







作者及发刊详情
Liqiang Lu, Yicheng Jin, Hangrui Bi, Zizhang Luo, Peng Li, Tao Wang, Yun Liang. Sanger: A Co-Design Framework for Enabling Sparse Attention using Reconfigurable Architecture. The 54th International Symposium on Microarchitecture (MICRO’21), 2021.
摘要
正文
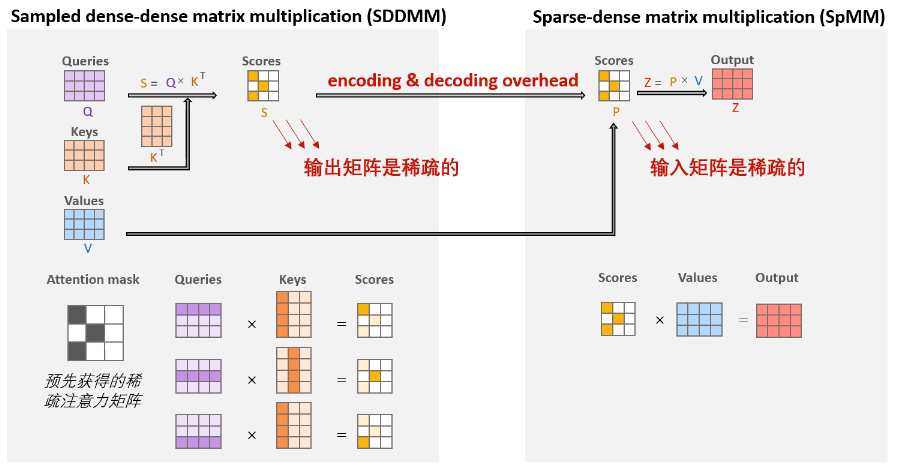
两种稀疏矩阵乘定义,如下图所示:
采样的密度矩阵乘(sampled dense–dense matrix multiplication,SDDMM):根据采样掩码,Q和K是稠密的,score矩阵是稀疏的
稀疏密度的矩阵乘(sparse-dense matrix multiplication,SpMM):稀疏的score矩阵和稠密的V矩阵计算
主要工作贡献
1)提出了Sanger,一个软硬协同设计框架,通过一个可配置矿建探索attention的动态稀疏
硬件的灵活性可以使如啊年获得搞得稀疏度。
2)软件:提出了动态的、细粒度的结构化剪枝技术,可以获得较高的灵活的和稀疏度
使用低bit计算预测稀疏attention掩码,然后通过包装和分割对齐编码,从而保证负载均衡。
3)硬件:提出了score静止的数据流和可重配置的架构
通过使用SDDMM和SpMM操作,该数据流可以有效地消除稀疏度解码负载和memory传输负载。
这种可重配置的架构可以支持大量的稀疏度模式。
实验评估
实验验证平台:Chisel
选用模型: BERT、GPT-2和BART
微调基于推理任务的预训练的checkpoint
测试集
8个任务包括:
