









作者及发刊详情
Fu, X., Yang, W., Dong, D., & Su, X. (2024). Optimizing Attention by Exploiting Data Reuse on ARM Multi-core CPUs. Proceedings of the 38th ACM International Conference on Supercomputing.
摘要
正文
主要工作贡献
1)为不同架构和工作负载提供了一个分析模型,来指导数据复用和推导算术参数
2)展现了一个新的方法来开发融合的微kernel,从而减少数据访存负载
3)设计了一种沐浴并行化算法,实现了mm内和mm间的并行计算
实验评估
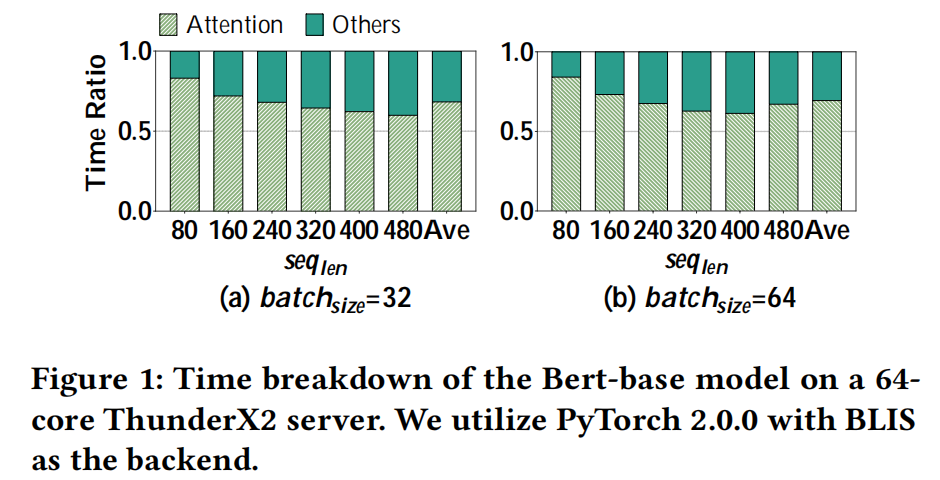
实验验证平台: Phytium 2000+, Kunpeng 920 (KP920), and ThunderX2
基于ARMv8
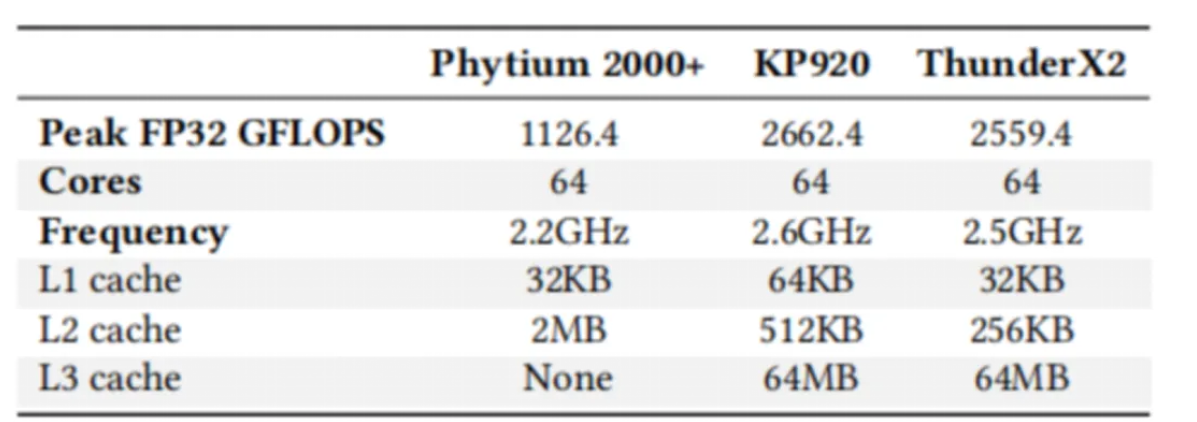
选用模型: Bert-base
测试集:GLUE benchmark
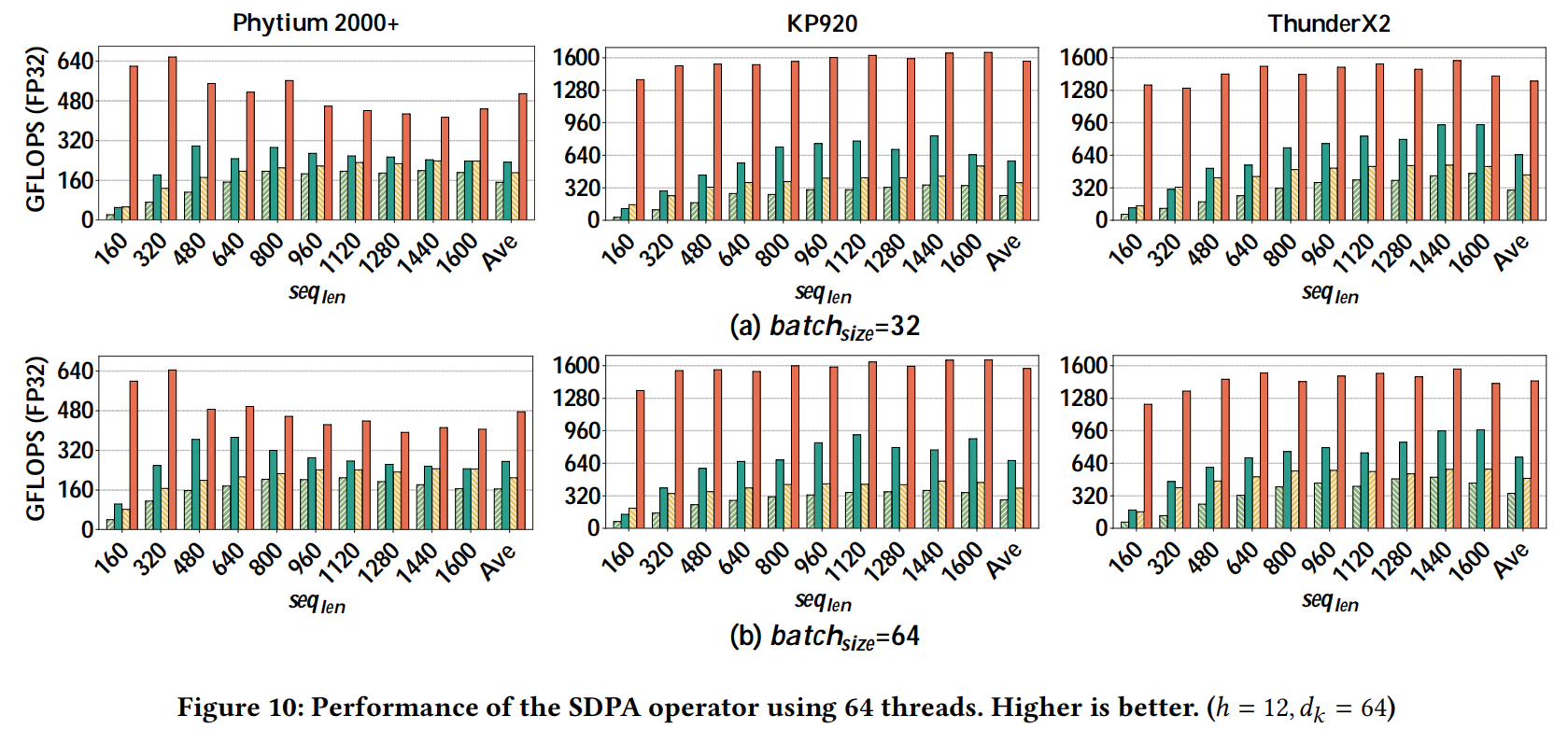
PPA表现
性能
与其他算子库的表现对比
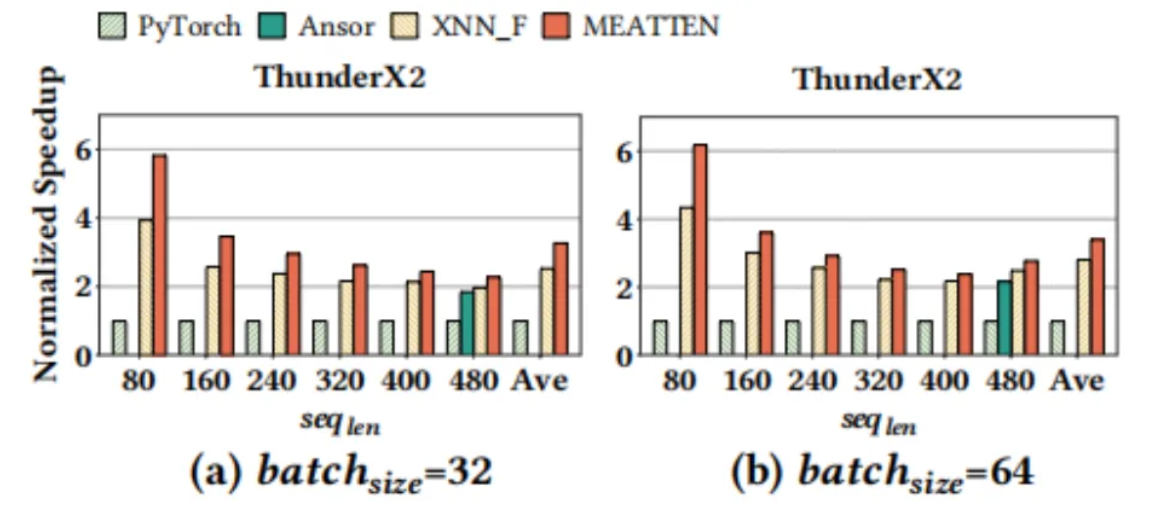
性能计算方法:
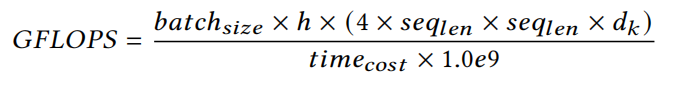
MeAtten在不同平台上的性能表现:
研究背景
Attention的在ARM处理器上的计算时间占据了70%
优化Self-Attention算子以加速Transformer模型的推理的三大挑战
