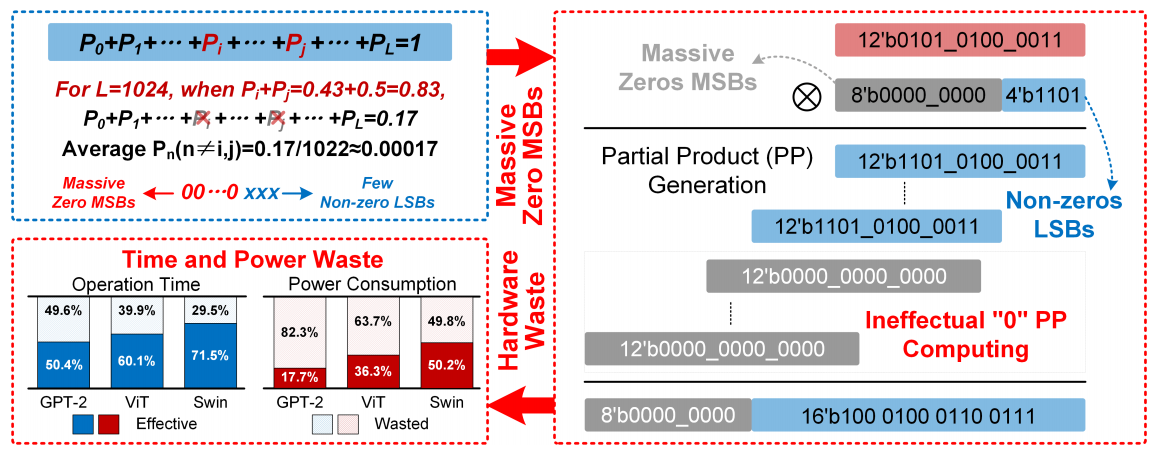
(1) 大量WR-Tokens在全局注意力计算中占主要地位
对于全局注意力块,WR-Tokens需要平均93.1%的能量消耗,但影响有限,因为softmax将小的attention score的概率降低到接近零,削弱了它们的贡献。
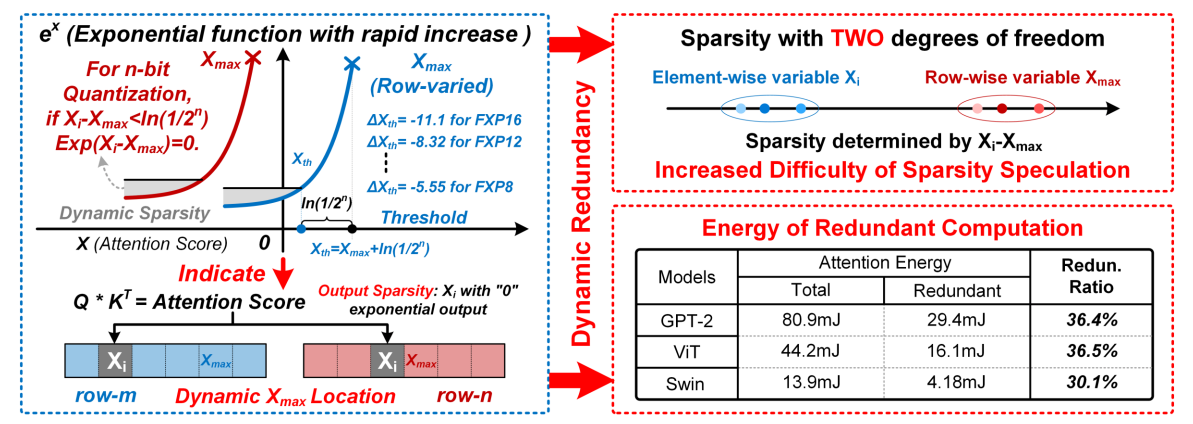
(2) WR-tokens引入动态输出稀疏,导致冗余计算
在 Q × K T Q×K^T Q×KT中,34.3%的计算是冗余的,因为softmax后许多近零值在n位量化后变为零,这表明由 X i < X m a x + l n ( 1 / 2 n ) X_i <X_{max}+ln(1/2n) Xi<Xmax+ln(1/2n)确定的输出稀疏度。这种稀疏性很难预测,因为 X m a x X_{max} Xmax是一个变量,每一行都不同,导致一个动态猜测阈值。
如图所示,动态注意力稀疏的双自由度增加了预测难度。
(3) WR-tokens的近零数值导致乘法器资源浪费
在
P
×
V
P×V