- GLUE benchmark [56] (text classification),排除了 WNLI
- SQuAD v1.1 [47] (question answering)
- CLOTH [62] (long-context cloze which is deliberately introduced to evaluate our method on longer sequences)
工具:
代码基于Hugging Face’s Transformer库
PyTorch v1.7.1
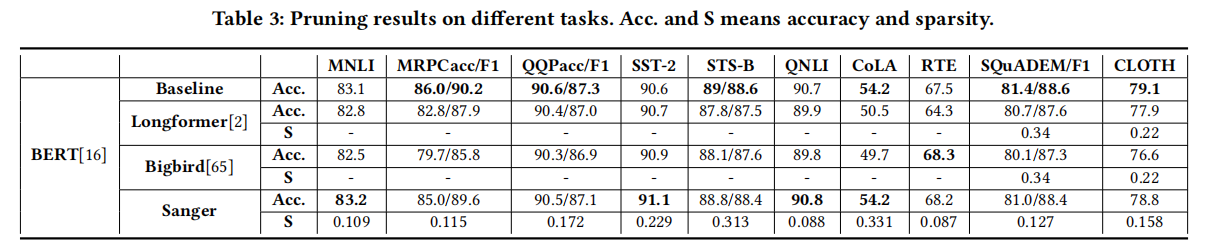
模型精度和稀疏度对比
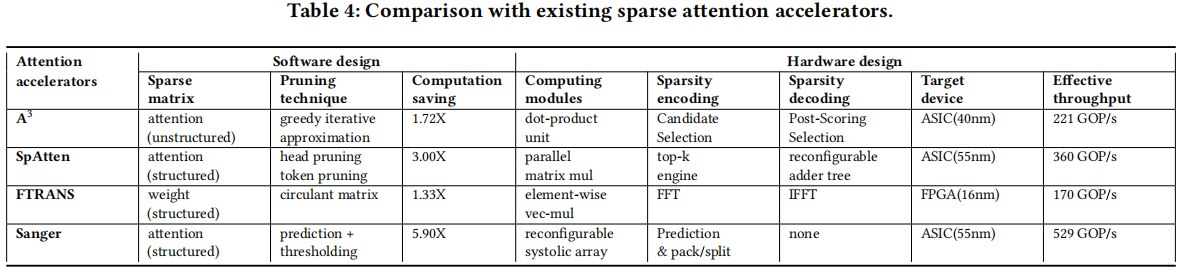
PPA表现
对比平台:
CPU:AMD Ryzen Threadripper 3970X,使用MKL-DNN算子库
GPU:Tesla V100 PCIe 32GB,使用CuDNN算子库
DSA: A3, SpAtten, FTRANS
性能
开发了周期级精度的性能模型,预设HBM带宽为128GB/s。
对于BERT、GPT-2、BART三个模型的benchmark测试,获得的加速:
基于GPUFP32, 4.71X, 6.45X, 3.76X
基于GPUFP16, 4.64X, 6.88X, 3.94X
基于 AMD Ryzen CPU, 22.7X, 13.3X, 13.2X
对于BERT模型的SQuAD任务测试,获得的加速:(基于有效吞吐计算)
相比A3 2.38X
相比SpAtten 1.47X
相比FTRANS 3.11X
能效方面:
基于GPUFP32, 48X
基于GPUFP16, 35X
基于 AMD Ryzen CPU,113X
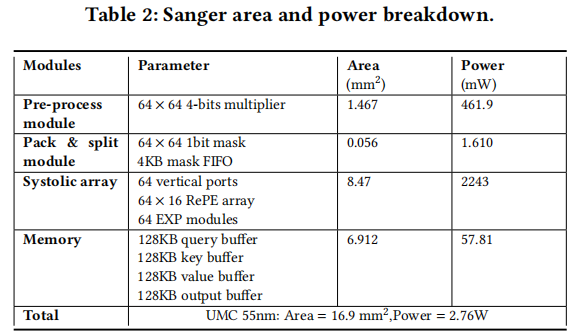
面积、功耗