Self-Attention的矩阵乘(GEMM)负载是小而不规则的,这样的矩阵负载没有被现有的主流BLAS库如OpenBLAS和BLIS优化
Self-Attention中的SoftMax是数据依赖关系复杂且访存密集的操作,如何将Softmax融合到GEMM中是一个重要的挑战
CPU上批量并行GEMM还没有成熟的解决方法
模型workload的特征
较小的batch size和seqence length将导致小的且不规则的GEMM[7,47]
文章的重点也并非是单一的大规模或不规则的矩阵乘算子的加速。
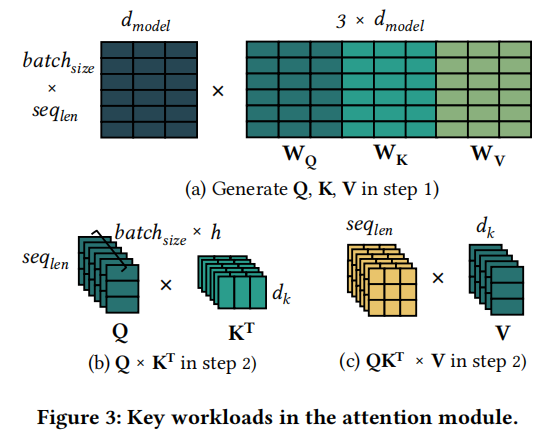
MM有着大量的betch并行计算
Q
K
T
QK^T
QKT的矩阵计算要进行batch_size x h次,占据着主要的计算。
这种小的矩阵计算不足以使用多核CPU的计算资源,强行使用将导致较低的计算效率。
不同seq长度的的MM的片上cache大小需求不同,导致算子融合和并行算法设计的挑战
逐元素操作(Point-wise Operation)是存储密集型操作,难以进行数据复用
掩码(Mask)和标量(Scale)典型地分别通过矩阵加和标量乘实现。
逐元素操作已经有工作展现了直接的融合策略[53]。
softmax有较大的访存开销,其串行的工作特征有复杂且严格的数据依赖
具体实现
MeAtten算法设计
MeAtten的输入Q,K,V以及输出O都是四维张量。

循环排序与分块
基于上述算法实现,将for循环展开,分块,从而提高数据的局部性。具体实现时,MeAtten根据循环最内层微内核的数据访问量来设计循环的排布顺序和分块参数,旨在高效利用片上的L1/L2 Cache存储资源。
其中分块参数主要是根据各层循环的访存量和各级Cache容量进行推导的。