P×V中,65.3%的硬件资源被浪费,因为接近零的概率有许多值的MSB为0,导致0值的部分积(PPs)计算。
模型优化
模型无优化。
硬件设计
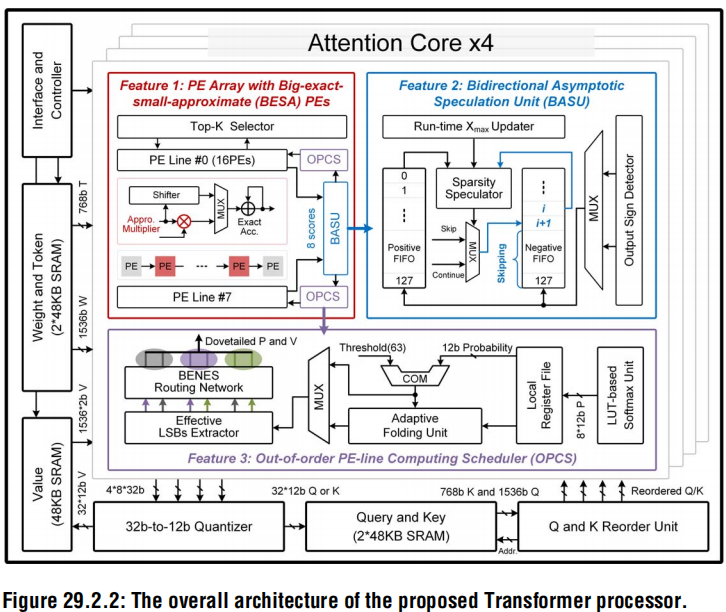
整体架构如下图所示,4个带BESA PEs的attention core(AC),4个BASUs,32个OPCSs,一个量化器,一个重排序单元和336KB SRAM。
BESA
- AC有8个PE lines,每一行有16个PE,总共8个输出
- 根据输入的token值生成Q、K、V矩阵
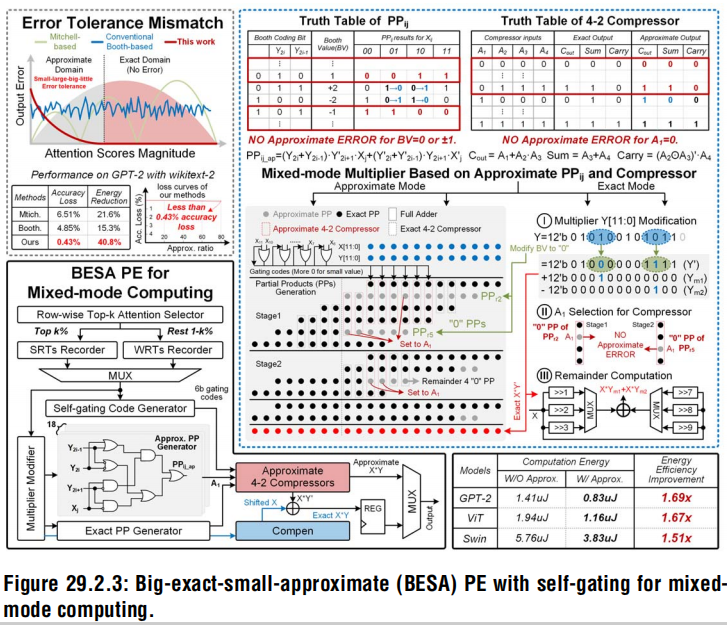
- Top-K selector选择SR-token(strongly related token,SR-token)和WR-token,attention block精确地计算SR-token,其他token近似计算
- 对于较小值的计算,PE通过检测MSB的值判断是否关断LSB的计算,以减少能耗。尽管这产生的23.5%的错误,但是softmax将错误减少到0.25%
- 每个PE都含有一个12b的booth乘法器,包含6个PPs行和24列