使用DC在UMC 55nm综合,综合频率为500MHz。
使用Innovus16进行布局布线
软件优化
动态稀疏化面临的三个挑战
- 动态稀疏不能在推理之前确定
- softmax导致隐式稀疏化,所有值都是非零值
- 动态稀疏化通常是非结构化模式,成为硬件实现的另一个挑战
解决办法:通过算法预测每个输入的稀疏模式
通过量化、二进制阈值提取隐式稀疏性、通过包装和分割将非结构化模式布置成硬件友好的格式,计算过程如下:
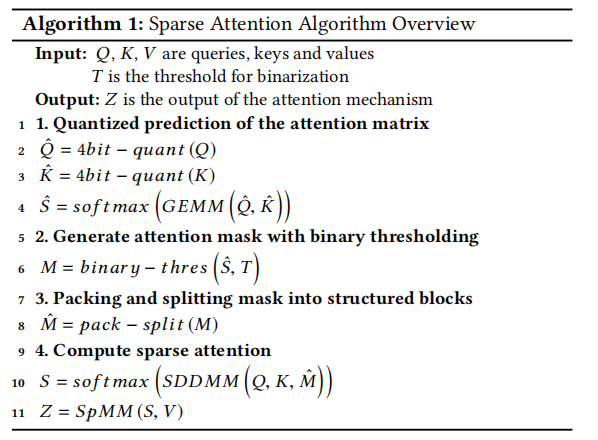
Sanger设计思路
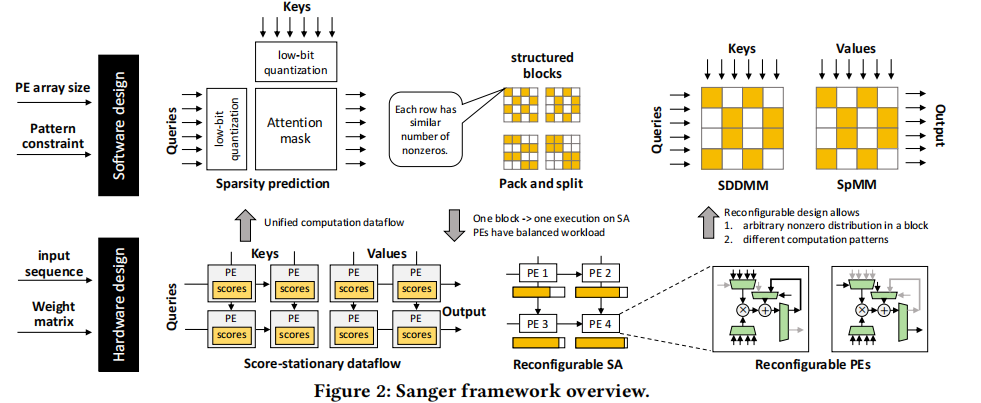
1. 通过QK的低bit的计算预测稀疏度
取Q和K矩阵的高4bit,通过稠密的通用矩阵乘和softmax计算attention矩阵的低bit预测值 S ^ \hat{S} S^
2. 根据阈值T剔除小的attention权值,从稠密的attention矩阵 S ^ \hat{S} S^中提取隐式稀疏性,输出一个非结构化稀疏性的二值化attention掩码M
3. 通过包装和分割将M转换成结构均匀的子块,每个子块对应脉动阵列上的一次执行
4. 最终attention的推理将转换为SDDMM和SpMM操作
通过可重构脉动阵列实现的score stationary的数据流,可以统一这两个矩阵的操作,并且消除中间稀疏数据的编解码开销。
硬件设计
整体架构
包含三个模块:
- 预处理单元:产生attention mask
- 编码模块:产生结构化的模块
- 可重配置脉动阵列:用于attention计算
硬件数据流
硬件数据流分为稠密和稀疏两种类型,(其区别是score矩阵在PE阵列中固定同时做稠密数据流计算和稀疏数据流计算,博主注)。目的是最大化score矩阵在片上资源的复用。从而避免了score的数据传输,消除了当score矩阵稀疏时解码负载。