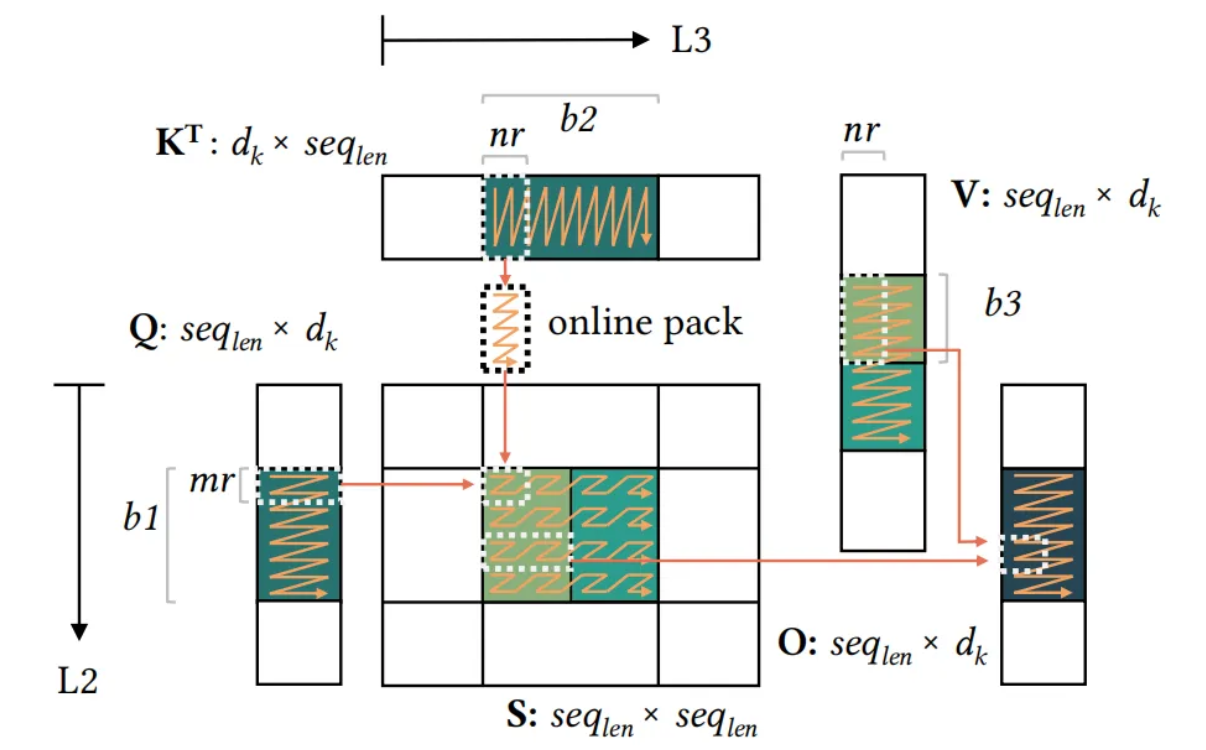
微kernel设计
MeAtten有两类微内核计算程序,分别用于计算张量Q和张量KT以及张量S和张量V的乘积,同时融合SoftMax等访存密集型子步骤。微内核用ARMv8 NEON SIMD指令编写,采用了循环展开、指令调度等经典指令级流水方法,旨在充分发挥CPU的计算能力。
第一类微kernel计算
Q
K
T
QK^T
QKT,同时融合Scale、Mask和Softmax求最大值的子步骤Max。
第二轮微kernel计算S和V的乘积,同时融合Softmax求指数Exp,求行和Sum和归一化Norm的三个子步骤。
批量并行化
MeAtten并行Self-Attention算子的批量、头数、序列长三个维度。MeAtten以参数b1对矩阵负载进行任务分割,这将产生parts个任务分区。MeAtten根据输入张量的形状自动调整每一个维度的并行线程数,以实现负载均衡。任务到线程的映射通过取余操作完成。
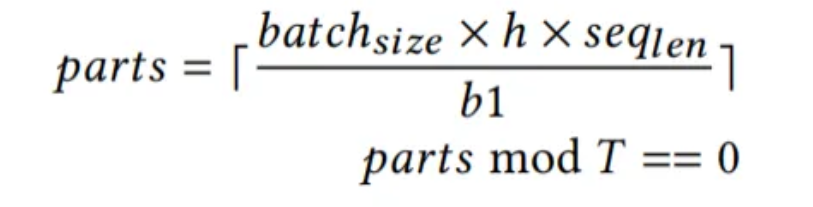
参考文献
[7] Jieyang Chen, Nan Xiong, Xin Liang, Dingwen Tao, Sihuan Li, Kaiming Ouyang,Kai Zhao, Nathan DeBardeleben, Qiang Guan, and Zizhong Chen. 2019. TSM2:optimizing tall-and-skinny matrix-matrix multiplication on GPUs. In Proceedings of the ACM International Conference on Supercomputing. 106–116.
[47] Weiling Yang, Jianbin Fang, Dezun Dong, Xing Su, and Zheng Wang. 2021. Libshalom: optimizing small and irregular-shaped matrix multiplications on armv8 multi-cores. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. 1–14.
[53] Zining Zhang, Yao Chen, Bingsheng He, and Zhenjie Zhang. 2023. NIOT: A Novel Inference Optimization of Transformers on Modern CPUs. IEEE Transactions on Parallel and Distributed Systems (2023).
评
国防科技大学团队HiNA发在ICS 24上的文章,该论文提出了一种面向ARMv8多核处理器的Self-Attention算子优化方法MeAtten,MeAtten重新定义了Attention的计算,该文将MeAtten集成到深度学习框架PyTorch中,可以了解一下MeAtten是如何集成到python中的。
HiNA@公众号:HiNA@ICS 24:面向ARM多核CPU的Transformer核心算子性能优化
知识搬运工人@CSDN:OpenBLAS学习一:源码架构解析&GEMM分析-爱代码爱编程



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