- 支持通过一个乘法器中PPs计算逻辑进行2个乘法操作
近似乘法器的架构如下:

- 基于Self-gating机制的数值自适应近似
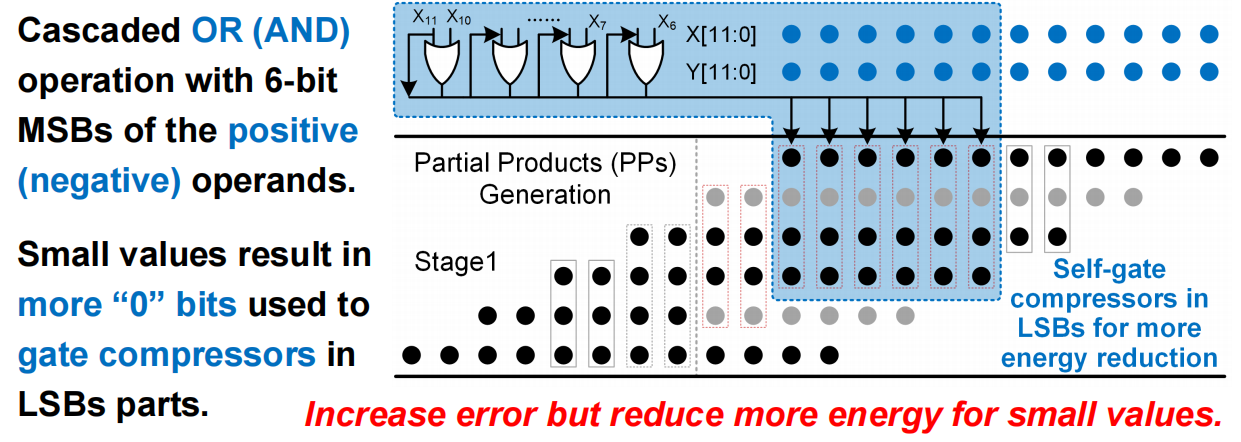
- 基于自适应调节和补偿,实现近似组件的精确计算
BASU
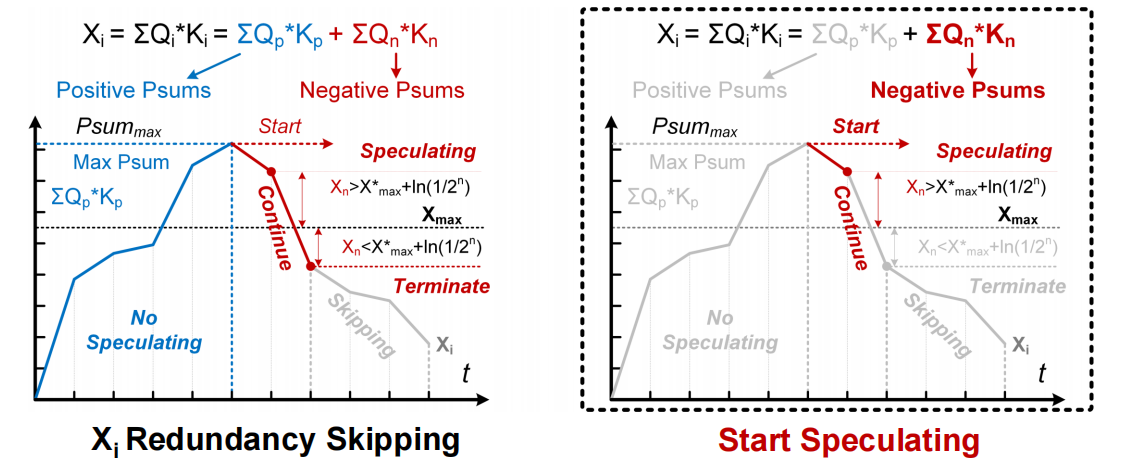
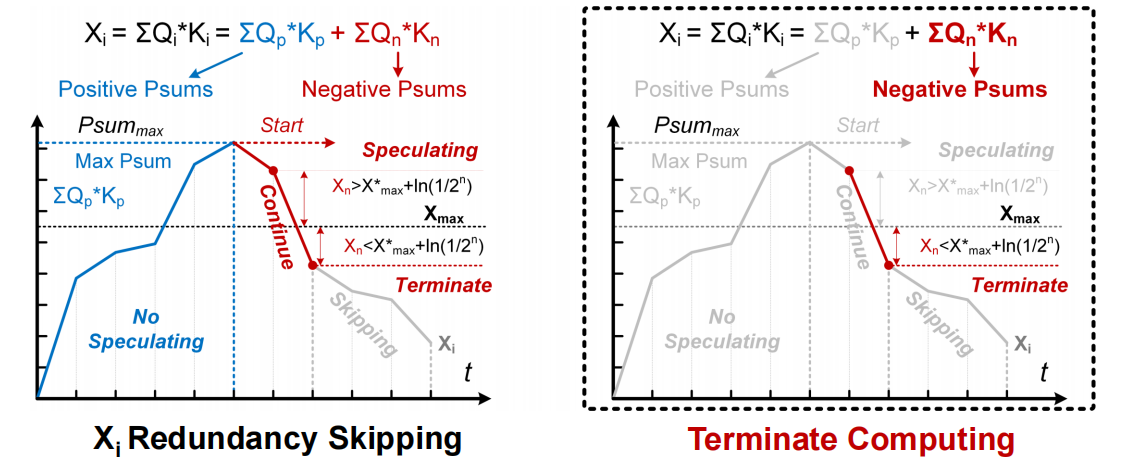
双向渐进的稀疏预测,即控制AC先进行正数MAC计算,一旦检测到稀疏后,中止负数计算
- BASU包含8个有符号的分割器,包括两个128深的fifo,一个运行时Xmax更新器和一个稀疏度预测器
- 在Q×KT期间,它控制AC对对角线attention score进行优先排序,以快速检测Xmax,以实现有效的稀疏预测。
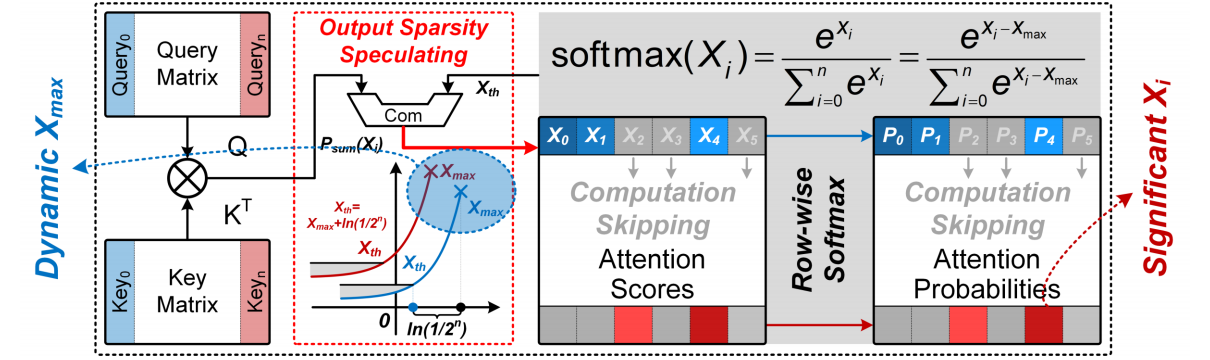
- 输出注意力稀疏预测以移除冗余计算
动态行变化的Xmax检测 ─> 对角线优先的计算
无损的Xi冗余计算移除 ─> 正数优先的预测