QKV矩阵仍然是稠密的,可以通过FIFO传入到PE阵列中。
score固定数据流另一个优势是将SDDMM和SpMM的计算布置在一个脉动阵列中,可以节约加速器的面积。
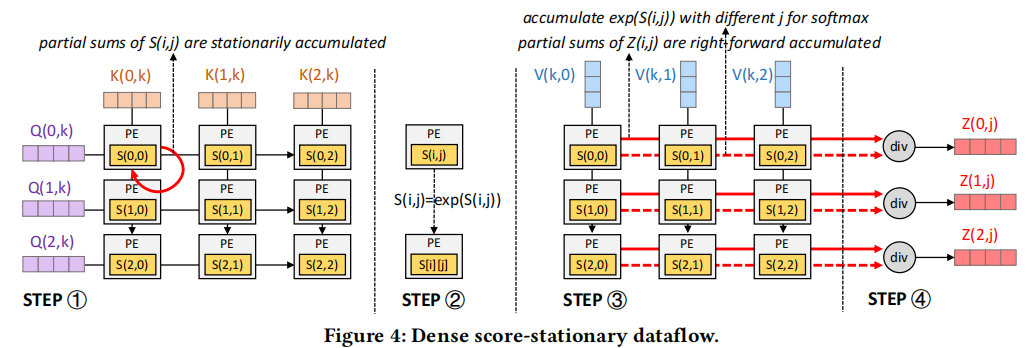
稠密score固定数据流
STEP1. Q和K矩阵通过一个脉动阵列生成一个attention score
STEP2. 每个PE进行指数计算,为softmax操作做准备
STEP3. score矩阵乘以V
STEP4. PE阵列的输出再除以指数和,以实现softmax归一化
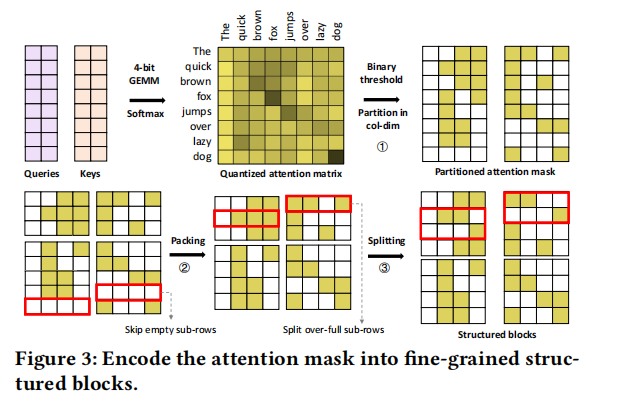
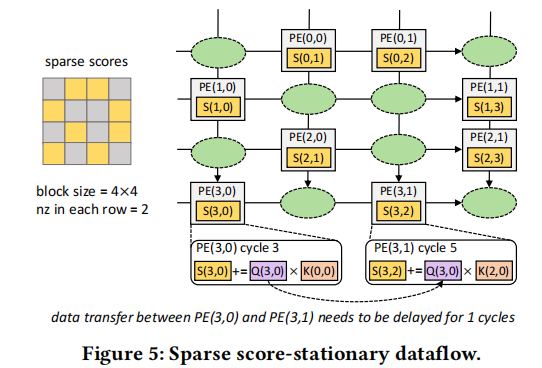
稀疏score-stationary数据流
不规则的稀疏很难发挥脉动阵列的并行性。稀疏的score固定数据流和稠密的score固定数据流共享Q、K、V的访问。
数据搬运需要被纠正,即在PE之间插入气泡(buddle),每个气泡都可以被认为使一个虚拟PE,可以让数据暂停一个周期。
插入的气泡数量根据稀疏块中的0数量分布决定。
如下图所示,若存在分割好的稀疏注意力score矩阵,计算单元按照非零元在矩阵中的位置进行排布,则每一行只有两个计算单元,S(3,0)和S(3,2)的计算都需要用到Q(3,0),因此在PE(3,0)和PE(3,1)之间插入一个buddle,使Q(3,0)在阵列中保存延迟一个时钟周期。
可重配置脉动阵列的设计
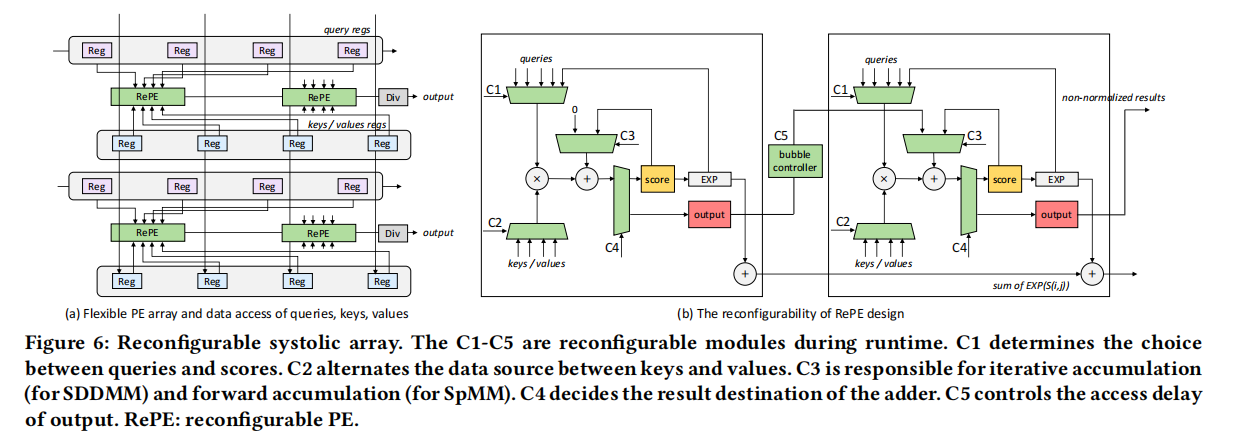
为了支持上述硬件数据流,需要设计一种可重配置的架构,该架构有两种挑战:
- 为了支持未知非0分布的稀疏模式,输入矩阵QKV和PE的连接需要比较灵活
- SDDMM和SpMM在部分和的数据传输和累加上不同
SDDMM是在内部迭代累加,而SpMM是计算单元间向右累加