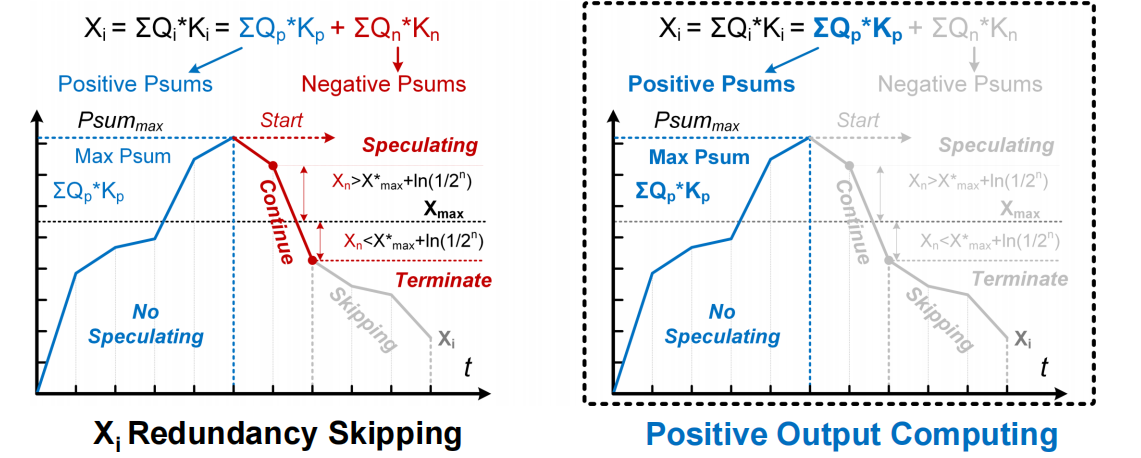
- 传统的顺序计算限制了稀疏预测效率,提出了高效的对角线优先计算

- 提出无损的正数有限预测
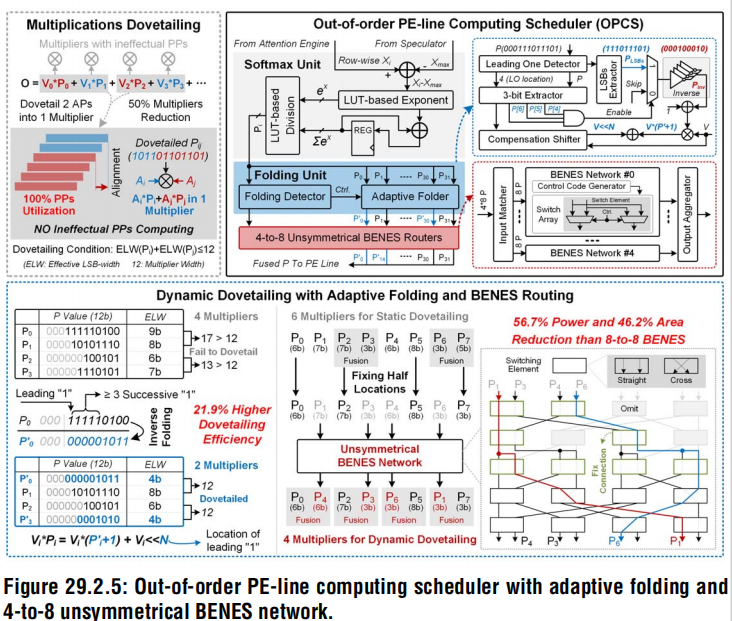
OPCS
实现乱序的计算融合,提升乘法器的资源利用率。接收AC的attention score,将其归一化为概率,在通过折叠模块获取32个概率数据并选出最大的一个
-
OPCS包含一个softmax计算单元、一个折叠单元和一个4-to-8 bit的非对称BENES网络
-
对于PxV计算,softmax计算完成后经过12 bit量化器量化,并重新排序,再发送到PE line计算
-
传统的顺序计算融合限制了资源利用率
影响融合效率的两个因素:
- 每个操作数的有效位宽大小
- 两个操作数的有效位宽之和
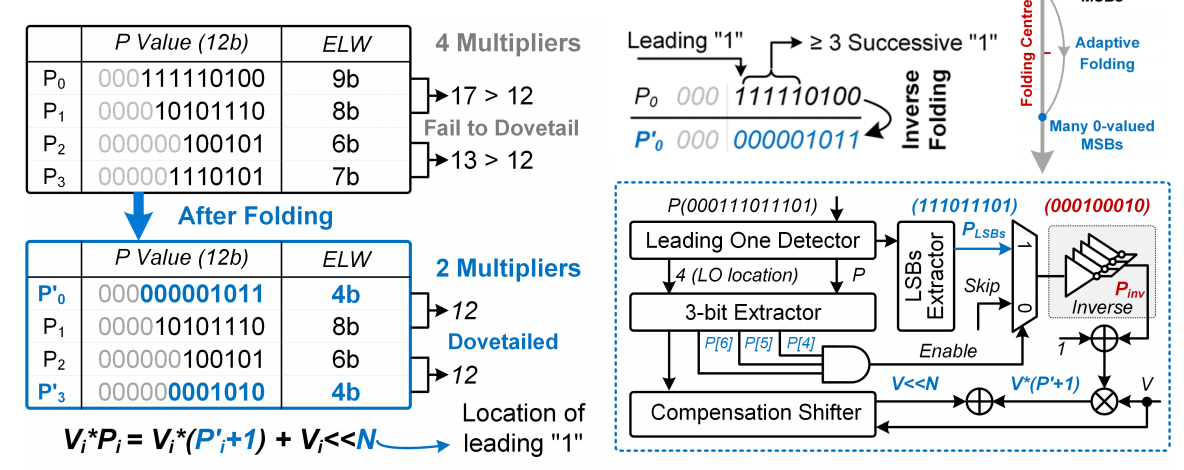
- 基于自适应的有效位宽减小
通过自适应的折叠减小操作数的有效位宽
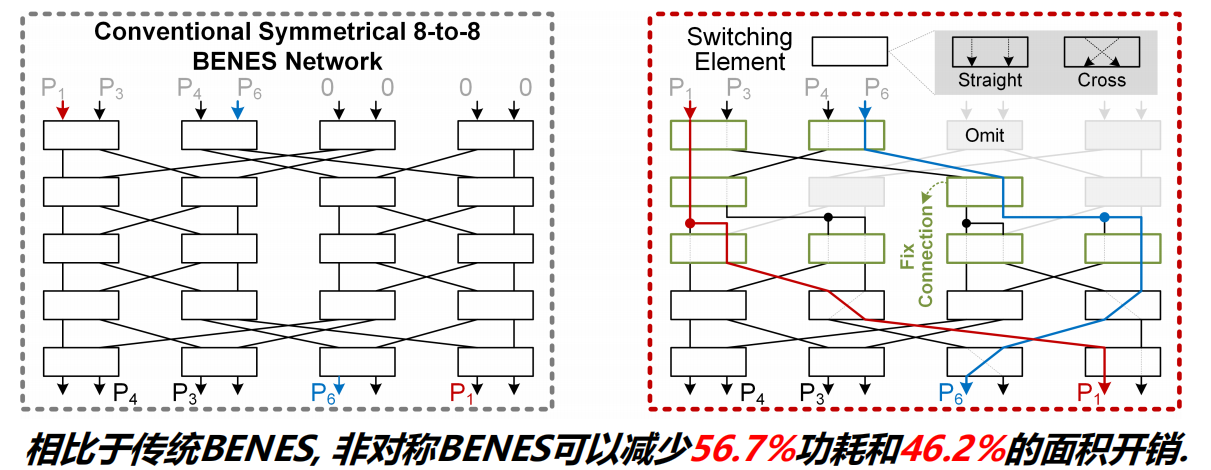
- 通过一个非对称的BENES网络乱序计算
4个4-to-8的非对称BENES路由器重新排序32个数据,每个路由器接收8个数据并根据排序的匹配器固定其中4个,另外4个数据通过4-to-8选择阵列重排序,最终将重排序的结果发送给PE line
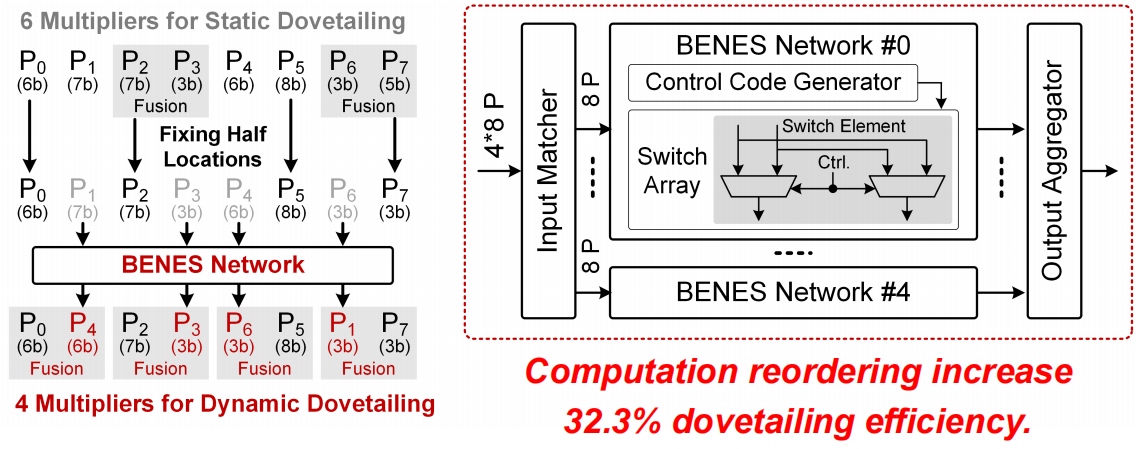 非对称性减小乱序规划开销
非对称性减小乱序规划开销
参考文献
评
上文正文部分来源于团队的ISSCC’22的论文和ICAC’2022的报告:
ISSCC:A 28nm 27.5TOPS/W Approximate-Computing-Based Transformer Processor with Asymptotic Sparsity Speculating and Out-of-Order Computing
ICAC:An Approximate-computing-based Transformer Processor with Asymptotic Sparsity Speculation and Out-of-order Computing Achieving 27.5TOPS/W Energy Efficiency