为此设计可重构脉动阵列,核心思想是将数据寄存器Reg和计算单元进行解耦,根据稀疏范式来决定寄存器与计算单元之间的连接,即通过一个多路选择器选择乘法的输入寄存器来源。如图6(a)所示是可重构脉动阵列架构图,图6(b)中的C1/2选择乘法数据来源,C3判断是SDDMM或是SpMM等方式的加法操作,C4判断加法结果的输出目的地,C5控制PE输出的延迟
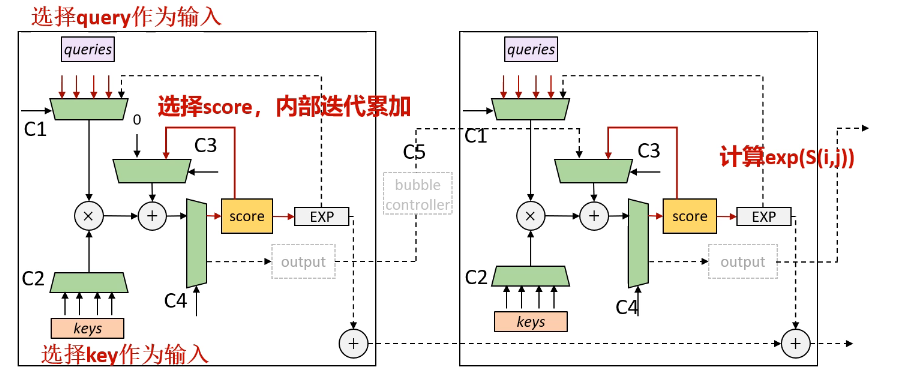
 执行SDDMM的配置情况如下:
执行SDDMM的配置情况如下:
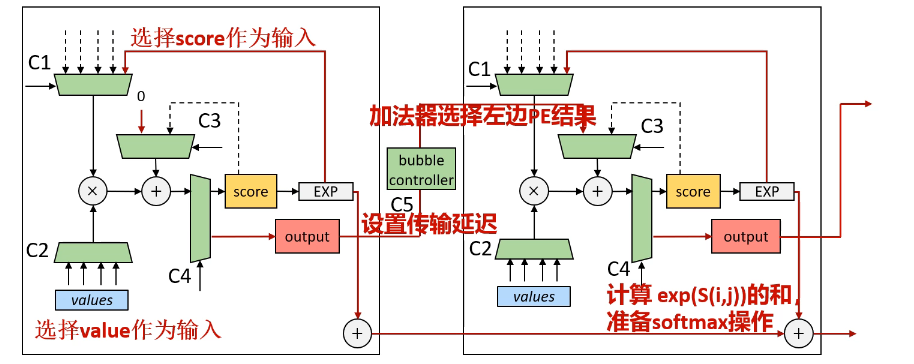
执行SpMM的配置情况如下:
参考文献
评
该论文提出了一种软硬协同设计的矩阵计算加速器方案。
在计算Attention Score之前,先采用Q和K矩阵的高4bit惩罚估算,并通过阈值判断哪些位置是不重要的,从而稀疏化注意力矩阵。
注意力稀疏化有三个挑战
负载不均衡
矩阵稀疏后,不规则的非零元分布会导致各个计算单元之间负载不均衡,最终的延迟取决于并行计算节点中算的最慢的一个
复杂的稀疏计算
attention的计算包含了稀疏矩阵、稠密矩阵的混合计算。
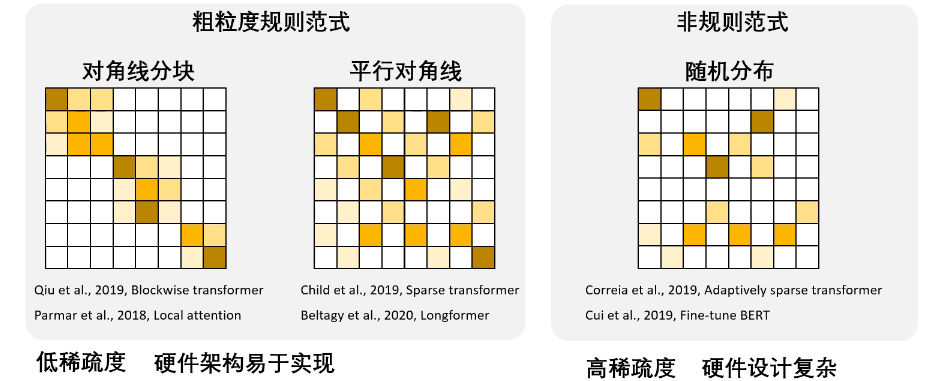
稀疏范式与硬件效率的矛盾
需要在稀疏粒度与硬件架构复杂度直接按权衡
低稀疏度,稀疏度规则,硬件架构易于实现
高稀疏度,稀疏度不规则,硬件设计较为复杂
该项目已开源,硬件代码采用chisal编写。
Github开源地址
B站:Sanger: A Co-Design Framework for Enabling Sparse Attention using Reconfigurable



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