王扬博士“博士创芯说”报告
博士Review | 博士创『芯』说第十期—王扬:高能效神经形态加速器设计与实现
研究动机:减少注意力机制的能耗
弱相关的元素占据了大量的计算但对最终的精度影响较小, 同时这些弱相关元素被量化后会变成零,但零的计算是不必要的。此外,弱相关元素计算的过程中有些数值会很小,这些值在高位会产生零,从而产生Partial Product的乘法器浪费。
三项关键技术
transformer中较小值误差较小,较大值误差较大,传统的近似乘法器没有这种特性,因此采用小值近似计算、大值精确计算的策略
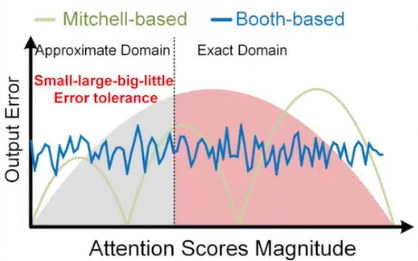
- 小值近似大值精确的近似乘法器
- self-gating自门控检测较小值并产生控制码减小压缩单元的功耗
- 动态稀疏预测预测
- 冗余计算筛选:对产生出的零值预测,并remove,从而减小计算量
- 寻找行变化的 X m a x X_{max} Xmax,通过 X i X_{i} Xi和 X m a x X_{max} Xmax的差值比较,预测输出稀疏性
- 采用对角线优先的双向渐进预测机制查询 X m a x X_{max} Xmax,提升预测效率
- 乘法操作融合
- 对于浪费的Partial Product,把乘法器分成两个部分,分别计算两个部分的的部分积
- 采用非对称的BENE降低数据搬运的面积和功耗
秦育彬博士“ICFC未来芯片”报告
活动预告 | 博士创『芯』说第七十期——秦育彬:高能效注意力模型计算架构设计
稀疏优化
在推理中寻找到结果为零的位置,并跳过相关计算
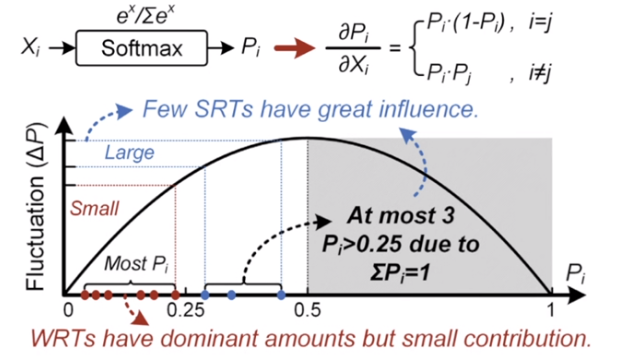
Softmax函数特征
Sofrmax的结果是和为1的概率值。
- Softmax函数导致大量存储在的极小Score
- 小的Score具有绩效的输出贡献和极高的误差容忍特性
下图可知,当Score接近于0的时候,梯度会很小,因此对其轻微的扰动不会影响最终结果
Q
模型没有经过优化直接运算了,难道芯片内Q、K、V矩阵的计算都是浮点数吗?



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











